Fazer deploy do YOLOv8 em NVIDIA Jetson usando TensorRT e DeepStream SDK Support
Este guia explica como fazer o deploy de um modelo de IA treinado na Plataforma NVIDIA Jetson e realizar inferência usando TensorRT e DeepStream SDK. Aqui usamos TensorRT para maximizar o desempenho de inferência na plataforma Jetson.

Pré‑requisitos
- PC Host com Ubuntu (nativo ou VM usando VMware Workstation Player)
- reComputer Jetson ou qualquer outro dispositivo NVIDIA Jetson executando JetPack 4.6 ou superior
Versão do DeepStream correspondente à versão do JetPack
Para que o YOLOv8 funcione junto com o DeepStream, estamos usando este repositório DeepStram-YOLO, que oferece suporte a diferentes versões do DeepStream. Portanto, certifique‑se de usar a versão correta do JetPack de acordo com a versão correta do DeepStream.
| Versão do DeepStream | Versão do JetPack |
|---|---|
| 6.2 | 5.1.1 |
| 5.1 | |
| 6.1.1 | 5.0.2 |
| 6.1 | 5.0.1 DP |
| 6.0.1 | 4.6.3 |
| 4.6.2 | |
| 4.6.1 | |
| 6.0 | 4.6 |
Para verificar este wiki, instalamos o DeepStream SDK 6.2 em um sistema JetPack 5.1.1 executando em reComputer J4012.
Gravar o JetPack no Jetson
Agora você precisa se certificar de que o dispositivo Jetson está gravado com um sistema JetPack, incluindo componentes do SDK, como CUDA, TensorRT, cuDNN e outros. Você pode usar o NVIDIA SDK Manager ou a linha de comando para gravar o JetPack no dispositivo.
Para guias de gravação de dispositivos Jetson alimentados pela Seeed, consulte os links abaixo:
- reComputer J1010 | J101
- reComputer J2021 | J202
- reComputer J1020 | A206
- reComputer J4012 | J401
- Placa Carrier A203
- Placa Carrier A205
- Kit Jetson Xavier AGX H01
- Kit Jetson AGX Orin 32GB H01
Instalar o DeepStream
Há várias maneiras de instalar o DeepStream no dispositivo Jetson. Você pode seguir este guia para saber mais. No entanto, recomendamos que você instale o DeepStream via SDK Manager porque isso pode garantir uma instalação bem‑sucedida e simples.
Se você instalar o DeepStream usando o SDK Manager, será preciso executar os comandos abaixo, que são dependências adicionais para o DeepStream, depois que o sistema inicializar
sudo apt install \
libssl1.1 \
libgstreamer1.0-0 \
gstreamer1.0-tools \
gstreamer1.0-plugins-good \
gstreamer1.0-plugins-bad \
gstreamer1.0-plugins-ugly \
gstreamer1.0-libav \
libgstreamer-plugins-base1.0-dev \
libgstrtspserver-1.0-0 \
libjansson4 \
libyaml-cpp-dev
Instalar Pacotes Necessários
- Passo 1. Acesse o terminal do dispositivo Jetson, instale o pip e faça o upgrade
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- Passo 2. Clone o repositório a seguir
git clone https://github.com/ultralytics/ultralytics.git
- Passo 3. Abra o requirements.txt
cd ultralytics
vi requirements.txt
- Passo 4. Edite as seguintes linhas. Aqui você precisa pressionar
iprimeiro para entrar no modo de edição. PressioneESC, depois digite:wqpara salvar e sair
# torch>=1.7.0
# torchvision>=0.8.1
Nota: torch e torchvision estão excluídos por enquanto porque serão instalados posteriormente.
- Passo 5. Instale os pacotes necessários
pip3 install -r requirements.txt
Se o instalador reclamar sobre o pacote python-dateutil desatualizado, faça o upgrade com
pip3 install python-dateutil --upgrade
Instalar PyTorch e Torchvision
Não podemos instalar PyTorch e Torchvision pelo pip porque eles não são compatíveis para execução na plataforma Jetson, que é baseada na arquitetura ARM aarch64. Portanto, precisamos instalar manualmente o pacote wheel do PyTorch pré‑compilado e compilar/ instalar o Torchvision a partir do código‑fonte.
Visite esta página para acessar todos os links de PyTorch e Torchvision.
Aqui estão algumas das versões compatíveis com JetPack 5.0 e superior.
PyTorch v1.11.0
Compatível com JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) com Python 3.8
file_name: torch-1.11.0-cp38-cp38-linux_aarch64.whl URL: https://nvidia.box.com/shared/static/ssf2v7pf5i245fk4i0q926hy4imzs2ph.whl
PyTorch v1.12.0
Compatível com JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) com Python 3.8
file_name: torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl URL: https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- Passo 1. Instale o torch de acordo com a sua versão do JetPack no seguinte formato
wget <URL> -O <file_name>
pip3 install <file_name>
Por exemplo, aqui estamos executando o JP5.0.2 e portanto escolhemos o PyTorch v1.12.0
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl -O torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
pip3 install torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- Passo 2. Instale o torchvision dependendo da versão do PyTorch que você instalou. Por exemplo, escolhemos o PyTorch v1.12.0, o que significa que precisamos escolher o Torchvision v0.13.0
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.13.0 https://github.com/pytorch/vision torchvision
cd torchvision
python3 setup.py install --user
Aqui está uma lista da versão correspondente do torchvision que você precisa instalar de acordo com a versão do PyTorch:
- PyTorch v1.11 - torchvision v0.12.0
- PyTorch v1.12 - torchvision v0.13.0
Se você quiser uma lista mais detalhada, verifique este link.
Configuração do DeepStream para YOLOv8
- Passo 1. Clone o repositório a seguir
cd ~
git clone https://github.com/marcoslucianops/DeepStream-Yolo
- Passo 2. Faça checkout do repositório para o commit a seguir
cd DeepStream-Yolo
git checkout 68f762d5bdeae7ac3458529bfe6fed72714336ca
- Passo 3. Copie gen_wts_yoloV8.py de DeepStream-Yolo/utils para o diretório ultralytics
cp utils/gen_wts_yoloV8.py ~/ultralytics
- Passo 4. Dentro do repositório ultralytics, baixe o arquivo pt em YOLOv8 releases (exemplo para YOLOv8s)
wget https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt
NOTA: Você pode usar seu modelo customizado, mas é importante manter a referência do modelo YOLO (yolov8_) nos nomes dos arquivos cfg e weights/wts para gerar o engine corretamente.
- Passo 5. Gere os arquivos cfg, wts e labels.txt (se disponível) (exemplo para YOLOv8s)
python3 gen_wts_yoloV8.py -w yolov8s.pt
Nota: Para alterar o tamanho de inferência (padrão: 640)
-s SIZE
--size SIZE
-s HEIGHT WIDTH
--size HEIGHT WIDTH
Example for 1280:
-s 1280
or
-s 1280 1280
- Passo 6. Copie os arquivos cfg, wts e labels.txt gerados (se gerados) para a pasta DeepStream-Yolo
cp yolov8s.cfg ~/DeepStream-Yolo
cp yolov8s.wts ~/DeepStream-Yolo
cp labels.txt ~/DeepStream-Yolo
- Passo 7. Abra a pasta DeepStream-Yolo e compile a biblioteca
cd ~/DeepStream-Yolo
CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.2/ 6.1.1 / 6.1
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
- Passo 8. Edite o arquivo config_infer_primary_yoloV8.txt de acordo com o seu modelo (exemplo para YOLOv8s com 80 classes)
[property]
...
custom-network-config=yolov8s.cfg
model-file=yolov8s.wts
...
num-detected-classes=80
...
- Passo 9. Edite o arquivo deepstream_app_config.txt
...
[primary-gie]
...
config-file=config_infer_primary_yoloV8.txt
- Passo 10. Altere a fonte de vídeo no arquivo deepstream_app_config.txt. Aqui um arquivo de vídeo padrão é carregado, como você pode ver abaixo
...
[source0]
...
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
Executar a Inferência
deepstream-app -c deepstream_app_config.txt
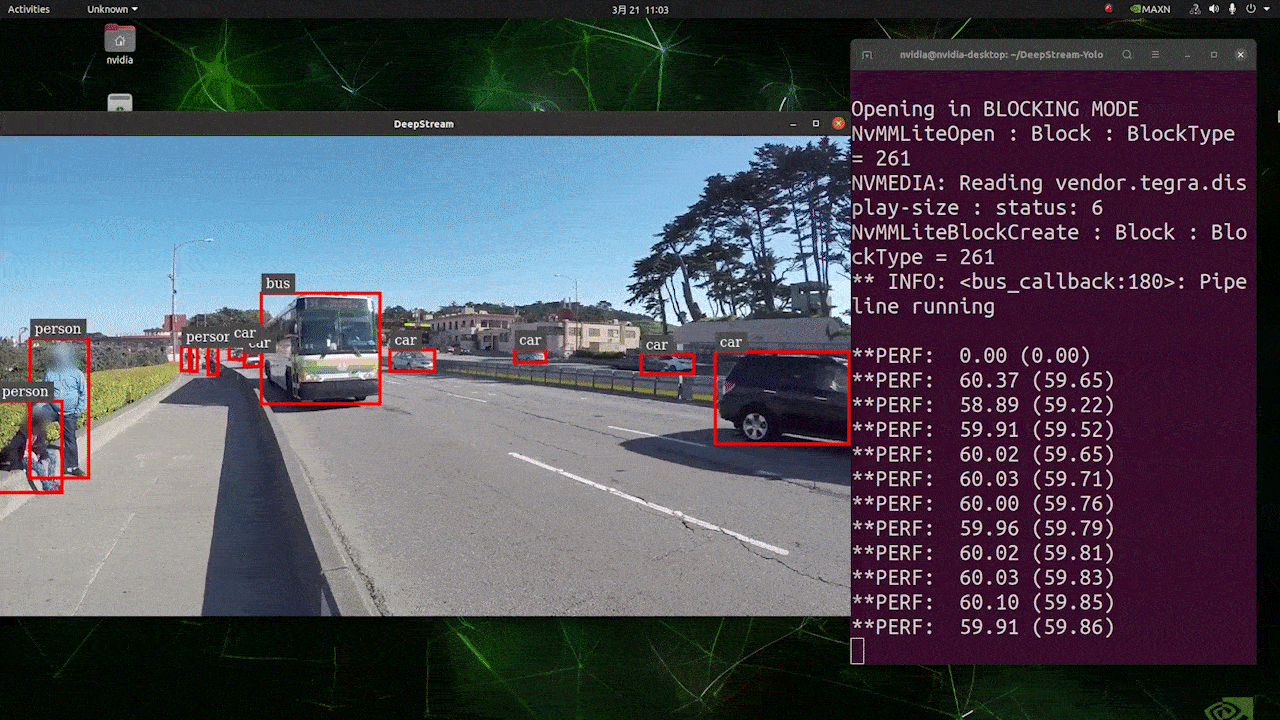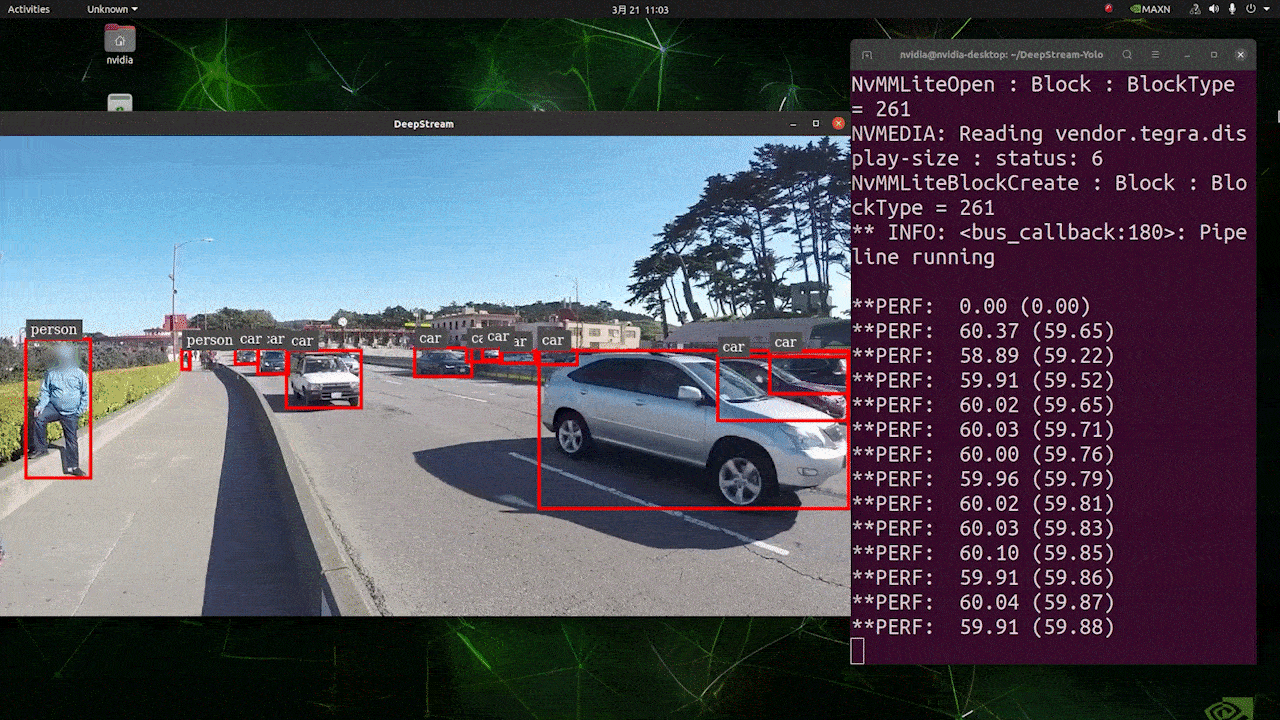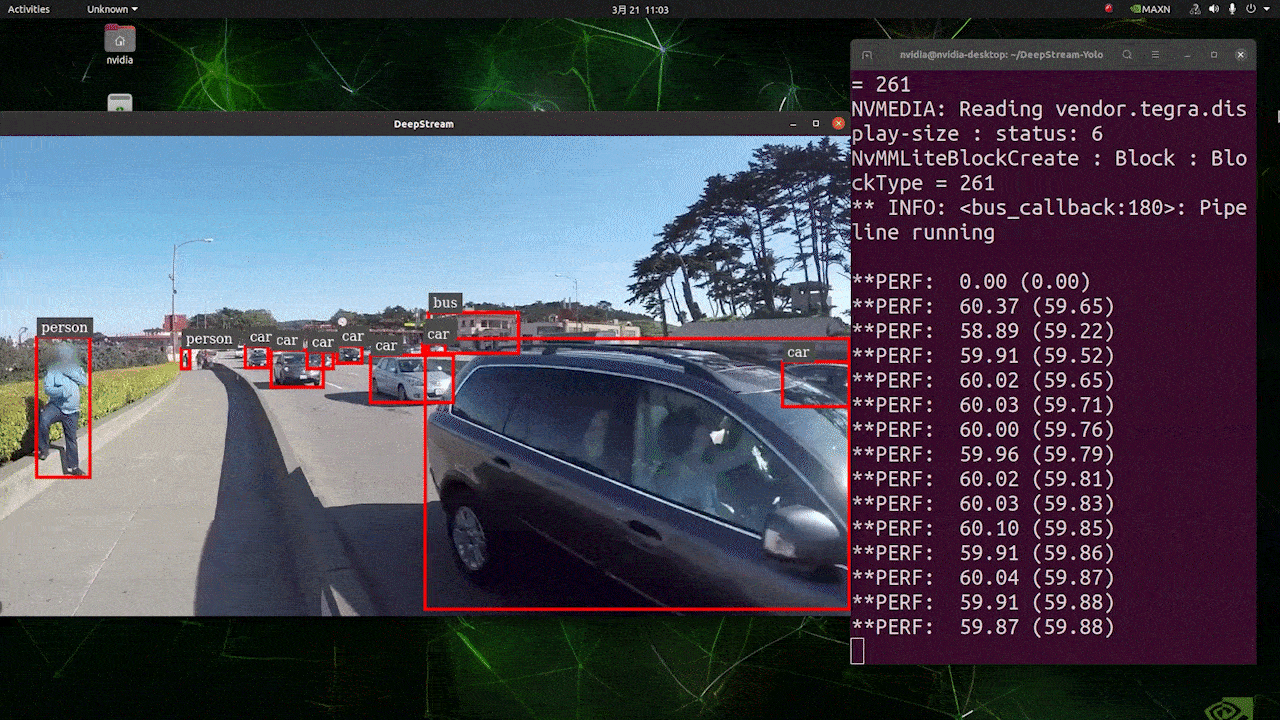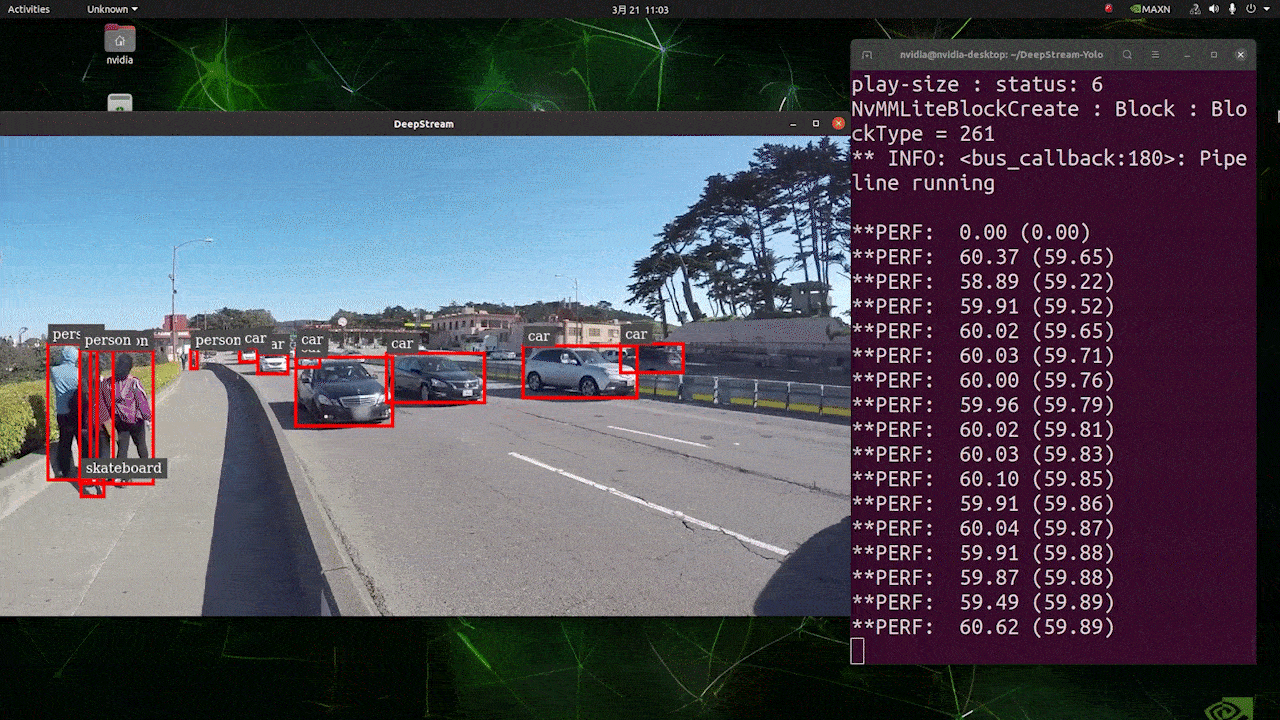
O resultado acima está sendo executado no Kit Jetson AGX Orin 32GB H01 com FP32 e YOLOv8s 640x640. Podemos ver que o FPS é em torno de 60 e esse não é o FPS real porque, quando definimos type=2 em [sink0] no arquivo deepstream_app_config.txt, o FPS é limitado ao fps do monitor e o monitor que usamos para este teste é um monitor de 60Hz. No entanto, se você alterar esse valor para type=1, poderá obter o FPS máximo, mas não haverá saída de detecção ao vivo.
Para a mesma fonte de vídeo e o mesmo modelo usados acima, após alterar type=1 em [sink0], o resultado abaixo pode ser obtido.
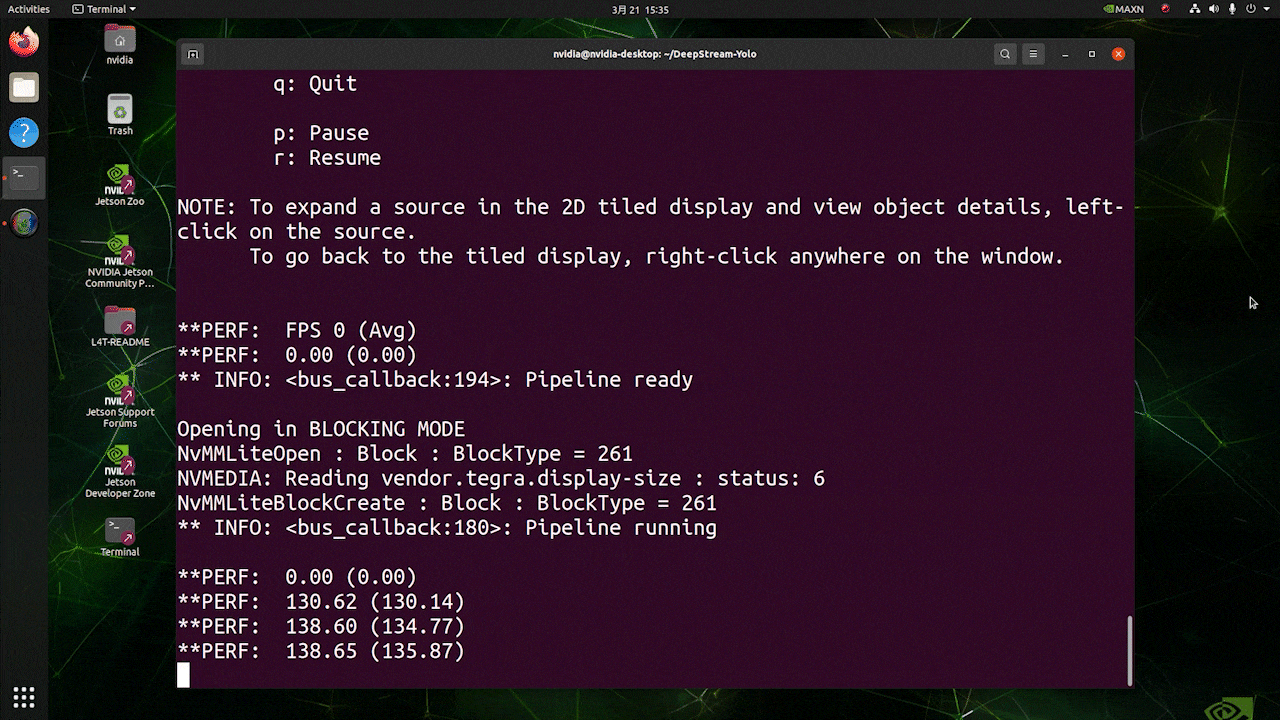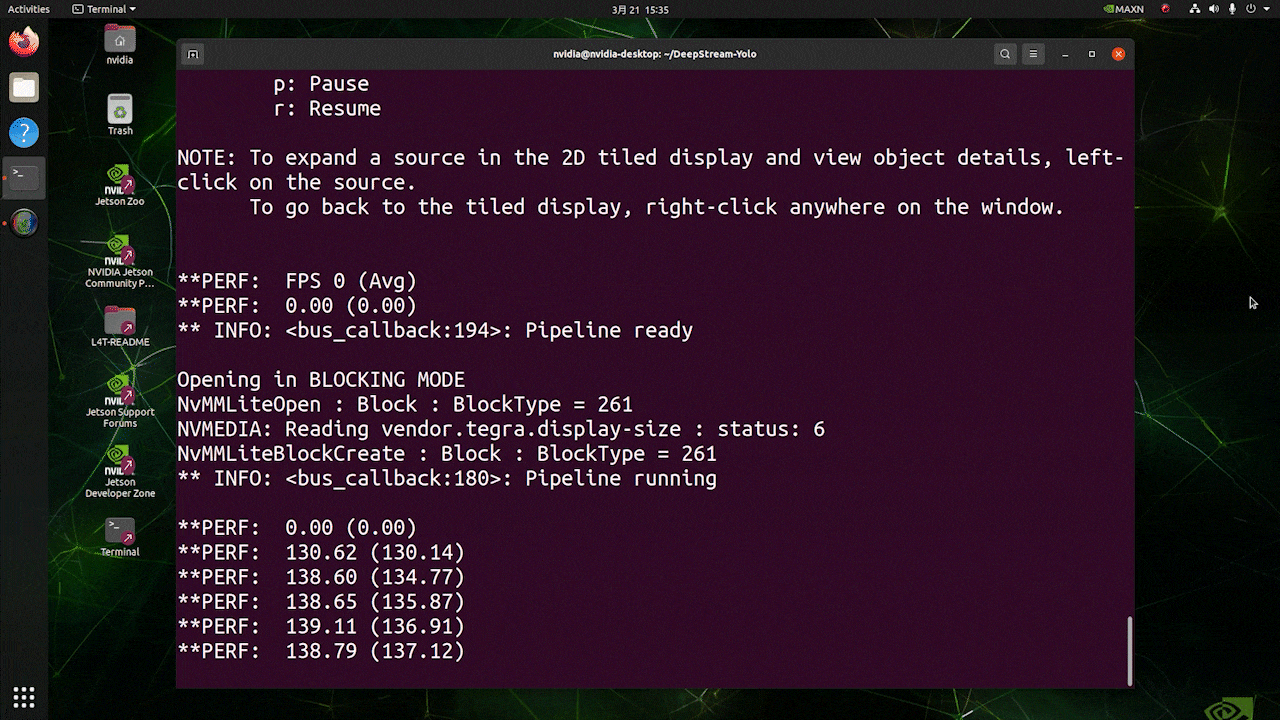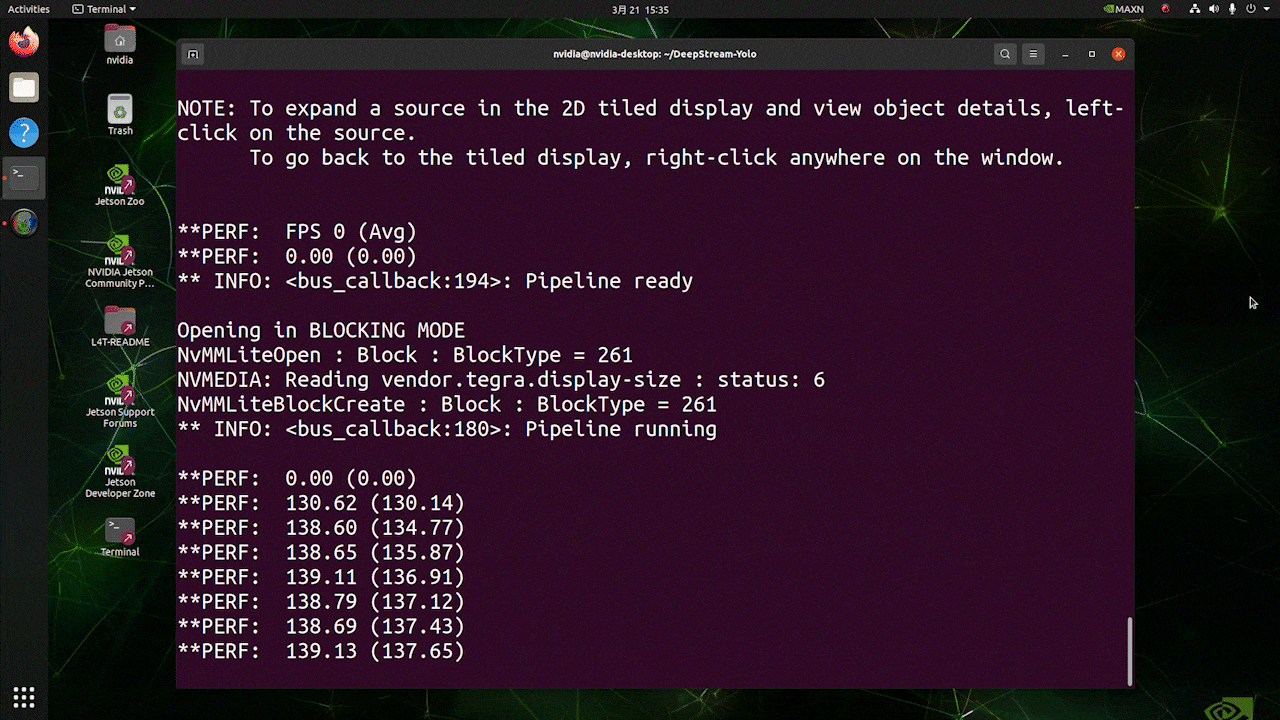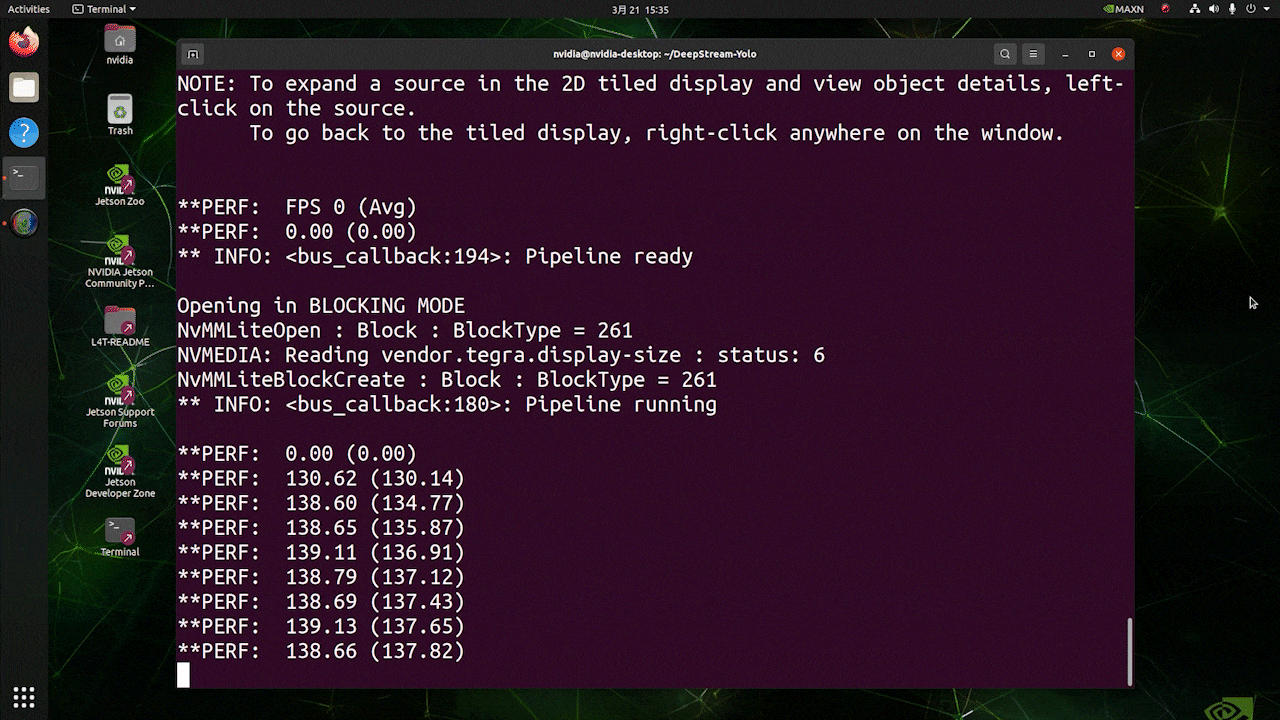
Como você pode ver, conseguimos um fps de cerca de 139, que se relaciona com o valor real de fps.
Calibração INT8
Se você quiser usar a precisão INT8 para inferência, precisa seguir as etapas abaixo
- Etapa 1. Instalar OpenCV
sudo apt-get install libopencv-dev
- Etapa 2. Compilar/recompilar a biblioteca nvdsinfer_custom_impl_Yolo com suporte a OpenCV
cd ~/DeepStream-Yolo
CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.2/ 6.1.1 / 6.1
CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
-
Etapa 3. Para o conjunto de dados COCO, baixe o val2017, extraia e mova para a pasta DeepStream-Yolo
-
Etapa 4. Crie um novo diretório para imagens de calibração
mkdir calibration
- Etapa 5. Execute o seguinte para selecionar 1000 imagens aleatórias do conjunto de dados COCO para executar a calibração
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
cp ${jpg} calibration/; \
done
Observação: a NVIDIA recomenda pelo menos 500 imagens para obter uma boa precisão. Neste exemplo, 1000 imagens foram escolhidas para obter melhor precisão (mais imagens = mais precisão). Valores mais altos de INT8_CALIB_BATCH_SIZE resultarão em maior precisão e velocidade de calibração mais rápida. Defina isso de acordo com a memória da sua GPU. Você pode configurá-lo a partir de head -1000. Por exemplo, para 2000 imagens, head -2000. Esse processo pode levar muito tempo.
- Etapa 6. Crie o arquivo calibration.txt com todas as imagens selecionadas
realpath calibration/*jpg > calibration.txt
- Etapa 7. Defina variáveis de ambiente
export INT8_CALIB_IMG_PATH=calibration.txt
export INT8_CALIB_BATCH_SIZE=1
- Etapa 8. Atualize o arquivo config_infer_primary_yoloV8.txt
De
...
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
...
network-mode=0
...
Para
...
model-engine-file=model_b1_gpu0_int8.engine
int8-calib-file=calib.table
...
network-mode=1
...
-
Etapa 9. Antes de executar a inferência, defina type=2 em [sink0] no arquivo deepstream_app_config.txt conforme mencionado antes para obter o desempenho máximo de fps.
-
Etapa 10. Execute a inferência
deepstream-app -c deepstream_app_config.txt
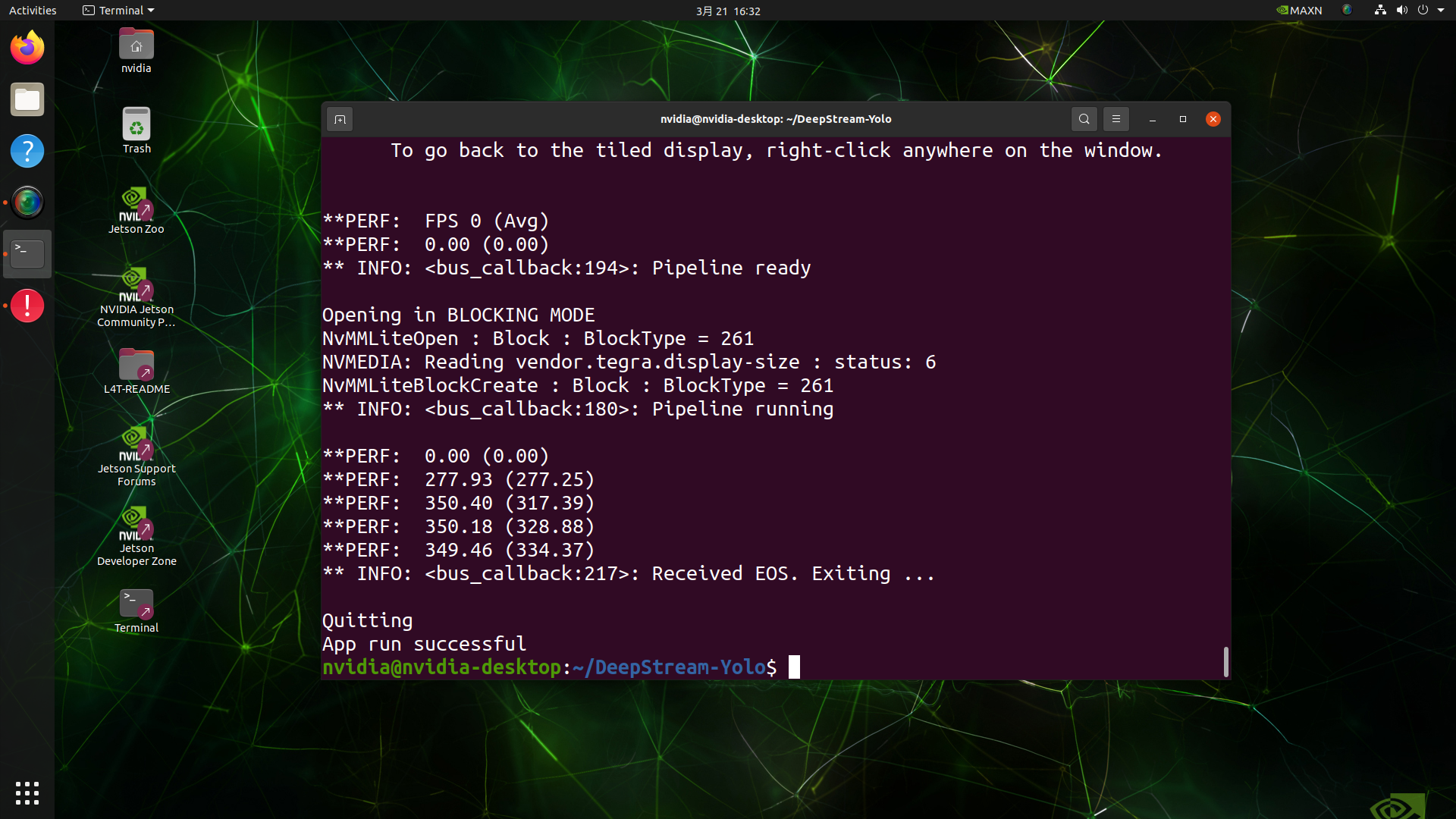
Aqui obtemos um valor de FPS de cerca de 350!
Configuração Multistream
O NVIDIA DeepStream permite configurar facilmente vários streams em um único arquivo de configuração para construir aplicações de análise de vídeo multistream. Vamos demonstrar mais adiante neste wiki como modelos com alto desempenho de FPS podem realmente ajudar em aplicações multistream junto com alguns benchmarks.
Aqui tomaremos 9 streams como exemplo. Estaremos alterando o arquivo deepstream_app_config.txt.
- Etapa 1. Na seção [tiled-display], altere as linhas e colunas para 3 e 3 para que possamos ter uma grade 3x3 com 9 streams
[tiled-display]
rows=3
columns=3
- Etapa 2. Na seção [source0], defina num-sources=9 e adicione mais uri. Aqui vamos simplesmente duplicar o arquivo de vídeo de exemplo atual 8 vezes para completar 9 streams no total. No entanto, você pode mudar para diferentes streams de vídeo de acordo com a sua aplicação
[source0]
enable=1
type=3
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
num-sources=9
Agora, se você executar a aplicação novamente com o comando deepstream-app -c deepstream_app_config.txt, verá a seguinte saída
Ferramenta trtexec
Incluída no diretório de amostras está uma ferramenta wrapper de linha de comando chamada trtexec. trtexec é uma ferramenta para usar TensorRT sem ter que desenvolver sua própria aplicação. A ferramenta trtexec tem três propósitos principais:
- Fazer benchmark de redes em dados de entrada aleatórios ou fornecidos pelo usuário.
- Gerar mecanismos serializados a partir de modelos.
- Gerar um cache de temporização serializado a partir do builder.
Aqui podemos usar a ferramenta trtexec para rapidamente fazer benchmark dos modelos com diferentes parâmetros. Mas antes de tudo, você precisa ter um modelo onnx e podemos gerar esse modelo onnx usando ultralytics yolov8.
- Etapa 1. Construir o ONNX usando:
yolo mode=export model=yolov8s.pt format=onnx
- Etapa 1. Construir o arquivo de engine usando trtexec da seguinte forma:
cd /usr/src/tensorrt/bin
./trtexec --onnx=<path_to_onnx_file> --saveEngine=<path_to_save_engine_file>
Por exemplo:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine
Isso irá produzir resultados de desempenho como segue juntamente com um arquivo .engine gerado. Por padrão, ele converterá ONNX em um arquivo otimizado TensorRT em precisão FP32 e você pode ver a saída como segue
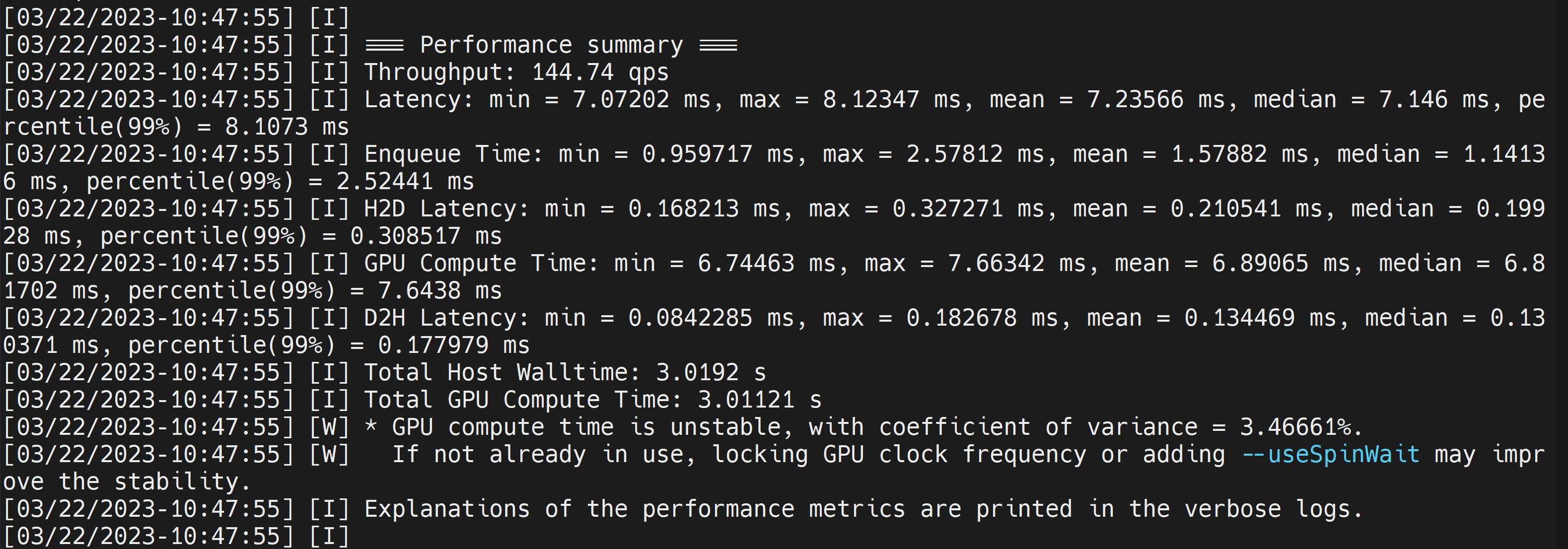
Aqui podemos considerar a latência média como 7.2ms, o que se traduz em 139FPS. Este é o mesmo desempenho que obtivemos na demonstração DeepStream anterior.
No entanto, se você quiser precisão INT8, que oferece melhor desempenho, pode executar o comando acima da seguinte forma
./trtexec --onnx=/home/nvidia/yolov8s.onnx --int8 --saveEngine=/home/nvidia/yolov8s.engine
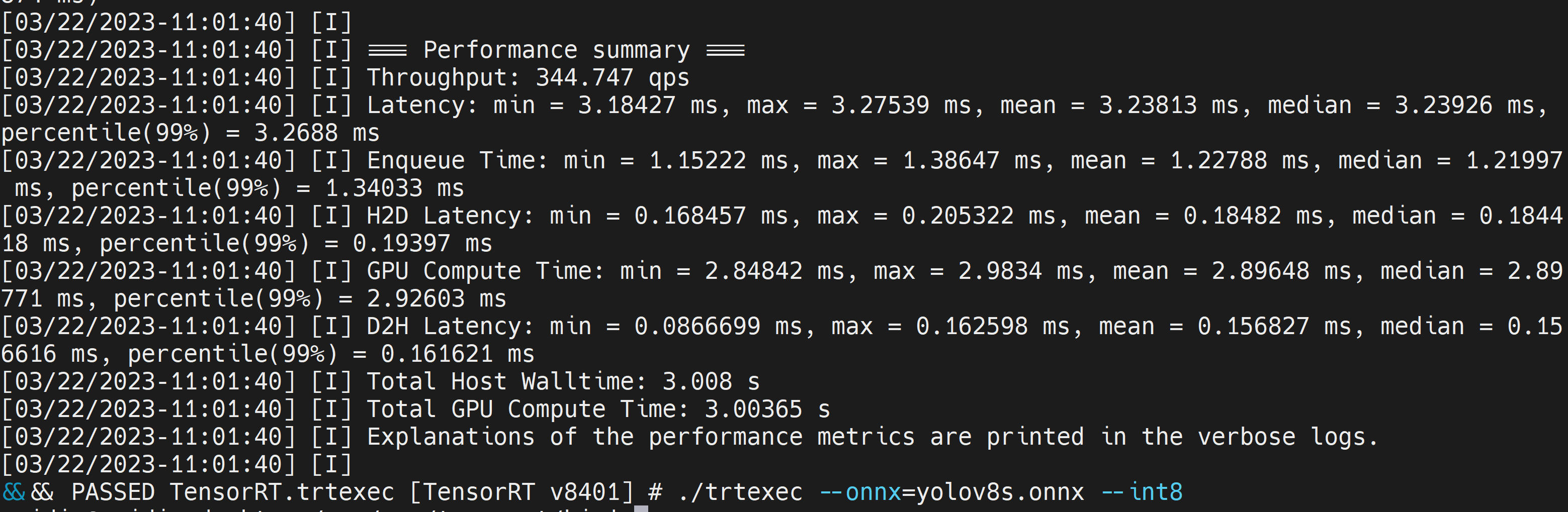
Aqui podemos considerar a latência média como 3.2ms, o que se traduz em 313FPS.
Resultados de Benchmark do YOLOv8
Fizemos benchmarks de desempenho para diferentes modelos YOLOv8 rodando em reComputer J4012, AGX Orin 32GB H01 Kit e reComputer J2021
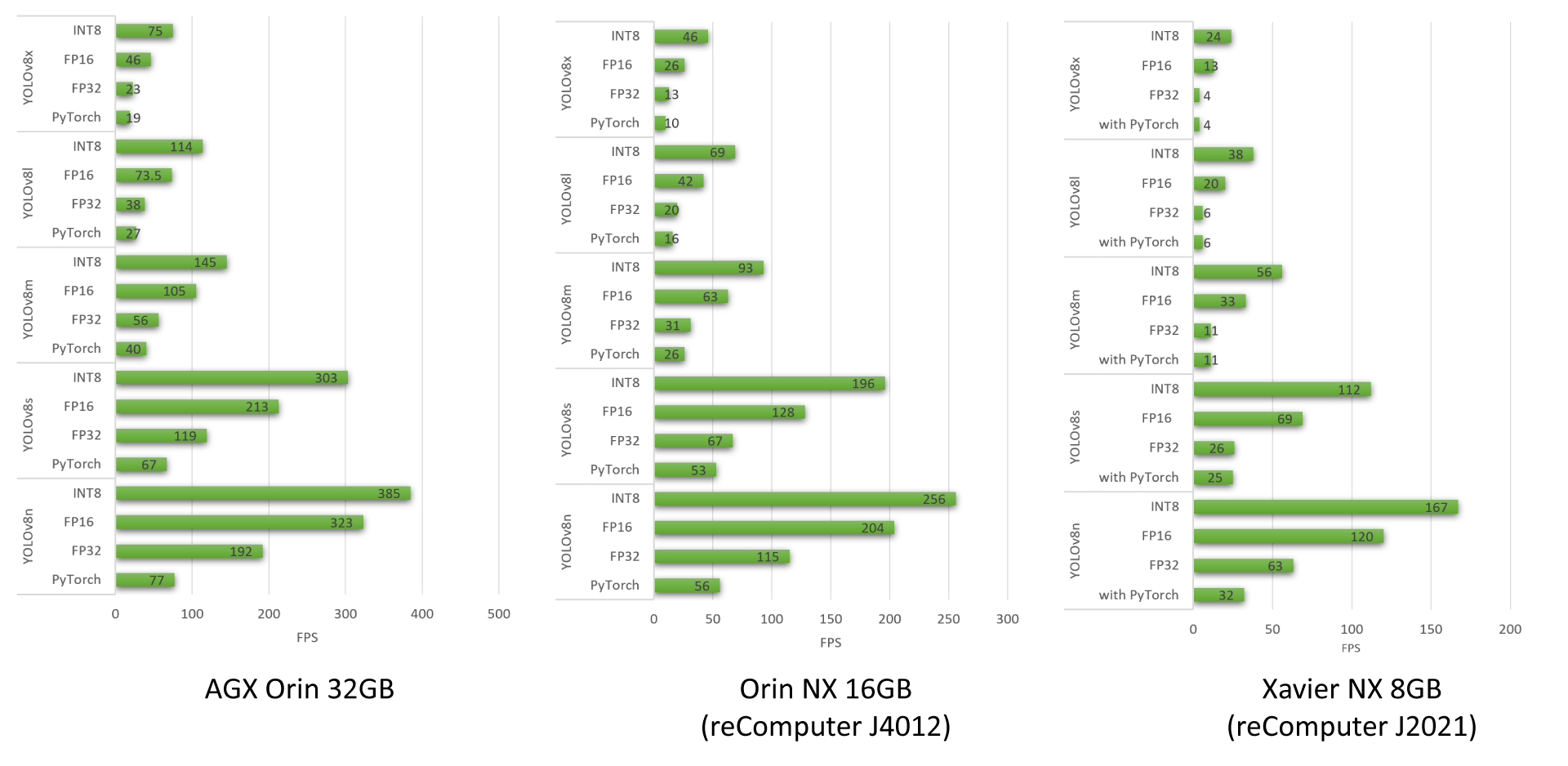
Para saber mais sobre os benchmarks de desempenho que fizemos usando modelos YOLOv8, por favor confira nosso blog.
Benchmarks de Modelo Multistream
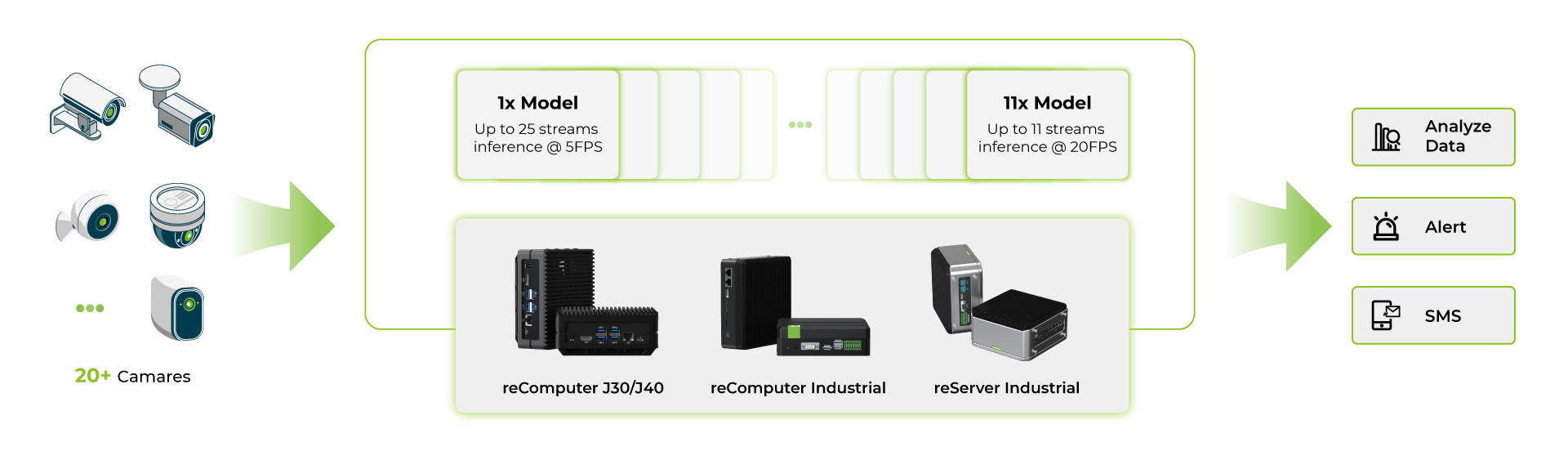
Após executar várias aplicações deepstream em produtos da série reComputer Jetson Orin, fizemos benchmarks com os modelos YOLOv8s.
- Primeiro, usamos um único modelo de IA e executamos múltiplos streams no mesmo modelo de IA
- Segundo, usamos múltiplos modelos de IA e executamos múltiplos streams em múltiplos modelos de IA
Todos esses benchmarks são realizados sob as seguintes condições:
- Entrada de imagem YOLOv8s 640x640
- UI desativada
- Ativar modo de potência máxima e desempenho máximo
A partir desses benchmarks, podemos ver que, para o dispositivo Orin NX 16GB de ponta mais alta com um único modelo YOLOv8s em INT8, você pode usar cerca de 40 câmeras a cerca de 5fps e, com múltiplos modelos YOLOv8s em INT8 para cada stream, você pode usar cerca de 11 câmeras a cerca de 15fps. Para aplicações com múltiplos modelos, o número de câmeras é menor devido às limitações de RAM no dispositivo e cada modelo ocupa uma quantidade substancial de RAM.
Em resumo, ao operar um dispositivo de borda apenas com o modelo YOLOv8 sem aplicações em execução, o Jetson Orin Nano 8GB pode suportar 4-6 streams, enquanto o Jetson Orin NX 16GB pode gerenciar 16-18 streams em capacidade máxima. No entanto, esses números podem diminuir à medida que os recursos de RAM são utilizados em aplicações do mundo real. Portanto, é recomendável usar esses números como diretrizes e realizar seus próprios testes sob suas condições específicas.
Recursos
Suporte Técnico & Discussão de Produto
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.