Introdução ao Jetson-Claw no Orin Nano / NX 8GB

Este wiki apresenta passo a passo uma construção prática de inicialização do Jetson-Claw para Jetson Orin Nano 8GB e Jetson Orin NX 8GB. Toda a pilha é executada localmente no Jetson: instalamos o nanobot, expandimos o espaço de swap para um carregamento de modelo mais seguro, compilamos o llama.cpp com CUDA, baixamos um modelo GGUF Qwen3.5 4B, fazemos o nanobot usar um backend local llama.cpp e, por fim, conectamos o bot ao Feishu para que você possa controlá‑lo via chat.
Em comparação com uma implantação OpenClaw maior, o nanobot é mais adequado para esta configuração de entrada do Jetson-Claw porque é muito mais leve, inicia mais rápido, é mais fácil de ler e modificar e já oferece suporte a Feishu além de backends locais compatíveis com OpenAI. Em um Jetson de 8 GB, essa sobrecarga de execução menor deixa mais espaço para o próprio modelo local. Se mais tarde você precisar de um ecossistema de plugins maior ou de um fluxo de trabalho com vários componentes mais pesado, ainda poderá migrar para o OpenClaw.
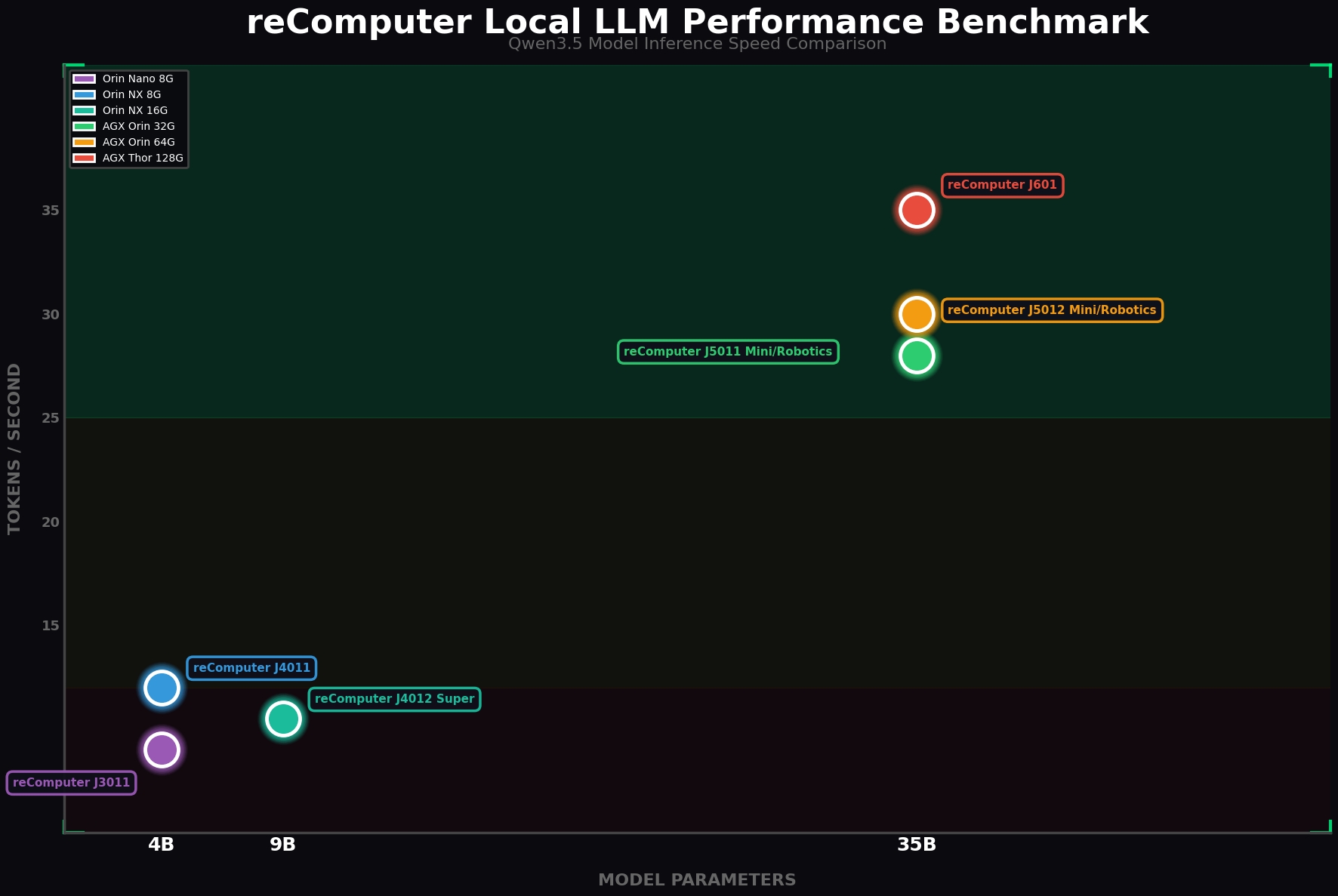
Benchmark
Aqui está listada a performance de LLMs locais para diferentes módulos Jetson. Após nossa verificação, o modelo 4B é a escolha ideal para configurar um sistema capaz de executar tarefas específicas! Quanto maior o tamanho de parâmetros do modelo, melhor será o desempenho! Você pode usar este Benchmark como referência para selecionar um reComputer que atenda às suas necessidades.
O que você irá construir
- Um assistente de IA local leve baseado em
nanobot - Um servidor HTTP
llama.cppcompatível com OpenAI executando no Jetson - Um modelo local
Qwen3.5 4BGGUF - Um bot Jetson conectado ao Feishu que pode ser controlado por chats privados ou menções em grupo
Pré-requisitos
- 1 x Jetson Orin Nano 8GB ou Jetson Orin NX 8GB
- JetPack 6.x já instalado
- Conexão com a Internet para baixar pacotes e modelos
- Recomenda-se pelo menos 20 GB de armazenamento livre
Este guia usa o reComputer Super J3011 como a plataforma Jetson de referência:

nanobot atualmente requer Python 3.11 ou mais recente, então este guia usa um ambiente Miniconda em vez do Python padrão do sistema no Jetson.
Etapa 1. Instalar o nanobot
Primeiro instale as dependências do sistema e o Miniconda:
sudo apt update
sudo apt install -y git curl wget build-essential cmake libcurl4-openssl-dev python3-pip
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
Crie um ambiente Python 3.11 limpo e instale o nanobot:
conda create -y -n jetson-claw python=3.11
conda activate jetson-claw
pip install -U pip
pip install nanobot-ai
Inicialize o diretório de runtime:
nanobot onboard
Após a inicialização, o principal arquivo de configuração estará localizado em:
~/.nanobot/config.json
O nanobot é inspirado no OpenClaw, mas para Orin Nano / NX 8GB ele geralmente é o melhor ponto de partida: menos uso de memória, inicialização mais rápida e menos componentes para depurar.
Etapa 2. Aumentar o espaço de Swap
Executar um modelo local 4B em um Jetson de 8 GB é muito mais estável com swap extra. Isso ajuda durante o carregamento do modelo, a compilação e a inferência com contexto longo.
sudo fallocate -l 8G /var/swapfile
sudo chmod 600 /var/swapfile
sudo mkswap /var/swapfile
sudo swapon /var/swapfile
echo '/var/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
swapon --show
Se você planeja experimentar janelas de contexto maiores ou outros modelos, pode aumentar ainda mais o swap.
Etapa 3. Compilar o llama.cpp com CUDA
Defina os caminhos do CUDA:
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
Clone e compile o llama.cpp:
git clone https://github.com/ggml-org/llama.cpp.git ~/llama.cpp
cd ~/llama.cpp
cmake -B build -DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release
cmake --build build --parallel
Após a compilação, os executáveis principais serão colocados em:
~/llama.cpp/build/bin
Você pode confirmar rapidamente que o binário do servidor está pronto com:
~/llama.cpp/build/bin/llama-server --help
Etapa 4. Baixar os pesos Qwen3.5 4B GGUF
Este guia usa uma quantização GGUF Q4_K_M porque é um equilíbrio prático entre uso de memória e qualidade de resposta para dispositivos Jetson de 8 GB.
Instale o CLI do Hugging Face:
conda activate jetson-claw
pip install -U "huggingface_hub[cli]"
mkdir -p ~/llama.cpp/models/Qwen3.5-4B-GGUF
Em seguida, abra a página do modelo abaixo e baixe o arquivo GGUF Q4_K_M em ~/llama.cpp/models/Qwen3.5-4B-GGUF/:
Escolha o arquivo Qwen3.5-4B.Q4_K_M.gguf na página do Hugging Face:
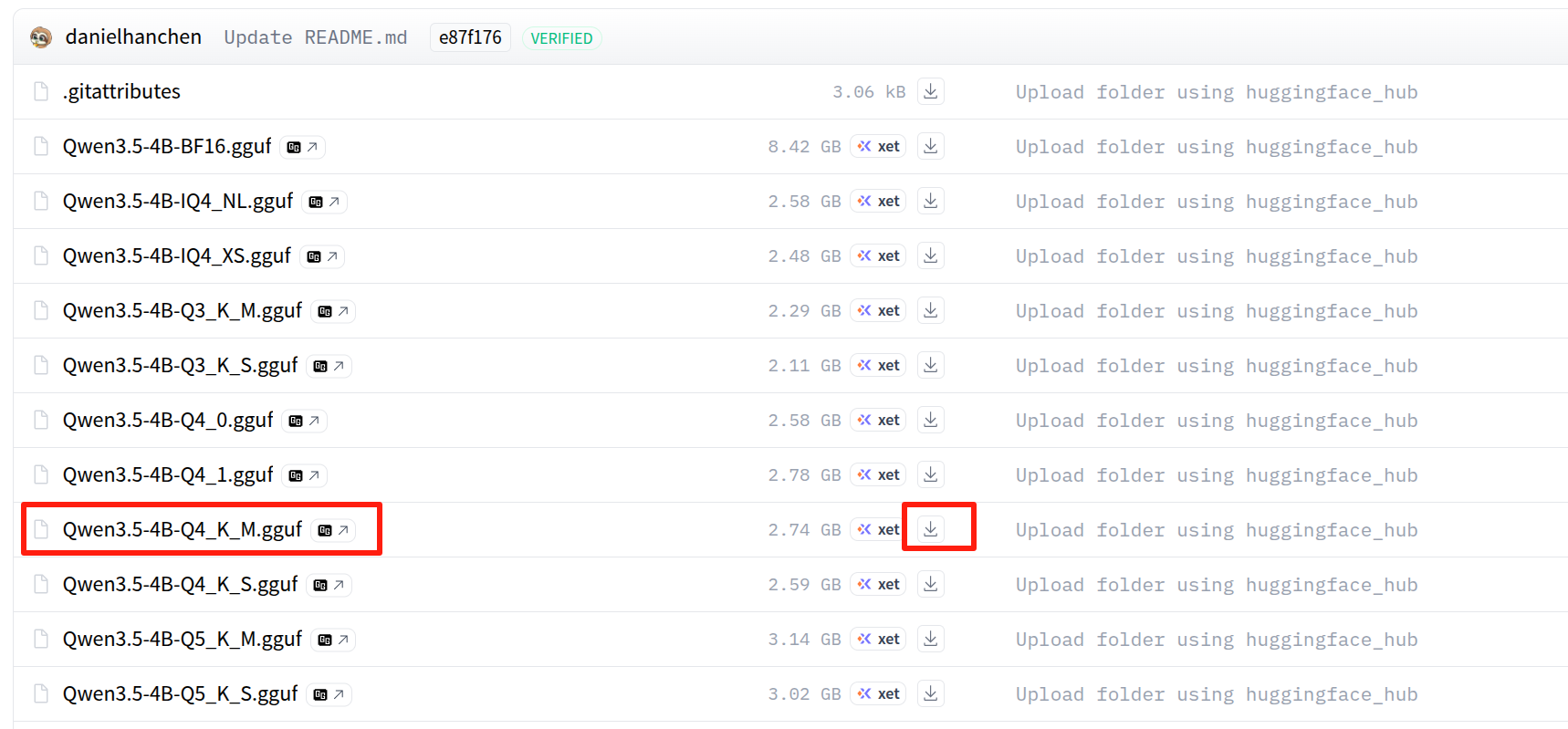
Se o repositório usar o mesmo nome de arquivo do exemplo deste guia, você também pode baixá-lo com:
huggingface-cli download \
unsloth/Qwen3.5-4B-GGUF \
Qwen3.5-4B.Q4_K_M.gguf \
--local-dir ~/llama.cpp/models/Qwen3.5-4B-GGUF
Se o seu arquivo tiver um nome diferente, apenas atualize o caminho no comando de inicialização abaixo. No exemplo aqui, assumimos que o arquivo de modelo é:
~/llama.cpp/models/Qwen3.5-4B-GGUF/Qwen3.5-4B.Q4_K_M.gguf
Etapa 5. Iniciar o llama.cpp como backend local
Inicie o servidor de API local compatível com OpenAI:
conda activate jetson-claw
cd ~/llama.cpp
./build/bin/llama-server \
-m ~/llama.cpp/models/Qwen3.5-4B-GGUF/Qwen3.5-4B.Q4_K_M.gguf \
--alias qwen3.5-4b-local \
-t 6 \
-c 40960 \
--n-gpu-layers 40 \
--reasoning off \
--reasoning-format none \
--host 127.0.0.1 \
--port 8080
Notas sobre parâmetros recomendados:
--alias qwen3.5-4b-local: dá ao modelo local um nome de modelo de API limpo para onanobot-t 6: usa um número moderado de threads de CPU em dispositivos Jetson de entrada-c 40960: fornece uma grande janela de contexto, mas você pode reduzi-la se a memória estiver limitada--n-gpu-layers 40: descarrega o máximo de camadas possível para a GPU do Jetson--reasoning off: mantém a saída mais simples e reduz sobrecarga desnecessária para uma configuração inicial
Se o servidor não iniciar devido à pressão de memória, tente primeiro reduzir -c para 16384 e depois diminuir --n-gpu-layers.
Em outro terminal, verifique a API:
curl http://127.0.0.1:8080/v1/models
Etapa 6. Configurar o nanobot para usar o llama.cpp
Abra o arquivo de configuração:
nano ~/.nanobot/config.json
Em seguida, mescle as seções a seguir na sua configuração:
{
"agents": {
"defaults": {
"workspace": "~/.nanobot/workspace",
"model": "qwen3.5-4b-local",
"provider": "custom",
"maxTokens": 8192,
"contextWindowTokens": 40960,
"temperature": 0.1,
"maxToolIterations": 40,
"reasoningEffort": null
}
},
"channels": {
"sendProgress": true,
"sendToolHints": false,
"feishu": {
"enabled": true,
"appId": "cli_xxx",
"appSecret": "xxx",
"encryptKey": "",
"verificationToken": "",
"allowFrom": ["*"],
"reactEmoji": "THUMBSUP",
"groupPolicy": "mention",
"replyToMessage": false
}
},
"providers": {
"custom": {
"apiKey": "no-key",
"apiBase": "http://127.0.0.1:8080/v1",
"extraHeaders": null
}
},
"gateway": {
"host": "0.0.0.0",
"port": 18790
}
}
Por que isso funciona:
provider: "custom"diz aonanobotpara usar qualquer backend compatível com OpenAIapiBase: "http://127.0.0.1:8080/v1"aponta para ollama-serverlocalmodel: "qwen3.5-4b-local"corresponde ao valor--aliasusado ao iniciar ollama.cpp
Para testes rápidos, allowFrom: ["*"] é conveniente. Para uso em produção, substitua isso pelo seu próprio open_id do Feishu após a validação.
Etapa 7. Conectar o Feishu ao nanobot
Crie um aplicativo Feishu na Feishu Open Platform:
- Abra https://open.feishu.cn/app
- Crie ou abra o aplicativo do seu bot
- Copie o App ID e o App Secret
- Cole-os em
channels.feishu.appIdechannels.feishu.appSecret
Para o modo de Long Connection, encryptKey e verificationToken podem permanecer vazios.
Se você não conseguir encontrar suas credenciais depois, vá para:
- Feishu Open Platform
- Seu aplicativo
Credentials & Basic Info
Importar permissões do Feishu
Para que o manuseio de arquivos, imagens e mensagens ricas funcione corretamente, importe o conjunto de permissões abaixo em:
- Feishu Open Platform
- Seu aplicativo
Permission ManagementBulk Import
{
"scopes": {
"tenant": [
"aily:file:read",
"aily:file:write",
"application:application.app_message_stats.overview:readonly",
"application:application:self_manage",
"application:bot.menu:write",
"cardkit:card:write",
"contact:user.employee_id:readonly",
"corehr:file:download",
"docs:document.content:read",
"event:ip_list",
"im:chat",
"im:chat.access_event.bot_p2p_chat:read",
"im:chat.members:bot_access",
"im:message",
"im:message.group_at_msg:readonly",
"im:message.group_msg",
"im:message.p2p_msg:readonly",
"im:message:readonly",
"im:message:send_as_bot",
"im:resource",
"sheets:spreadsheet",
"wiki:wiki:readonly"
],
"user": [
"aily:file:read",
"aily:file:write",
"im:chat.access_event.bot_p2p_chat:read"
]
}
}
Depois de importar as permissões:
- Crie uma nova versão do aplicativo
- Publique a versão do aplicativo
Caso contrário, as permissões recém-adicionadas podem não entrar em vigor.
Etapa 8. Iniciar o nanobot e testar o controle via Feishu
Mantenha o llama-server em execução em um terminal e, em seguida, inicie o nanobot em outro:
conda activate jetson-claw
nanobot gateway
Verificações úteis:
nanobot status
nanobot channels status
Agora envie uma mensagem para o bot a partir do Feishu:
- Em um chat privado, envie uma mensagem direta
- Em um chat em grupo, mencione o bot se você mantiver
groupPolicy: "mention"
Se você usou allowFrom: ["*"], o bot deve responder imediatamente. Se depois você quiser restringir o acesso, envie primeiro uma mensagem, verifique nos logs do nanobot o seu open_id e substitua ["*"] por esse valor.
Opcional: adicionar uma habilidade de exemplo Jetson-Claw
Se você quiser transformar esta configuração inicial em uma demo Jetson-Claw mais útil, pode adicionar um conjunto de habilidades de exemplo:
git clone https://github.com/jjjadand/JetsonClaw-SKILLS.git ~/JetsonClaw-SKILLS
mkdir -p ~/.nanobot/workspace/skills
cp -r ~/JetsonClaw-SKILLS/person-detection ~/.nanobot/workspace/skills/
Em seguida, reinicie o nanobot gateway, conecte uma câmera USB ao Jetson e peça ao bot no Feishu para verificar se uma pessoa está visível em frente à câmera.
Exemplo de fluxo de monitoramento no Feishu
Depois que a habilidade estiver instalada, você pode enviar uma solicitação pelo aplicativo Feishu para pedir ao Jetson-Claw que verifique o feed da câmera:
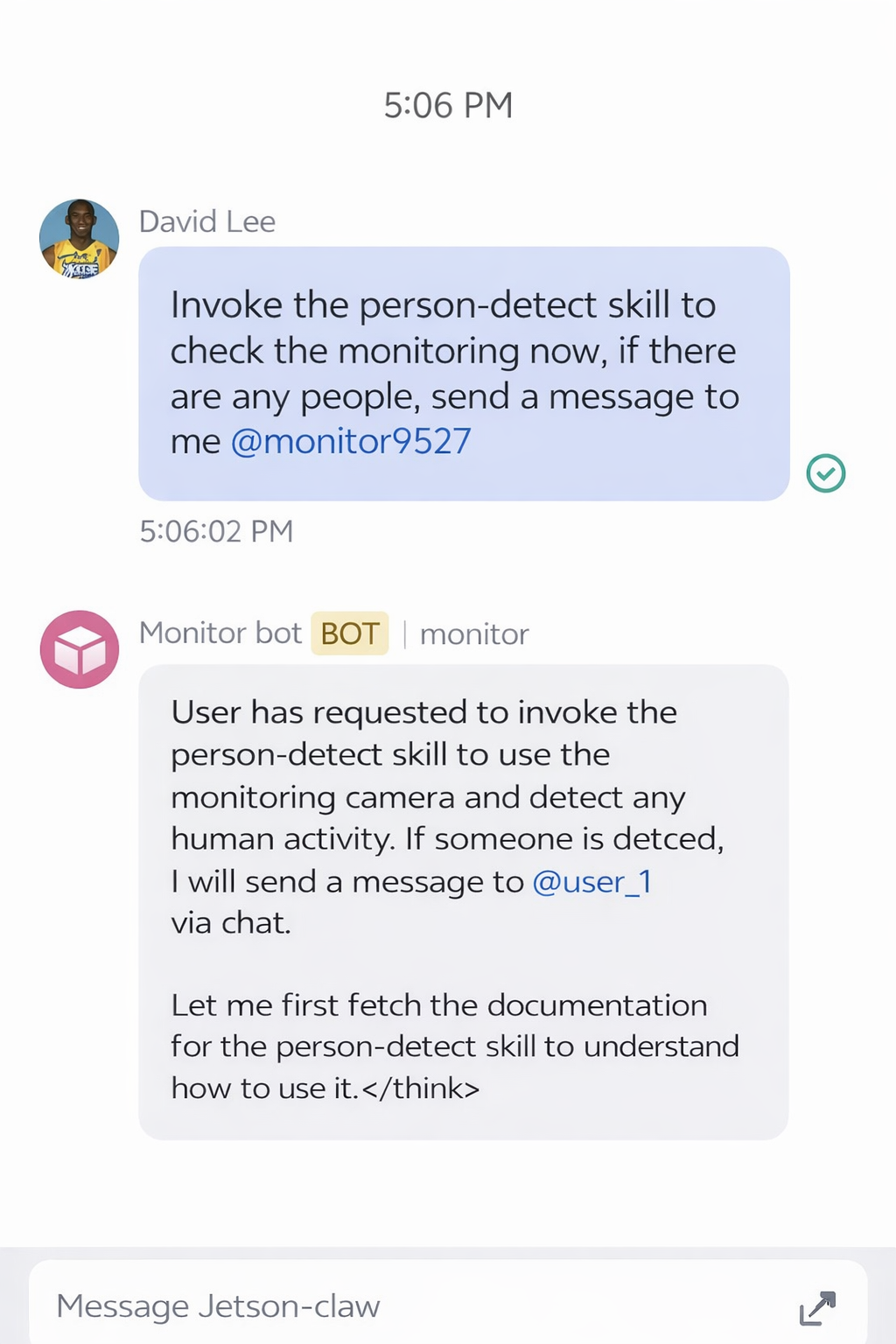
Se nenhuma pessoa for detectada, o resultado do monitoramento pode parecer com isto:
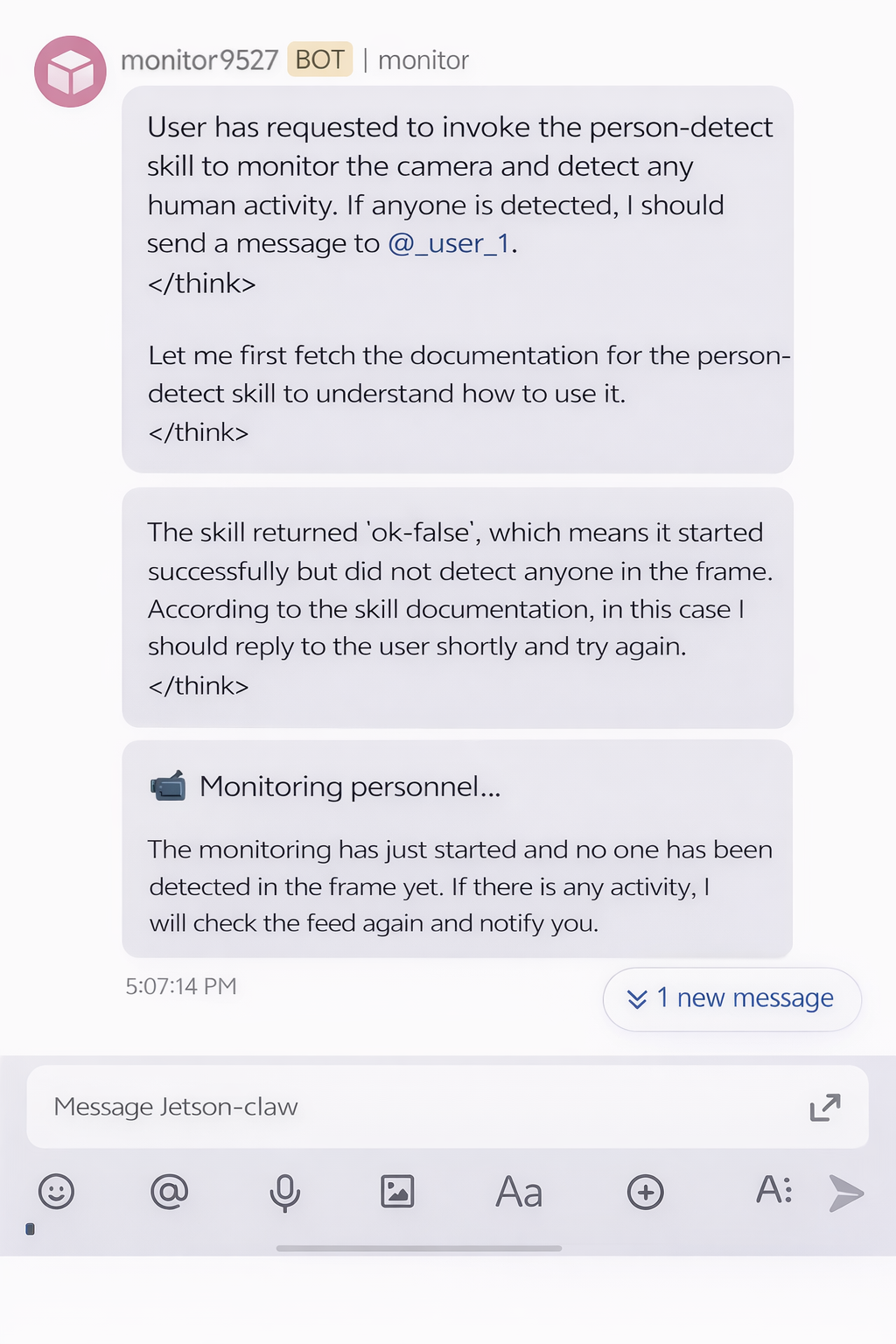
Se uma pessoa for detectada, o Jetson-Claw pode retornar um alerta por meio do Feishu:
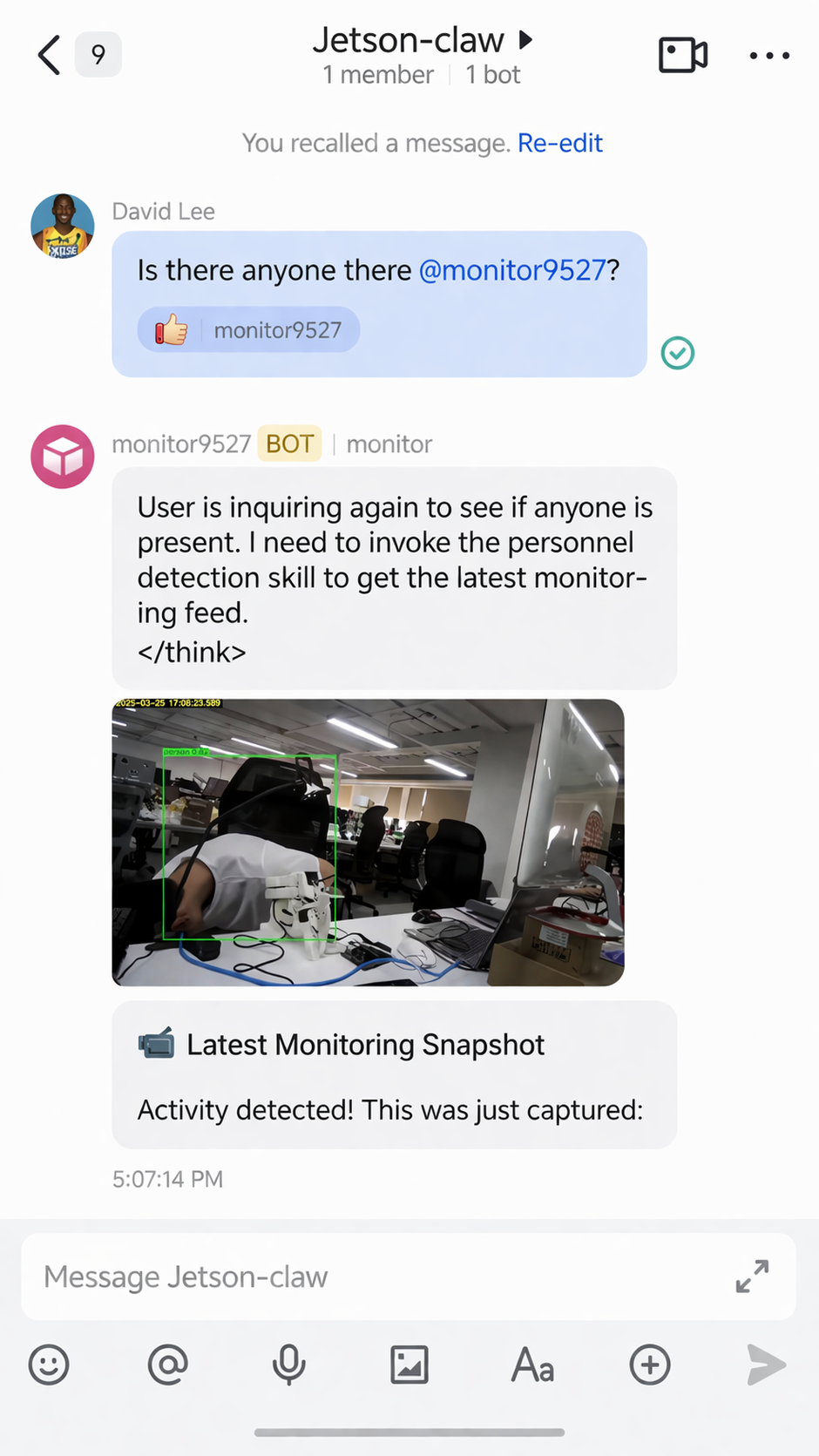
A habilidade de monitoramento também pode enviar de volta a imagem capturada do resultado:

Solução de problemas
- Falha na instalação do
nanobot: certifique-se de estar em um ambiente Python 3.11 llama-serveré encerrado durante o carregamento do modelo: aumente a swap ou reduza-c- O bot do Feishu não responde: verifique App ID, App Secret, permissões importadas e versão publicada do aplicativo
- Mensagens em grupo não acionam o bot: verifique
groupPolicye certifique-se de mencionar o bot - As respostas estão lentas: reduza o tamanho de contexto, diminua o uso simultâneo ou use uma quantização menor
Referências
- https://github.com/HKUDS/nanobot
- https://github.com/ggml-org/llama.cpp
- https://huggingface.co/unsloth/Qwen3.5-4B-GGUF/tree/main
- https://open.feishu.cn/app
- https://github.com/jjjadand/JetsonClaw-SKILLS
- https://wiki.seeedstudio.com/pt-br/local_openclaw_on_recomputer_jetson/
Suporte técnico e discussão de produtos
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.