GPT-OSS Rodando Ao Vivo no reComputer Jetson!
Introdução
Isto é muito mais do que um simples exercício de portabilidade técnica - é uma exploração do que é possível na borda. Neste artigo, demonstrarei como um modelo de linguagem grande open-source de 20 bilhões de parâmetros ganha vida em dispositivos de borda como o Nvidia Jetson Orin Nx.

A série NVIDIA Jetson se destaca como uma plataforma de computação de borda de primeira linha, conhecida por sua excepcional eficiência energética e formato compacto. Enquanto isso, o GPT-OSS-20B representa o estado da arte dos modelos de linguagem grandes open-source disponíveis gratuitamente. Sua convergência não apenas mostra o potencial não explorado dos dispositivos de borda, mas também inaugura novas possibilidades para aplicações de IA offline.
Pré-requisitos
- reComputer Super J4012
Neste wiki, concluiremos as seguintes tarefas usando o reComputer Super J4012, mas você também pode tentar usar outros dispositivos Jetson.

Os passos subsequentes envolverão a configuração de múltiplos ambientes Python no Jetson. Recomendamos instalar o Conda no dispositivo Jetson:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
Instalar o llama.cpp
Primeiro, precisamos instalar o mecanismo de inferência llama.cpp no Jetson. Execute os seguintes comandos na janela de terminal do Jetson.
sudo apt update
sudo apt install -y build-essential cmake git
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --parallel
Após a compilação, todos os arquivos executáveis para o llama.cpp serão gerados em build/bin.
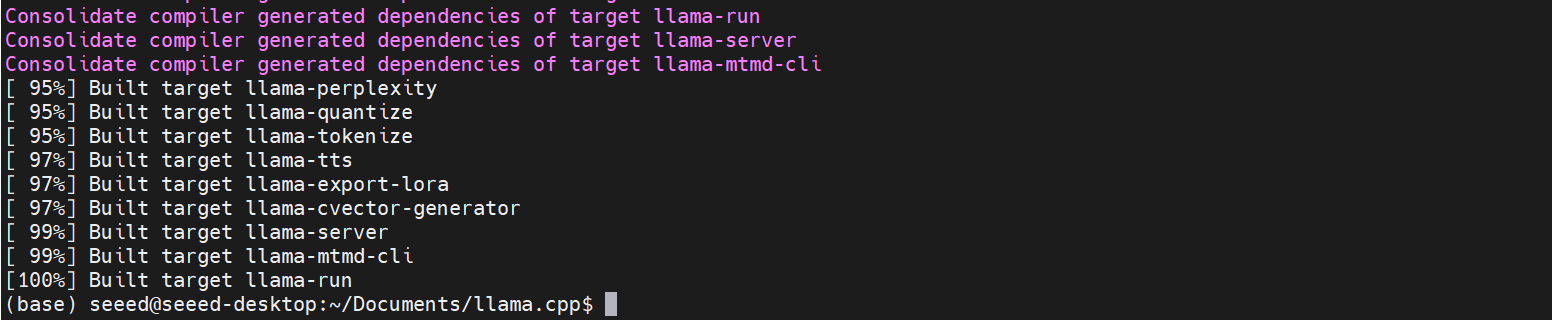
O processo de compilação geralmente leva cerca de 2 horas.
Preparar o Modelo GPT-OSS
Passo 1. Baixe o GPT-OSS-20B do Huggingface e envie para o Jetson.

Passo 2. Instale as dependências necessárias para a conversão do modelo.
conda create -n gpt-oss python=3.10
conda activate gpt-oss
cd /home/seeed/Documents/llama.cpp # cd `path_of_llama.cpp`
pip install .
Passo 3. Execute o processo de conversão do modelo.
python convert_hf_to_gguf.py --outfile /home/seeed/Downloads/gpt-oss /home/seeed/Documents/gpt-oss-gguf/
# python convert_hf_to_gguf.py --outfile <path_of_input_model> <path_of_output_model>
Passo 4. Quantização do Modelo.
./build/bin/llama-quantize /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf /home/seeed/Documents/gpt-oss-gguf-Q4/Gpt-Oss-32x2.4B-Q4.gguf Q4_K
# ./build/bin/llama-quantize <path_of_f16_gguf_model> <path_of_output_model> <quantization_method>
Iniciar o GPT-OSS pelo llama.cpp
Agora podemos tentar iniciar o programa de inferência no terminal do Jetson.
./build/bin/llama-cli -m /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf -ngl 40
Substitua o caminho do modelo conforme necessário.
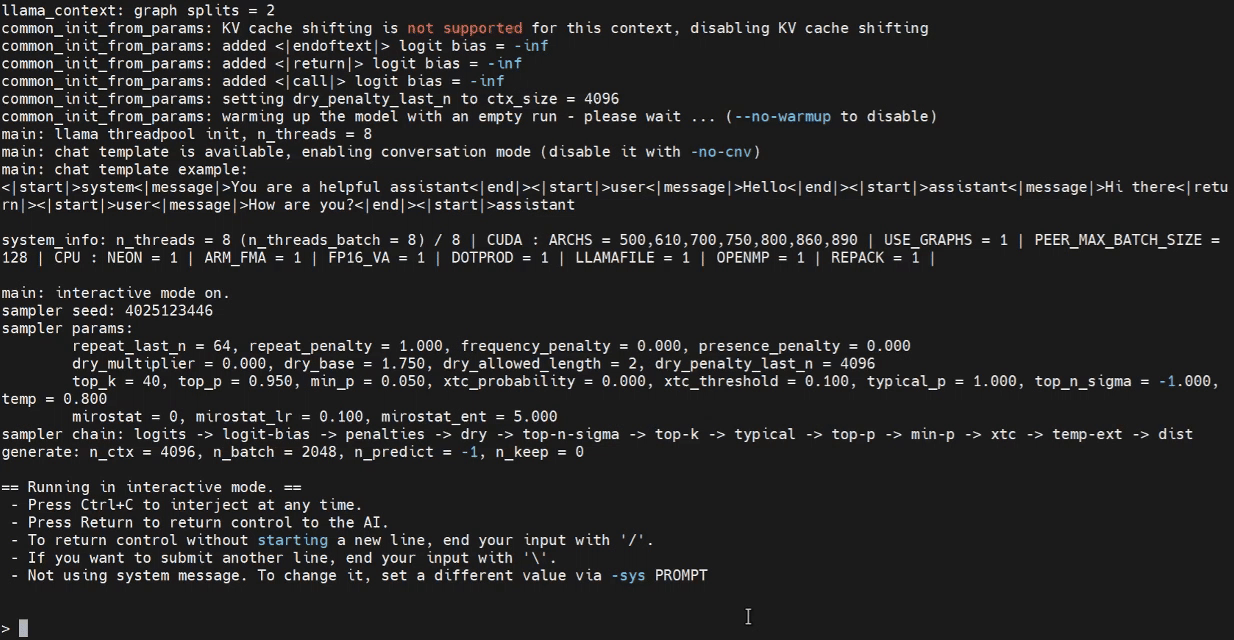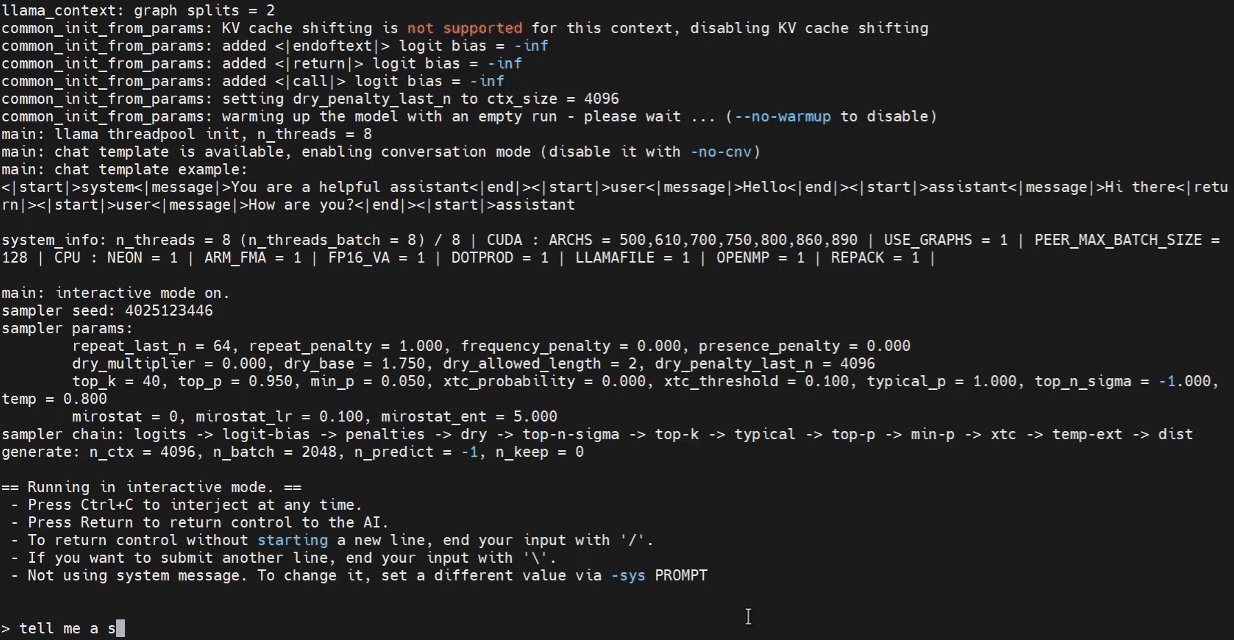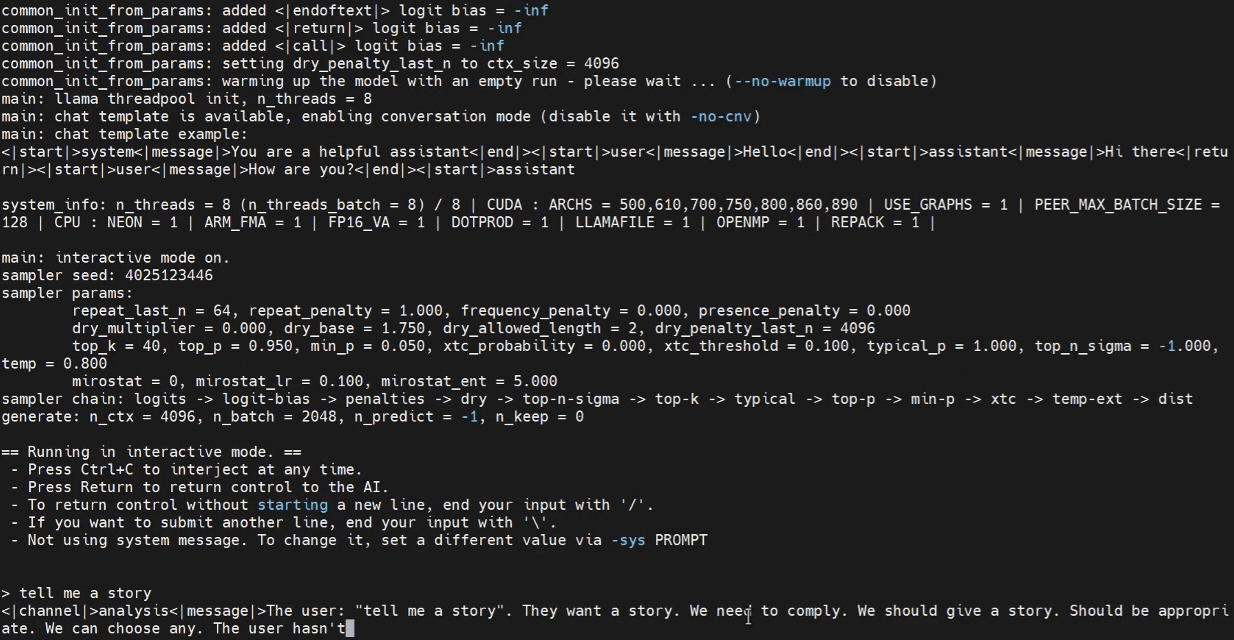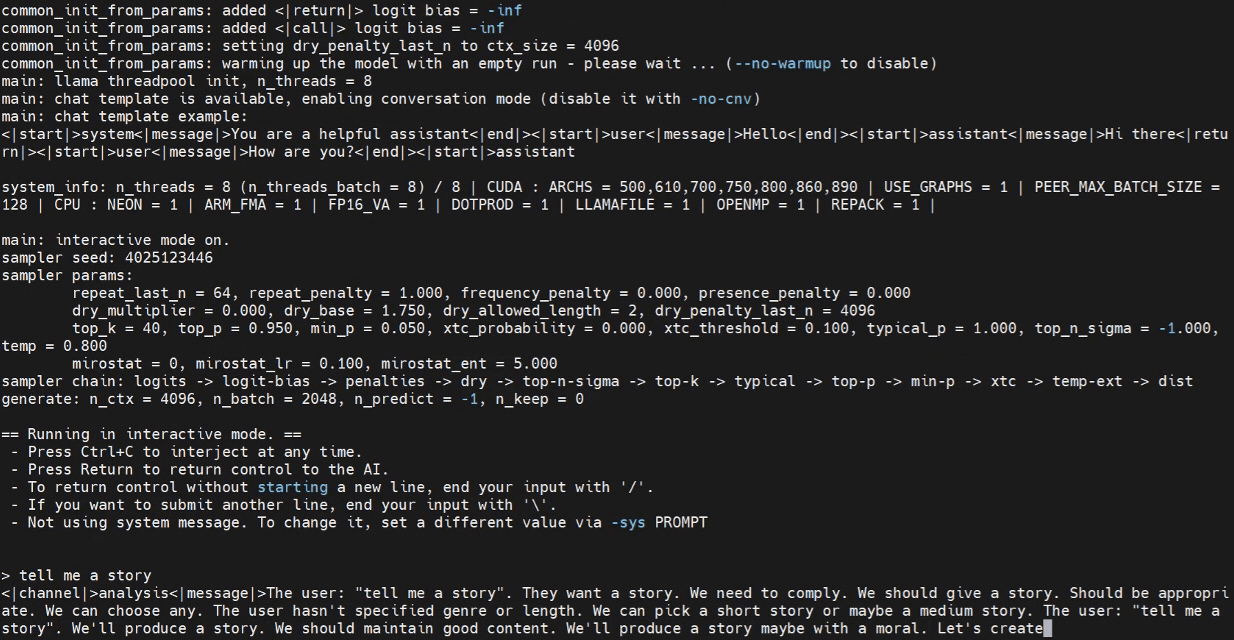
Inferência com WebUI (Opcional)
Se você quiser acessar o modelo por meio de uma interface UI, pode instalar o OpenWebUI no Jetson para isso. Abra um novo terminal no Jetson e digite o seguinte comando:
conda create -n open-webui python=3.11
conda activate open-webui
pip install open-webui
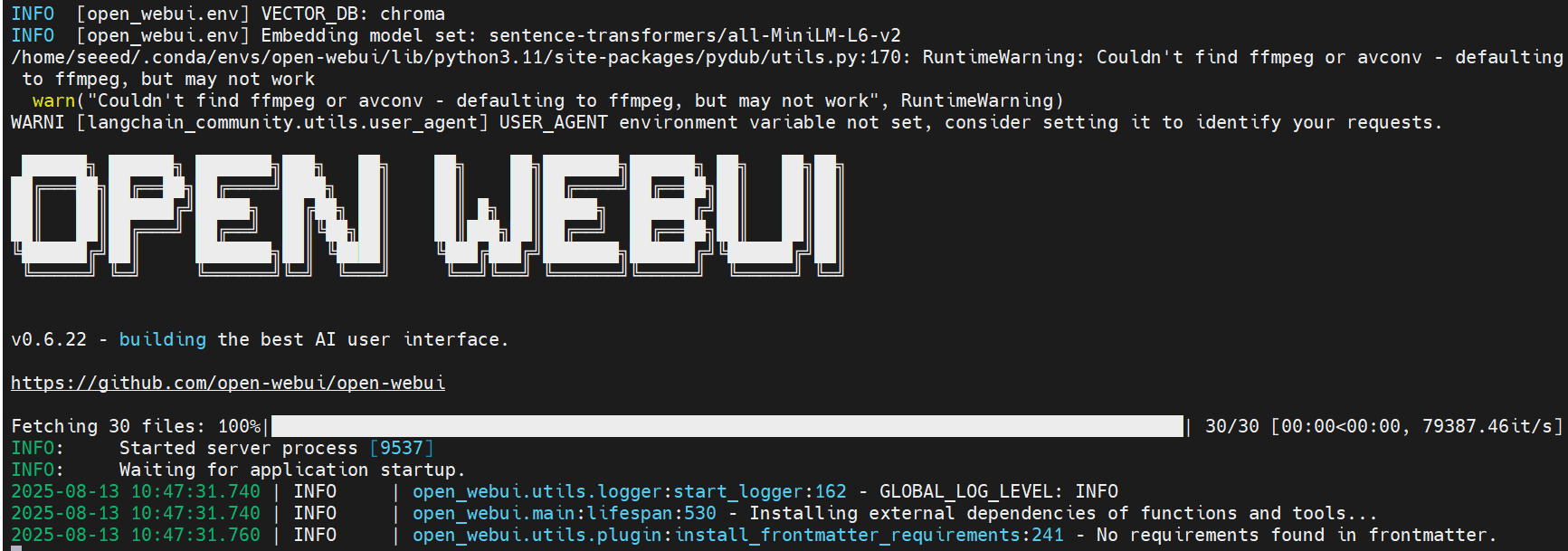
open-webui serve
Ao iniciar o OpenWebUI, serão instaladas dependências e baixados modelos — tenha paciência.
Quando a configuração estiver concluída, você deverá ver no terminal logs semelhantes a estes.
Em seguida, abra seu navegador e acesse http://<ip-of-jetson>:8080 para iniciar o Open WebUI.
Se você estiver abrindo isto pela primeira vez, siga as instruções para configurar sua conta.
Vá para ⚙️ Admin Settings → Connections → OpenAI Connections para definir a URL como: http://127.0.0.1:8081. Depois de salvar, o Open WebUI começará a usar seu servidor local Llama.cpp como backend!
Demonstração do Efeito
Por fim, demonstrarei o desempenho real de inferência do modelo GPT-OSS-20B em um NVIDIA Jetson Orin NX por meio de um vídeo demonstrativo.
Referências
- https://hyd.ai/2025/03/07/llamacpp-on-jetson-orin-agx/
- https://docs.openwebui.com/getting-started/quick-start/starting-with-llama-cpp
- https://github.com/open-webui/open-webui
- https://huggingface.co/openai/gpt-oss-20b
- https://www.seeedstudio.com/tag/nvidia.html
Suporte Técnico & Discussão de Produto
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.