Implantar YOLOv8 no NVIDIA Jetson usando TensorRT
Este guia da wiki explica como implantar um modelo YOLOv8 na Plataforma NVIDIA Jetson e realizar inferência usando TensorRT. Aqui usamos TensorRT para maximizar o desempenho de inferência na plataforma Jetson.
Diferentes tarefas de visão computacional serão apresentadas aqui, tais como:
- Detecção de Objetos
- Segmentação de Imagem
- Classificação de Imagem
- Estimativa de Pose
- Rastreamento de Objetos

Pré-requisitos
- PC Host Ubuntu (nativo ou VM usando VMware Workstation Player)
- reComputer Jetson ou qualquer outro dispositivo NVIDIA Jetson executando JetPack 5.1.1 ou superior
Esta wiki foi testada e verificada em um reComputer J4012 e reComputer Industrial J4012[https://www.seeedstudio.com/reComputer-Industrial-J4012-p-5684.html] com módulo NVIDIA Jetson orin NX 16GB
Gravar o JetPack no Jetson
Agora você precisa se certificar de que o dispositivo Jetson está gravado com um sistema JetPack. Você pode usar o NVIDIA SDK Manager ou a linha de comando para gravar o JetPack no dispositivo.
Para guias de gravação dos dispositivos Jetson da Seeed, consulte os links abaixo:
- reComputer J1010 | J101
- reComputer J2021 | J202
- reComputer J1020 | A206
- reComputer J4012 | J401
- Placa Carrier A203
- Placa Carrier A205
- Kit Jetson Xavier AGX H01
- Kit Jetson AGX Orin 32GB H01
Certifique-se de gravar o JetPack versão 5.1.1, porque essa é a versão que verificamos para esta wiki
Implantar YOLOV8 no Jetson com Uma Linha de Código
Depois de gravar o dispositivo Jetson com JetPack, você pode simplesmente executar os comandos abaixo para rodar modelos YOLOv8. Isso primeiro irá baixar e instalar os pacotes necessários, dependências, configurar o ambiente e baixar modelos pré-treinados do YOLOv8 para realizar tarefas de detecção de objetos, segmentação de imagem, estimativa de pose e classificação de imagens!
wget files.seeedstudio.com/YOLOv8-Jetson.py && python YOLOv8-Jetson.py
O código-fonte para o script acima pode ser encontrado aqui
Usar modelos pré-treinados
A maneira mais rápida de começar com YOLOv8 é usar modelos pré-treinados fornecidos pelo YOLOv8. No entanto, estes são modelos PyTorch e, portanto, só utilizarão a CPU ao fazer inferência no Jetson. Se você quiser o melhor desempenho desses modelos no Jetson enquanto utiliza a GPU, você pode exportar os modelos PyTorch para TensorRT seguindo esta seção da wiki.
- Detecção de Objetos
- Classificação de Imagem
- Segmentação de Imagem
- Estimativa de Pose
- Rastreamento de Objetos
YOLOv8 oferece 5 pesos de modelos PyTorch pré-treinados para detecção de objetos, treinados no conjunto de dados COCO com tamanho de imagem de entrada 640x640. Você pode encontrá-los abaixo
| Modelo | tamanho (pixels) | mAPval 50-95 | Velocidade CPU ONNX (ms) | Velocidade A100 TensorRT (ms) | parâmetros (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
Referência: https://docs.ultralytics.com/tasks/detect
Você pode escolher e baixar o modelo desejado na tabela acima e executar o comando abaixo para rodar a inferência em uma imagem
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' show=True
Aqui, para o modelo, você pode mudar para yolov8s.pt, yolov8m.pt, yolov8l.pt, yolov8x.pt e ele fará o download do modelo pré-treinado correspondente
Você também pode conectar uma webcam e executar o comando abaixo
yolo detect predict model=yolov8n.pt source='0' show=True
Se você encontrar quaisquer erros ao executar os comandos acima, tente adicionar "device=0" ao final do comando

O acima é executado em um reComputer J4012/ reComputer Industrial J4012 e usa o modelo YOLOv8s treinado com entrada 640x640 e TensorRT com precisão FP16.
YOLOv8 oferece 5 pesos de modelos PyTorch pré-treinados para classificação de imagem, treinados no ImageNet com tamanho de imagem de entrada 224x224. Você pode encontrá-los abaixo
| Modelo | tamanho (pixels) | acc top1 | acc top5 | Velocidade CPU ONNX (ms) | Velocidade A100 TensorRT (ms) | parâmetros (M) | FLOPs (B) em 640 |
|---|---|---|---|---|---|---|---|
| YOLOv8n-cls | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
| YOLOv8s-cls | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
| YOLOv8m-cls | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
| YOLOv8l-cls | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
| YOLOv8x-cls | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
Referência: https://docs.ultralytics.com/tasks/classify
Você pode escolher o modelo desejado e executar o comando abaixo para rodar a inferência em uma imagem
yolo classify predict model=yolov8n-cls.pt source='https://ultralytics.com/images/bus.jpg' show=True
Aqui, para o modelo, você pode mudar para yolov8s-cls.pt, yolov8m-cls.pt, yolov8l-cls.pt, yolov8x-cls.pt e ele fará o download do modelo pré-treinado correspondente
Você também pode conectar uma webcam e executar o comando abaixo
yolo classify predict model=yolov8n-cls.pt source='0' show=True
Se você encontrar quaisquer erros ao executar os comandos acima, tente adicionar "device=0" ao final do comando
(atualizar com inferência 224)
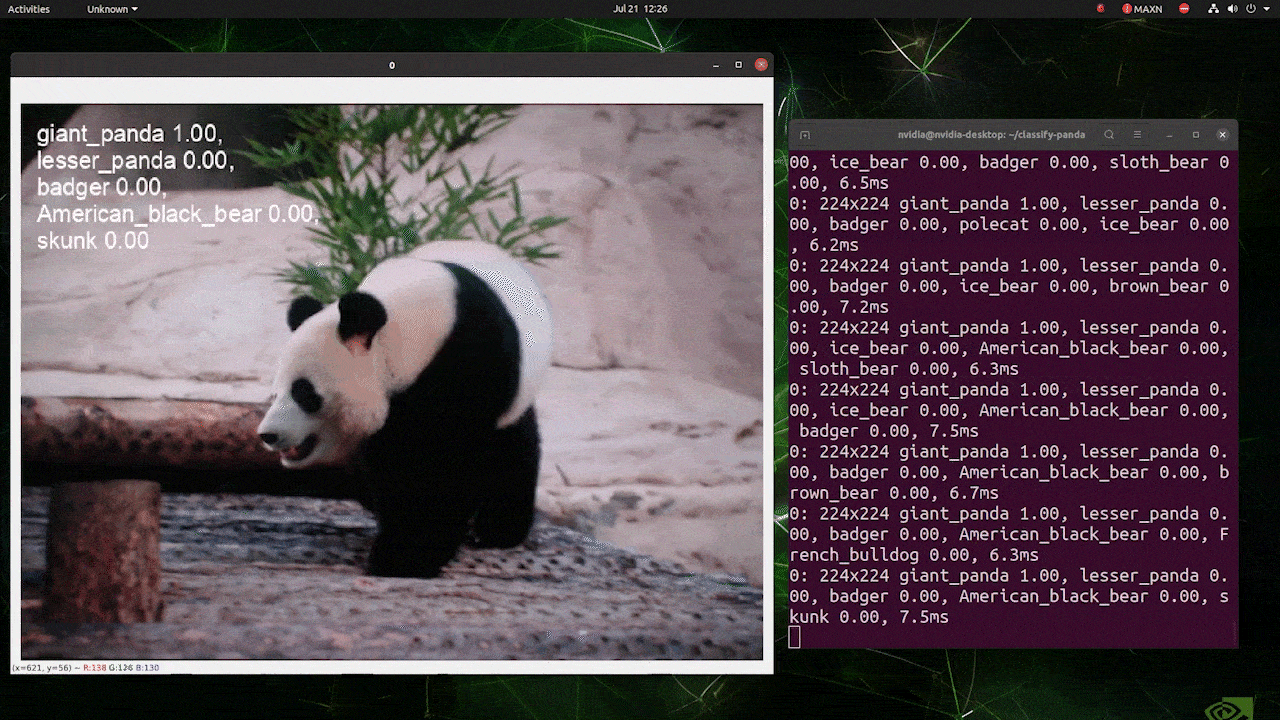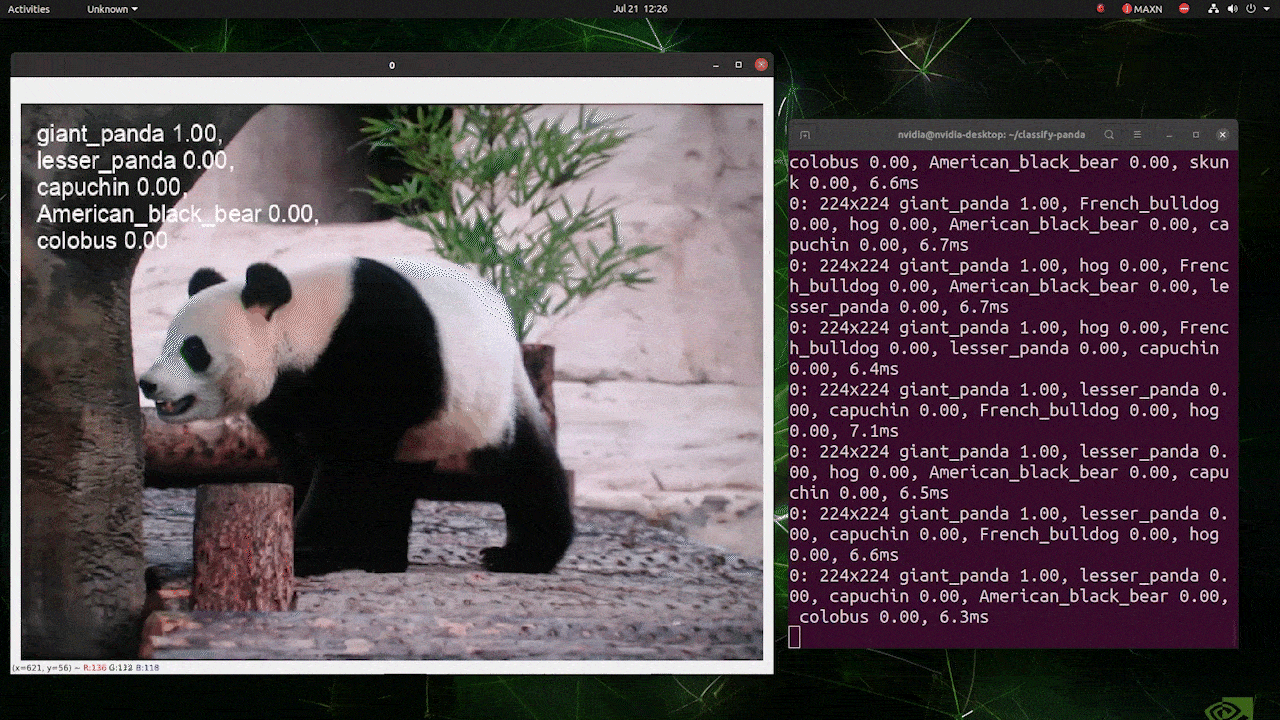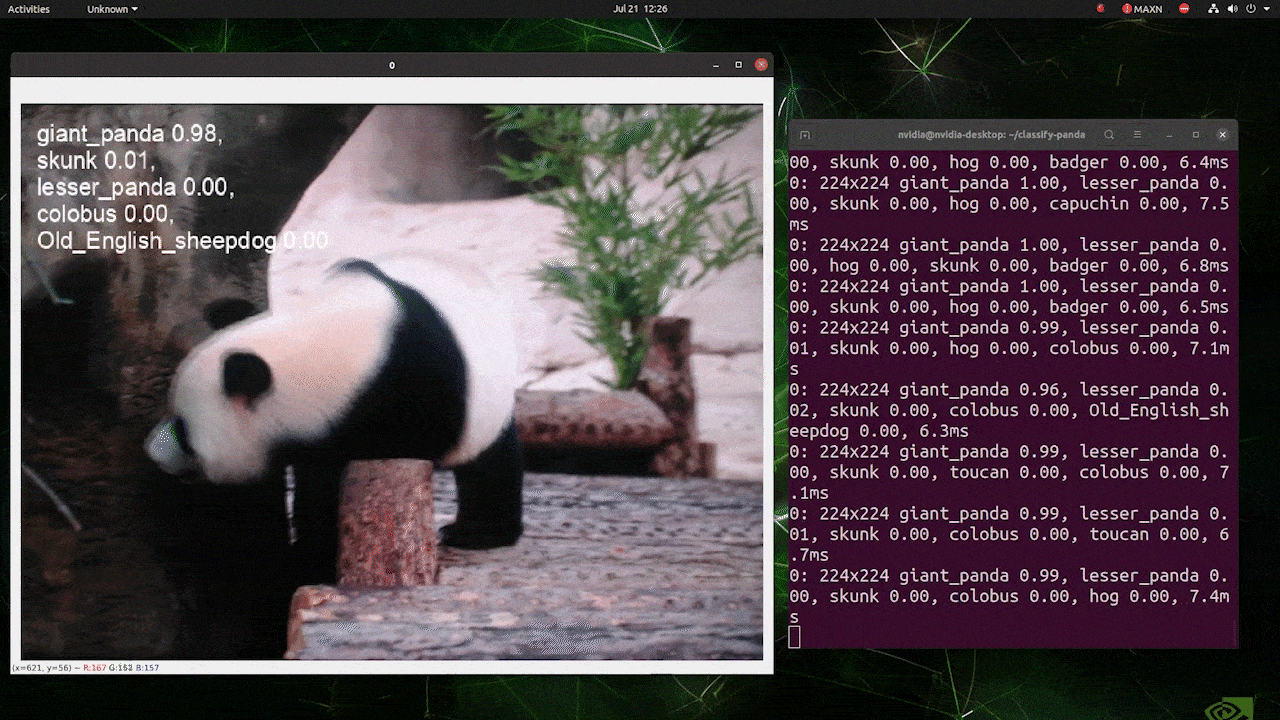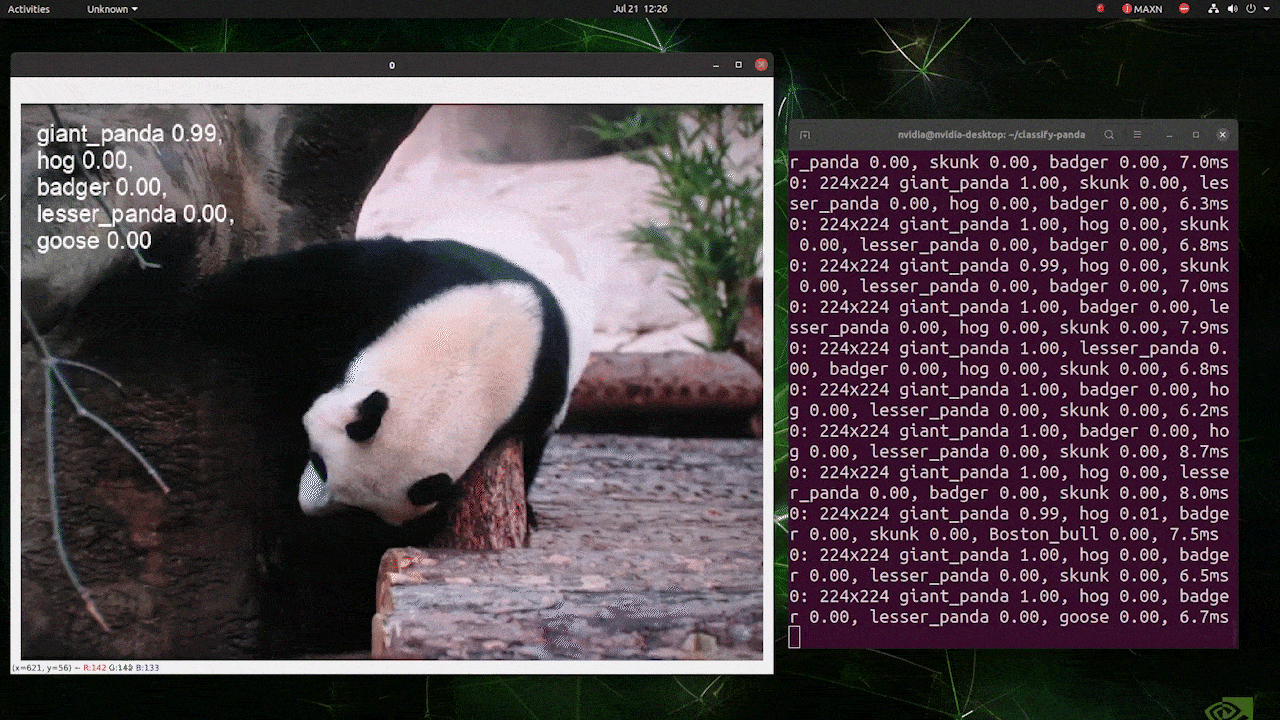
O acima é executado em um reComputer J4012/ reComputer Industrial J4012 e usa o modelo YOLOv8s-cls treinado com entrada 224x224 e TensorRT com precisão FP16. Além disso, certifique-se de passar o argumento imgsz=224 dentro do comando de inferência com exports TensorRT porque o mecanismo de inferência aceita tamanho de imagem 640 por padrão ao usar modelos TensorRT.
YOLOv8 oferece 5 pesos de modelos PyTorch pré-treinados para segmentação de imagem, treinados no conjunto de dados COCO com tamanho de imagem de entrada 640x640. Você pode encontrá-los abaixo
| Modelo | tamanho (pixels) | mAPbox 50-95 | mAPmask 50-95 | Velocidade CPU ONNX (ms) | Velocidade A100 TensorRT (ms) | parâmetros (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-seg | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
| YOLOv8s-seg | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
| YOLOv8m-seg | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
| YOLOv8l-seg | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
| YOLOv8x-seg | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
Referência: https://docs.ultralytics.com/tasks/segment
Você pode escolher o modelo desejado e executar o comando abaixo para rodar a inferência em uma imagem
yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg' show=True
Aqui, para o modelo, você pode mudar para yolov8s-seg.pt, yolov8m-seg.pt, yolov8l-seg.pt, yolov8x-seg.pt e ele fará o download do modelo pré-treinado relevante
Você também pode conectar uma webcam e executar o comando abaixo
yolo segment predict model=yolov8n-seg.pt source='0' show=True
Se você encontrar algum erro ao executar os comandos acima, tente adicionar "device=0" ao final do comando

O exemplo acima é executado em um reComputer J4012/ reComputer Industrial J4012 e usa o modelo YOLOv8s-seg treinado com entrada 640x640 e usando precisão TensorRT FP16.
YOLOv8 oferece 6 pesos de modelos PyTorch pré-treinados para estimativa de pose, treinados no conjunto de dados de keypoints COCO com tamanho de imagem de entrada 640x640. Você pode encontrá-los abaixo
| Model | size (pixels) | mAPpose 50-95 | mAPpose 50 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-pose | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
| YOLOv8s-pose | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
| YOLOv8m-pose | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
| YOLOv8l-pose | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
| YOLOv8x-pose | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
| YOLOv8x-pose-p6 | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
Referência: https://docs.ultralytics.com/tasks/pose
Você pode escolher o modelo desejado e executar o comando abaixo para rodar a inferência em uma imagem
yolo pose predict model=yolov8n-pose.pt source='https://ultralytics.com/images/bus.jpg'
Aqui, para o modelo, você pode mudar para yolov8s-pose.pt, yolov8m-pose.pt, yolov8l-pose.pt, yolov8x-pose.pt, yolov8x-pose-p6 e ele fará o download do modelo pré-treinado relevante
Você também pode conectar uma webcam e executar o comando abaixo
yolo pose predict model=yolov8n-pose.pt source='0'
Se você encontrar algum erro ao executar os comandos acima, tente adicionar "device=0" ao final do comando

O rastreamento de objetos é uma tarefa que envolve identificar a localização e a classe dos objetos e, em seguida, atribuir um ID exclusivo a essa detecção em fluxos de vídeo.
Basicamente, a saída do rastreamento de objetos é a mesma da detecção de objetos com um ID de objeto adicional.
Referência: https://docs.ultralytics.com/modes/track
Você pode escolher o modelo desejado com base em detecção de objetos/ segmentação de imagem e executar o comando abaixo para rodar a inferência em um vídeo
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc"
Aqui, para o modelo, você pode mudar para yolov8n.pt, yolov8s.pt, yolov8m.pt, yolov8l.pt, yolov8x.pt, yolov8n-seg.pt, yolov8s-seg.pt, yolov8m-seg.pt, yolov8l-seg.pt, yolov8x-seg.pt, e ele fará o download do modelo pré-treinado relevante
Você também pode conectar uma webcam e executar o comando abaixo
yolo track model=yolov8n.pt source="0"
Se você encontrar algum erro ao executar os comandos acima, tente adicionar "device=0" ao final do comando

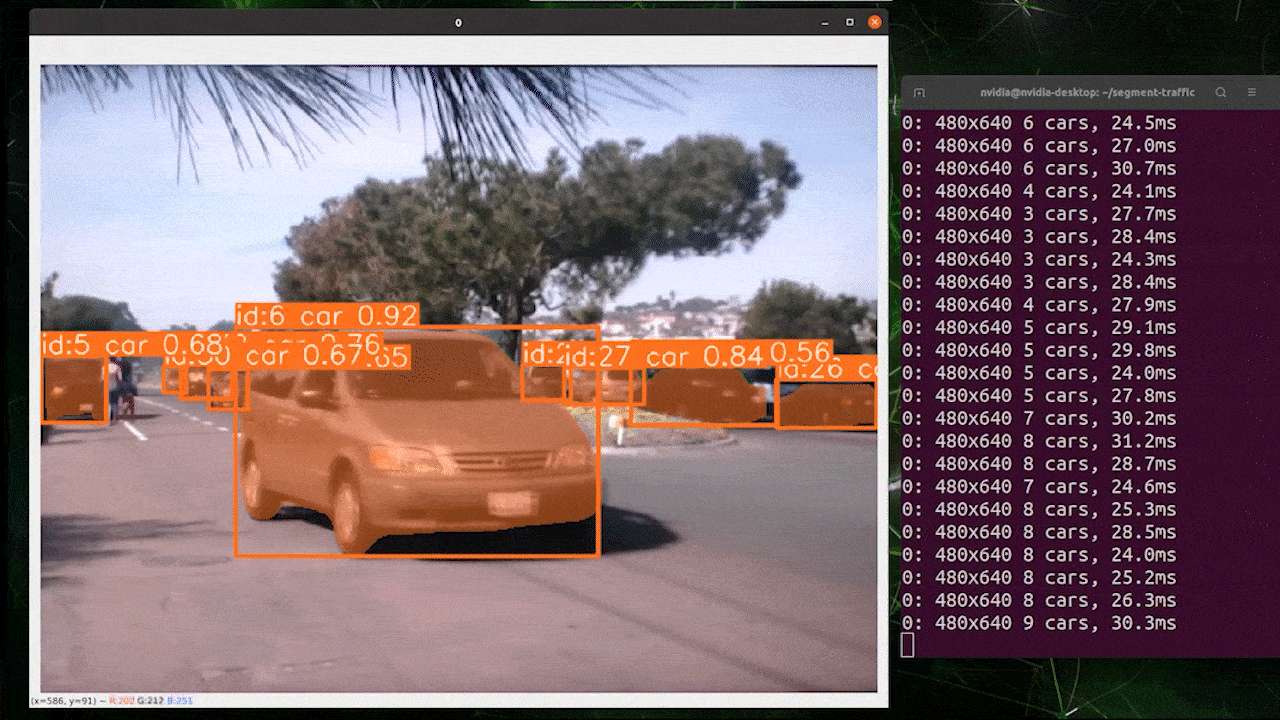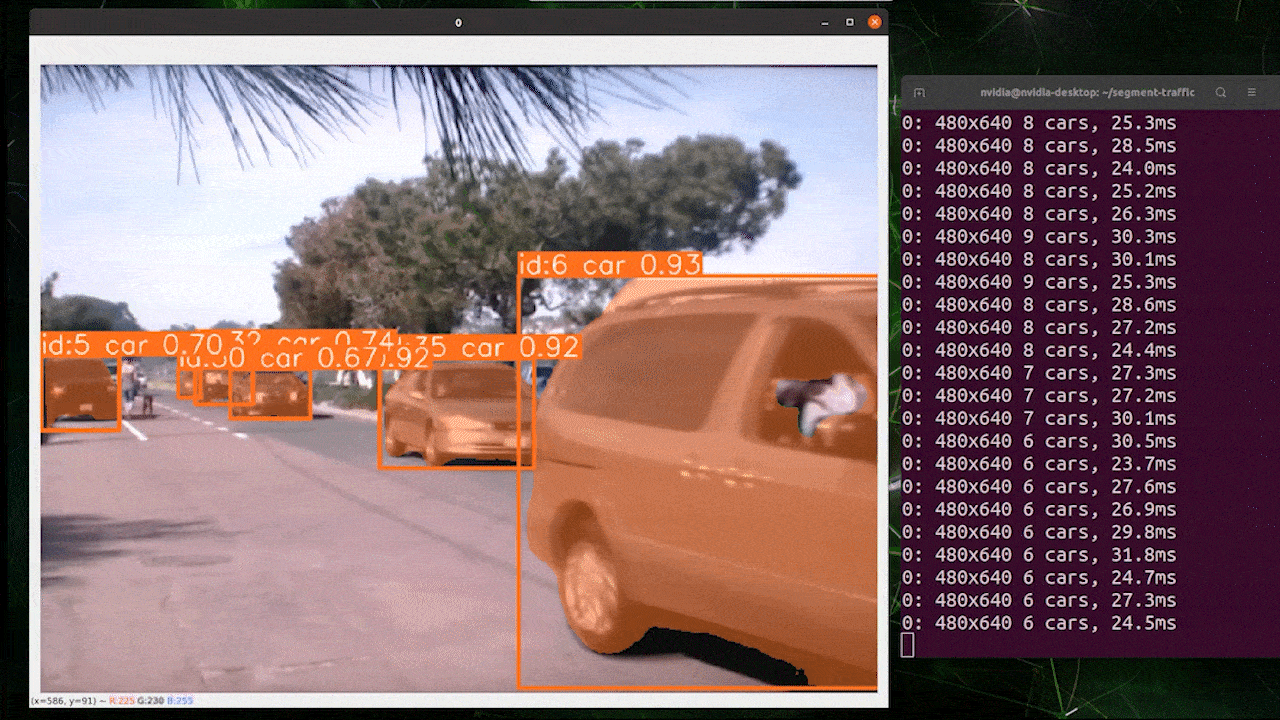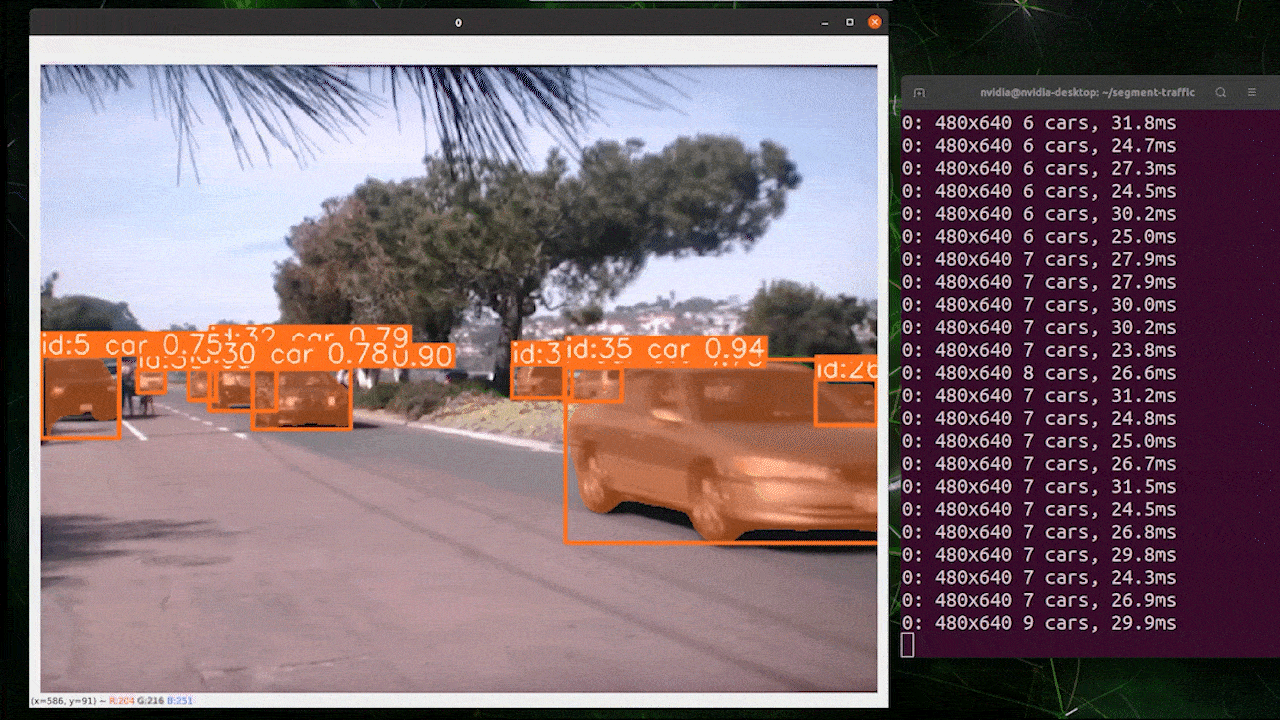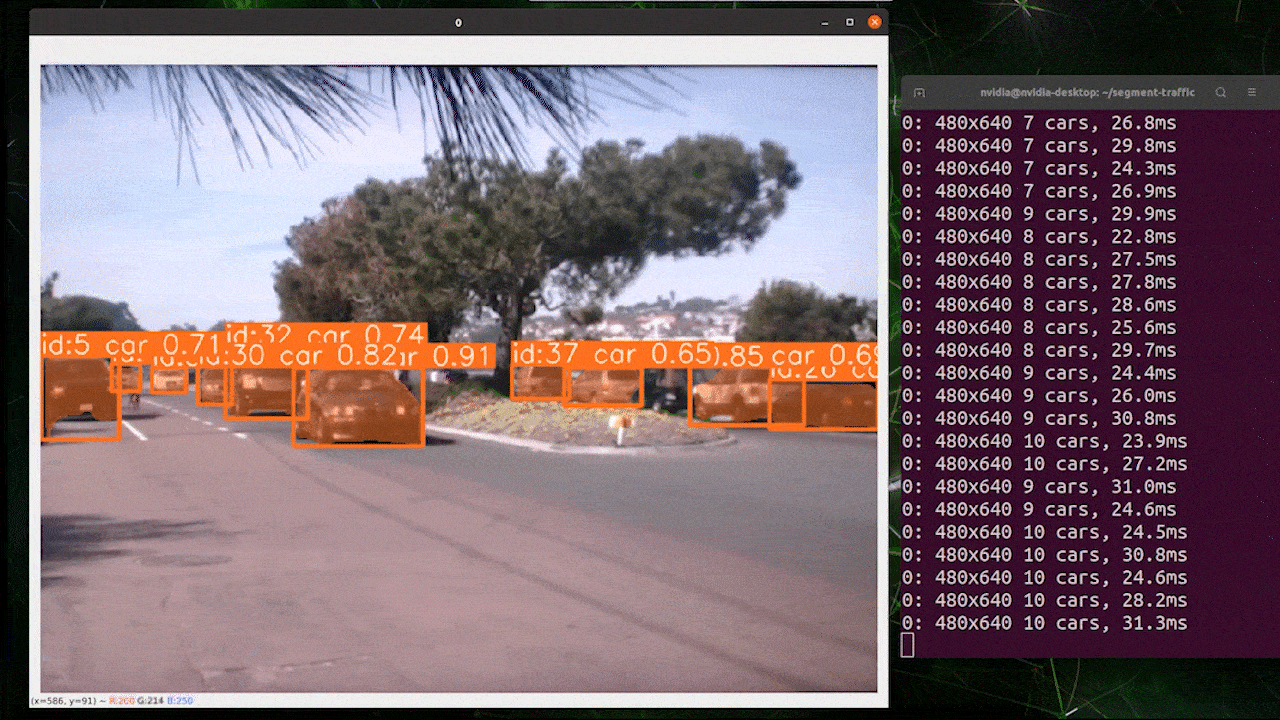
Use TensorRT para Melhorar a Velocidade de Inferência
Como mencionamos antes, se você quiser melhorar a velocidade de inferência no Jetson executando modelos YOLOv8, primeiro você precisa converter os modelos PyTorch originais em modelos TensorRT.
Siga as etapas abaixo para converter modelos YOLOv8 PyTorch em modelos TensorRT.
Isso funciona para todas as quatro tarefas de visão computacional que mencionamos antes
- Etapa 1. Execute o comando de exportação especificando o caminho do modelo
yolo export model=<path_to_pt_file> format=engine device=0
Por exemplo:
yolo export model=yolov8n.pt format=engine device=0
Se você encontrar um erro sobre cmake, pode ignorá-lo. Por favor, seja paciente até que a exportação para TensorRT seja concluída. Pode levar alguns minutos
Depois que o arquivo de modelo TensorRT (.engine) for criado, você verá a saída a seguir
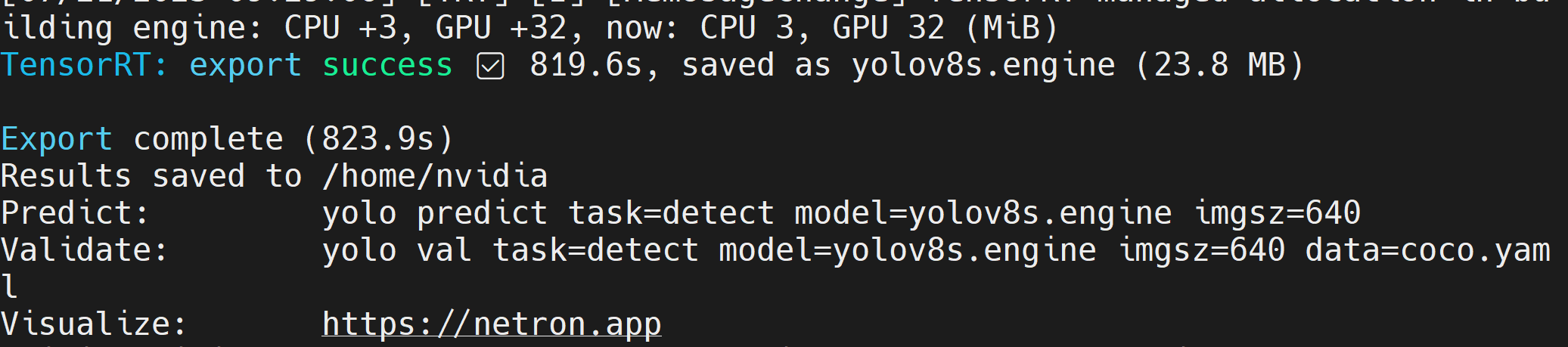
- Etapa 2. Se você quiser passar argumentos adicionais, pode fazê-lo seguindo a tabela abaixo
| Key | Value | Description |
|---|---|---|
| imgsz | 640 | Tamanho da imagem como escalar ou lista (h, w), ou seja, (640, 480) |
| half | False | Quantização FP16 |
| dynamic | False | Eixos dinâmicos |
| simplify | False | Simplificar modelo |
| workspace | 4 | Tamanho do workspace (GB) |
Por exemplo, se você quiser converter seu modelo PyTorch em um modelo TensorRT com quantização FP16, execute assim
yolo export model=yolov8n.pt format=engine half=True device=0
Depois que o modelo for exportado com sucesso, você pode simplesmente substituir esse modelo pelo argumento model= dentro do comando predict do yolo ao executar todas as 4 tarefas de detecção, classificação, segmentação e estimativa de pose.
Por exemplo, com detecção de objetos:
yolo detect predict model=yolov8n.engine source='0' show=True
Traga Seu Próprio Modelo de IA
Coleta e Rotulagem de Dados
Se você tem uma aplicação específica de IA e quer trazer seu próprio modelo de IA que seja adequado para sua aplicação, você pode coletar seu próprio conjunto de dados, rotulá-los e então treinar usando YOLOv8.
Se você não quiser coletar dados por conta própria, também pode escolher conjuntos de dados públicos que já estão disponíveis. Você pode baixar vários conjuntos de dados disponíveis publicamente, como o conjunto de dados COCO, conjunto de dados Pascal VOC e muitos outros. O Roboflow Universe é uma plataforma recomendada que oferece uma grande variedade de conjuntos de dados e possui mais de 90.000 conjuntos de dados com mais de 66 milhões de imagens disponíveis para criar modelos de visão computacional. Além disso, você pode simplesmente pesquisar conjuntos de dados de código aberto no Google e escolher entre uma variedade de conjuntos de dados disponíveis.
Se você tiver seu próprio conjunto de dados e quiser anotar as imagens, recomendamos que use a ferramenta de anotação fornecida pelo Roboflow. Por favor, siga esta parte do wiki para saber mais sobre isso. Você também pode seguir este guia do Roboflow sobre anotação.
Treinamento
Aqui temos 3 métodos para treinar um modelo.
-
A primeira maneira seria usar o Ultralytics HUB. Você pode integrar facilmente o Roboflow ao Ultralytics HUB para que todos os seus projetos do Roboflow fiquem prontamente disponíveis para treinamento. Aqui é oferecido um notebook do Google Colab para iniciar facilmente o processo de treinamento e também visualizar o progresso do treinamento em tempo real.
-
A segunda maneira seria usar um workspace do Google Colab criado por nós para facilitar o processo de treinamento. Aqui usamos a Roboflow API para baixar o conjunto de dados a partir do projeto do Roboflow.
-
A terceira maneira seria usar um PC local para o processo de treinamento. Aqui você precisa se certificar de que possui uma GPU suficientemente potente e também precisa baixar o conjunto de dados manualmente.
- Ultralytics HUB + Roboflow + Google Colab
- Roboflow + Google Colab
- Roboflow + Local PC
Aqui usamos o Ultralytics HUB para carregar o projeto do Roboflow e depois treinar no Google Colab.
-
Passo 1. Visite este URL e registre-se para uma conta Ultralytics
-
Passo 2. Depois de fazer login com a conta recém‑criada, você verá o seguinte painel
-
Passo 3. Visite este URL e registre-se para uma conta Roboflow
-
Passo 4. Depois de fazer login com a conta recém‑criada, você verá o seguinte painel
-
Passo 5. Crie um novo workspace e crie um novo projeto dentro do workspace seguindo este guia wiki que preparamos. Você também pode ver aqui para aprender mais na documentação oficial do Roboflow.
-
Passo 6. Depois que você tiver alguns projetos dentro do seu workspace, ele ficará como mostrado abaixo
- Passo 7. Vá para Settings e clique em Roboflow API
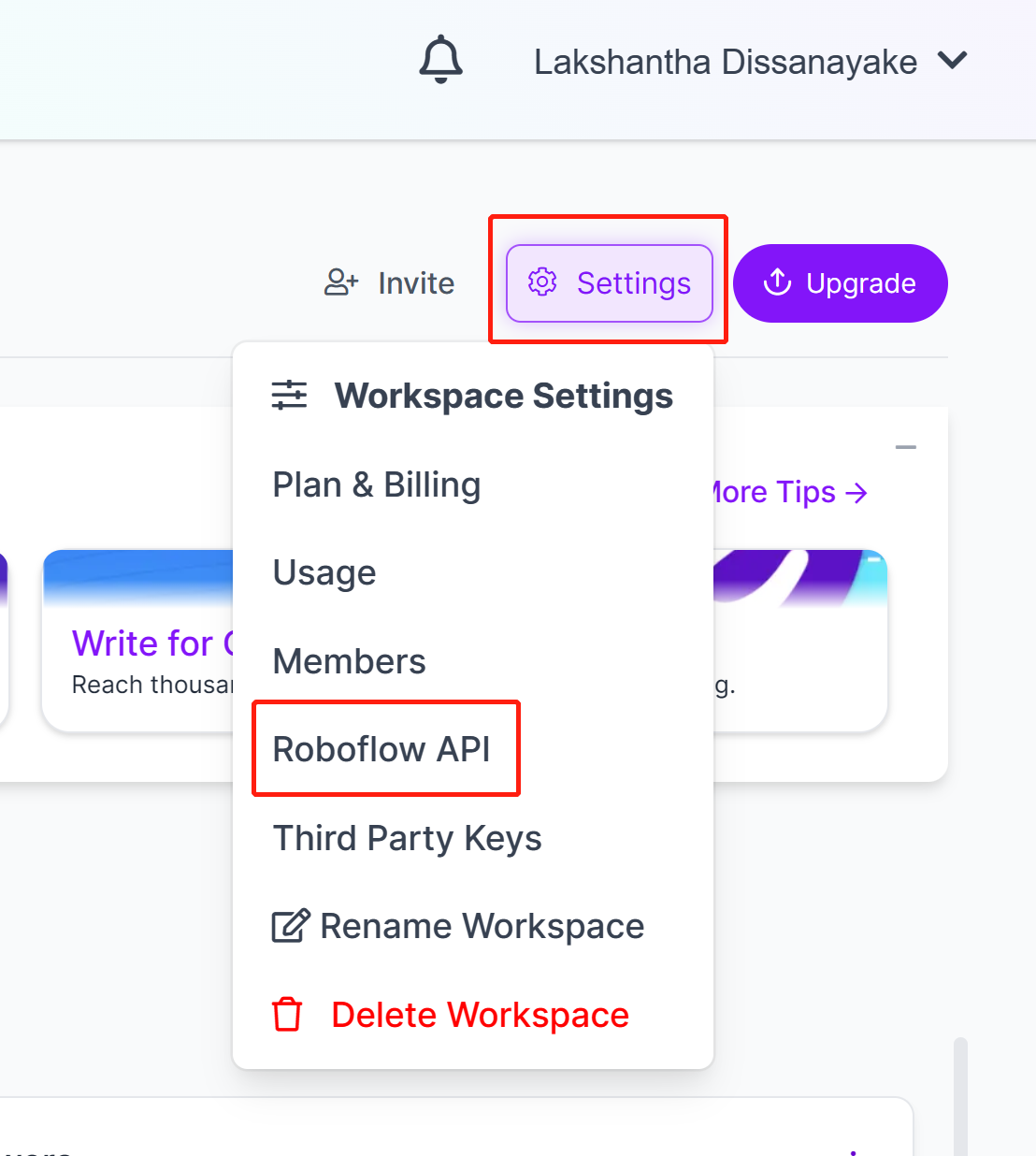
- Passo 8. Clique no botão copy para copiar a Private API Key
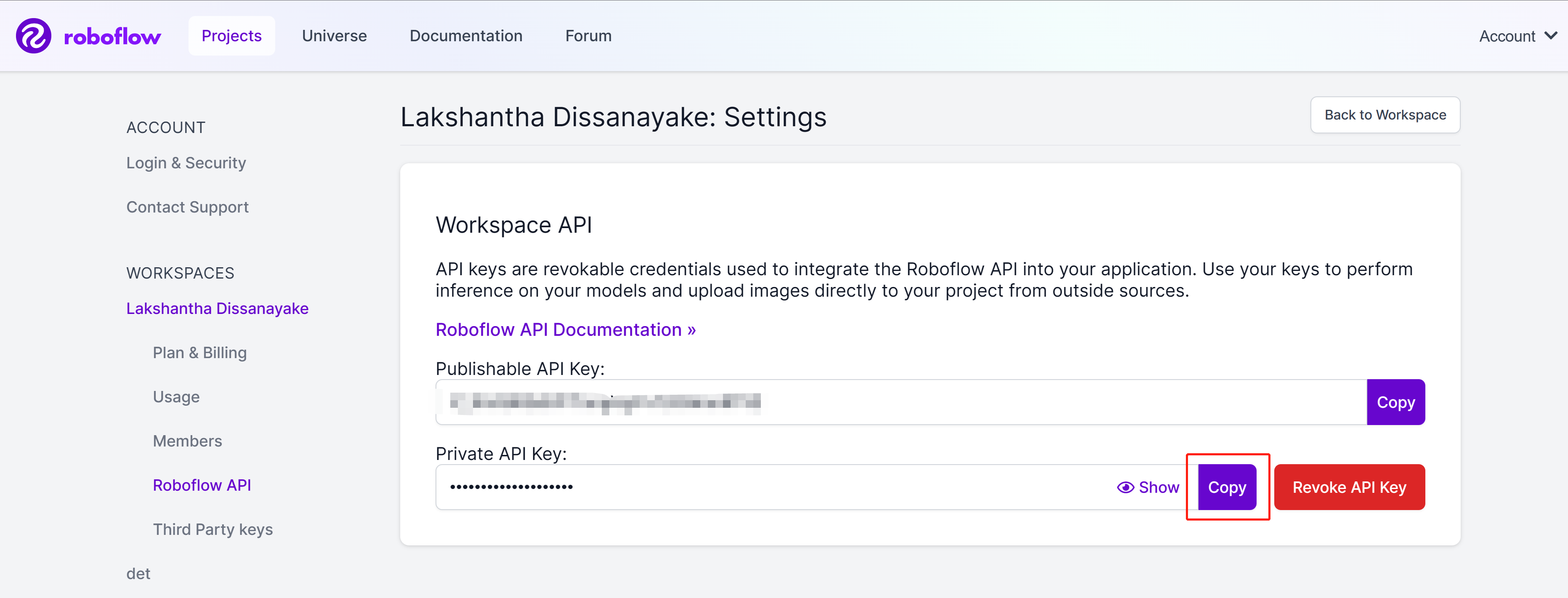
- Passo 9. Volte para o painel do Ultralytics HUB, clique em Integrations, cole a API Key que copiamos antes na coluna vazia e clique em Add
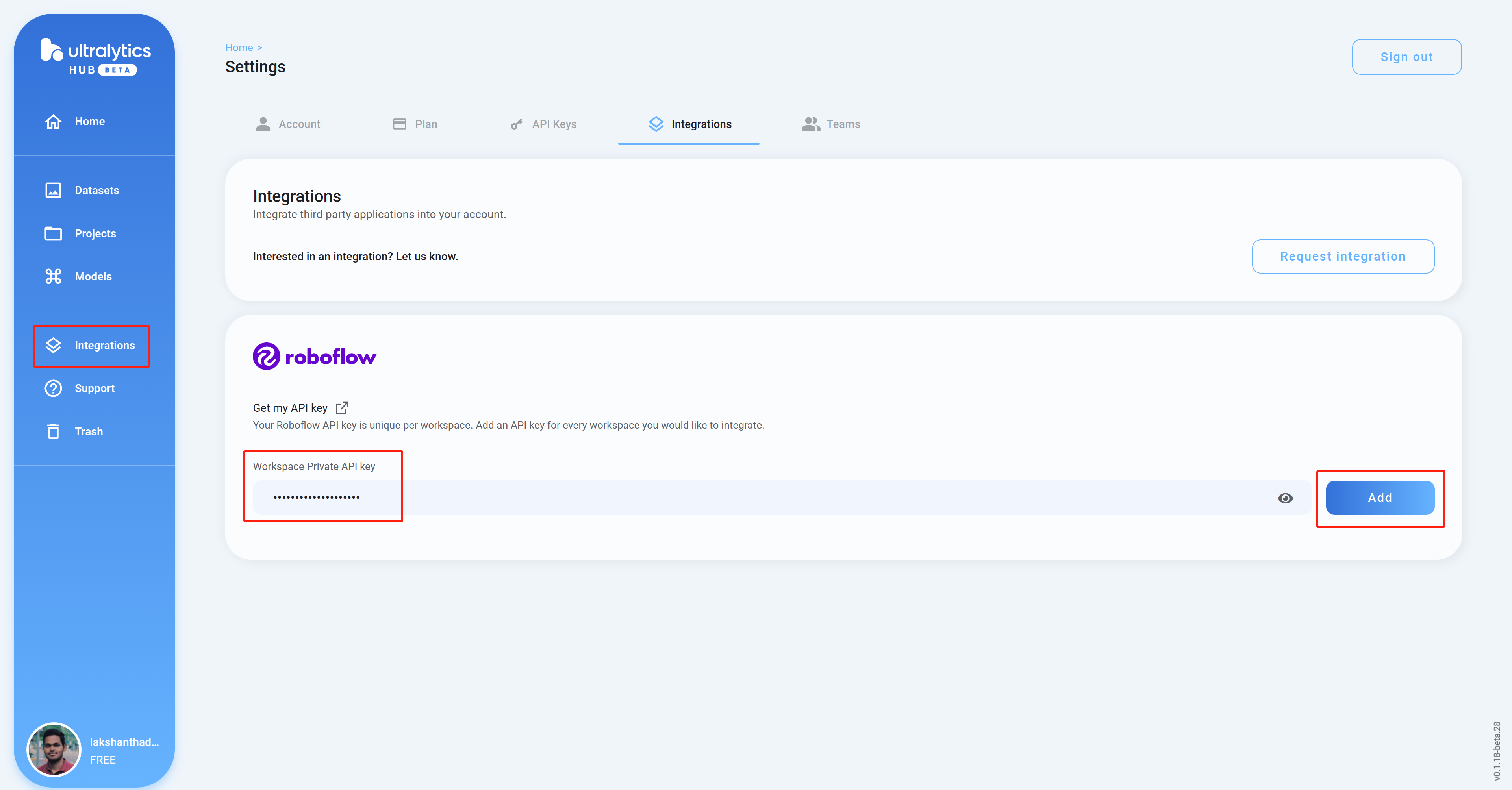
- Passo 10 Se você vir o nome do seu workspace listado, isso significa que a integração foi bem‑sucedida
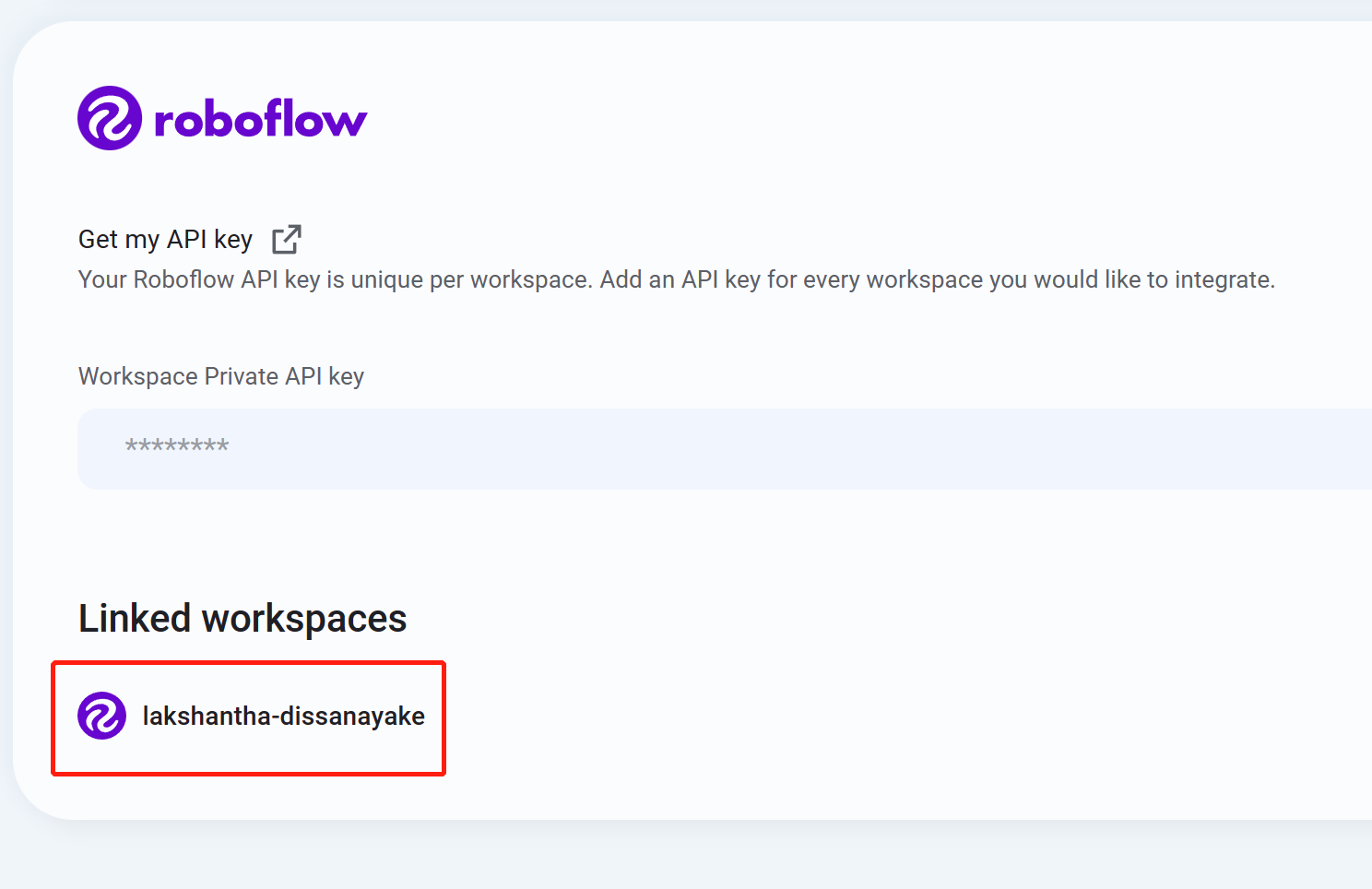
- Passo 11 Navegue até Datasets e você verá todos os seus projetos do Roboflow aqui
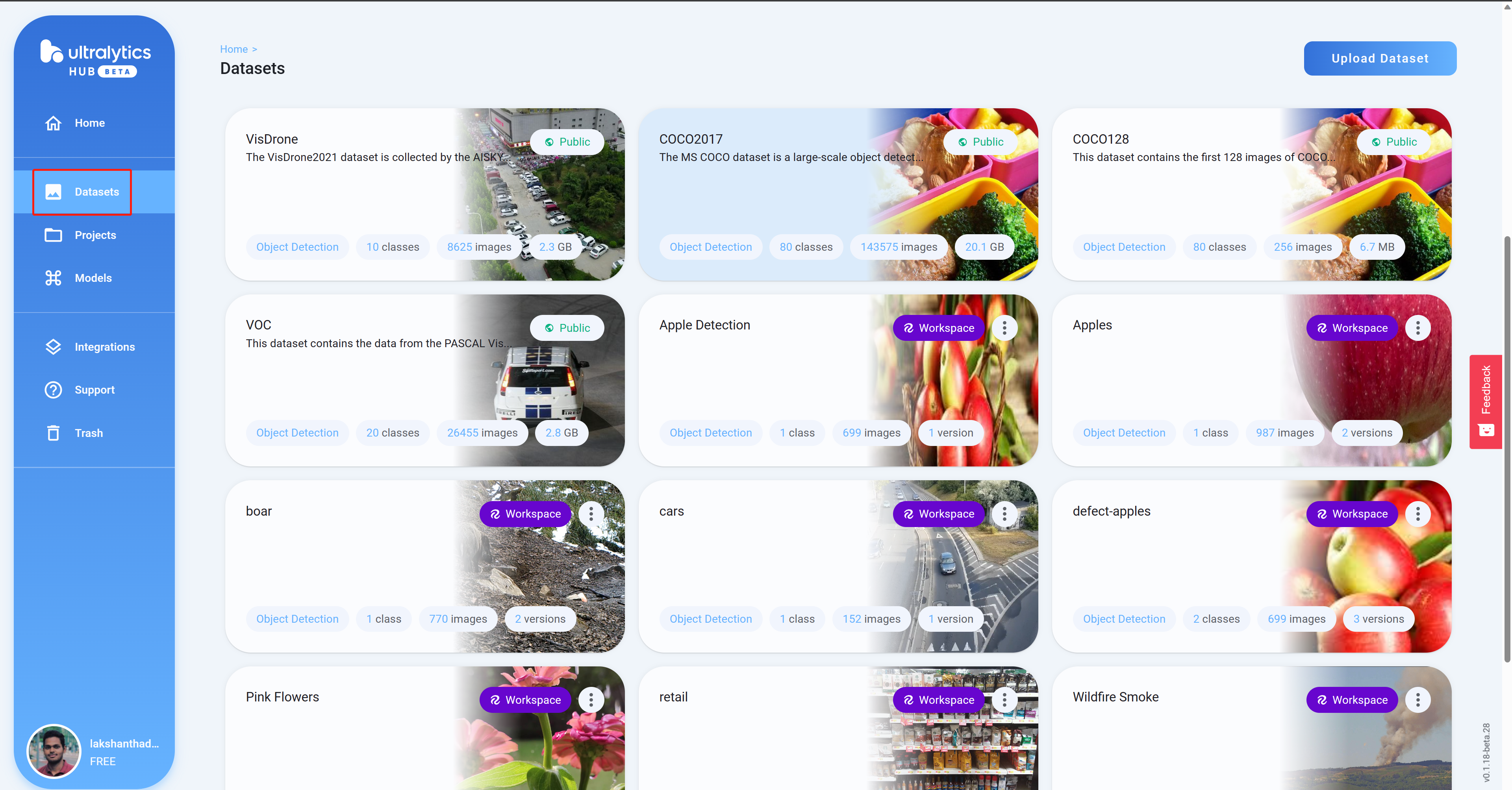
- Passo 12 Clique em um projeto para verificar mais detalhes sobre o conjunto de dados. Aqui selecionei um conjunto de dados que pode detectar maçãs saudáveis e danificadas
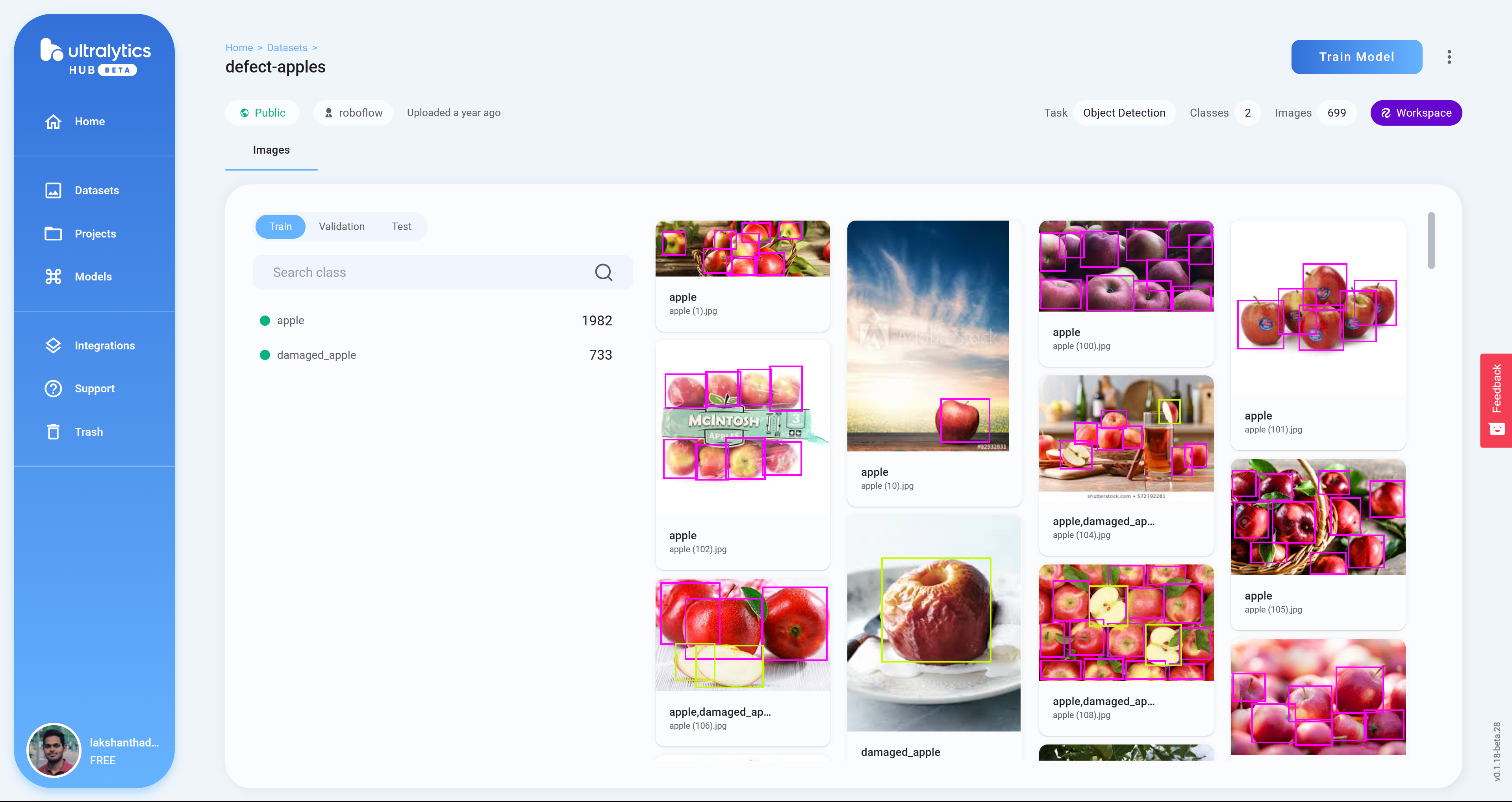
- Passo 13 Clique em Train Model
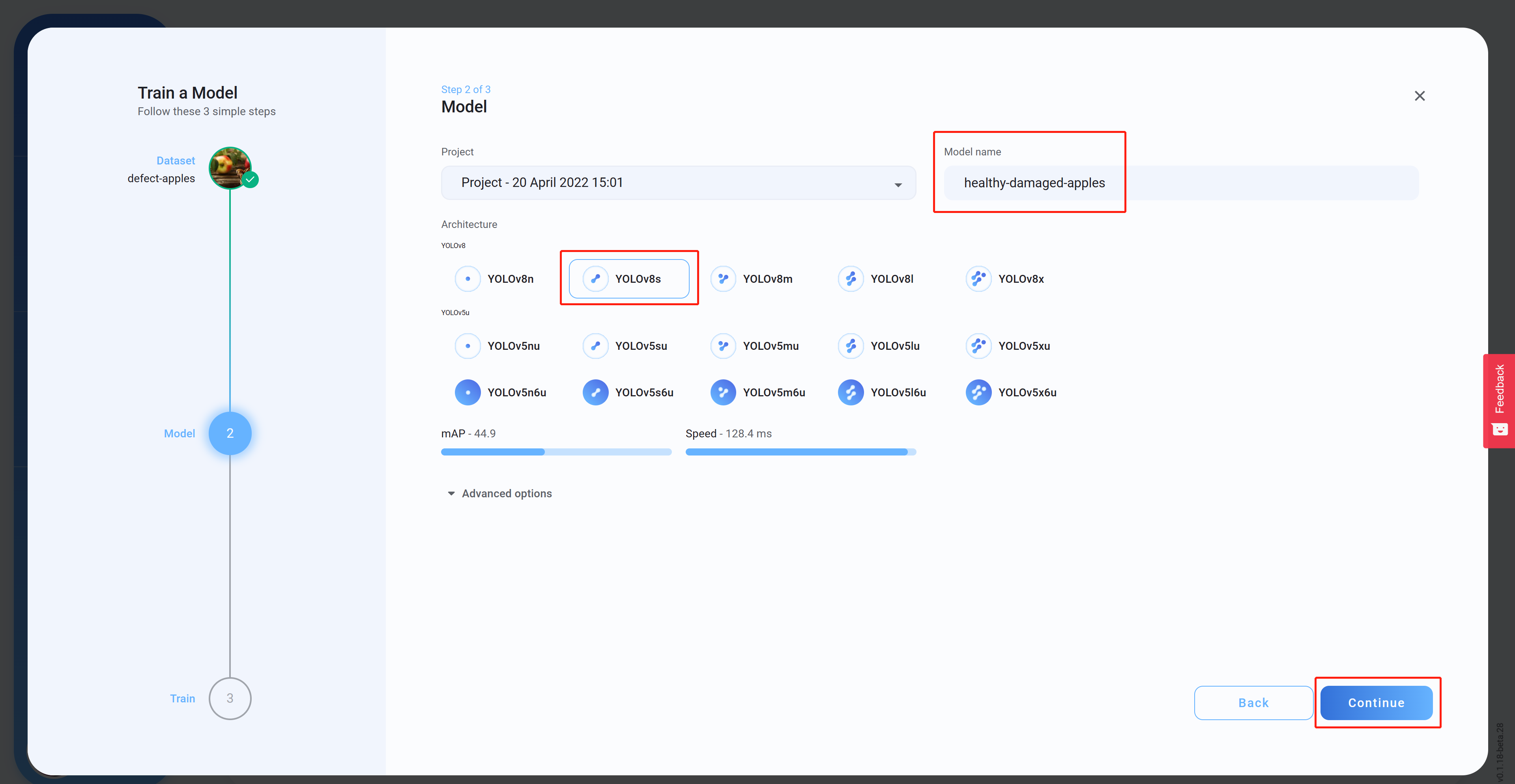
- Passo 14 Selecione a Architecture, defina um Model name (optional) e clique em Continue. Aqui selecionamos YOLOv8s como arquitetura do modelo
- Passo 15 Em Advanced options, configure as definições de acordo com a sua preferência, copie e cole o código do Colab (ele será colado depois no workspace do Colab) e clique em Open Google Colab
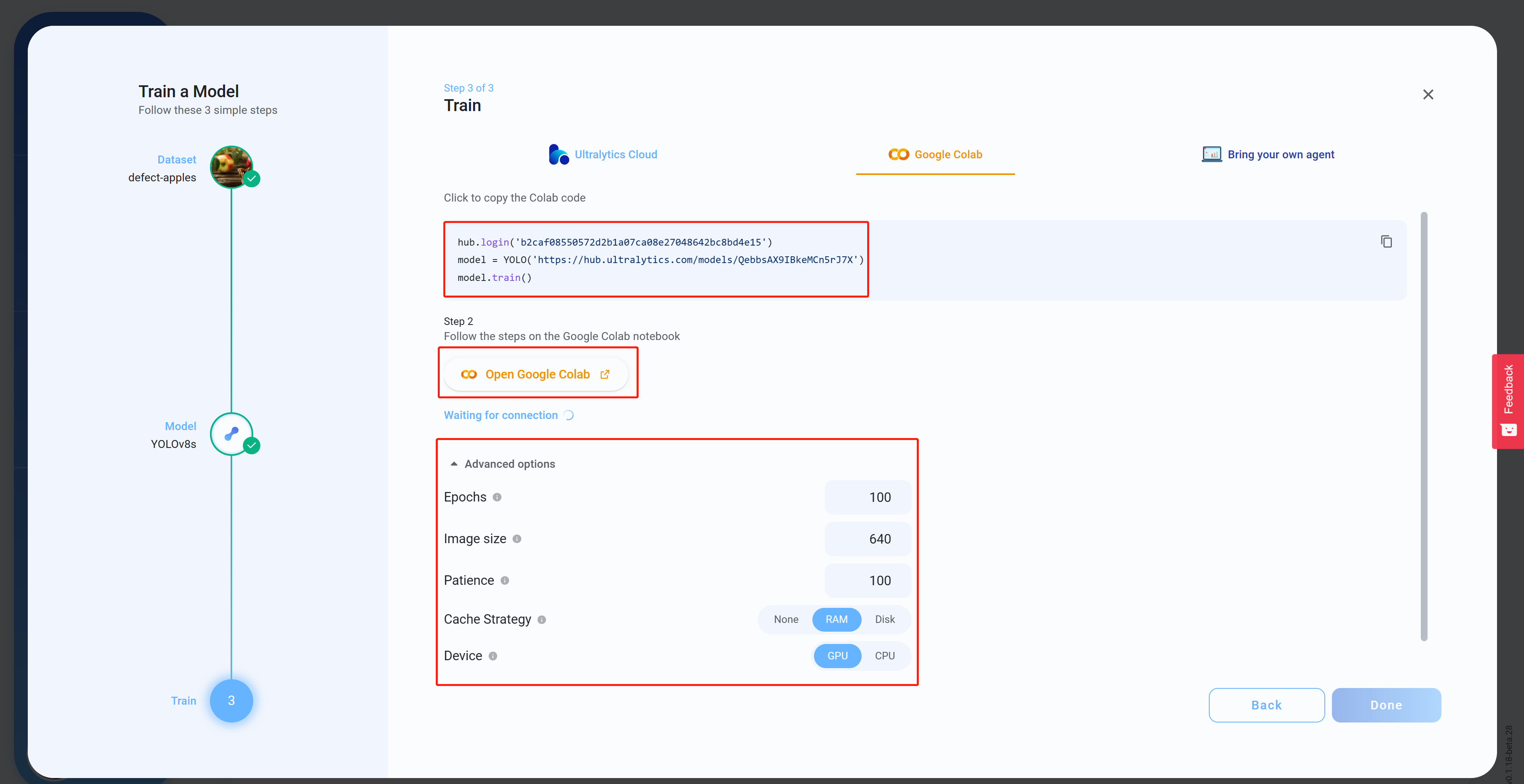
- Passo 16 Faça login na sua conta Google se ainda não tiver feito
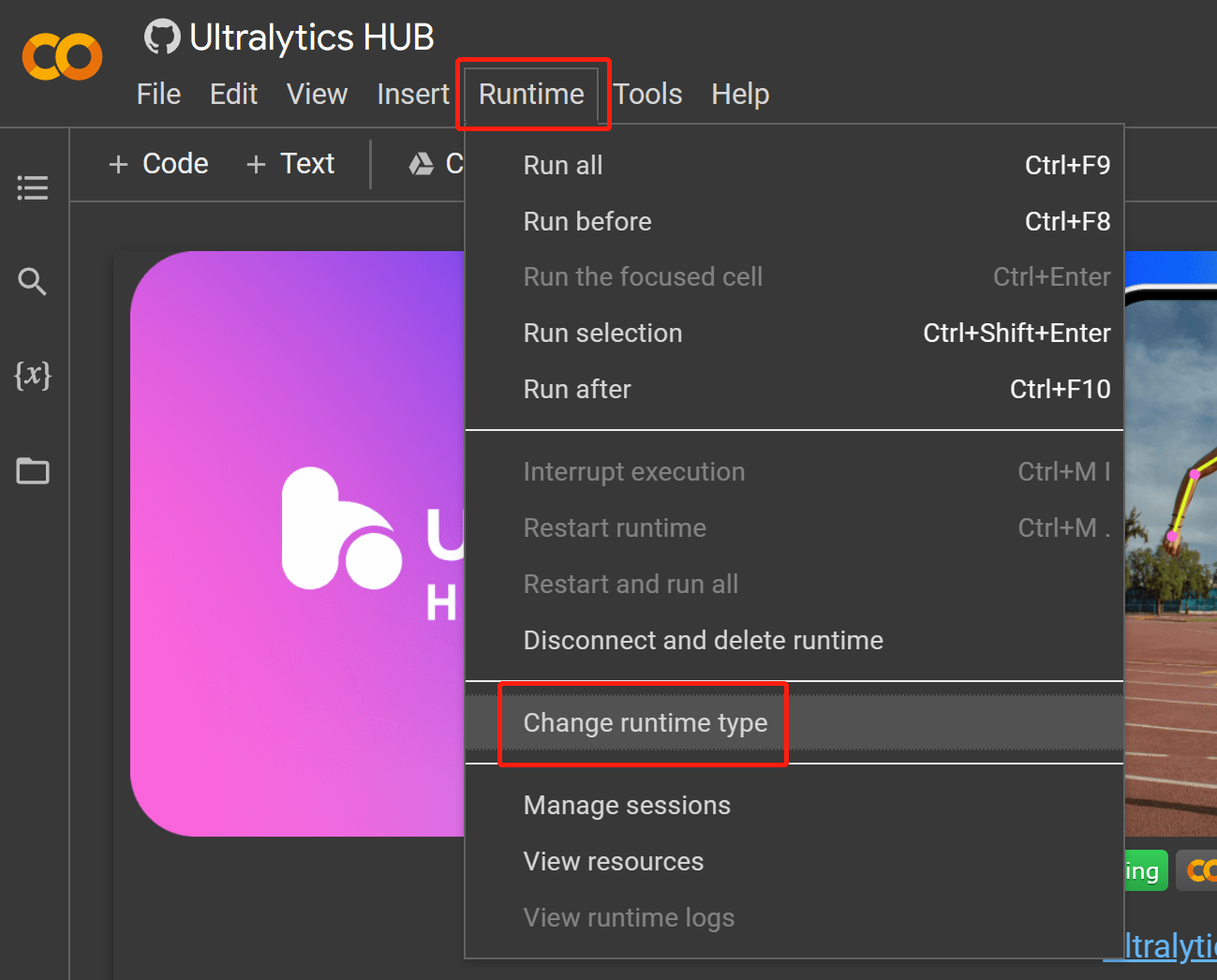
- Passo 17 Navegue até
Runtime > Change runtime type
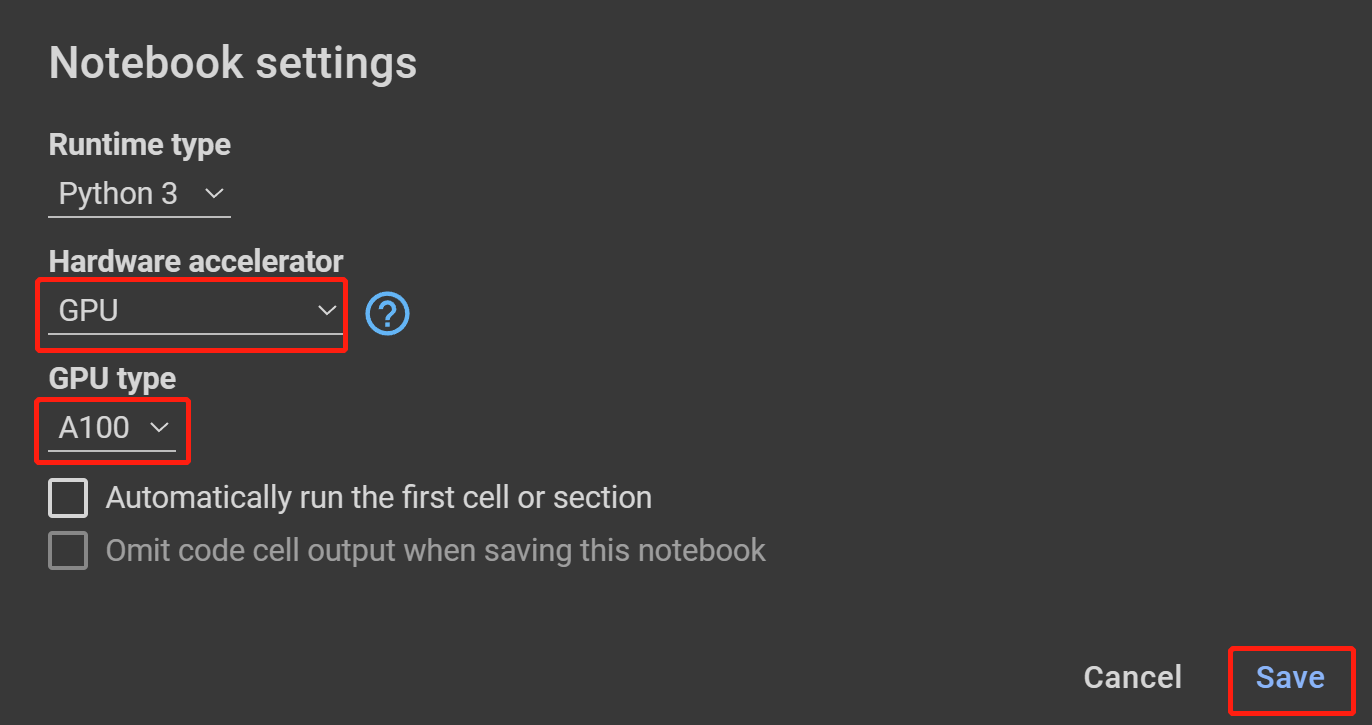
- Passo 18 Selecione GPU em Hardware accelerator, o mais alto disponível em GPU type e clique em Save
- Passo 19 Clique em Connect
- Passo 20 Clique no botão RAM, Disk para verificar o uso de recursos de hardware
- Passo 21 Clique no botão Play para executar a primeira célula de código
- Passo 22 Cole a célula de código que copiamos anteriormente do Ultralytics HUB na seção Start e execute‑a para iniciar o treinamento
- Passo 23 Agora, se você voltar ao Ultralytics HUB, verá a mensagem Connected. Clique em Done
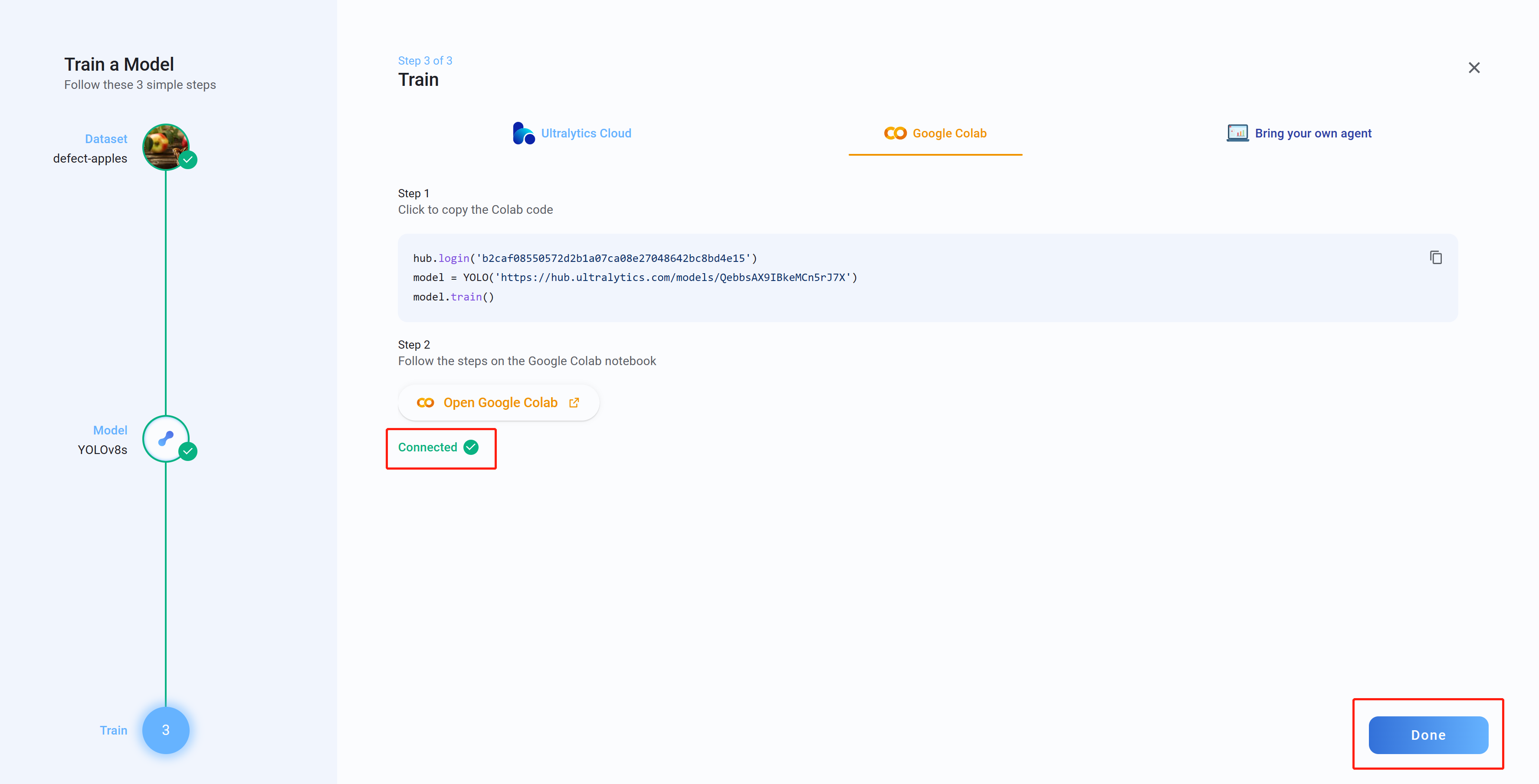
- Passo 24 Aqui você verá Box Loss, Class Loss e Object Loss em tempo real enquanto o modelo está sendo treinado no Google Colab
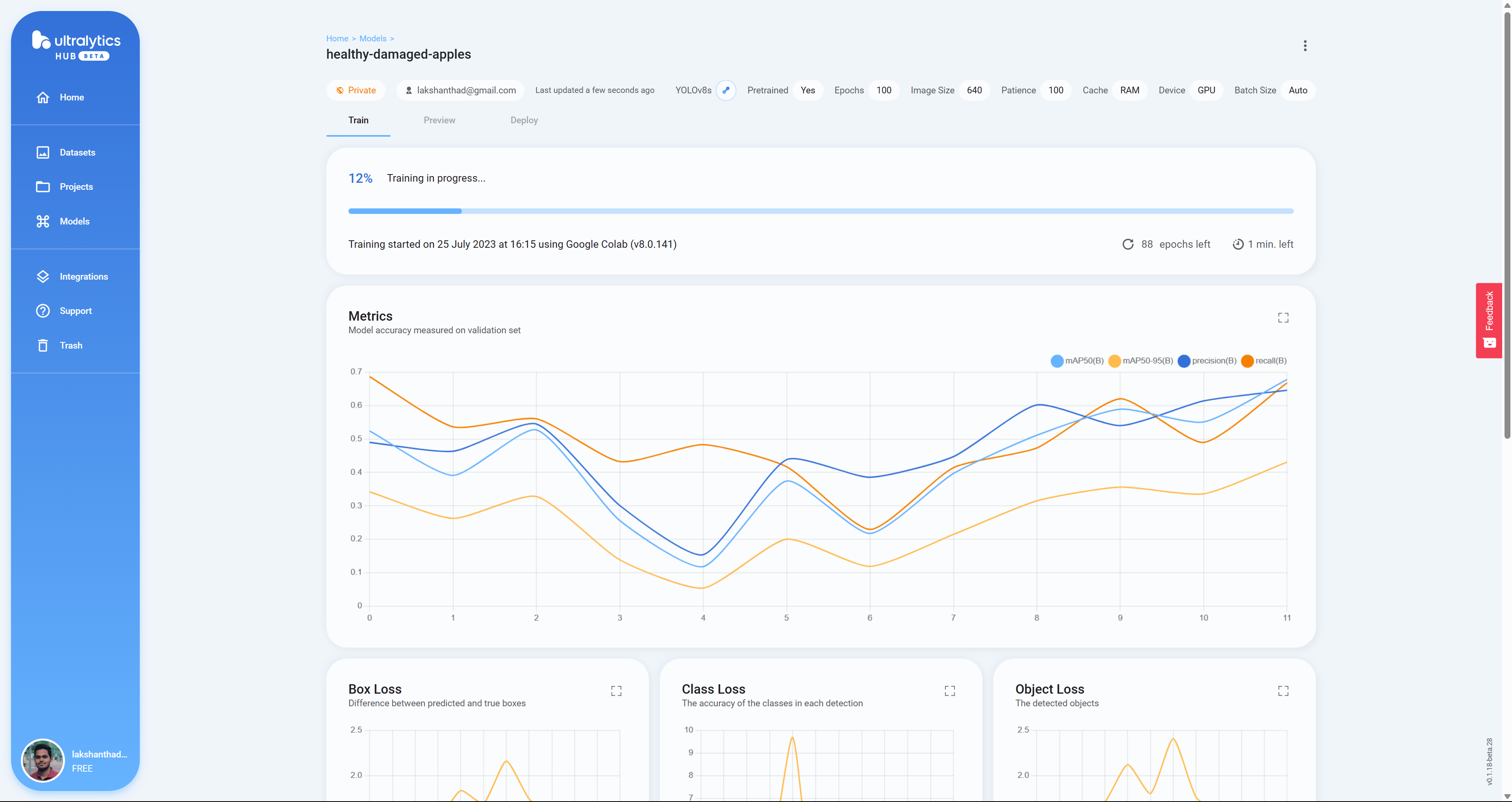
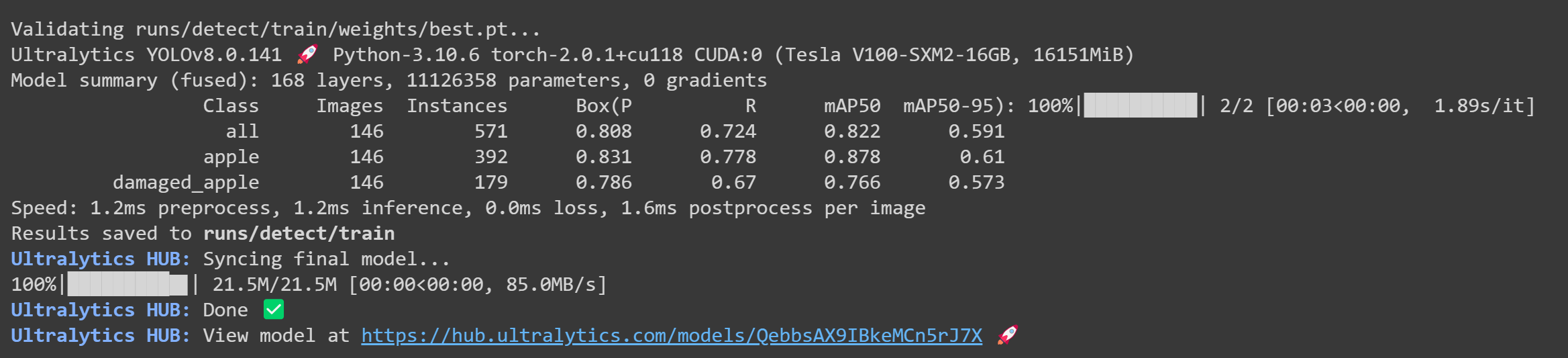
- Passo 25 Depois que o treinamento terminar, você verá a seguinte saída no Google Colab
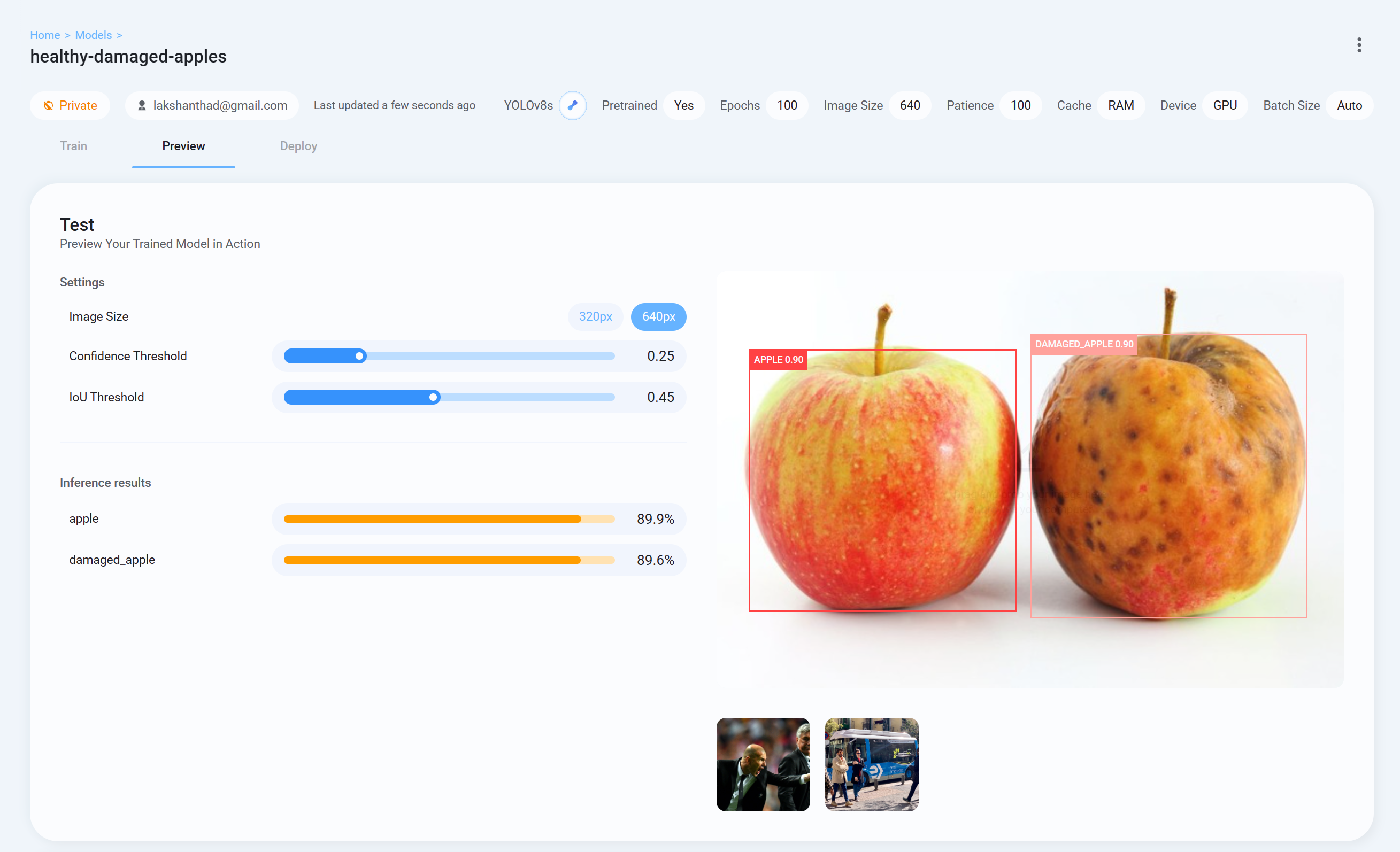
- Passo 26 Agora volte para o Ultralytics HUB, vá até a aba Preview e envie uma imagem de teste para verificar como o modelo treinado está se comportando
- Passo 26 Finalmente vá até a aba Deploy e baixe o modelo treinado no formato que você preferir para fazer inferência com o YOLOv8. Aqui escolhemos PyTorch.
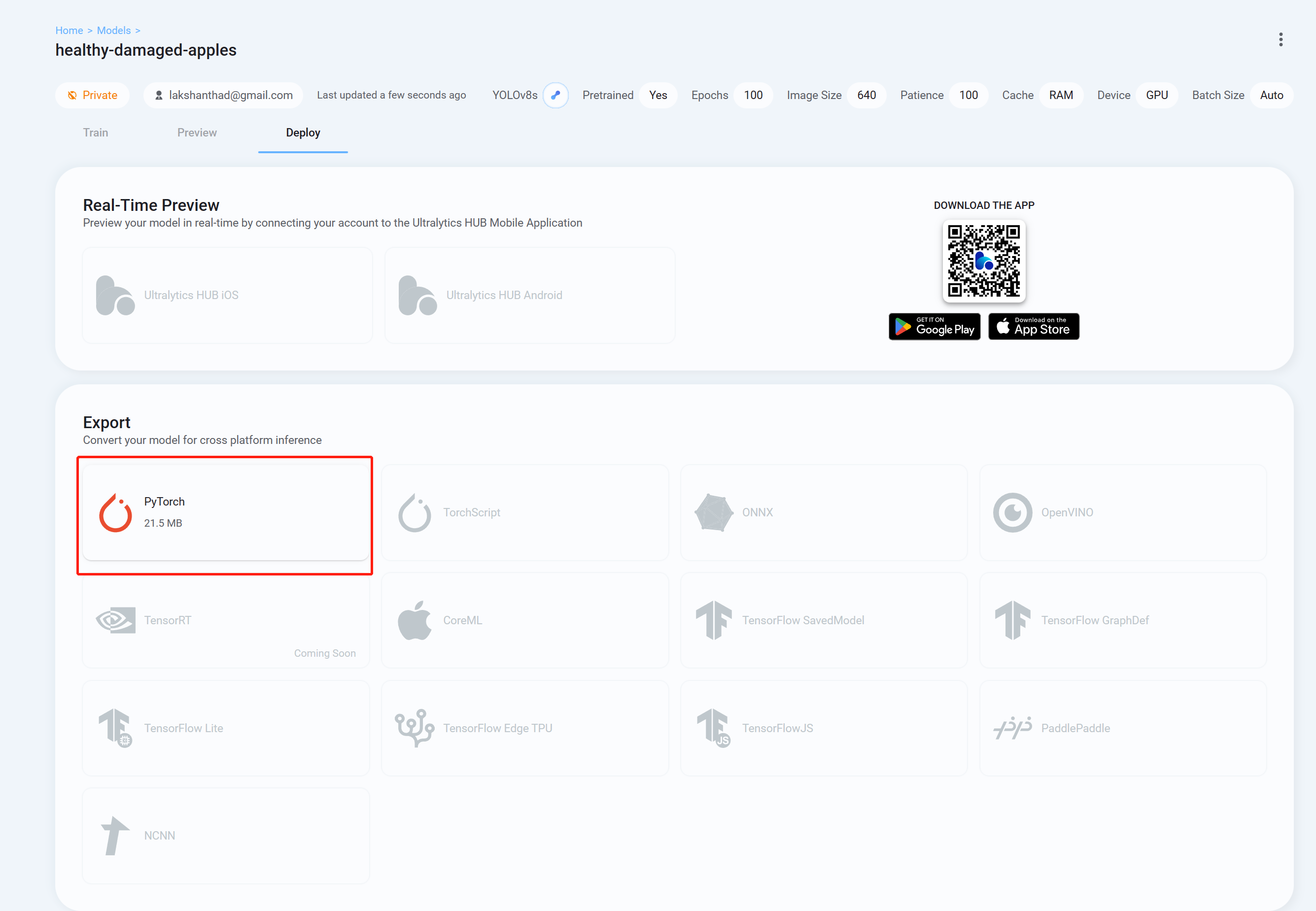
Agora você pode usar este modelo baixado com as tarefas que explicamos anteriormente neste wiki. Você só precisa substituir o arquivo de modelo pelo seu modelo.
Por exemplo:
yolo detect predict model=<your_model.pt> source='0' show=True
Aqui usamos um ambiente Google Colaboratory para realizar o treinamento na nuvem. Além disso, usamos a Roboflow api dentro do Colab para baixar facilmente nosso conjunto de dados.
- Passo 1. Clique aqui para abrir um workspace do Google Colab já preparado e siga as etapas mencionadas no workspace
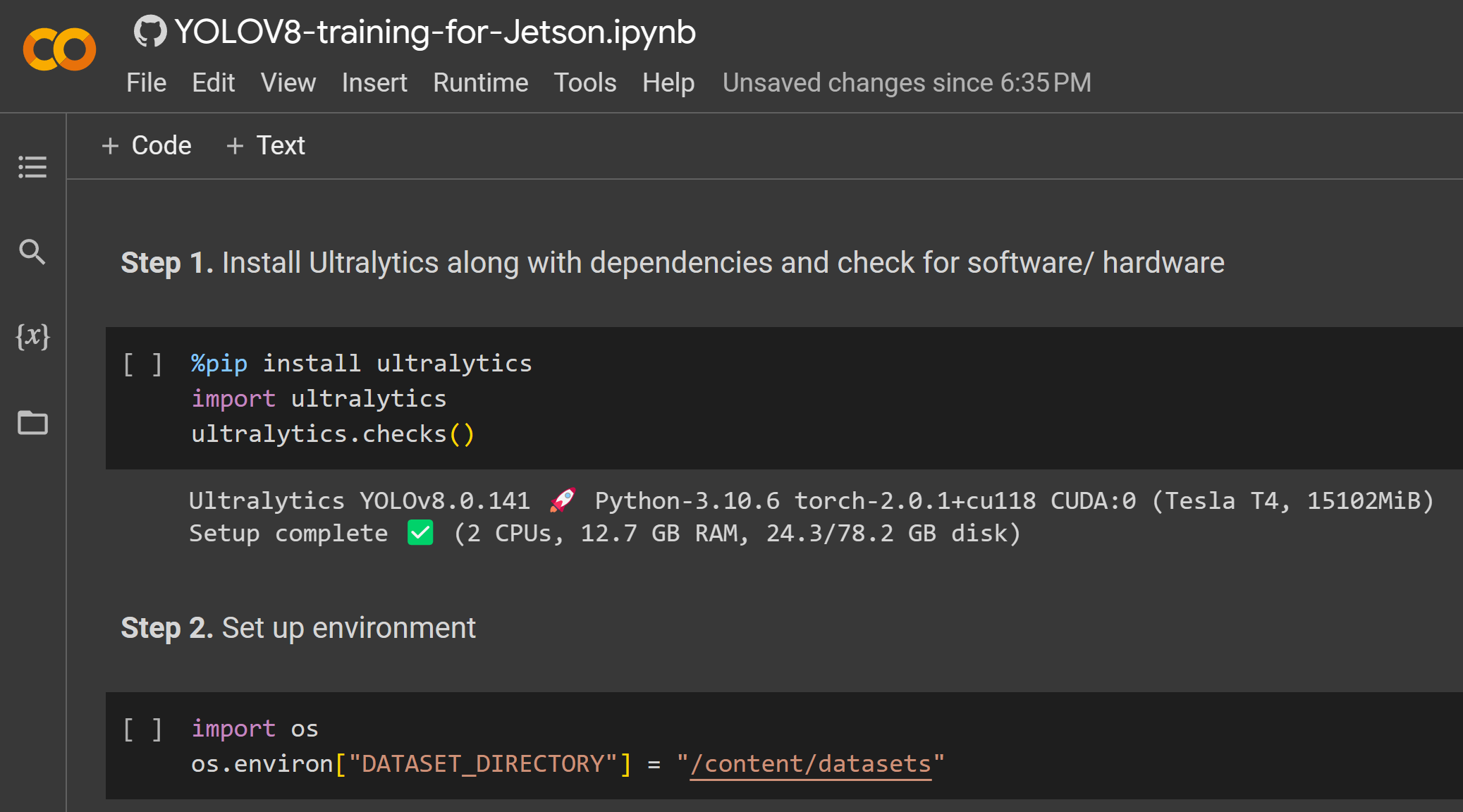
Depois que o treinamento terminar, você verá uma saída como a seguir:
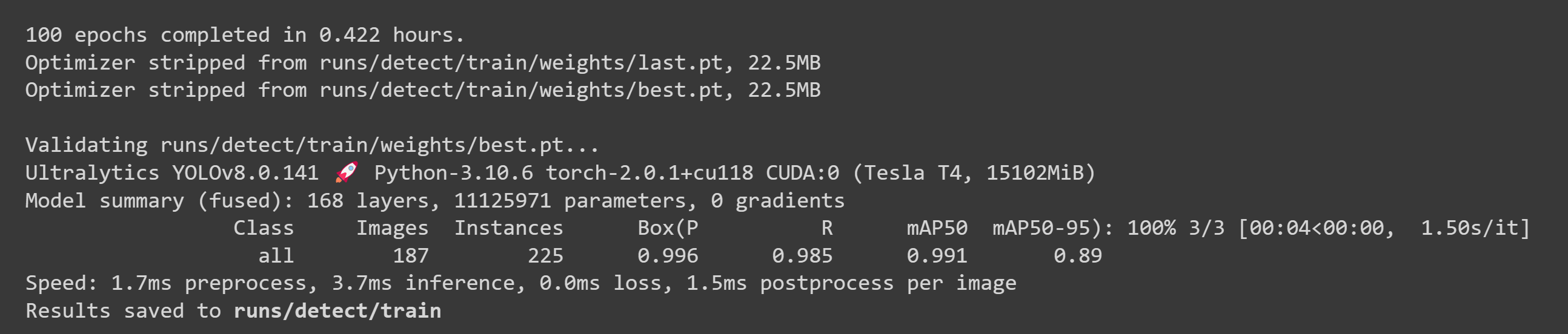
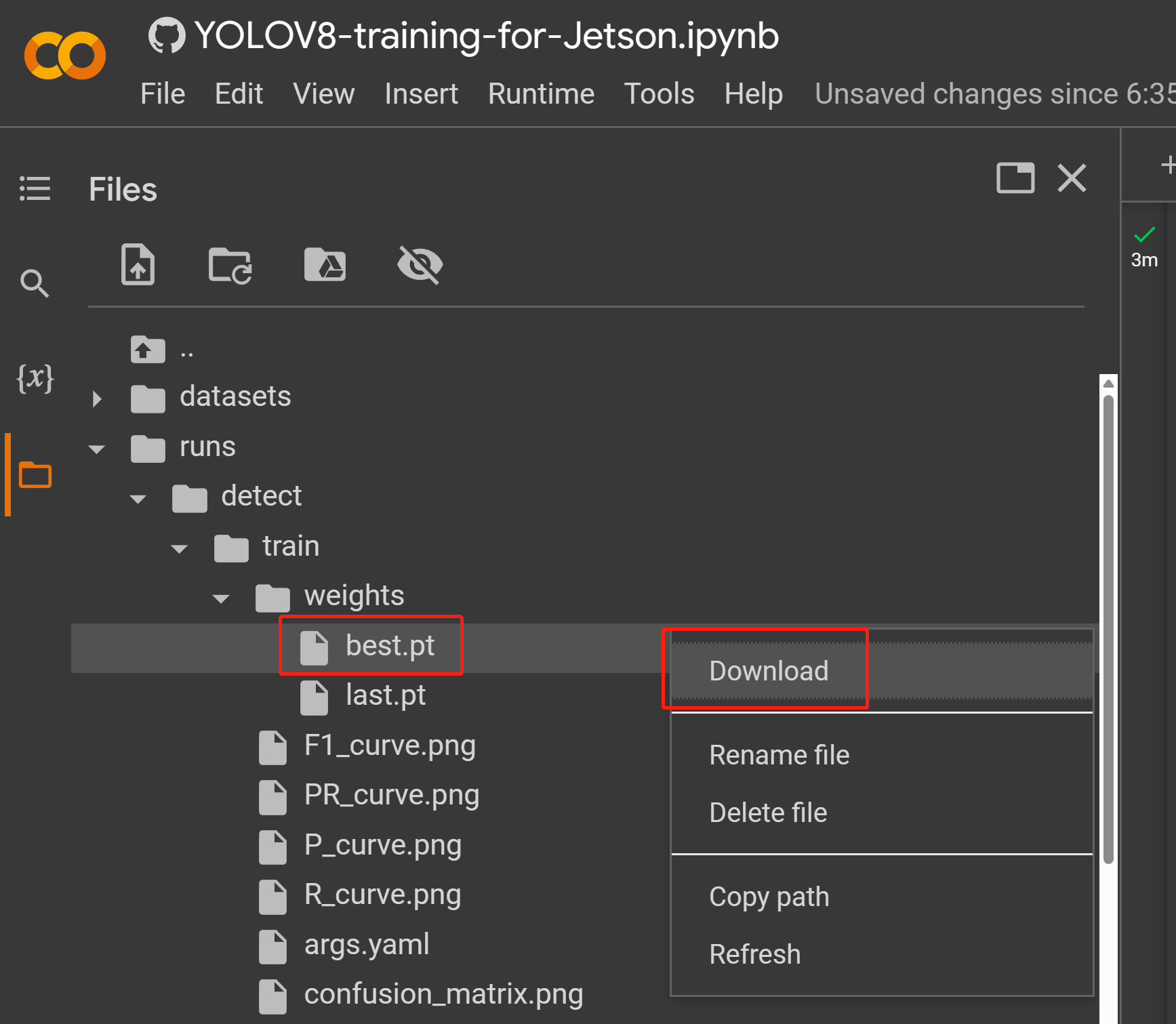
- Passo 2. Na aba Files, se você navegar até
runs/train/exp/weights, verá um arquivo chamado best.pt. Este é o modelo gerado a partir do treinamento. Baixe este arquivo e copie‑o para o seu dispositivo Jetson, pois este é o modelo que vamos usar depois para inferência no dispositivo Jetson.
Agora você pode usar este modelo baixado com as tarefas que explicamos anteriormente neste wiki. Você só precisa substituir o arquivo de modelo pelo seu modelo.
Por exemplo:
yolo detect predict model=<your_model.pt> source='0' show=True
Aqui você pode usar um PC com um sistema operacional Linux para treinamento. Usamos um PC com Ubuntu 20.04 para este wiki.
- Passo 1. Instale o pip se você não tiver o pip no seu sistema
sudo apt install python3-pip -y
- Passo 2. Instale Ultralytics juntamente com as dependências
pip install ultralytics
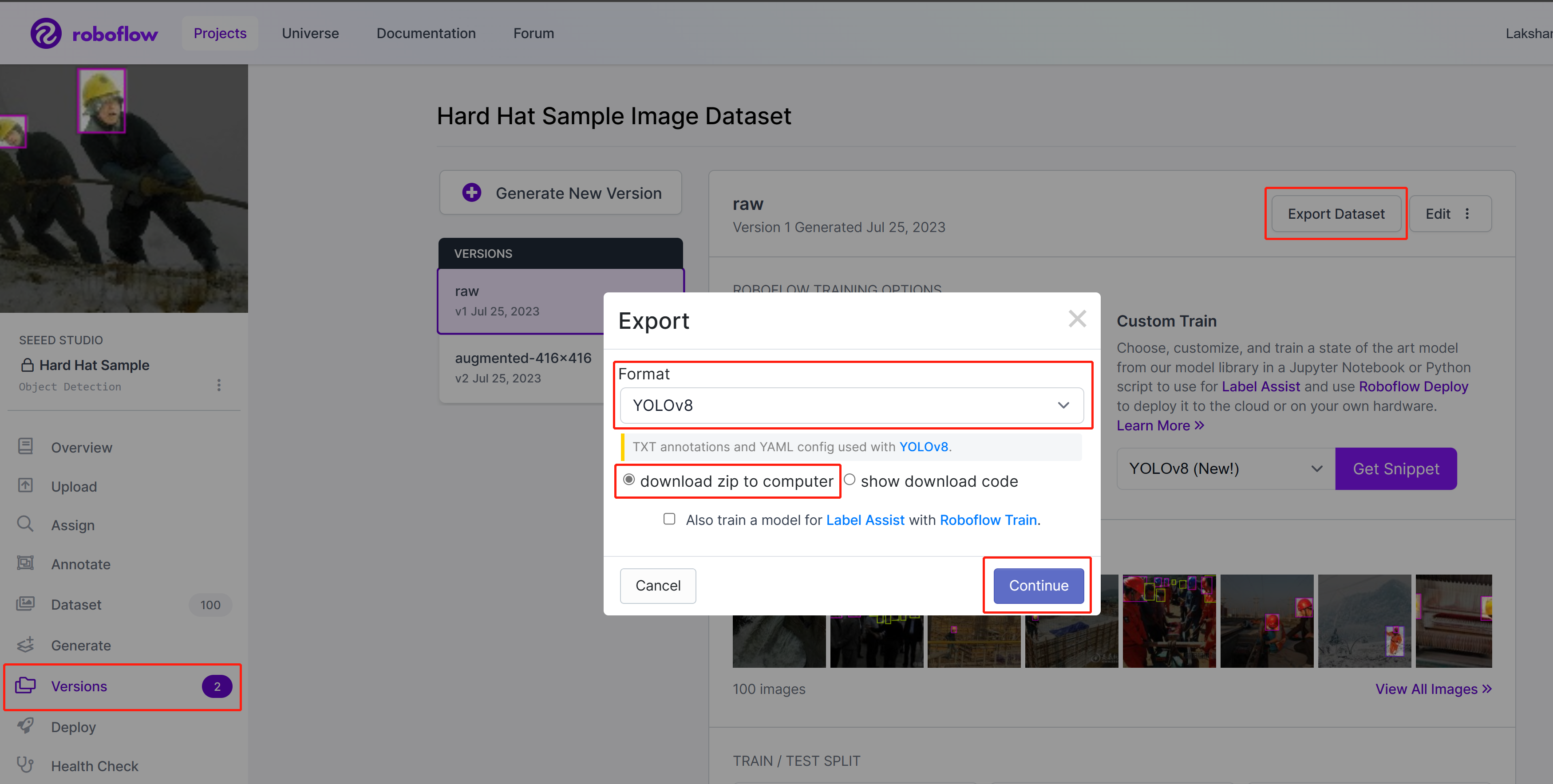
- Passo 3. No Roboflow, dentro do seu projeto, vá para Versions, selecione Export Dataset, selecione Format como YOLOv8, escolha download zip to computer e clique em Continue
-
Passo 4. Extraia o arquivo zip baixado
-
Passo 5. Execute o seguinte comando para iniciar o treinamento. Aqui você precisa substituir path_to_yaml pelo local do arquivo .yaml que está dentro do arquivo zip extraído anteriormente
yolo train data=<path_to_yaml> model=yolov8s.pt epochs=100 imgsz=640 batch=-1
Aqui o tamanho da imagem é definido como 640x640. Usamos o batch-size como -1 porque isso determinará automaticamente o melhor tamanho de batch. Você também pode alterar o epoch de acordo com sua preferência. Aqui você pode mudar o modelo pré-treinado para qualquer modelo de detecção, segmentação, classificação ou pose.
Depois que o treinamento for concluído, você verá uma saída como a seguir:
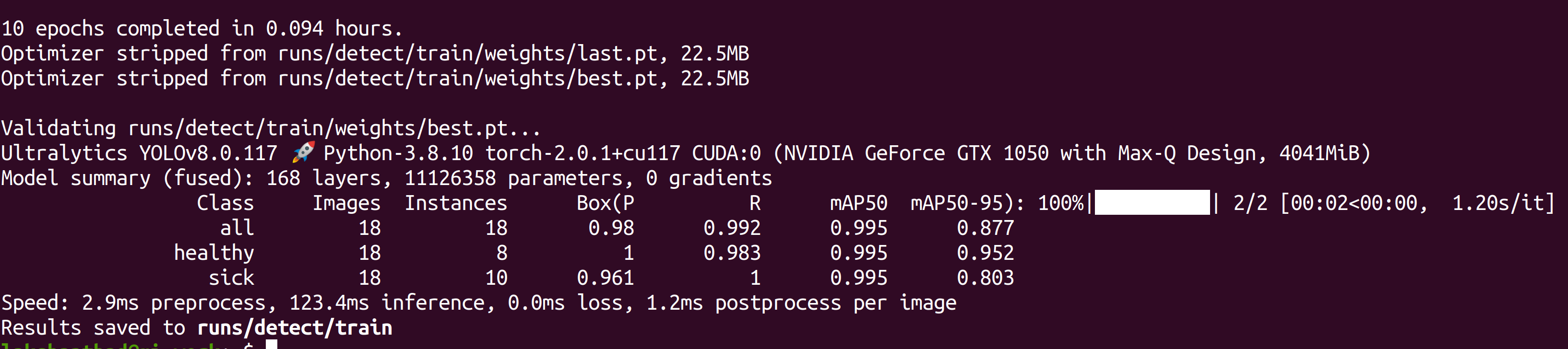
- Passo 6. Dentro de runs/detect/train/weights, você verá um arquivo chamado best.pt. Este é o modelo gerado a partir do treinamento. Baixe este arquivo e copie-o para o seu dispositivo Jetson porque este é o modelo que usaremos depois para inferência no dispositivo Jetson.

Agora você pode usar este modelo baixado com as tarefas que explicamos anteriormente neste wiki. Você só precisa substituir o arquivo de modelo pelo seu modelo.
Por exemplo:
yolo detect predict model=<your_model.pt> source='0' show=True
Testes de Desempenho
Preparação
Realizamos testes de desempenho para todas as tarefas de visão computacional suportadas pelo YOLOv8 rodando no reComputer J4012/ reComputer Industrial J4012 com módulo NVIDIA Jetson Orin NX 16GB.
Incluído no diretório de samples há uma ferramenta de linha de comando chamada trtexec. trtexec é uma ferramenta para usar TensorRT sem precisar desenvolver sua própria aplicação. A ferramenta trtexec tem três principais finalidades:
- Fazer benchmark de redes com dados de entrada aleatórios ou fornecidos pelo usuário.
- Gerar engines serializadas a partir de modelos.
- Gerar um cache de temporização serializado a partir do builder.
Aqui podemos usar a ferramenta trtexec para rapidamente fazer benchmark dos modelos com diferentes parâmetros. Mas antes de tudo, você precisa ter um modelo onnx e podemos gerar esse modelo onnx usando ultralytics yolov8.
- Passo 1. Construir o ONNX usando:
yolo mode=export model=yolov8s.pt format=onnx
- Passo 2. Construir o arquivo de engine usando trtexec da seguinte forma:
cd /usr/src/tensorrt/bin
./trtexec --onnx=<path_to_onnx_file> --saveEngine=<path_to_save_engine_file>
Por exemplo:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine
Isso produzirá resultados de desempenho como a seguir juntamente com um arquivo .engine gerado. Por padrão, ele converterá ONNX em um arquivo otimizado TensorRT em precisão FP32 e você poderá ver a saída como a seguir
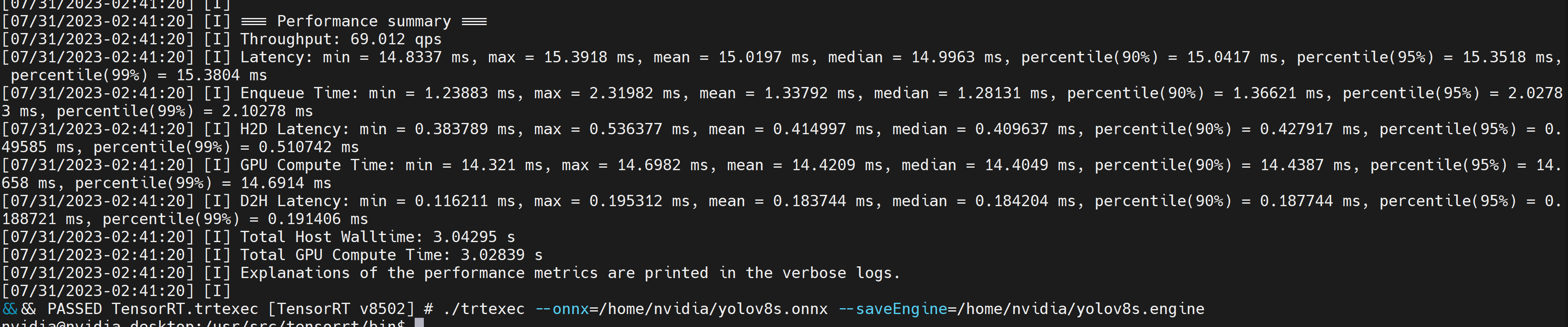
Se você quiser precisão FP16, que oferece melhor desempenho do que FP32, você pode executar o comando acima da seguinte forma
./trtexec --onnx=/home/nvidia/yolov8s.onnx --fp16 --saveEngine=/home/nvidia/yolov8s.engine
No entanto, se você quiser precisão INT8, que oferece melhor desempenho do que FP16, você pode executar o comando acima da seguinte forma
./trtexec --onnx=/home/nvidia/yolov8s.onnx --int8 --saveEngine=/home/nvidia/yolov8s.engine
Resultados
Abaixo resumimos os resultados que obtivemos de todas as quatro tarefas de visão computacional rodando no reComputer J4012/ reComputer Industrial J4012.
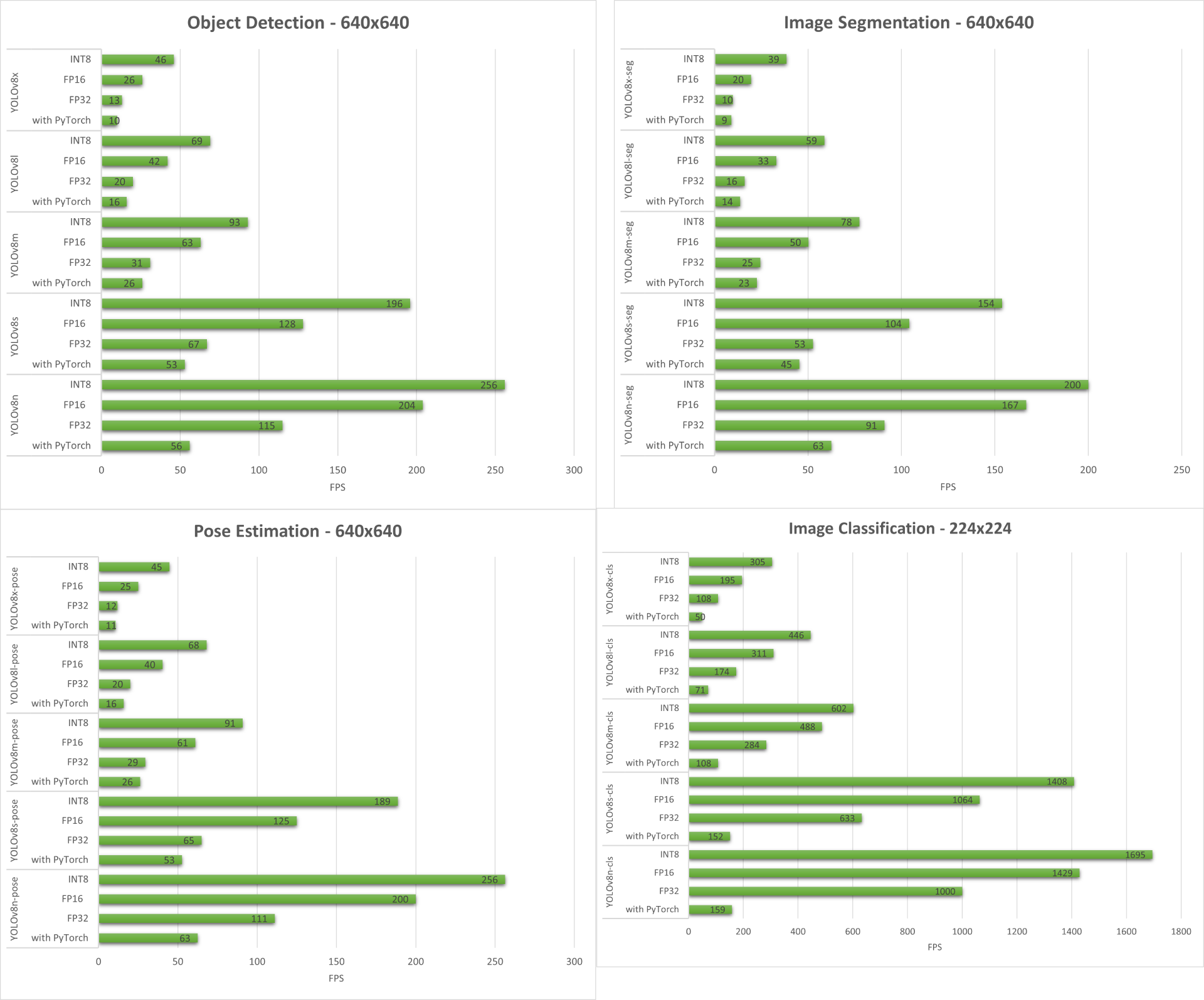
Demo Extra: Detector e Contador de Exercícios com YOLOv8
Nós construímos um aplicativo demo de estimativa de pose para detecção e contagem de exercícios com YOLOv8 usando o modelo YOLOv8-Pose. Você pode conferir o projeto aqui para saber mais sobre este demo e implantá-lo no seu próprio dispositivo Jetson!
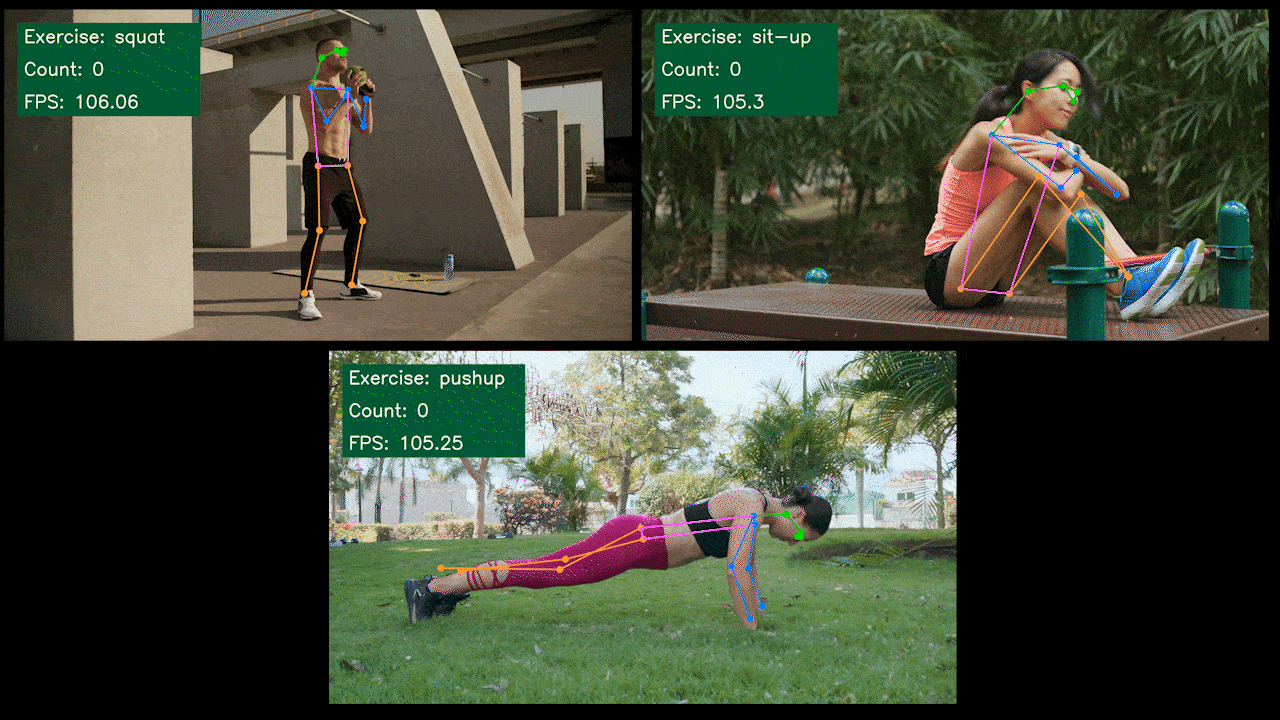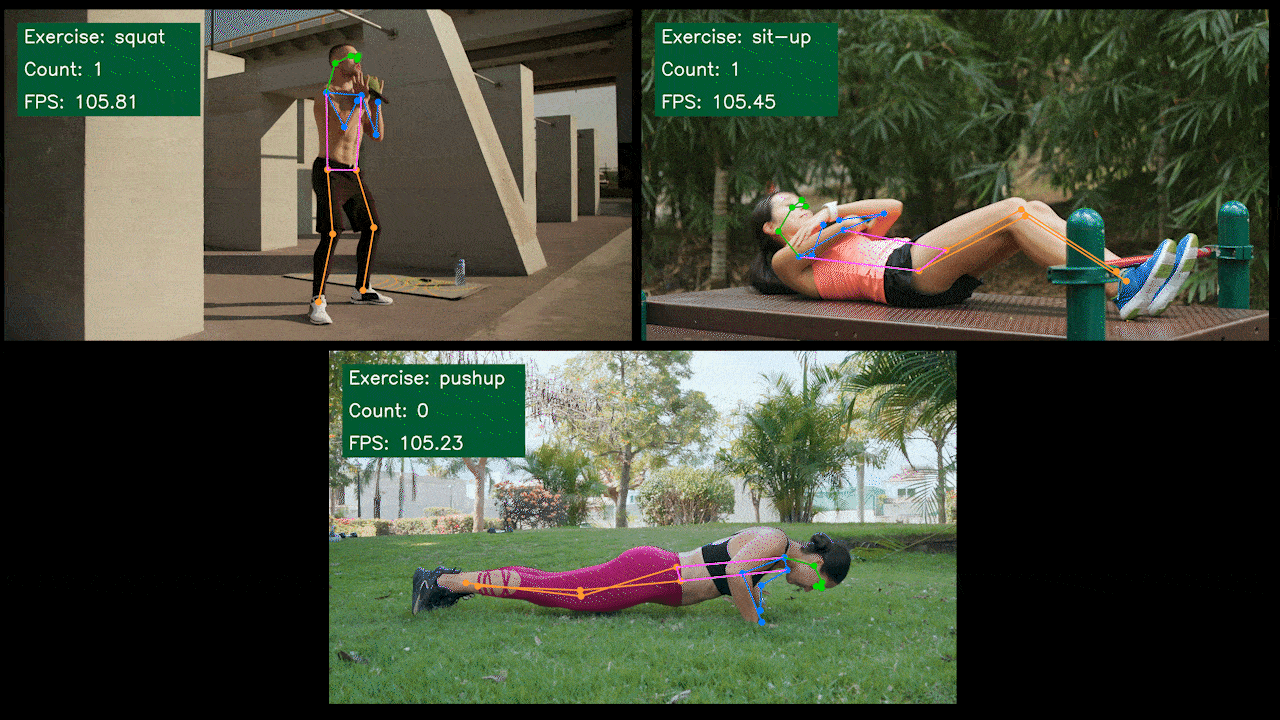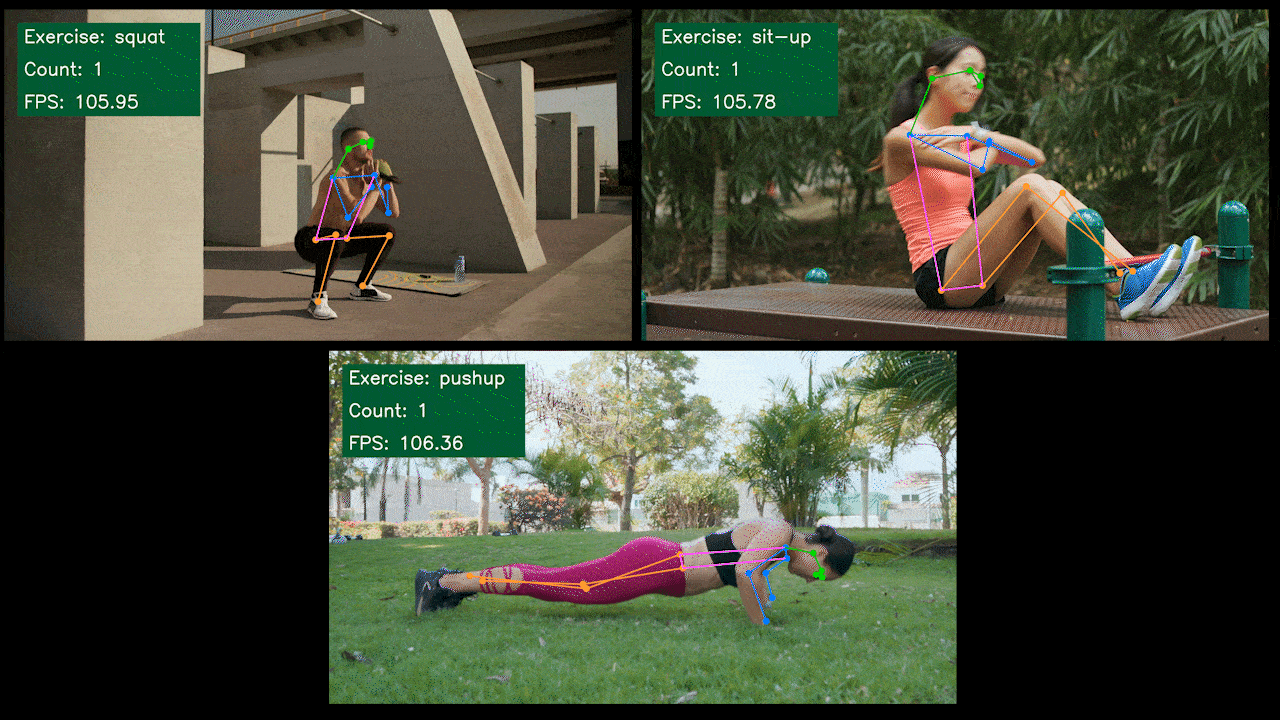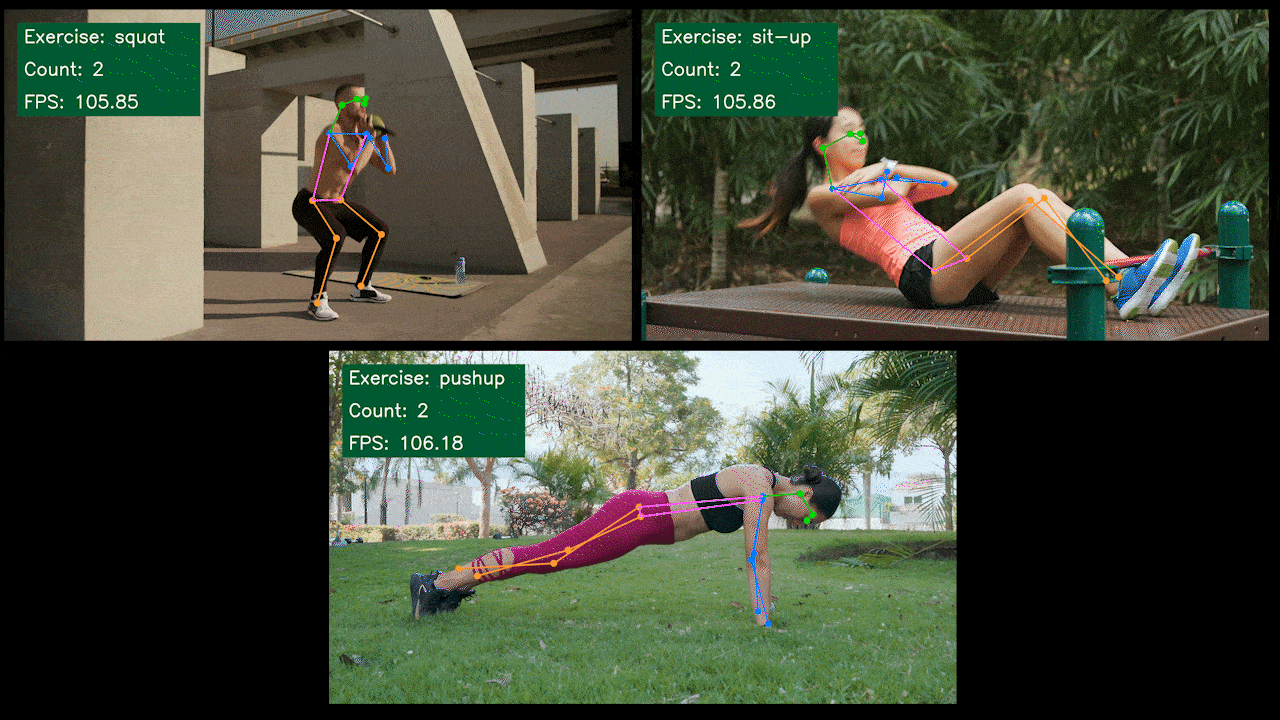
Configuração Manual do YOLOv8 para NVIDIA Jetson
Se o script de uma linha que mencionamos antes apresentar alguns erros, você pode seguir os passos abaixo um por um para preparar o dispositivo Jetson com YOLOv8.
Instalar o Pacote Ultralytics
- Passo 1. Acesse o terminal do dispositivo Jetson, instale o pip e faça o upgrade
sudo apt update
sudo apt install -y python3-pip -y
pip3 install --upgrade pip
- Passo 2. Instale o pacote Ultralytics
pip3 install ultralytics
- Passo 3. Atualize a versão do numpy para a mais recente
pip3 install numpy -U
- Passo 4. Reinicie o dispositivo
sudo reboot
Desinstalar Torch e Torchvision
A instalação do ultralytics acima instalará Torch e Torchvision. No entanto, esses 2 pacotes instalados via pip não são compatíveis para rodar na plataforma Jetson, que é baseada na arquitetura ARM aarch64. Portanto, precisamos instalar manualmente o pacote pré-compilado do PyTorch (wheel pip) e compilar/ instalar o Torchvision a partir do código-fonte.
pip3 uninstall torch torchvision
Instalar PyTorch e Torchvision
Visite esta página para acessar todos os links de PyTorch e Torchvision.
Aqui estão algumas das versões suportadas pelo JetPack 5.0 e superior.
PyTorch v2.0.0
Suportado por JetPack 5.1 (L4T R35.2.1) / JetPack 5.1.1 (L4T R35.3.1) com Python 3.8
file_name: torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl URL: https://nvidia.box.com/shared/static/i8pukc49h3lhak4kkn67tg9j4goqm0m7.whl
PyTorch v1.13.0
Suportado por JetPack 5.0 (L4T R34.1) / JetPack 5.0.2 (L4T R35.1) / JetPack 5.1 (L4T R35.2.1) / JetPack 5.1.1 (L4T R35.3.1) com Python 3.8
file_name: torch-1.13.0a0+d0d6b1f2.nv22.10-cp38-cp38-linux_aarch64.whl URL: https://developer.download.nvidia.com/compute/redist/jp/v502/pytorch/torch-1.13.0a0+d0d6b1f2.nv22.10-cp38-cp38-linux_aarch64.whl
- Passo 1. Instale o torch de acordo com a sua versão do JetPack no seguinte formato pip3
wget <URL> -O <file_name>
pip3 install <file_name>
Por exemplo, aqui estamos executando JP5.1.1 e, portanto, escolhemos PyTorch v2.0.0
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/i8pukc49h3lhak4kkn67tg9j4goqm0m7.whl -O torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
pip3 install torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
- Passo 2. Instale torchvision dependendo da versão do PyTorch que você instalou. Por exemplo, escolhemos PyTorch v2.0.0, o que significa que precisamos escolher Torchvision v0.15.2
sudo apt install -y libjpeg-dev zlib1g-dev
git clone https://github.com/pytorch/vision torchvision
cd torchvision
git checkout v0.15.2
python3 setup.py install --user
Aqui está uma lista da versão correspondente do torchvision que você precisa instalar de acordo com a versão do PyTorch:
- PyTorch v2.0.0 - torchvision v0.15
- PyTorch v1.13.0 - torchvision v0.14
Se você quiser uma lista mais detalhada, por favor consulte este link.
Instalar ONNX e Fazer Downgrade do Numpy
Isso só é necessário se você quiser converter os modelos PyTorch para TensorRT
- Passo 1. Instale ONNX, que é um requisito
pip3 install onnx
- Passo 2. Faça downgrade para uma versão inferior do Numpy para corrigir um erro
pip3 install numpy==1.20.3
Recursos
Suporte Técnico & Discussão de Produtos
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.