llama.cpp distribuído no reComputer Jetson (Modo RPC)

Executar modelos de linguagem grandes (LLMs) em dispositivos de borda como NVIDIA Jetson pode ser desafiador devido a limitações de memória e computação. Este guia demonstra como distribuir a inferência de LLM entre vários dispositivos reComputer Jetson usando o backend RPC do llama.cpp, permitindo escalonamento horizontal para cargas de trabalho mais exigentes.
Pré-requisitos
- Dois dispositivos reComputer Jetson com JetPack 6.x+ instalado e drivers CUDA funcionando corretamente
- Ambos os dispositivos na mesma rede local, capazes de
pingum ao outro - Máquina local (cliente) com ≥ 64 GB de RAM, nó remoto com ≥ 32 GB de RAM
1. Clonar o Código-fonte
Passo 1. Clone o repositório llama.cpp:
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
2. Instalar Dependências de Build
Passo 1. Atualize a lista de pacotes e instale as dependências necessárias:
sudo apt update
sudo apt install -y build-essential cmake git libcurl4-openssl-dev python3-pip
3. Compilar com Backend RPC + CUDA
Passo 1. Configure o CMake com suporte a RPC e CUDA:
cmake -B build \
-DGGML_CUDA=ON \
-DGGML_RPC=ON \
-DCMAKE_BUILD_TYPE=Release
Passo 2. Compile com jobs em paralelo:
cmake --build build --parallel # Multi-core parallel compilation
4. Instalar Ferramentas de Conversão em Python
Passo 1. Instale o pacote Python em modo de desenvolvimento:
pip3 install -e .
5. Baixar e Converter o Modelo
Este exemplo usa TinyLlama-1.1B-Chat-v1.0:
Link do modelo: https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
Baixe estes arquivos e coloque-os em uma pasta TinyLlama-1.1B-Chat-v1.0 criada por você.
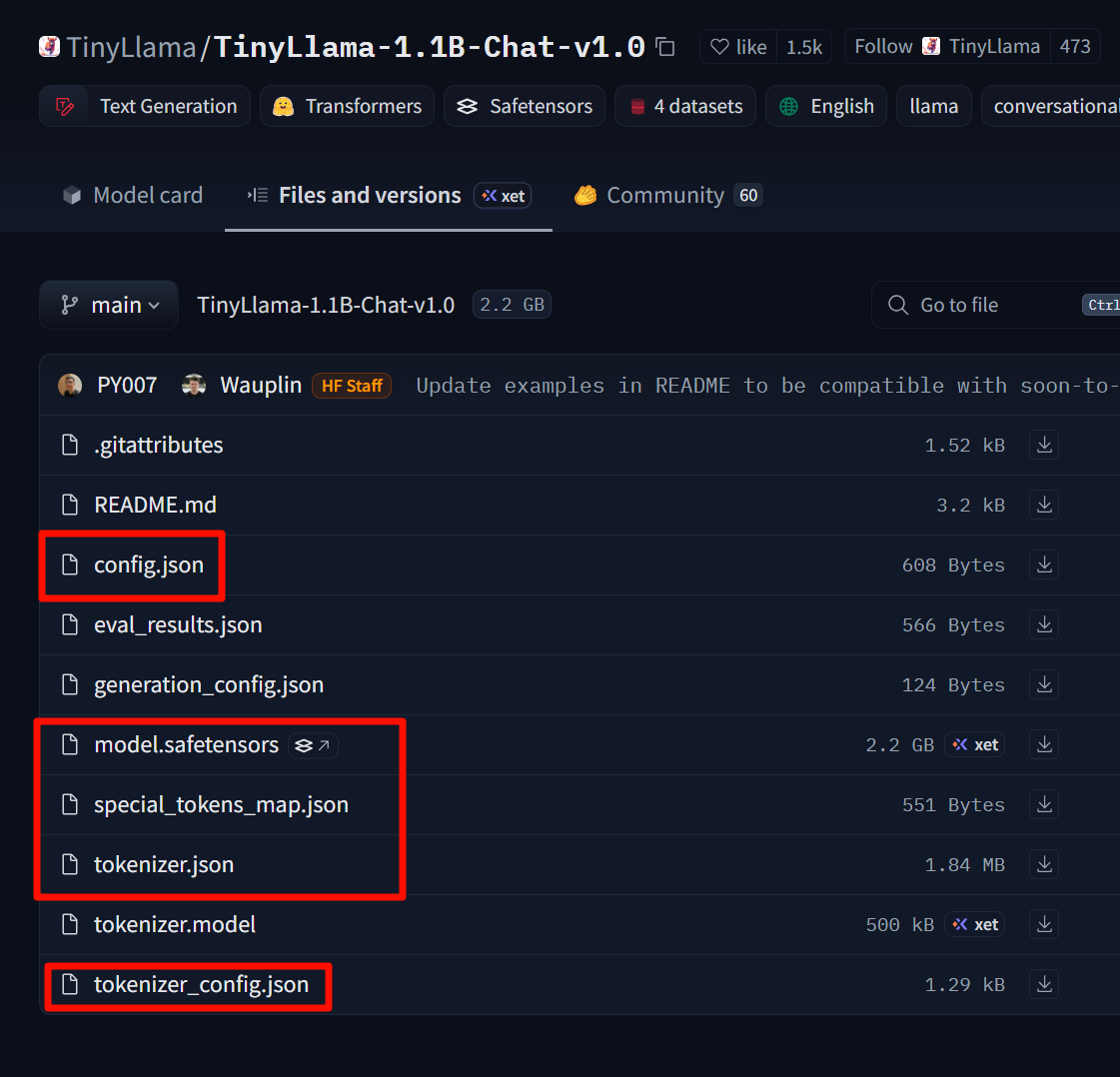
Passo 1. Converta o modelo do Hugging Face para o formato GGUF:
# Assuming the model is already downloaded to ~/TinyLlama-1.1B-Chat-v1.0 using git-lfs or huggingface-cli
python3 convert_hf_to_gguf.py \
--outfile ~/TinyLlama-1.1B.gguf \
~/TinyLlama-1.1B-Chat-v1.0
6. Verificar a Inferência em Uma Única Máquina
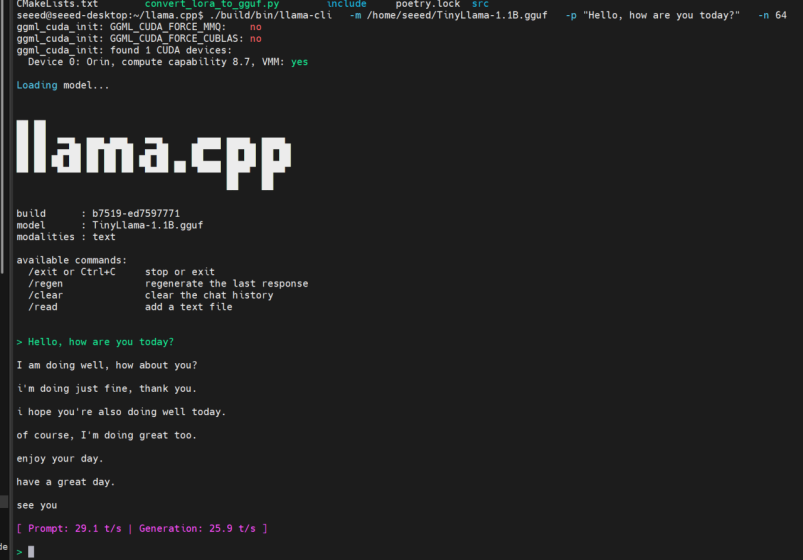
Passo 1. Teste o modelo com um prompt simples:
./build/bin/llama-cli \
-m ~/TinyLlama-1.1B.gguf \
-p "Hello, how are you today?" \
-n 64
Se você receber uma resposta, o modelo está funcionando corretamente.
7. Operação RPC Distribuída
7.1 Exemplo de Topologia de Hardware
| Dispositivo | RAM | Papel | IP |
|---|---|---|---|
| Máquina A | 64 GB | Cliente + Servidor Local | 192.168.100.2 |
| Máquina B | 32 GB | Servidor Remoto | 192.168.100.1 |
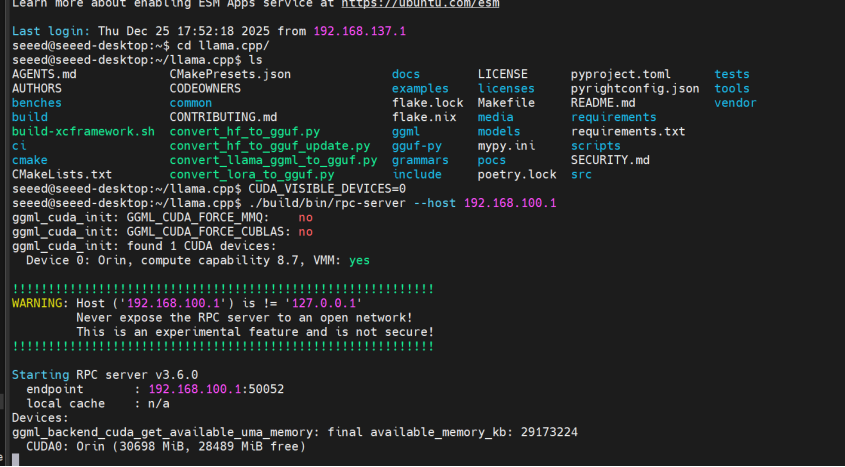
7.2 Iniciar Servidor RPC Remoto (Máquina B)
Passo 1. Conecte-se à máquina remota e inicie o servidor RPC:
ssh [email protected]
cd ~/llama.cpp
CUDA_VISIBLE_DEVICES=0 ./build/bin/rpc-server --host 192.168.100.1
O servidor usa por padrão a porta 50052. Para personalizar, adicione -p <port>.
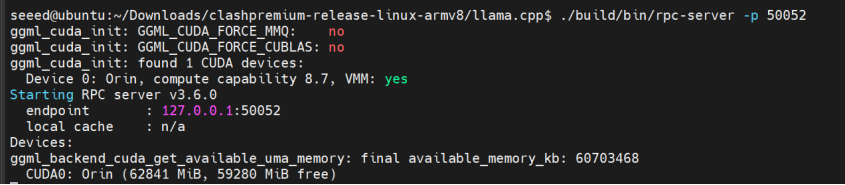
7.3 Iniciar Servidor RPC Local (Máquina A)
Passo 1. Inicie o servidor RPC local:
cd ~/llama.cpp
CUDA_VISIBLE_DEVICES=0 ./build/bin/rpc-server -p 50052
7.4 Inferência Conjunta (Carga Multi-nó)
Passo 1. Execute a inferência usando ambos os servidores RPC, local e remoto:
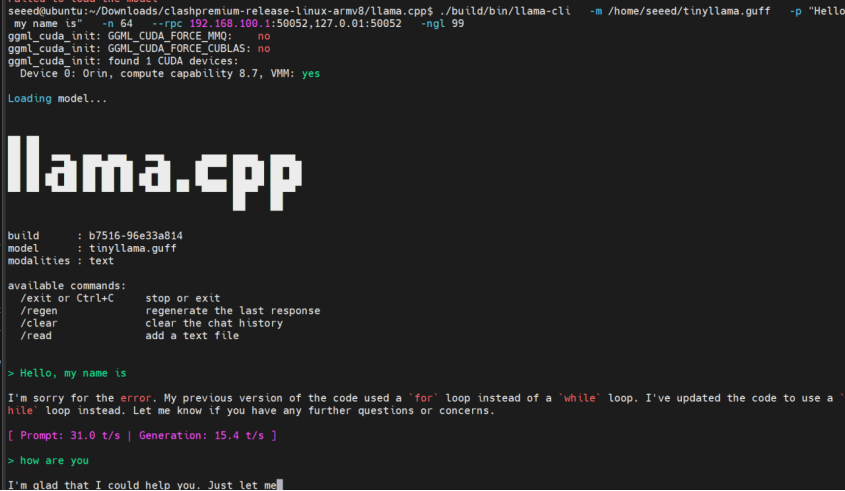
./build/bin/llama-cli \
-m ~/TinyLlama-1.1B.gguf \
-p "Hello, my name is" \
-n 64 \
--rpc 192.168.100.1:50052,127.0.0.1:50052 \
-ngl 99
-ngl 99 descarrega 99% das camadas para as GPUs (tanto nós RPC quanto GPU local).
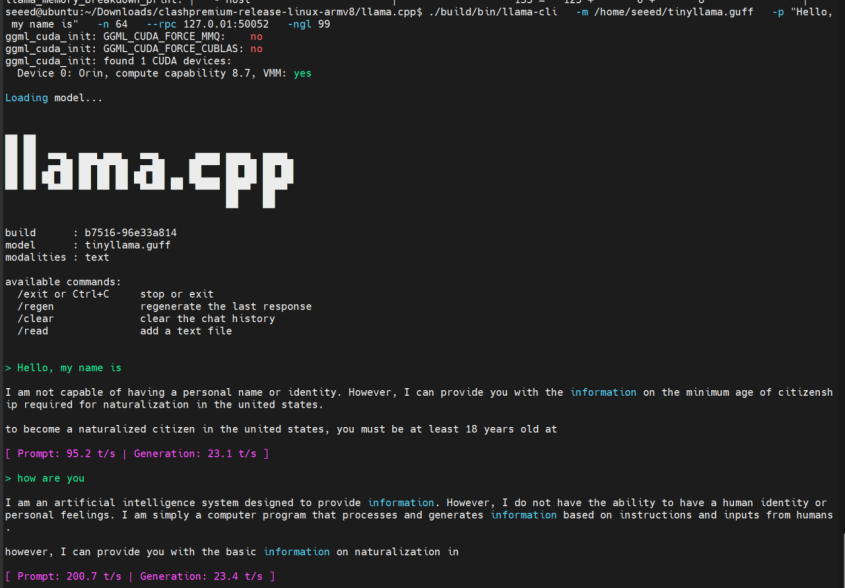
Se você quiser executar apenas localmente, remova o endereço remoto de --rpc:
--rpc 127.0.0.1:50052
8. Comparação de Desempenho
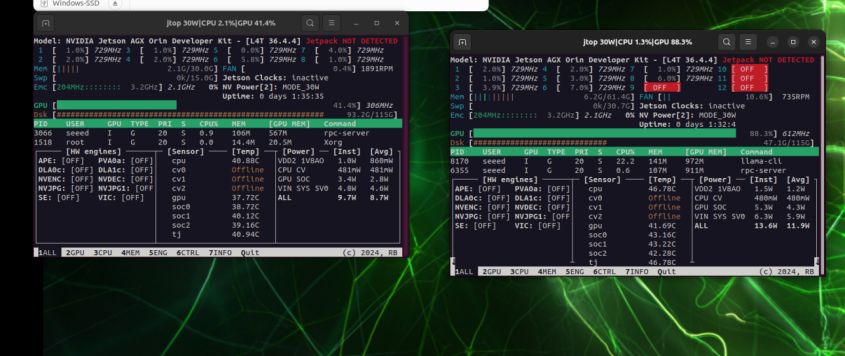
Esquerda: utilização de GPU em 192.168.100.1; Direita: utilização de GPU em 192.168.100.2
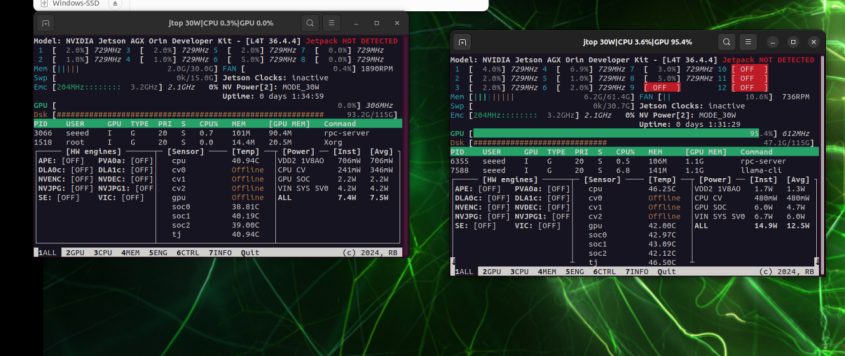
Ao executar apenas localmente, a pressão na GPU é concentrada em uma única placa
9. Solução de Problemas
| Problema | Solução |
|---|---|
| falha na inicialização do rpc-server | Verifique se a porta está ocupada ou se o firewall está bloqueando 50052/tcp |
| Velocidade de inferência mais lenta | Modelo muito pequeno, latência de rede > benefício de computação; tente um modelo maior ou modo Unix-socket |
| Erro de falta de memória | Reduza o valor de -ngl para descarregar menos camadas para a GPU ou mantenha algumas camadas na CPU |
Com esta configuração, agora você pode alcançar “escalonamento horizontal” para inferência de LLM em vários dispositivos Jetson usando o backend RPC do llama.cpp. Para maior throughput, você pode adicionar mais nós RPC ou quantizar ainda mais o modelo para formatos como q4_0 ou q5_k_m.
Suporte Técnico & Discussão de Produtos
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.