Interação de Voz com IA usando reCamera
Introdução
Este projeto demonstra uma forma de interagir com a reCamera por meio de linguagem natural. Após o raciocínio visual acionar a gravação de áudio, a reCamera envia a gravação para o servidor, que a processa através do pipeline completo STT (Speech-to-Text) → LLM (Large Language Model Reasoning) → TTS (Text-to-Speech), e a voz sintetizada é retornada para a reCamera para reprodução, possibilitando conversas em linguagem natural.
Você já quis ter uma câmera que não apenas "vê", mas também "entende" e "fala"? Por meio da arquitetura deste projeto, usando o microfone e o alto-falante da reCamera, o dispositivo deixa de ser apenas uma ferramenta visual e se torna um assistente inteligente capaz de conversar naturalmente. Isso inclui, mas não se limita, aos seguintes cenários:
-
Assistente Inteligente de Controle de Acesso: Instale a reCamera na entrada, onde os visitantes podem concluir o registro de identidade, deixar recados ou obter orientações apenas por voz, sem a necessidade de uma tela interativa adicional.
-
Parceiro de Inspeção de Segurança em Fábricas: Em ambientes industriais, quando as mãos dos trabalhadores estão ocupadas, eles podem acionar a interação por voz por meio de gestos para perguntar ao assistente de IA sobre o status de equipamentos, manuais de operação ou relatar anomalias.
-
Interação Assistiva para Acessibilidade: Fornece um ponto de entrada de controle por voz para usuários com deficiência visual ou mobilidade reduzida, permitindo conversas em linguagem natural com o dispositivo por meio de simples gestos para obter informações do ambiente ou enviar comandos.
-
Guia para Educação e Exposições: Em museus ou salas de exposição, os visitantes podem acionar a interação por voz por meio de gestos para perguntar ao assistente de IA sobre informações das exposições e receber visitas guiadas personalizadas.
Vídeo de Demonstração
Arquitetura do Sistema
Todo o sistema é concluído de forma colaborativa por duas partes: lado reCamera e lado servidor PC. A arquitetura é a seguinte:
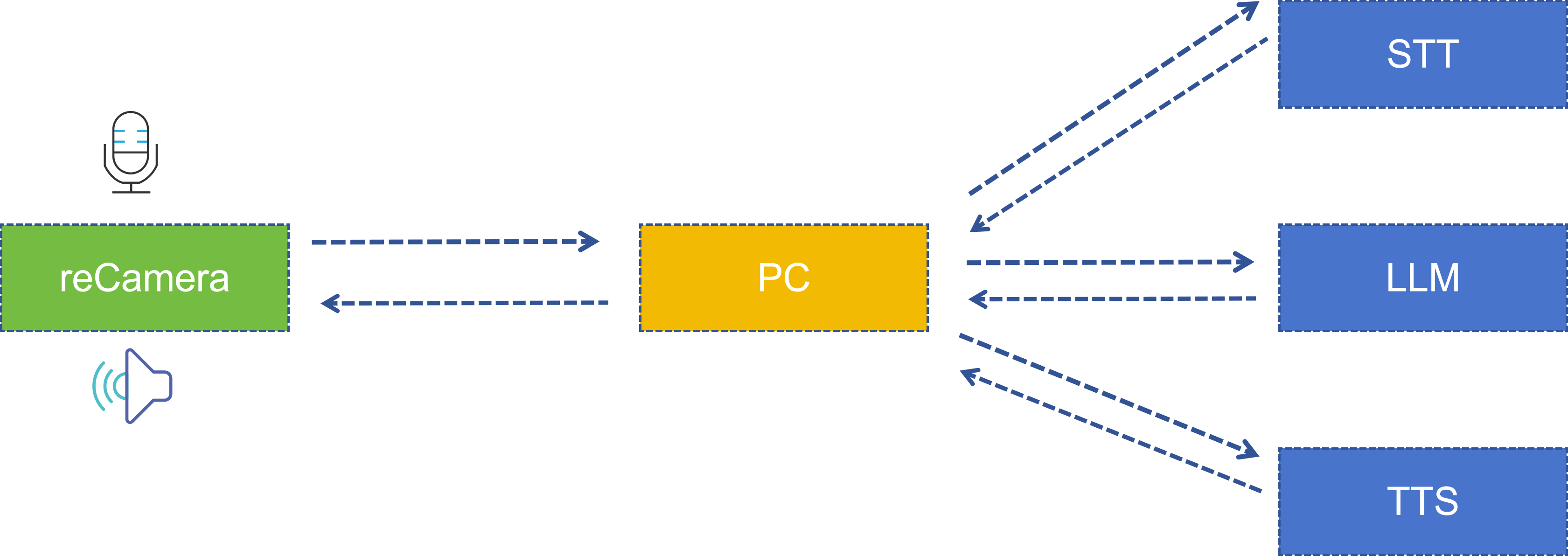
| Etapa | Local de Execução | Tecnologia/Modelo Utilizado | Descrição |
|---|---|---|---|
| Detecção de Pose | reCamera | YOLO11n Pose | Detecta 17 pontos-chave do corpo humano |
| Julgamento de Pose | reCamera (Função Node-RED) | Lógica personalizada | Compara as distâncias dos pontos-chave do ombro e do cotovelo |
| Gravação/Reprodução | reCamera | arecord / aplay | PCM mono 16kHz |
| Reconhecimento de Fala (STT) | Servidor PC | iFlytek Speech Dictation API | Áudio para texto |
| Raciocínio com Modelo de Grande Porte (LLM) | Servidor PC | Spark Large Model Spark Lite | Gera respostas inteligentes |
| Texto para Fala (TTS) | Servidor PC | iFlytek Speech Synthesis API | Texto para áudio |
Preparação de Hardware
Para executar esta demonstração, você precisa do seguinte hardware:
- Um dispositivo reCamera (suporta todas as variantes de reCamera)
- Um computador PC (para executar o serviço de processamento de voz, deve estar na mesma LAN que a reCamera)
Você pode escolher qualquer versão da reCamera com base em suas necessidades de implantação:
- reCamera 2002 Series (Wi-Fi)
- reCamera Gimbal
- reCamera HQ PoE (Ethernet + PoE)
Observação: A versão PoE não oferece suporte a Wi-Fi e deve ser conectada à mesma rede local por meio de um switch compatível com PoE.
| reCamera 2002 Series | reCamera Gimbal | reCamera HQ PoE |
|---|---|---|
 |  |  |
Configurando a Demonstração
Etapa 1: Configurar a reCamera
Primeiro, siga o guia oficial de primeiros passos para concluir a configuração básica da reCamera: reCamera Getting Started
Após concluir a configuração inicial, certifique-se de que o dispositivo esteja ligado e devidamente conectado à rede. Em seguida, acesse o endereço 192.168.42.1 por meio de um navegador para fazer login na reCamera e entrar no espaço de trabalho do Node-RED.
Se você conseguir acessar com sucesso a interface de fluxo do Node-RED, conforme mostrado abaixo, a configuração estará concluída.

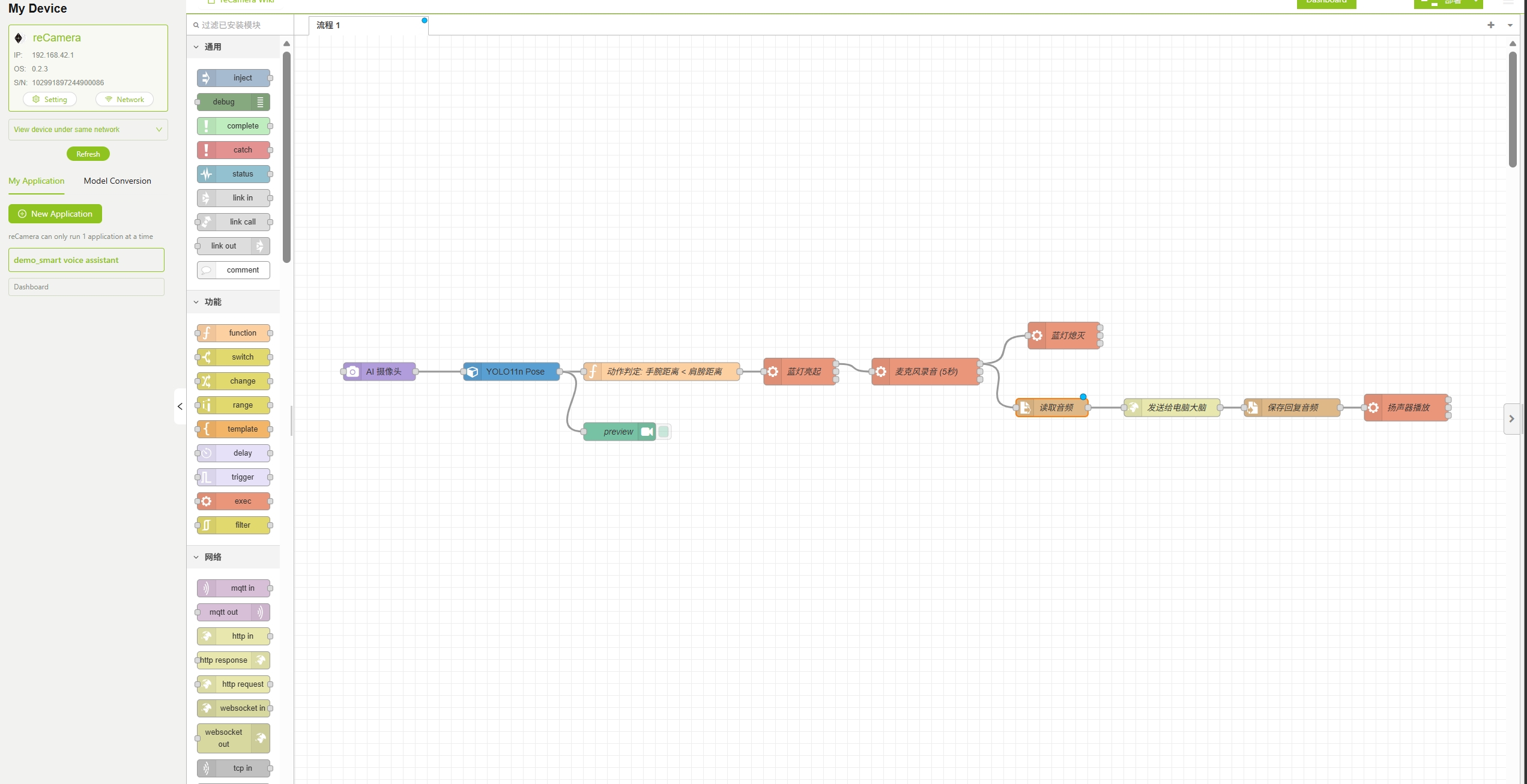
Etapa 2: Importar o Fluxo do Node-RED
Esta demonstração fornece um arquivo de fluxo pré-configurado com todos os nós e conexões necessários para o assistente de voz inteligente já configurados. Você precisa seguir as etapas abaixo para fazer algumas configurações a fim de executar corretamente este projeto.
Crie um novo aplicativo, depois baixe o arquivo de fluxo do Assistente de Voz com IA na SenseCraft AI Platform e importe-o diretamente para a reCamera. Para tutoriais do SenseCraft AI, consulte o link Access SenseCraft AI reCamera Dashboard.
Se você conseguir acessar com sucesso a interface de fluxo do Node-RED, conforme mostrado abaixo, o fluxo foi importado com êxito.
Etapa 3: Configurar os Parâmetros do Fluxo
Após importar o fluxo, você precisa modificar os parâmetros nas seções 3.1 a 3.5 abaixo de acordo com o seu ambiente de rede real e configurações do sistema.
3.1 Nó Model
O nó Model no fluxo vem com vários modelos pré-treinados. Você pode selecionar e configurar vários parâmetros de modelo aqui. Esta demonstração usa o modelo YOLO11n Pose para detectar poses humanas.
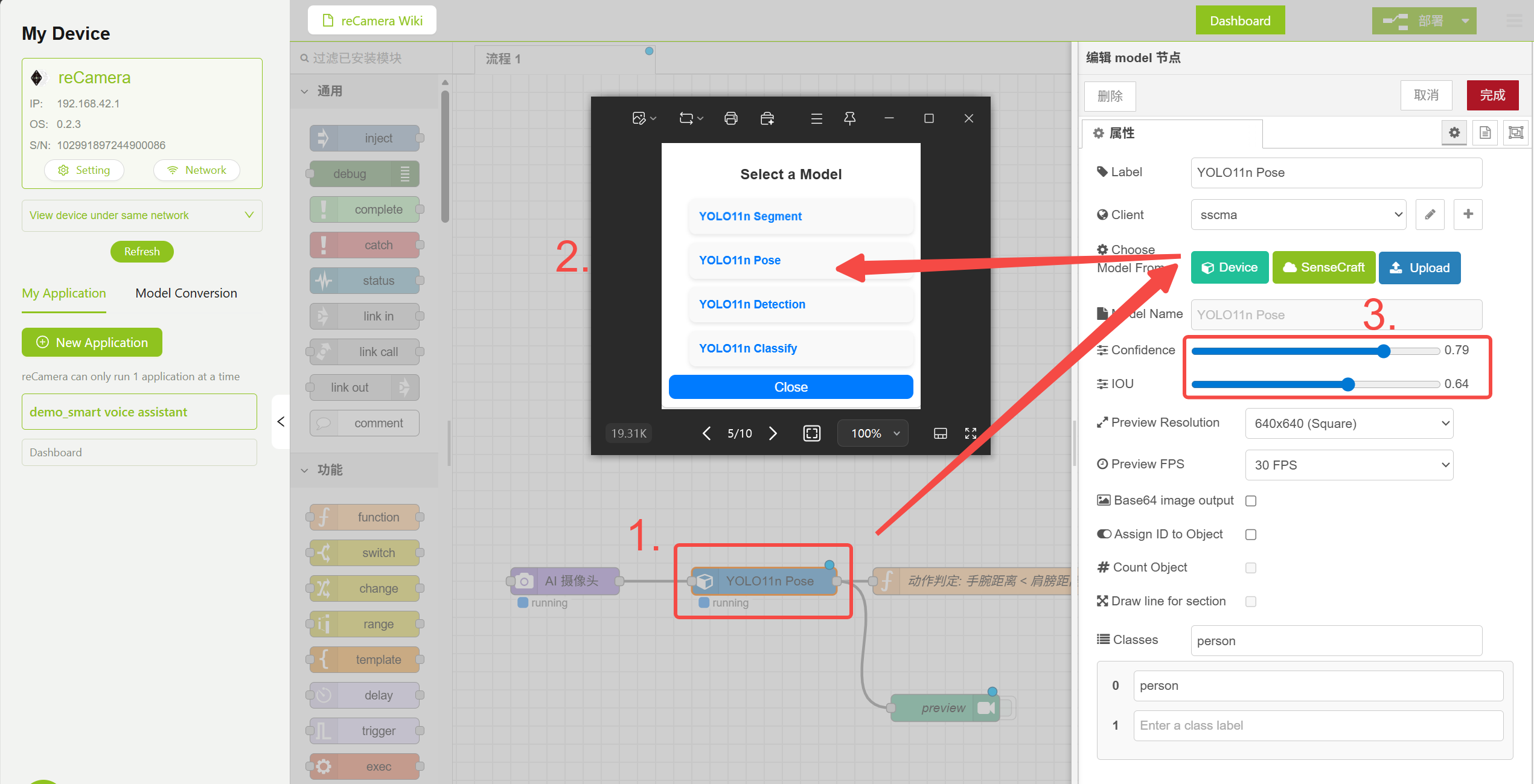
Configuração do Nó Model
3.2 Nó Model — Lógica de Julgamento de Pose
O nó Function contém a lógica de julgamento de pose que determina se deve acionar a interação por voz comparando a distância do ponto-chave do ombro com a distância do ponto-chave do cotovelo. Você pode ajustar os parâmetros de Confidence e IOU no nó Model para reduzir falsos positivos ou modificar o código lógico no nó Function abaixo para implementar recursos adicionais.
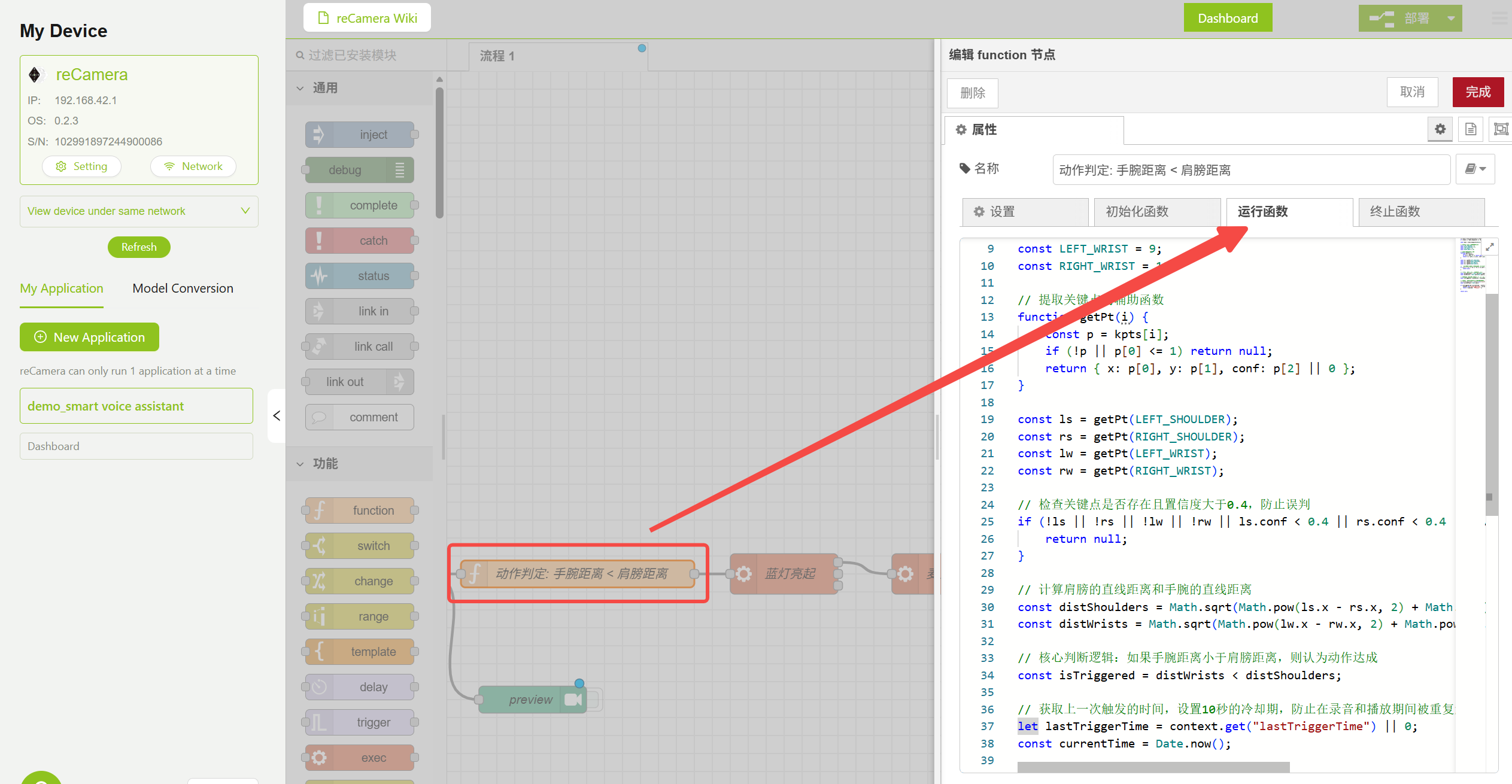
Configuração do Nó Function de Julgamento de Pose
3.3 Nó Exec — Controle de LED e Gravação
O fluxo usa nós Exec para executar comandos do sistema para controlar o LED e a gravação. Clique duas vezes no nó correspondente e modifique a senha root da reCamera de acordo com a sua configuração real:
echo "your_Password" | sudo -S sh -c 'echo 1 > /sys/class/leds/blue/brightness'
- Ligar e desligar o LED azul (indicando que a gravação foi iniciada)
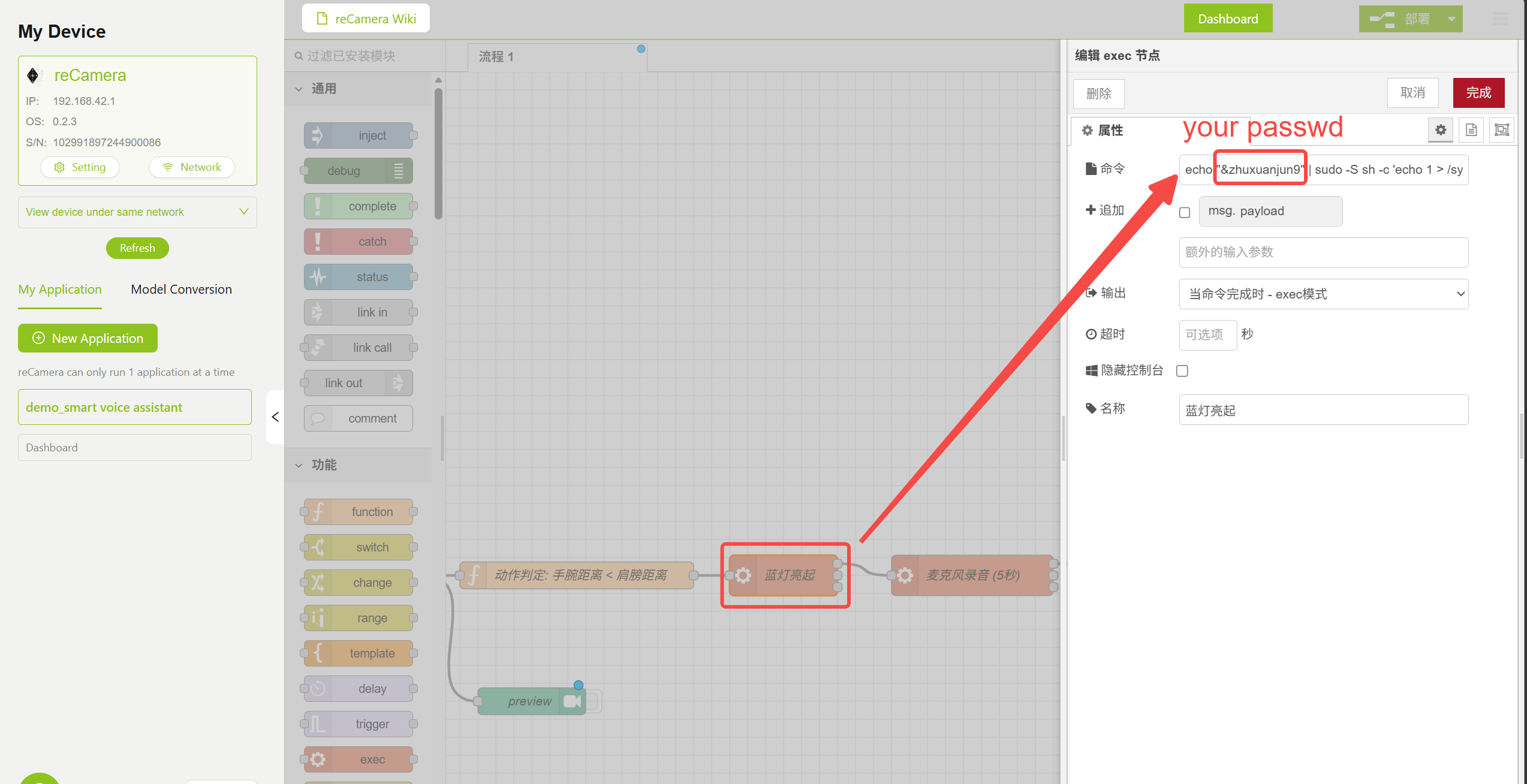
Configuração de Parâmetros do Nó Turn On LED
3.4 Nó HTTP Request — Endereço de Envio de Áudio
Encontre o nó HTTP Request no fluxo e modifique a URL para o endereço do seu servidor PC. Isso exige que você conclua a Etapa 4 e execute primeiro o server.py, depois preencha o endereço na posição correspondente mostrada abaixo.
http://<PC_IP_ADDRESS>:5000/interact
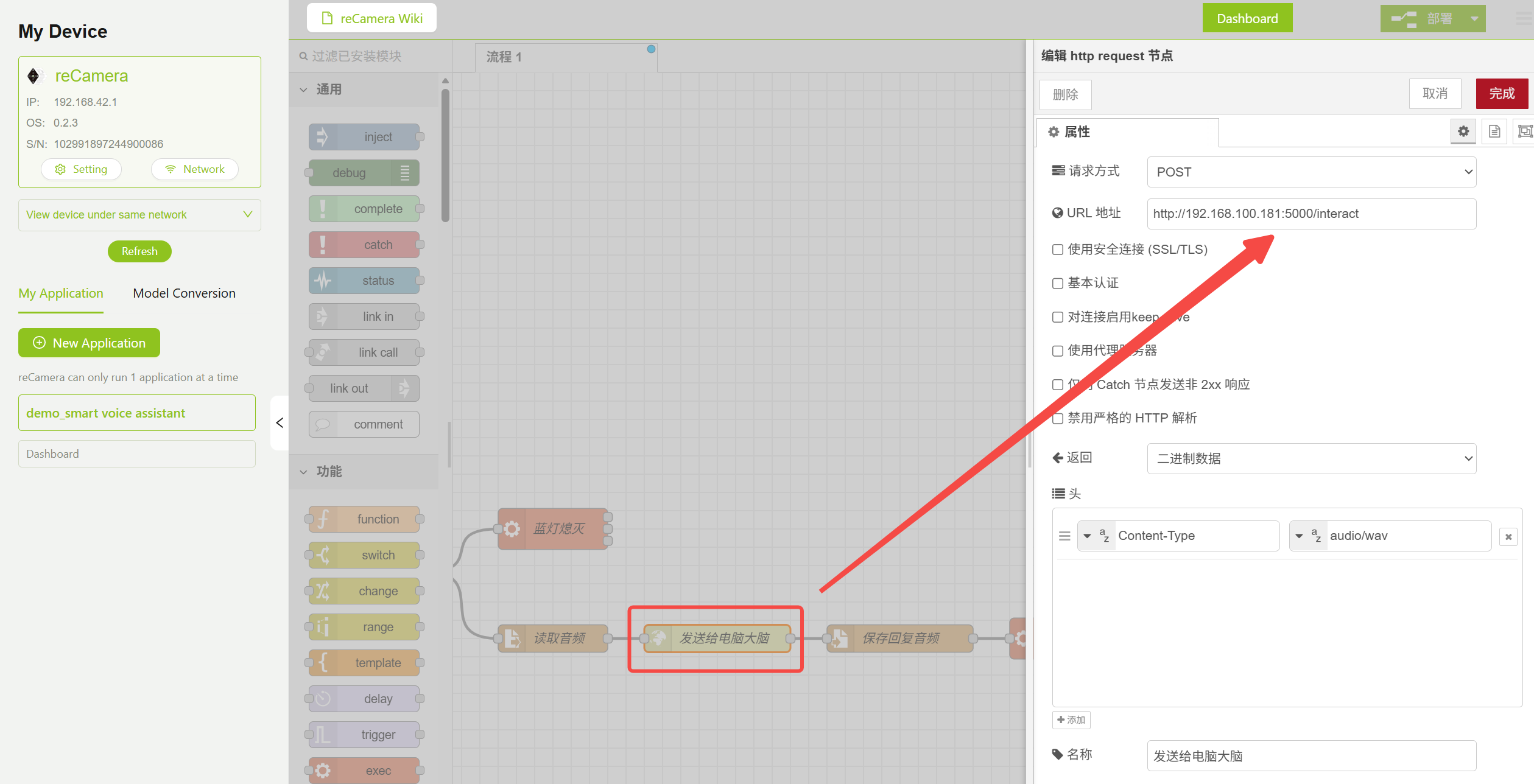
Configuração de Parâmetros do Nó HTTP Request
3.5 Nó Exec — Reprodução de Áudio
O áudio retornado é reproduzido por meio do comando aplay. Você precisa especificar os parâmetros de áudio corretos para corresponder ao formato de saída do modelo TTS (16kHz, mono, 16 bits):
aplay -D hw:1,0 -f S16_LE -c 1 -r 16000 /tmp/reply.wav
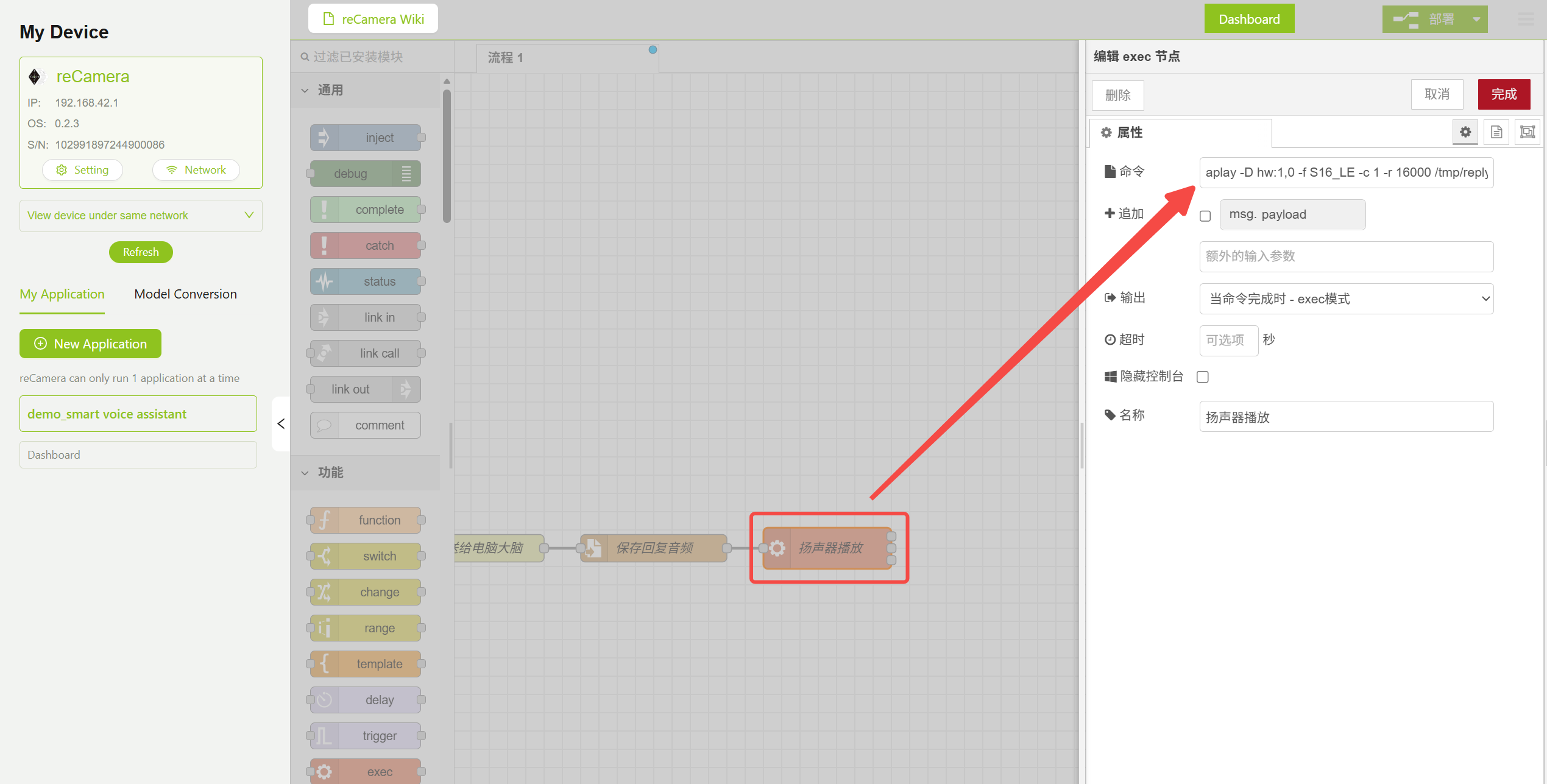
Configuração de Parâmetros do Nó de Reprodução de Áudio
Etapa 4: Implantar o Serviço de Processamento de Voz no PC
O serviço de processamento de voz é executado no PC e é responsável por concluir todo o pipeline de processamento de voz STT → LLM → TTS.
4.1 Pré-requisitos
Certifique-se de que o seguinte ambiente esteja instalado no seu PC:
- Python 3.8+
- Gerenciador de pacotes pip
4.2 Obter o código e instalar dependências
Obtenha o código Python do lado do servidor para o Assistente de Voz com IA a partir do repositório. Após baixar o código do projeto para o seu PC, entre no diretório do serviço e instale as dependências Python:
cd server/
pip install -r requirements.txt
As principais dependências incluem:
| Pacote | Finalidade |
|---|---|
| Flask | Framework de serviço HTTP |
| websocket-client | Comunicação com a API da iFlytek |
| certifi | Verificação de certificado SSL |
| pydub | Processamento de áudio |
4.3 Configurar chaves de API
Antes de executar o serviço, você precisa configurar as chaves de API da iFlytek. Acesse a Plataforma Aberta iFlytek para registrar uma conta e ativar os três serviços a seguir:
| Serviço | Finalidade | Link de ativação |
|---|---|---|
| Speech Dictation (STT) | Converter a fala do usuário em texto | iFlytek Speech Dictation |
| Spark Large Model (LLM) | Gerar respostas inteligentes com base em texto | iFlytek Spark Large Model |
| Speech Synthesis (TTS) | Converter o texto da resposta em fala | iFlytek Speech Synthesis |
Após a ativação, preencha suas chaves de API em server.py:
# 1. STT Speech Recognition Configuration
STT_APPID = "your_APPID"
STT_APISecret = "your_APISecret"
STT_APIKey = "your_APIKey"
# 2. TTS Speech Synthesis Configuration
TTS_APPID = "your_APPID"
TTS_APISecret = "your_APISecret"
TTS_APIKey = "your_APIKey"
# 3. LLM Spark Large Model Configuration (Spark Lite)
LLM_APPID = "your_APPID"
LLM_APISecret = "your_APISecret"
LLM_APIKey = "your_APIKey"
Este demo usa o modelo Spark Lite (gratuito). Você também pode alternar para uma versão de modelo mais avançada, conforme necessário, ou usar grandes modelos de outros provedores.
4.4 Iniciar o serviço
python server.py

Log de inicialização do servidor
Após o serviço iniciar, ele aguardará solicitações de áudio da reCamera. Certifique-se de que o firewall do PC permita conexões de entrada na porta 5000 e que o PC e a reCamera estejam na mesma LAN.Etapa 5: Executar o demo
- Certifique-se de que
server.pyno PC esteja iniciado e em execução - Clique em Deploy no Node-RED para implantar o fluxo de trabalho
- Fique em frente à reCamera e faça um gesto de braços cruzados (distância entre ombros menor que a distância entre cotovelos)
- O LED azul na reCamera acende, indicando que a gravação foi iniciada
- Fale sua pergunta no microfone
- Após o LED azul apagar, a reCamera envia o áudio para o servidor e reproduz a resposta depois de recebê-la.
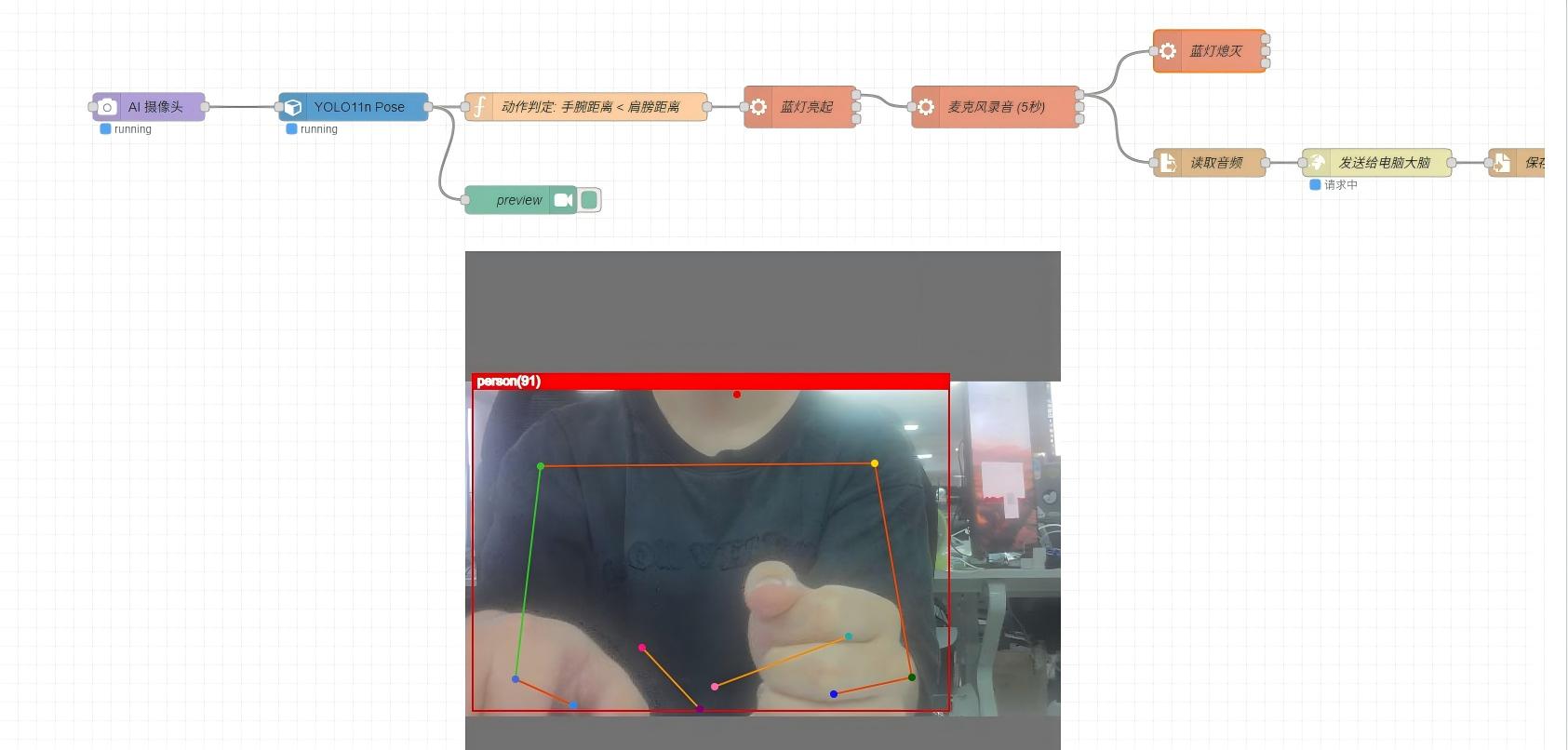
Acionando o fluxo de conversa por voz
Received reCamera audio,length:160044 bytes
User said:Hi,who are you?
LLM is thinking……
LLM reply:Hi,I′m the voice assistant on your smart camera reCamera.I'm here to help you with any questions or concerns you may have.
Generating speech……
Speech delivered! Waiting for next interaction.
192.168.4.53--[11/Jun/2026 16:38:14]"POST /interact HTTP/1.1" 200 -

Log do servidor
Detalhes do fluxo de trabalho
A lógica de alto nível de todo o fluxo de trabalho é a seguinte:
-
Entrada de vídeo e detecção de pose A câmera captura continuamente quadros de vídeo, e o modelo de estimativa de pose YOLO11 detecta os pontos-chave do corpo humano (17 pontos-chave no total, incluindo ombros, cotovelos, pulsos, etc.).
-
Julgamento de gatilho por gesto O nó Function calcula a distância entre os pontos-chave dos ombros esquerdo e direito e a distância entre os pontos-chave dos cotovelos esquerdo e direito. Quando distância entre ombros < distância entre cotovelos, isso é determinado como um gesto de gatilho (ou seja, pose de braços cruzados).
-
Processo de gravação Após o gatilho: ligar o LED azul → gravar áudio → desligar o LED azul.
-
Processamento de áudio e geração de diálogo Após a conclusão da gravação, os dados de áudio são enviados por POST para o serviço Flask do PC via HTTP Request, executando:
- STT: a API iFlytek Speech Dictation converte o áudio em texto
- LLM: o Spark Large Model (Spark Lite) gera respostas inteligentes com base na entrada do usuário
- TTS: a API iFlytek Speech Synthesis converte o texto da resposta em áudio
-
Reprodução de áudio O PC retorna o áudio WAV, e a reCamera reproduz a voz de resposta por meio do comando
aplay.
Notas
- O intervalo de gravação atual está definido para 10 segundos. Se o tempo de processamento STT → LLM → TTS exceder esse intervalo, múltiplos gatilhos podem causar congestionamento no pipeline. Recomenda-se controlar a contagem de palavras da resposta do LLM (o prompt de sistema atual a limita a 50 palavras ou menos) para reduzir o tempo de processamento.
- Se o congestionamento fizer com que a CPU deixe de responder, você pode ajustar o atributo Confidence no nó Model para reduzir falsos positivos e controlar a frequência de gatilho.
- Ao reproduzir o áudio retornado usando
aplay, especifique os parâmetros corretos (-f S16_LE -c 1 -r 16000), caso contrário a reprodução pode não funcionar corretamente. Consulte o áudio gerado pelo TTS para parâmetros específicos.
Suporte técnico e discussão sobre o produto
Obrigado por escolher nossos produtos! Se você precisar de orientação sobre metas específicas de personalização ou quiser estender ainda mais o fluxo de trabalho, sinta-se à vontade para entrar em contato conosco. Estamos aqui para fornecer diferentes níveis de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.