Introdução ao uso dos braços robóticos SO-ARM100 e SO-ARM101 com LeRobot
Introdução
O SO-10xARM é um projeto de braço robótico totalmente open-source lançado pela TheRobotStudio. Ele inclui o braço seguidor e o braço robótico líder, e também fornece arquivos detalhados para impressão 3D e guias de operação. O LeRobot é dedicado a fornecer modelos, conjuntos de dados e ferramentas para robótica no mundo real em PyTorch. Seu objetivo é reduzir a barreira de entrada da robótica, permitindo que todos contribuam e se beneficiem do compartilhamento de conjuntos de dados e modelos pré-treinados. O LeRobot integra metodologias de ponta validadas para aplicação no mundo real, com foco em aprendizado por imitação. Ele disponibiliza um conjunto de modelos pré-treinados, conjuntos de dados com demonstrações coletadas por humanos e ambientes de simulação, permitindo que os usuários comecem sem a necessidade de montar um robô. Nas próximas semanas, a intenção é ampliar o suporte à robótica no mundo real nos robôs mais econômicos e competentes atualmente disponíveis.
Introdução aos projetos
O kit de robô inteligente SO-ARM10x e reComputer Jetson AI combina perfeitamente o controle de braço robótico de alta precisão com uma poderosa plataforma de computação de IA, fornecendo uma solução completa de desenvolvimento de robôs. Este kit é baseado na plataforma Jetson Orin ou AGX Orin, combinada com o braço robótico SO-ARM10x e o framework de IA LeRobot, oferecendo aos usuários um sistema de robô inteligente aplicável a múltiplos cenários, como educação, pesquisa e automação industrial. Este wiki fornece o tutorial de montagem e depuração para o SO ARM10x e realiza a coleta de dados e o treinamento dentro do framework Lerobot.

Principais recursos
- Open-source e baixo custo: É uma solução de braço robótico open-source e de baixo custo da TheRobotStudio
- Integração com LeRobot: Projetado para integração com a plataforma LeRobot
- Recursos de aprendizado abundantes: Fornece recursos de aprendizado open-source abrangentes, como guias de montagem e calibração, e tutoriais para teste, coleta de dados, treinamento e implantação, para ajudar os usuários a começarem rapidamente e desenvolverem aplicações robóticas.
- Compatível com Nvidia: Faça a implantação deste kit de braço com o reComputer Mini J4012 Orin NX 16 GB.
- Aplicação em múltiplos cenários: É aplicável a áreas como educação, pesquisa científica, produção automatizada e robótica, ajudando os usuários a alcançar operações robóticas eficientes e precisas em várias tarefas complexas.
Novidades:
- Otimização da fiação: Em comparação com o SO-ARM100, o SO-ARM101 apresenta uma fiação aprimorada que evita problemas de desconexão anteriormente observados na junta 3. O novo design de fiação também não limita mais a amplitude de movimento das juntas.
- Diferentes relações de engrenagem para o braço líder: O braço líder agora usa motores com relações de engrenagem otimizadas, melhorando o desempenho e eliminando a necessidade de caixas de engrenagens externas.
- Suporte a novas funcionalidades: O braço líder agora pode seguir o braço seguidor em tempo real, o que é crucial para a futura política de aprendizado, na qual um humano pode intervir e corrigir as ações do robô.
A Seeed Studio é responsável apenas pela qualidade do hardware em si. Os tutoriais são rigorosamente atualizados de acordo com a documentação oficial. Se você encontrar problemas de software ou de dependências de ambiente que não possam ser resolvidos, além de verificar a seção de FAQ no final deste tutorial, relate o problema prontamente na plataforma LeRobot ou no canal do LeRobot no Discord.
Especificações
| Tipo | SO-ARM100 | SO-ARM101 | ||
|---|---|---|---|---|
| Arm Kit | Arm Kit Pro | Arm Kit | Arm Kit Pro | |
| Braço líder | 12x motores ST-3215- C001 (7.4V) com relação de engrenagem 1:345 para todas as juntas | 12x motores ST-3215-C018/ST-3215-C047 (12V) com relação de engrenagem 1:345 para todas as juntas | 1x motor ST-3215- C001 (7.4V) com relação de engrenagem 1:345 apenas para a junta 2 | |
| Braço seguidor | Igual ao SO-ARM100 | |||
| Fonte de alimentação | 5,5 mm × 2,1 mm DC 5 V 4 A | 5,5 mm × 2,1 mm DC 12 V 2 A | 5,5 mm × 2,1 mm DC 5 V 4 A | 5,5 mm × 2,1 mm DC 12 V 2 A (Braço seguidor) |
| Sensor de ângulo | Encoder magnético de 12 bits | |||
| Temperatura de operação recomendada | 0 °C a 40 °C | |||
| Comunicação | UART | |||
| Método de controle | PC | |||
Se você comprar a versão Arm Kit, ambas as fontes de alimentação são de 5V. Se você comprar a versão Arm Kit Pro, use a fonte de alimentação de 5V para a calibração e todas as etapas do braço robótico líder, e a fonte de alimentação de 12V para a calibração e todas as etapas do braço robótico seguidor.
Lista de materiais (BOM)
| Peça | Quantidade | Incluído |
|---|---|---|
| Servo Motos | 12 | ✅ |
| Placa de controle do motor | 2 | ✅ |
| Cabo USB-C 2 pcs | 1 | ✅ |
| Fonte de alimentação2 | 2 | ✅ |
| Presilha de mesa | 4 | ✅ |
| Peças do braço impressas em 3D | 1 | Opção |
Ambiente inicial do sistema
Para Ubuntu x86:
- Ubuntu 22.04
- CUDA 12+
- Python 3.10
- Torch 2.6+
Para Jetson Orin:
- Jetson JetPack 6.0 e 6.1, não suporta 6.1
- Python 3.10
- Torch 2.3+
Sumário
H. Registrar o conjunto de dados
I. Visualizar o conjunto de dados
Guia de impressão 3D
Após a atualização oficial do SO101, o SO100 não terá mais suporte e os arquivos-fonte serão excluídos conforme o oficial, mas os arquivos-fonte ainda podem ser encontrados em nosso Makerworld. No entanto, para usuários que compraram o SO100 anteriormente, os tutoriais e métodos de instalação permanecem compatíveis. A impressão do SO101 é totalmente compatível com a instalação do kit de motor do SO100.
Passo 1: Escolher uma impressora
Os arquivos STL fornecidos estão prontos para impressão em muitas impressoras FDM. Abaixo estão as configurações testadas e sugeridas, embora outras também possam funcionar.
- Material: PLA+
- Diâmetro do bico e precisão: bico de 0,4mm com altura de camada de 0,2mm ou bico de 0,6mm com altura de camada de 0,4mm.
- Densidade de preenchimento: 15%
Passo 2: Configurar a impressora
- Certifique-se de que a impressora esteja calibrada e que o nivelamento da mesa esteja corretamente ajustado usando as instruções específicas da impressora.
- Limpe a mesa de impressão, certificando-se de que esteja livre de poeira ou gordura. Se limpar a mesa usando água ou outro líquido, seque-a.
- Se a sua impressora recomendar, use um bastão de cola comum e aplique uma camada fina e uniforme de cola em toda a área de impressão da mesa. Evite acúmulos ou aplicação irregular.
- Carregue o filamento da impressora usando as instruções específicas da impressora.
- Certifique-se de que as configurações da impressora correspondam às sugeridas acima (a maioria das impressoras possui várias configurações, então escolha as que mais se aproximam).
- Configure para gerar suportes em todos os lugares, mas ignore inclinações maiores que 45 graus em relação à horizontal.
- Não deve haver suportes nos furos de parafuso com eixos horizontais.
Etapa 3: Imprimir as peças
Todas as peças para o líder ou seguidor já estão contidas em um único arquivo, fáceis de imprimir em 3D, corretamente orientadas com o eixo z para cima para minimizar os suportes.
-
Para mesas de impressão de 220mmx220mm (como a Ender), imprima estes arquivos:
-
Para mesas de impressão de 205mm x 250mm (como a Prusa/Up):
Instalar o LeRobot
Ambientes como pytorch e torchvision precisam ser instalados com base na sua versão do CUDA.
- Instale o Miniconda: Para Jetson:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
Ou, para X86 Ubuntu 22.04:
mkdir -p ~/miniconda3
cd miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm ~/miniconda3/miniconda.sh
source ~/miniconda3/bin/activate
conda init --all
- Crie e ative um novo ambiente conda para o lerobot
conda create -y -n lerobot python=3.10 && conda activate lerobot
- Clone o Lerobot:
git clone https://github.com/Seeed-Projects/lerobot.git ~/lerobot
- Ao usar o miniconda, instale o ffmpeg no seu ambiente:
conda install ffmpeg -c conda-forge
Isso geralmente instala o ffmpeg 7.X para a sua plataforma compilado com o codificador libsvtav1. Se o libsvtav1 não for suportado (verifique os codificadores suportados com ffmpeg -encoders), você pode:
- [Em qualquer plataforma] Instalar explicitamente o ffmpeg 7.X usando:
conda install ffmpeg=7.1.1 -c conda-forge
- [Somente no Linux] Instalar as dependências de compilação do ffmpeg e compilar o ffmpeg a partir do código-fonte com libsvtav1, e certificar-se de usar o binário do ffmpeg correspondente à sua instalação com which ffmpeg.
Se você encontrar um erro como este, também pode usar este comando.
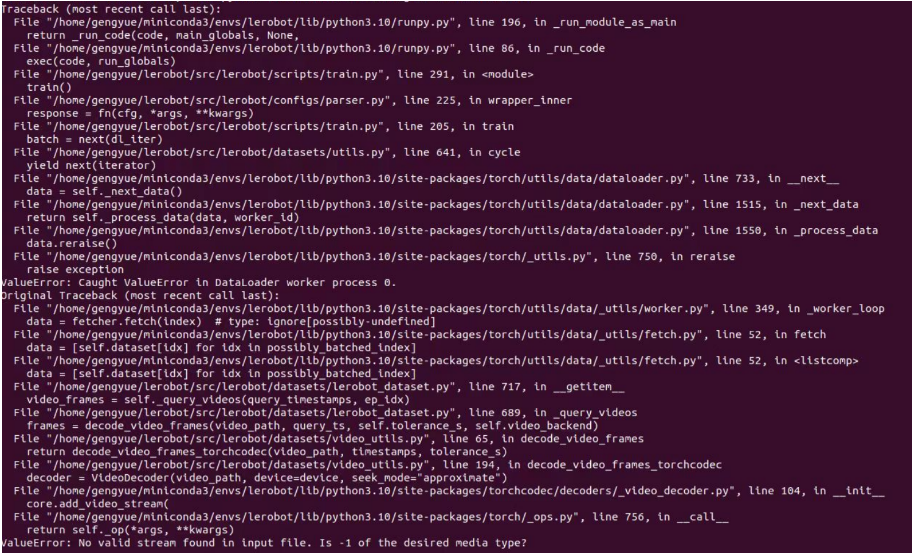
- Instale o LeRobot com dependências para os motores feetech:
cd ~/lerobot && pip install -e ".[feetech]"
Para dispositivos Jetson Jetpack 6.0+ (certifique-se de instalar o Pytorch-gpu e Torchvision a partir da etapa 5 antes de executar esta etapa):
conda install -y -c conda-forge "opencv>=4.10.0.84" # Install OpenCV and other dependencies through conda, this step is only for Jetson Jetpack 6.0+
conda remove opencv # Uninstall OpenCV
pip3 install opencv-python==4.10.0.84 # Then install opencv-python via pip3
conda install -y -c conda-forge ffmpeg
conda uninstall numpy
pip3 install numpy==1.26.0 # This should match torchvision
- Verificar Pytorch e Torchvision
Como instalar o ambiente do lerobot via pip desinstalará o Pytorch e o Torchvision originais e instalará as versões de CPU do Pytorch e do Torchvision, você precisa realizar uma verificação em Python.
import torch
print(torch.cuda.is_available())
Se o resultado impresso for False, você precisa reinstalar o Pytorch e o Torchvision de acordo com o tutorial do site oficial.
Se você estiver usando um dispositivo Jetson, instale o Pytorch e o Torchvision de acordo com este tutorial.
Configurar os motores
- SO101
O processo de calibração e inicialização do servo para o SO-ARM101 é o mesmo do SO-ARM100, tanto em termos de método quanto de código. No entanto, observe que as relações de engrenagem para as três primeiras juntas do Braço Líder SO-ARM101 diferem das do SO-ARM100, portanto é importante distingui-las e calibrá-las com cuidado.
Para configurar os motores, designe um adaptador de servo de barramento e 6 motores para o seu braço líder e, da mesma forma, o outro adaptador de servo de barramento e 6 motores para o braço seguidor. É conveniente rotulá-los e escrever em cada motor se ele é para o seguidor F ou para o líder L e seu ID de 1 a 6. Usamos F1–F6 para representar as juntas 1 a 6 do Braço Seguidor, e L1–L6 para representar as juntas 1 a 6 do Braço Líder. O modelo de servo correspondente, atribuições de juntas e detalhes da relação de engrenagem são os seguintes:
| Modelo de Servo | Relação de Engrenagem | Juntas Correspondentes |
|---|---|---|
| ST-3215-C044(7.4V) | 1:191 | L1 |
| ST-3215-C001(7.4V) | 1:345 | L2 |
| ST-3215-C044(7.4V) | 1:191 | L3 |
| ST-3215-C046(7.4V) | 1:147 | L4–L6 |
| ST-3215-C001(7.4V) / C018(12V) / C047(12V) | 1:345 | F1–F6 |
Agora você deve conectar a fonte de alimentação de 5V ou 12V ao barramento do motor. 5V para os motores STS3215 7.4V e 12V para os motores STS3215 12V. Observe que o braço líder sempre usa os motores de 7.4V, então tome cuidado para conectar a fonte de alimentação correta se você tiver motores de 12V e 7.4V, caso contrário você pode queimar seus motores! Agora, conecte o barramento do motor ao seu computador via USB. Observe que o USB não fornece nenhuma alimentação, e tanto a fonte de alimentação quanto o USB precisam estar conectados.

A seguir estão as etapas de calibração por código, por favor calibre com o servo de fiação de referência na imagem acima
Encontre as portas USB associadas aos seus braços Para encontrar as portas corretas para cada braço, execute o script utilitário duas vezes:
lerobot-find-port
Exemplo de saída:
Finding all available ports for the MotorBus.
['/dev/ttyACM0', '/dev/ttyACM1']
Remove the usb cable from your MotorsBus and press Enter when done.
[...Disconnect corresponding leader or follower arm and press Enter...]
The port of this MotorsBus is /dev/ttyACM1
Reconnect the USB cable.
Lembre-se de remover o USB, caso contrário a interface não será detectada.
Exemplo de saída ao identificar a porta do braço seguidor (por exemplo, /dev/tty.usbmodem575E0031751 no Mac, ou possivelmente /dev/ttyACM0 no Linux):
Exemplo de saída ao identificar a porta do braço líder (por exemplo, /dev/tty.usbmodem575E0032081, ou possivelmente /dev/ttyACM1 no Linux):
Você pode precisar conceder acesso às portas USB executando:
sudo chmod 666 /dev/ttyACM0
sudo chmod 666 /dev/ttyACM1
Configurar seus motores
Use uma fonte de alimentação de 5V para calibrar os motores do Líder (ST-3215-C046, C044, 001).
| Calibração da Junta 6 do Braço Líder | Calibração da Junta 5 do Braço Líder | Calibração da Junta 4 do Braço Líder | Calibração da Junta 3 do Braço Líder | Calibração da Junta 2 do Braço Líder | Calibração da Junta 1 do Braço Líder |
|---|---|---|---|---|---|
 |  |  |  |  |  |
Se você comprar a versão Arm Kit (ST-3215-C001), use uma fonte de alimentação de 5V. Se você comprar a versão Arm Kit Pro, use uma fonte de alimentação de 12V para calibrar o servo (ST-3215-C047/ST-3215-C018).
| Calibração da Junta 6 do Braço Seguidor | Calibração da Junta 5 do Braço Seguidor | Calibração da Junta 4 do Braço Seguidor | Calibração da Junta 3 do Braço Seguidor | Calibração da Junta 2 do Braço Seguidor | Calibração da Junta 1 do Braço Seguidor |
|---|---|---|---|---|---|
 |  |  |  |  |  |
Novamente, certifique-se de que os IDs das juntas dos servos e as relações de engrenagem correspondam estritamente às do SO-ARM101.
Conecte o cabo USB do seu computador e a fonte de alimentação à placa controladora do braço seguidor. Em seguida, execute o seguinte comando.
lerobot-setup-motors \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 # <- paste here the port found at previous step
Você deverá ver a seguinte instrução.
Connect the controller board to the 'gripper' motor only and press enter.
Conforme instruído, conecte o motor do gripper. Certifique-se de que ele seja o único motor conectado à placa e de que o próprio motor ainda não esteja em cadeia (daisy-chained) com nenhum outro motor. Ao pressionar [Enter], o script definirá automaticamente o ID e a taxa de transmissão (baudrate) para esse motor.
Você deverá então ver a seguinte mensagem:
'gripper' motor id set to 6
Seguido pela próxima instrução:
Connect the controller board to the 'wrist_roll' motor only and press enter.
Você pode desconectar o cabo de 3 pinos da placa controladora, mas pode deixá-lo conectado ao motor do gripper na outra extremidade, pois ele já estará no lugar correto. Agora, conecte outro cabo de 3 pinos ao motor de rotação do punho (wrist roll) e conecte-o à placa controladora. Assim como no motor anterior, certifique-se de que ele seja o único motor conectado à placa e de que o próprio motor não esteja conectado a nenhum outro.
Repita a operação para cada motor conforme instruído.
Verifique sua fiação em cada etapa antes de pressionar Enter. Por exemplo, o cabo da fonte de alimentação pode se desconectar enquanto você manipula a placa.
Quando terminar, o script simplesmente será concluído, momento em que os motores estarão prontos para uso. Agora você pode conectar o cabo de 3 pinos de cada motor ao próximo, e o cabo do primeiro motor (o “shoulder pan” com id=1) à placa controladora, que agora pode ser fixada à base do braço.
Repita os mesmos passos para o braço líder.
lerobot-setup-motors \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM0 # <- paste here the port found at previous step
Montagem
- O processo de montagem de braço duplo do SO-ARM101 é o mesmo do SO-ARM100. As únicas diferenças são a adição de presilhas de cabo no SO-ARM101 e as diferentes relações de engrenagem dos servos das juntas no Braço Líder. Portanto, tanto o SO100 quanto o SO101 podem ser instalados consultando o conteúdo a seguir.
- Antes da montagem, verifique novamente o modelo do seu motor e a relação de redução. Se você comprou o SO100, pode ignorar esta etapa. Se você comprou o SO101, verifique a tabela a seguir para distinguir F1 a F6 e L1 a L6.
| Modelo do Servo | Relação de Engrenagem | Juntas Correspondentes |
|---|---|---|
| ST-3215-C044(7.4V) | 1:191 | L1 |
| ST-3215-C001(7.4V) | 1:345 | L2 |
| ST-3215-C044(7.4V) | 1:191 | L3 |
| ST-3215-C046(7.4V) | 1:147 | L4–L6 |
| ST-3215-C001(7.4V) / C018(12V) / C047(12V) | 1:345 | F1–F6 |
Se você comprou o SO101 Arm Kit Standard Edition, todas as fontes de alimentação são de 5V. Se você comprou o SO101 Arm Kit Pro Edition, o Braço Líder deve ser calibrado e operado em cada etapa usando uma fonte de alimentação de 5V, enquanto o Braço Seguidor deve ser calibrado e operado em cada etapa usando uma fonte de alimentação de 12V.
Montar o Braço Líder
| Etapa 1 | Etapa 2 | Etapa 3 | Etapa 4 | Etapa 5 | Etapa 6 |
|---|---|---|---|---|---|
 |  |  |  |  |  |
| Etapa 7 | Etapa 8 | Etapa 9 | Etapa 10 | Etapa 11 | Etapa 12 |
 |  |  |  |  |  |
| Etapa 13 | Etapa 14 | Etapa 15 | Etapa 16 | Etapa 17 | Etapa 18 |
 |  |  |  |  |  |
| Etapa 19 | Etapa 20 | ||||
 |  |
Montar o Braço Seguidor
- As etapas para montar o Braço Seguidor são, em geral, as mesmas do Braço Líder. A única diferença está no método de instalação do efetuador final (gripper e manete) após a Etapa 12.
| Etapa 1 | Etapa 2 | Etapa 3 | Etapa 4 | Etapa 5 | Etapa 6 |
|---|---|---|---|---|---|
 |  |  |  |  |  |
| Etapa 7 | Etapa 8 | Etapa 9 | Etapa 10 | Etapa 11 | Etapa 12 |
 |  |  |  |  |  |
| Etapa 13 | Etapa 14 | Etapa 15 | Etapa 16 | Etapa 17 | |
 |  |  |  |  |
Calibração
Os códigos do SO100 e SO101 são compatíveis. Usuários do SO100 podem utilizar diretamente os parâmetros e o código do SO101 para operação.
Se você comprou o SO101 Arm Kit Standard Edition, todas as fontes de alimentação são de 5V. Se você comprou o SO101 Arm Kit Pro Edition, o Braço Líder deve ser calibrado e operado em cada etapa usando uma fonte de alimentação de 5V, enquanto o Braço Seguidor deve ser calibrado e operado em cada etapa usando uma fonte de alimentação de 12V.
Em seguida, você precisa conectar a fonte de alimentação e o cabo de dados ao seu robô SO-10x para calibração, a fim de garantir que os braços líder e seguidor tenham os mesmos valores de posição quando estiverem na mesma posição física. Essa calibração é essencial porque permite que uma rede neural treinada em um robô SO-10x funcione em outro. Se você precisar recalibrar o braço robótico, exclua os arquivos em ~/.cache/huggingface/lerobot/calibration/robots ou ~/.cache/huggingface/lerobot/calibration/teleoperators e recalibre o braço robótico. Caso contrário, aparecerá um aviso de erro. As informações de calibração do braço robótico serão armazenadas nos arquivos JSON nesse diretório.
Em PCs (Linux) e dispositivos Jetson, o primeiro dispositivo USB que você conecta normalmente é mapeado para ttyACM0, e o segundo é mapeado para ttyACM1. Verifique cuidadosamente qual porta está mapeada para o braço líder e para o seguidor antes de executar os comandos.
Calibração manual do braço seguidor
Conecte as interfaces dos 6 servomotores do robô por meio de um cabo de 3 pinos e conecte o servo do chassi à placa de acionamento do servo, depois execute o seguinte comando ou exemplo de API para calibrar o braço robótico:
Primeiro, conceda as permissões de interface
sudo chmod 666 /dev/ttyACM*
Depois calibre o braço seguidor
lerobot-calibrate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \# <- The port of your robot
--robot.id=my_awesome_follower_arm # <- Give the robot a unique name
O vídeo abaixo mostra como realizar a calibração. Primeiro você precisa mover o robô para a posição em que todas as juntas estejam no meio de seus intervalos. Em seguida, após pressionar Enter, você deve mover cada junta por toda a sua amplitude de movimento.
Calibração manual do braço líder
Siga os mesmos passos para calibrar o braço líder, executando o seguinte comando ou exemplo de API:
lerobot-calibrate \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \# <- The port of your robot
--teleop.id=my_awesome_leader_arm # <- Give the robot a unique name
(Opcional) Calibração de posição central com a ferramenta rápida Seeed Studio SoARM
Ao calibrar ou operar o robô, se você vir erros como:
Magnitude 30841 exceeds 2047 (max for sign_bit_index=11)
Isso geralmente significa que a posição atual / deslocamento de zero de um servo está anormal, fazendo com que o ângulo lido exceda o intervalo esperado. Nesse caso, você pode usar a ferramenta SoARM da Seeed Studio para fazer uma calibração de posição central (gravar a posição atual como o valor central 2048) e então refazer a calibração de todo o braço.
1) Clone a ferramenta do GitHub e instale as dependências
git clone https://github.com/Seeed-Projects/Seeed_RoboController.git
cd Seeed_RoboController
pip install -r requirements.txt
2) Calibração de posição central e verificação
Localização dos scripts:
src/tools/servo_middle_calibration.py: calibração de posição central (grava a posição atual como 2048)src/tools/servo_disable.py: desativa o torque do servo (facilita girar as juntas manualmente)src/tools/servo_center_test.py: move para 2048 para verificar o resultado da calibração
Execute na seguinte ordem (os comandos irão, de forma interativa, pedir para você selecionar uma porta):
- (Opcional) Desative o torque para ajustar as juntas manualmente:
python -m src.tools.servo_disable
- Faça a calibração de posição central (defina a posição atual como 2048):
python -m src.tools.servo_middle_calibration
- Verifique: mova o servo para 2048 e confira se ele retorna para a posição central esperada:
python -m src.tools.servo_center_test
Após a calibração de posição central, volte para os passos do lerobot-calibrate acima e refaça a calibração de todo o braço.
Teleoperação
Teleop simples Agora você está pronto para teleoperar seu robô! Execute este script simples (ele não irá conectar nem exibir as câmeras):
Observe que o id associado a um robô é usado para armazenar o arquivo de calibração. É importante usar o mesmo id ao teleoperar, gravar e avaliar quando estiver usando a mesma configuração.
sudo chmod 666 /dev/ttyACM*
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm
O comando de teleoperação irá automaticamente:
- Identificar quaisquer calibrações ausentes e iniciar o procedimento de calibração.
- Conectar o robô e o dispositivo de teleoperação e iniciar a teleoperação.
Adicionar câmeras
If using RealSense D435i/D405
As câmeras de profundidade RealSense podem fornecer percepção RGB-D para o LeRobot e são adequadas para tarefas como reconhecimento de objetos, reconstrução de nuvens de pontos e manipulação em mesas. Os modelos recomendados aqui são RealSense D405 e RealSense D435i.
RealSense D405

A RealSense D405 é uma câmera estéreo de profundidade de curto alcance projetada para tarefas de alta precisão em curta distância, como manipulação robótica em mesas, com faixa de trabalho típica de 7 cm a 50 cm.
RealSense D435i

A RealSense D435i combina detecção de profundidade, imagem RGB e um IMU, tornando-a adequada para aplicações de médio a curto alcance, como reconstrução 3D, SLAM e percepção do ambiente robótico.
1. Mudar para o branch da câmera
O suporte atual a câmeras está disponível no branch DepthCameraSupport:
git checkout DepthCameraSupport
git pull origin DepthCameraSupport
Confirme o branch atual:
git branch --show-current
Saída esperada:
DepthCameraSupport
2. Instalar o LeRobot em modo editável
Se você usar apenas RealSense:
pip install -e ".[realsense]"
3. Detectar câmeras
lerobot-find-cameras realsense
Esta etapa irá exibir:
- Modelo da câmera
- Número de série
- Informações de USB
- Configuração padrão de stream
4. Exemplo com RealSense
Teste com duas RealSense:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras='{
d435i_color: {
type: realsense_d435i_color,
serial_number_or_name: "419522072950",
width: 640,
height: 480,
fps: 30,
color_mode: rgb,
color_stream_format: rgb8,
rotation: 0,
warmup_s: 1
},
d435i_depth: {
type: realsense_d435i_depth,
serial_number_or_name: "419522072950",
width: 640,
height: 480,
fps: 30,
max_depth_m: 2.0,
depth_alpha: 0.2,
rotation: 0,
warmup_s: 5
},
d405_color: {
type: realsense_d405_color,
serial_number_or_name: "409122273421",
width: 640,
height: 480,
fps: 30,
color_mode: rgb,
color_stream_format: rgb8,
rotation: 0,
warmup_s: 1
},
d405_depth: {
type: realsense_d405_depth,
serial_number_or_name: "409122273421",
width: 640,
height: 480,
fps: 30,
depth_alpha: 0.03,
rotation: 0,
warmup_s: 5
}
}' \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
5. Observações sobre parâmetros
depth_alphacontrola o fator de escala da imagem de profundidade e pode ser ajustado com base no resultado de exibição e na faixa de distância alvo.- Se você conectar três ou mais câmeras de profundidade, é recomendável reduzir o
fpspara15para melhorar a estabilidade geral. - Recomenda-se manter a resolução em
640x480para um melhor equilíbrio entre estabilidade e desempenho em tempo real.
If using Orbbec Gemini2/Gemini336 cameras

A Orbbec Gemini 2 é uma câmera RGB-D de alto desempenho para aplicações em robótica, fornecendo streams sincronizados de RGB e profundidade com alinhamento preciso de profundidade para cor. Combinando detecção de profundidade estéreo e um IMU de 6 eixos integrado, ela é bem adequada para tarefas robóticas como detecção de objetos, percepção 3D, mapeamento e navegação. Seu design compacto e o suporte completo ao Orbbec SDK a tornam adequada tanto para pesquisa quanto para implantação em cenários reais.

A Gemini 336 é um novo membro da série Gemini 330. Ela herda o forte desempenho de profundidade da Gemini 335 e melhora ainda mais a qualidade de imagem de profundidade em áreas internas reflexivas, regiões escuras em cenas de alta dinâmica e ambientes externos claros. Para aplicações em robótica, ela pode fornecer dados de profundidade mais estáveis e de alta qualidade para tarefas como percepção, localização e manipulação.
1. Mudar para o branch da câmera
O suporte atual a câmeras está disponível no branch DepthCameraSupport:
git checkout DepthCameraSupport
git pull origin DepthCameraSupport
Confirme o branch atual:
git branch --show-current
Saída esperada:
DepthCameraSupport
2. Instalar o LeRobot em modo editável
Se você usar apenas Orbbec:
pip install -e ".[orbbec]"
3. Detectar câmeras
lerobot-find-cameras orbbec
Esta etapa irá exibir:
- Modelo da câmera
- Número de série
- Informações de USB
- Configuração padrão de stream
4. Exemplo com Orbbec
Teste com uma única Orbbec:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras='{
orbbec_color: {
type: orbbec_color,
serial_number_or_name: "CP9JA530003A",
width: 640,
height: 480,
fps: 30,
color_mode: rgb,
rotation: 0,
warmup_s: 1
},
orbbec_depth: {
type: orbbec_depth,
serial_number_or_name: "CP9JA530003A",
width: 640,
height: 400,
fps: 30,
depth_alpha: 0.2,
rotation: 0,
warmup_s: 5
}
}' \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
5. Notas sobre parâmetros
depth_alphacontrola o fator de escala da imagem de profundidade. Um bom ponto de partida é0.2, depois você pode ajustá-lo com base no resultado exibido.- Se você conectar três ou mais câmeras de profundidade, é recomendável reduzir o
fpspara15para obter melhor estabilidade. - Recomenda-se manter a resolução em
640x480para uma exibição e transferência de dados mais estáveis.
6. Problemas comuns
Se você vir o seguinte erro:
No Orbbec camera found for 'XXXX'
isso geralmente significa que o número de série na configuração não corresponde ao dispositivo atualmente conectado. Execute:
lerobot-find-cameras orbbec
Em seguida, confirme o serial real e atualize serial_number_or_name no seu comando.
Se estiver usando uma câmera comum
Os códigos SO100 e SO101 são compatíveis. Usuários do SO100 podem utilizar diretamente os parâmetros e o código do SO101 para operação.
Para instanciar uma câmera, você precisa de um identificador de câmera. Esse identificador pode mudar se você reiniciar o computador ou reconectar a câmera, um comportamento que depende principalmente do seu sistema operacional.
Para encontrar os índices das câmeras conectadas ao seu sistema, execute o seguinte script:
lerobot-find-cameras opencv # or realsense for Intel Realsense cameras
O terminal exibirá as seguintes informações.
--- Detected Cameras ---
Camera #0:
Name: OpenCV Camera @ 0
Type: OpenCV
Id: 0
Backend api: AVFOUNDATION
Default stream profile:
Format: 16.0
Width: 1920
Height: 1080
Fps: 15.0
--------------------
(more cameras ...)
Você pode encontrar as imagens capturadas por cada câmera no diretório outputs/captured_images.
Ao usar câmeras Intel RealSense no , você pode receber este erro: , isso pode ser resolvido executando o mesmo comando com permissões. Observe que o uso de câmeras RealSense no é instável.macOSError finding RealSense cameras: failed to set power statesudomacOS.
Em seguida, você poderá exibir as câmeras no seu computador enquanto faz a teleoperação executando o código a seguir. Isso é útil para preparar sua configuração antes de gravar seu primeiro conjunto de dados.
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
Se você tiver mais câmeras, pode alterar --robot.cameras para adicionar câmeras. Você deve observar o formato de index_or_path, que é determinado pelo último dígito do ID da câmera exibido por python -m lerobot.find_cameras opencv.
Imagens no formato fourcc: "MJPG" são compactadas. Você pode tentar resoluções mais altas e também pode experimentar o formato YUYV. No entanto, este último reduzirá a resolução da imagem e o FPS, causando atraso na operação do braço robótico. Atualmente, no formato MJPG, é possível suportar 3 câmeras com resolução de 1920*1080 mantendo 30FPS. Dito isso, ainda não é recomendado conectar 2 câmeras a um computador por meio do mesmo HUB USB.
Por exemplo, você quer adicionar uma câmera lateral:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
Imagens no formato fourcc: "MJPG" são compactadas. Você pode tentar resoluções mais altas e também pode experimentar o formato YUYV. No entanto, este último reduzirá a resolução da imagem e o FPS, causando atraso na operação do braço robótico. Atualmente, no formato MJPG, é possível suportar 3 câmeras com resolução de 1920*1080 mantendo 30FPS. Dito isso, ainda não é recomendado conectar 2 câmeras a um computador por meio do mesmo HUB USB.
Se você encontrar um bug como este.
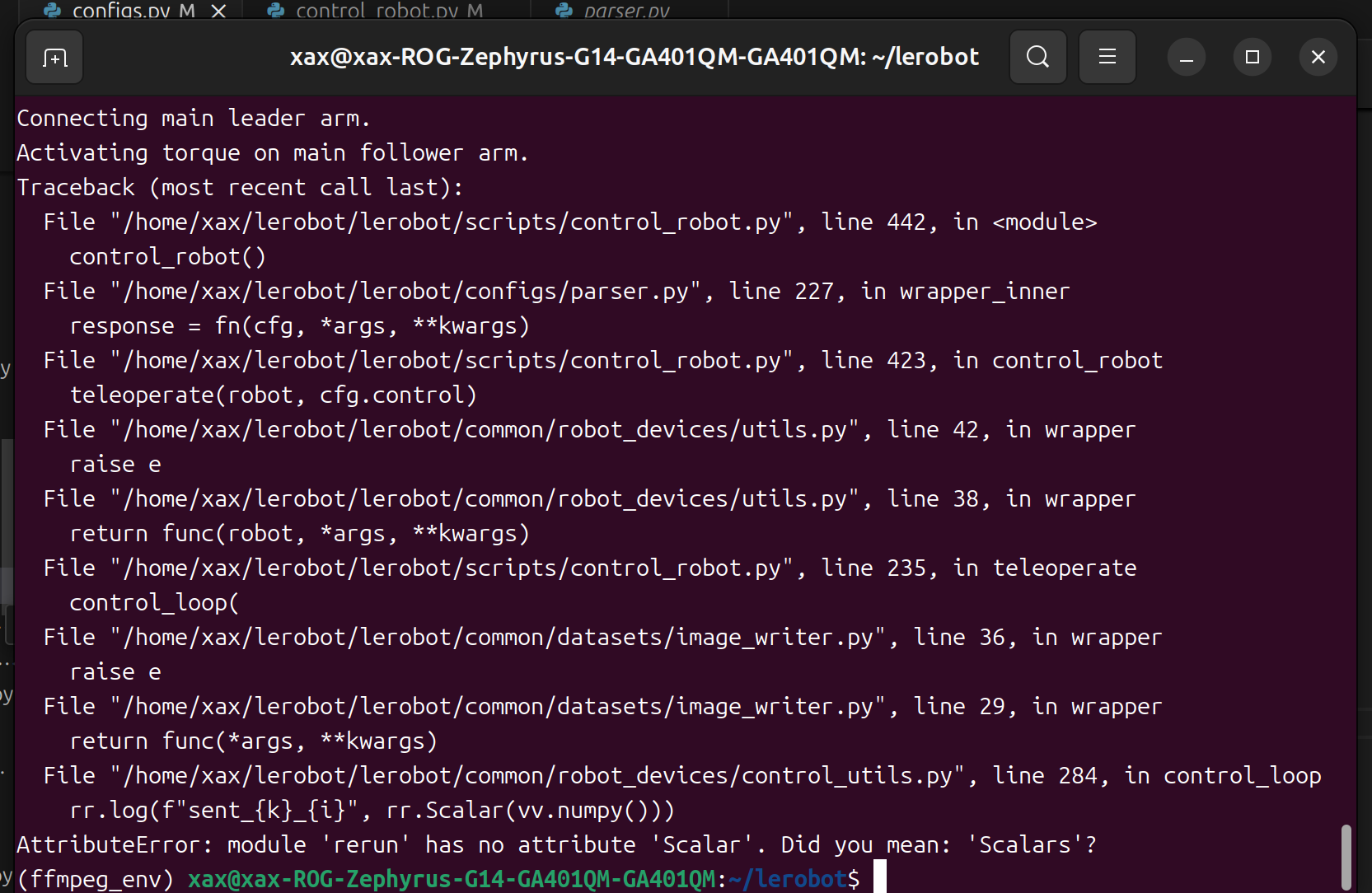
Você pode fazer downgrade da versão do rerun para resolver o problema.
pip3 install rerun-sdk==0.23
Grave o conjunto de dados
- Se você quiser salvar o conjunto de dados localmente, pode executá-lo diretamente:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true \
--dataset.repo_id=seeedstudio123/test \
--dataset.num_episodes=5 \
--dataset.single_task="Grab the black cube" \
--dataset.push_to_hub=false \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=30
Entre eles, repo_id pode ser modificado de forma personalizada, e push_to_hub=false. Por fim, o conjunto de dados será salvo no diretório ~/.cache/huggingface/lerobot na pasta home, onde a pasta seeedstudio123/test mencionada acima será criada.
- Se você quiser usar os recursos do hub do Hugging Face para enviar seu conjunto de dados e ainda não tiver feito isso antes, certifique-se de ter feito login usando um token com permissão de escrita, que pode ser gerado nas configurações do Hugging Face:
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential
Armazene o nome do seu repositório Hugging Face em uma variável para executar estes comandos:
HF_USER=$(huggingface-cli whoami | head -n 1)
echo $HF_USER
Grave 5 episódios e envie seu conjunto de dados para o hub:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true \
--dataset.repo_id=${HF_USER}/record-test \
--dataset.num_episodes=5 \
--dataset.single_task="Grab the black cube" \
--dataset.push_to_hub=true \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=30
Você verá muitas linhas aparecendo como esta:
INFO 2024-08-10 15:02:58 ol_robot.py:219 dt:33.34 (30.0hz) dtRlead: 5.06 (197.5hz) dtWfoll: 0.25 (3963.7hz) dtRfoll: 6.22 (160.7hz) dtRlaptop: 32.57 (30.7hz) dtRphone: 33.84 (29.5hz)
Função de gravação
A função record fornece um conjunto de ferramentas para capturar e gerenciar dados durante a operação do robô.
1. Armazenamento de dados
- Os dados são armazenados usando o formato
LeRobotDatasete são gravados em disco durante a gravação. - Por padrão, o conjunto de dados é enviado para a sua página do Hugging Face após a gravação.
- Para desativar o envio, use:
--dataset.push_to_hub=False
2. Checkpoints e retomada
- Checkpoints são criados automaticamente durante a gravação.
- Para retomar após uma interrupção, execute novamente o mesmo comando com:
--resume=true
⚠️ Nota crítica: Ao retomar, defina --dataset.num_episodes para o número de episódios adicionais a serem gravados (não o número total de episódios desejado no conjunto de dados).
- Para iniciar a gravação do zero, exclua manualmente o diretório do conjunto de dados.
3. Parâmetros de gravação
Defina o fluxo de gravação de dados usando argumentos de linha de comando:
| Parâmetro | Descrição | Padrão |
|---|---|---|
| --dataset.episode_time_s | Duração por episódio de dados (segundos) | 60 |
| --dataset.reset_time_s | Tempo de reinicialização do ambiente após cada episódio (segundos) | 60 |
| --dataset.num_episodes | Total de episódios a serem gravados | 50 |
4. Controles de teclado durante a gravação
Controle o fluxo de gravação de dados usando atalhos de teclado:
| Tecla | Ação |
|---|---|
| → (Seta para a direita) | Encerrar antecipadamente o episódio/reset atual; ir para o próximo. |
| ← (Seta para a esquerda) | Cancelar o episódio atual; regravá-lo. |
| ESC | Encerrar a sessão imediatamente, codificar os vídeos e enviar o conjunto de dados. |
Se o teclado não funcionar, talvez você precise instalar outra versão do pynput.
pip install pynput==1.6.8
Dicas para coletar dados
- Sugestão de tarefa: Agarrar objetos em diferentes locais e colocá-los em uma caixa.
- Escala: Grave ≥50 episódios (10 episódios por local).
- Consistência:
- Mantenha as câmeras fixas.
- Mantenha o mesmo comportamento de preensão.
- Garanta que os objetos manipulados estejam visíveis nas imagens das câmeras.
- Progressão:
- Comece com preensões confiáveis antes de adicionar variações (novos locais, técnicas, ajustes de câmera).
- Evite aumentar a complexidade rapidamente para não causar falhas.
💡 Regra geral: Você deve ser capaz de realizar a tarefa apenas olhando para as imagens da câmera.
Se você quiser se aprofundar neste tópico importante, pode conferir o post no blog que escrevemos sobre o que torna um conjunto de dados bom.
Solução de problemas
Problema específico do Linux:
Se as teclas Seta para a Direita/Seta para a Esquerda/ESC não responderem durante a gravação:
- Verifique se a variável de ambiente
$DISPLAYestá definida (consulte limitações do pynput).
Visualizar o conjunto de dados
Os códigos SO100 e SO101 são compatíveis. Usuários do SO100 podem utilizar diretamente os parâmetros e o código do SO101 para operação.
Se você enviou seu conjunto de dados para o hub com --control.push_to_hub=true, você pode visualizar seu conjunto de dados online copiando e colando o id do seu repositório obtido por:
echo ${HF_USER}/so101_test
Se você não fez o upload com --dataset.push_to_hub=false, também pode visualizá-lo localmente com:
lerobot-dataset-viz \
--repo-id ${HF_USER}/so101_test \
Se você fizer o upload com --dataset.push_to_hub=false, também poderá visualizá-lo localmente com:
lerobot-dataset-viz \
--repo-id seeed_123/so101_test \
Aqui, seeed_123 é o nome personalizado de repo_id definido ao coletar os dados.
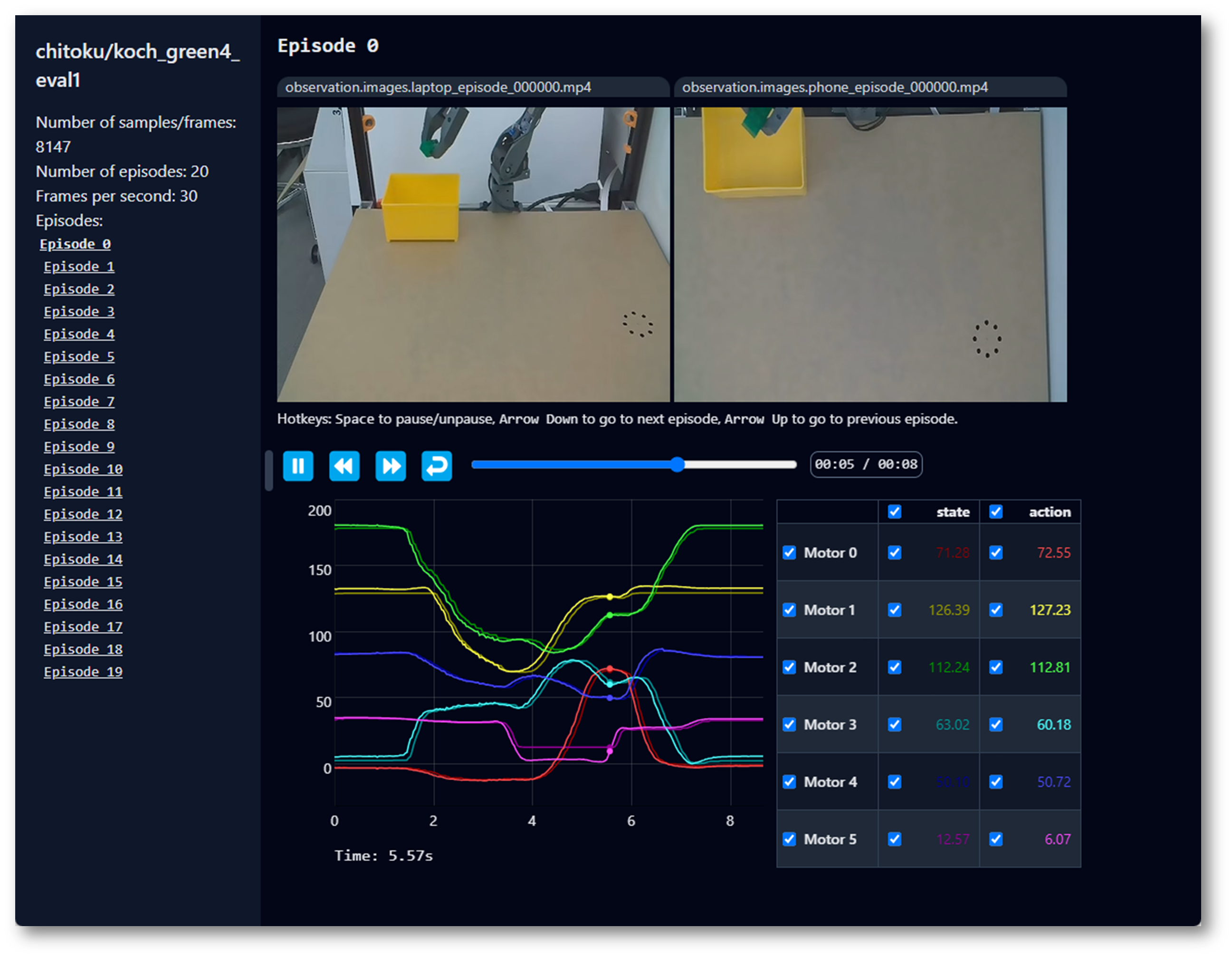
Reproduzir um episódio
Os códigos SO100 e SO101 são compatíveis. Usuários do SO100 podem utilizar diretamente os parâmetros e o código do SO101 para operação.
Um recurso útil é a função replay, que permite reproduzir qualquer episódio que você tenha gravado ou episódios de qualquer conjunto de dados disponível. Essa função ajuda a testar a repetibilidade das ações do seu robô e avaliar a transferibilidade entre robôs do mesmo modelo.
Você pode reproduzir o primeiro episódio no seu robô com o comando abaixo ou com o exemplo de API:
lerobot-replay \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--dataset.repo_id=${HF_USER}/record-test \
--dataset.episode=0
Seu robô deve reproduzir movimentos semelhantes aos que você gravou.
Treinar e Avaliar
ACT
Consulte ACT
Para treinar uma política para controlar seu robô, use o script lerobot-train.
Treinar
lerobot-train \
--dataset.repo_id=${HF_USER}/so101_test \
--policy.type=act \
--output_dir=outputs/train/act_so101_test \
--job_name=act_so101_test \
--policy.device=cuda \
--wandb.enable=false \
--steps=300000
Se você quiser treinar em um conjunto de dados local, certifique-se de que o repo_id corresponda ao usado durante a coleta de dados e adicione --policy.push_to_hub=False.
lerobot-train \
--dataset.repo_id=seeedstudio123/test \
--policy.type=act \
--output_dir=outputs/train/act_so101_test \
--job_name=act_so101_test \
--policy.device=cuda \
--wandb.enable=false \
--policy.push_to_hub=false\
--steps=300000
Vamos explicar:
- Especificação do conjunto de dados: Fornecemos o conjunto de dados por meio do parâmetro
--dataset.repo_id=${HF_USER}/so101_test. - Etapas de treinamento: Modificamos o número de etapas de treinamento usando
--steps=300000. O algoritmo usa por padrão 800000 etapas, e você pode ajustá-lo com base na dificuldade da sua tarefa e observando a perda durante o treinamento. - Tipo de política: Fornecemos a política com
policy.type=act. Da mesma forma, você pode alternar entre políticas como [act,diffusion,pi0,pi0fast,pi0fast,sac,smolvla], o que carregará a configuração deconfiguration_act.py. Importante: essa política se adaptará automaticamente aos estados dos motores, ações dos motores e ao número de câmeras do seu robô (por exemplo,laptopephone), pois essas informações já estão armazenadas no seu conjunto de dados. - Seleção de dispositivo: Fornecemos
policy.device=cudaporque estamos treinando em uma GPU Nvidia, mas você pode usarpolicy.device=mpspara treinar em Apple Silicon. - Ferramenta de visualização: Fornecemos
wandb.enable=truepara visualizar gráficos de treinamento usando Weights and Biases. Isso é opcional, mas, se você usar, certifique-se de ter feito login executandowandb login.
Avaliar
Os códigos SO100 e SO101 são compatíveis. Usuários do SO100 podem utilizar diretamente os parâmetros e o código do SO101 para operação.
Você pode usar a função record de lerobot/record.py, mas com um checkpoint de política como entrada. Por exemplo, execute este comando para gravar 10 episódios de avaliação:
lerobot-record \
--robot.type=so100_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{ up: {type: opencv, index_or_path: /dev/video10, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: intelrealsense, serial_number_or_name: 233522074606, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=${HF_USER}/eval_so100 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=${HF_USER}/my_policy
por exemplo:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=seeed/eval_test123 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=outputs/train/act_so101_test/checkpoints/last/pretrained_model
-
O parâmetro
--policy.pathindica o caminho para o arquivo de pesos dos resultados do treinamento da sua política (por exemplo,outputs/train/act_so101_test/checkpoints/last/pretrained_model). Se você enviar o arquivo de pesos do resultado do treinamento do modelo para o Hub, também poderá usar o repositório do modelo (por exemplo,${HF_USER}/act_so100_test). -
O nome do conjunto de dados
dataset.repo_idcomeça comeval_. Essa operação registrará separadamente vídeos e dados durante a avaliação, que serão salvos na pasta que começa comeval_, comoseeed/eval_test123. -
Se você encontrar
File exists: 'home/xxxx/.cache/huggingface/lerobot/xxxxx/seeed/eval_xxxx'durante a fase de avaliação, exclua primeiro a pasta que começa comeval_e depois execute o programa novamente. -
Ao encontrar
mean is infinity. You should either initialize with stats as an argument or use a pretrained model, observe que palavras-chave como front e side no parâmetro--robot.camerasdevem ser estritamente consistentes com as usadas ao coletar o conjunto de dados.
SmolVLA
SmolVLA é o modelo base leve da Hugging Face para robótica. Projetado para fácil fine-tuning em conjuntos de dados do LeRobot, ele ajuda a acelerar o seu desenvolvimento!
Configurar seu ambiente
Instale as dependências do SmolVLA executando:
pip install -e ".[smolvla]"
Fazer fine-tuning do SmolVLA nos seus dados
Use o smolvla_base, nosso modelo pré-treinado de 450M, e faça o fine-tuning dele nos seus dados. Treinar o modelo por 20k etapas levará aproximadamente ~4 horas em uma única GPU A100. Você deve ajustar o número de etapas com base no desempenho e no seu caso de uso.
Se você não tiver um dispositivo com GPU, pode treinar usando nosso notebook no Google Colab.
Passe seu conjunto de dados para o script de treinamento usando --dataset.repo_id. Se quiser testar sua instalação, execute o seguinte comando, em que usamos um dos conjuntos de dados que coletamos para o artigo do SmolVLA.
lerobot-train \
--policy.path=lerobot/smolvla_base \
--dataset.repo_id=${HF_USER}/mydataset \
--batch_size=64 \
--steps=20000 \
--output_dir=outputs/train/my_smolvla \
--job_name=my_smolvla_training \
--policy.device=cuda \
--wandb.enable=true
Você pode começar com um tamanho de batch pequeno e aumentá-lo gradualmente, se a GPU permitir, desde que os tempos de carregamento permaneçam curtos.
Fazer fine-tuning é uma arte. Para uma visão completa das opções de fine-tuning, execute
lerobot-train --help
Avaliar o modelo com fine-tuning e executá-lo em tempo real
Da mesma forma que ao gravar um episódio, é recomendado que você esteja logado no HuggingFace Hub. Você pode seguir as etapas correspondentes: Gravar um conjunto de dados. Depois de fazer login, você pode executar inferência na sua configuração fazendo:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \ # <- Use your port
--robot.id=my_blue_follower_arm \ # <- Use your robot id
--robot.cameras="{ front: {type: opencv, index_or_path: 8, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \ # <- Use your cameras
--dataset.single_task="Grasp a lego block and put it in the bin." \ # <- Use the same task description you used in your dataset recording
--dataset.repo_id=${HF_USER}/eval_DATASET_NAME_test \ # <- This will be the dataset name on HF Hub
--dataset.episode_time_s=50 \
--dataset.num_episodes=10 \
# <- Teleop optional if you want to teleoperate in between episodes \
# --teleop.type=so100_leader \
# --teleop.port=/dev/ttyACM0 \
# --teleop.id=my_red_leader_arm \
--policy.path=HF_USER/FINETUNE_MODEL_NAME # <- Use your fine-tuned model
Dependendo da sua configuração de avaliação, você pode configurar a duração e o número de episódios a serem registrados para o seu conjunto de avaliação.
LIBERO
LIBERO é um benchmark projetado para estudar aprendizado contínuo de robôs. A ideia é que robôs não serão apenas pré-treinados uma vez em uma fábrica; eles precisarão continuar aprendendo e se adaptando com seus usuários humanos ao longo do tempo. Essa adaptação contínua é chamada de aprendizado ao longo da vida na tomada de decisão (LLDM), e é um passo fundamental para construir robôs que se tornem ajudantes verdadeiramente personalizados.
Avaliando com LIBERO
No LeRobot, portamos o LIBERO para o nosso framework e o usamos principalmente para avaliar o SmolVLA, nosso modelo leve de Visão-Linguagem-Ação.
LIBERO agora faz parte da nossa simulação com suporte a multi-avaliação, o que significa que você pode avaliar suas políticas em um único conjunto de tarefas ou em múltiplos conjuntos de uma vez com apenas uma flag.
Para instalar o LIBERO, depois de seguir as instruções oficiais do LeRobot, basta fazer: pip install -e ".[libero]"
Avaliação de um único conjunto
Avalie uma política em um conjunto LIBERO:
lerobot-eval \
--policy.path="your-policy-id" \
--env.type=libero \
--env.task=libero_object \
--eval.batch_size=2 \
--eval.n_episodes=3
--env.taskseleciona o conjunto (libero_object,libero_spatial, etc.).--eval.batch_sizecontrola quantos ambientes rodam em paralelo.--eval.n_episodesdefine quantos episódios serão executados no total.
Avaliação de múltiplos conjuntos
Avalie uma política em vários conjuntos de uma vez:
lerobot-eval \
--policy.path="your-policy-id" \
--env.type=libero \
--env.task=libero_object,libero_spatial \
--eval.batch_size=1 \
--eval.n_episodes=2
- Passe uma lista separada por vírgulas para
--env.taskpara avaliação em múltiplos conjuntos.
Exemplo de comando de treinamento
lerobot-train \
--policy.type=smolvla \
--policy.repo_id=${HF_USER}/libero-test \
--dataset.repo_id=HuggingFaceVLA/libero \
--env.type=libero \
--env.task=libero_10 \
--output_dir=./outputs/ \
--steps=100000 \
--batch_size=4 \
--eval.batch_size=1 \
--eval.n_episodes=1 \
--eval_freq=1000 \
Observação sobre renderização
LeRobot usa MuJoCo para simulação. Você precisa definir o backend de renderização antes do treinamento ou da avaliação:
export MUJOCO_GL=egl→ para servidores sem display (por exemplo, HPC, nuvem)
Pi0
Consulte Pi0
pip install -e ".[pi]"
Treinar
lerobot-train \
--policy.type=pi0 \
--dataset.repo_id=seeed/eval_test123 \
--job_name=pi0_training \
--output_dir=outputs/pi0_training \
--policy.pretrained_path=lerobot/pi0_base \
--policy.compile_model=true \
--policy.gradient_checkpointing=true \
--policy.dtype=bfloat16 \
--steps=20000 \
--policy.device=cuda \
--batch_size=32 \
--wandb.enable=false
Avaliar
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30,fourcc: "MJPG"}}" \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=seeed/eval_test123 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=outputs/pi0_training/checkpoints/last/pretrained_model
Pi0.5
Consulte Pi0.5
pip install -e ".[pi]"
Treinar
lerobot-train \
--dataset.repo_id=seeed/eval_test123 \
--policy.type=pi05 \
--output_dir=outputs/pi05_training \
--job_name=pi05_training \
--policy.pretrained_path=lerobot/pi05_base \
--policy.compile_model=true \
--policy.gradient_checkpointing=true \
--wandb.enable=false \
--policy.dtype=bfloat16 \
--steps=3000 \
--policy.device=cuda \
--batch_size=32
Avaliar
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30,fourcc: "MJPG"}}" \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=seeed/eval_test123 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=outputs/pi05_training/checkpoints/last/pretrained_model
GR00T N1.5
Consulte a documentação oficial: GR00T N1.5.
GR00T N1.5 é um modelo base aberto da NVIDIA para raciocínio robótico mais geral e aprendizado de habilidades. É um modelo de múltiplos corpos: ele pode receber entradas multimodais como linguagem e imagens, e executar tarefas de manipulação em diferentes ambientes.
No LeRobot, o ponto-chave é definir o tipo de política como --policy.type=groot. Observe que o GR00T N1.5 tem requisitos de ambiente mais altos (depende de FlashAttention e requer uma GPU CUDA). Recomenda-se primeiro colocar ACT / Pi0 para rodar de ponta a ponta e, em seguida, experimentar o GR00T.
Instalação (importante)
De acordo com a documentação oficial atual, GR00T N1.5 requer flash-attn e só pode ser usado em hardware compatível com CUDA.
Ordem recomendada:
- Prepare primeiro o seu ambiente base (Python, CUDA, drivers, etc.). Não instale
lerobotainda. - Instale o PyTorch para a sua versão do CUDA (diferentes versões do CUDA podem exigir um
--index-urldiferente; siga a página de instalação do PyTorch).
pip install "torch>=2.2.1,<2.8.0" "torchvision>=0.21.0,<0.23.0"
- Instale as dependências de build para
flash-attne depois instale o próprioflash-attn.
pip install ninja "packaging>=24.2,<26.0"
pip install "flash-attn>=2.5.9,<3.0.0" --no-build-isolation
python -c "import flash_attn; print(f'Flash Attention {flash_attn.__version__} imported successfully')"
- Instale o LeRobot com as dependências opcionais
groot(lerobot[groot]).
pip install "lerobot[groot]"
Se a instalação do flash-attn falhar, geralmente é devido a (1) incompatibilidade entre PyTorch/CUDA, (2) dependências de build ausentes ou (3) um ambiente muito novo/muito antigo. Verifique primeiro a documentação oficial do GR00T e as instruções de instalação do PyTorch.
Treinamento (fine-tuning)
A documentação oficial fornece um exemplo multi-GPU com accelerate launch --multi_gpu .... Se você tiver apenas uma GPU, ainda pode começar fazendo um experimento de processo único funcionar primeiro (o suporte/argumentos exatos dependem da documentação oficial).
accelerate launch \
--multi_gpu \
--num_processes=$NUM_GPUS \
$(which lerobot-train) \
--output_dir=$OUTPUT_DIR \
--save_checkpoint=true \
--batch_size=$BATCH_SIZE \
--steps=$NUM_STEPS \
--save_freq=$SAVE_FREQ \
--log_freq=$LOG_FREQ \
--policy.push_to_hub=true \
--policy.type=groot \
--policy.repo_id=$REPO_ID \
--policy.tune_diffusion_model=false \
--dataset.repo_id=$DATASET_ID \
--wandb.enable=true \
--wandb.disable_artifact=true \
--job_name=$JOB_NAME
Validação no robô (avaliação)
Após o treinamento, você pode avaliar e gravar replays com lerobot-record como em outras políticas. A documentação oficial inclui um exemplo bimanual; usuários de braço único SO101 não precisam de argumentos do tipo left_arm_port/right_arm_port.
lerobot-record \
--robot.type=bi_so_follower \
--robot.left_arm_port=/dev/ttyACM1 \
--robot.right_arm_port=/dev/ttyACM0 \
--robot.id=bimanual_follower \
--robot.cameras='{ right: {"type": "opencv", "index_or_path": 0, "width": 640, "height": 480, "fps": 30}, left: {"type": "opencv", "index_or_path": 2, "width": 640, "height": 480, "fps": 30}, top: {"type": "opencv", "index_or_path": 4, "width": 640, "height": 480, "fps": 30} }' \
--display_data=true \
--dataset.repo_id=${HF_USER}/eval_groot_bimanual \
--dataset.num_episodes=10 \
--dataset.single_task="Grab and handover the red cube to the other arm" \
--policy.path=${HF_USER}/groot-bimanual \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=10
Licença: Apache 2.0 (a mesma do repositório GR00T original).
(Opcional) Fine-Tuning Eficiente em Parâmetros (PEFT)
PEFT (Fine-Tuning Eficiente em Parâmetros) é uma família de métodos e ferramentas que ajudam um grande modelo pré-treinado a se adaptar a novas tarefas sem atualizar todos os parâmetros. Para políticas LeRobot pré-treinadas (por exemplo, SmolVLA, Pi0), você geralmente pode treinar apenas um pequeno conjunto de parâmetros “adaptadores” (por exemplo, LoRA) para reduzir o uso de VRAM e o custo de treinamento, ainda assim alcançando desempenho próximo ao do fine-tuning completo.
Instalar
Depois de instalar o LeRobot com as dependências opcionais peft, você pode usar argumentos relacionados a PEFT no treinamento.
pip install -e ".[peft]"
pip install "lerobot[peft]"
Mais conceitos e métodos: 🤗 Documentação do PEFT.
Exemplo: fazer fine-tuning do SmolVLA com LoRA (subtarefa LIBERO libero_spatial)
Este exemplo faz fine-tuning de lerobot/smolvla_base com LoRA no conjunto de dados HuggingFaceVLA/libero. Os nomes dos argumentos dependem da versão do LeRobot; recomenda-se também verificar lerobot-train --help.
lerobot-train \
--policy.path=lerobot/smolvla_base \
--policy.repo_id=${HF_USER}/my_libero_smolvla_peft \
--dataset.repo_id=HuggingFaceVLA/libero \
--env.type=libero \
--env.task=libero_spatial \
--output_dir=outputs/train/my_libero_smolvla_peft \
--job_name=my_libero_smolvla_peft \
--policy.device=cuda \
--steps=10000 \
--batch_size=32 \
--optimizer.lr=1e-3 \
--peft.method_type=LORA \
--peft.r=64
Principais argumentos de PEFT
--peft.method_type: Selecione o método PEFT. LoRA (Low-Rank Adapter) é uma das opções mais comuns.--peft.r: Rank do LoRA. Um rank mais alto geralmente aumenta a capacidade, mas também aumenta a contagem de parâmetros e o uso de VRAM.
Escolher em quais camadas/módulos injetar LoRA (opcional)
Por padrão, o PEFT geralmente injeta LoRA nas camadas de projeção mais importantes (por exemplo, atenção q_proj, v_proj), e também pode cobrir projeções de estado/ação. Se quiser personalizar, use --peft.target_modules.
Padrões comuns:
- Fornecer uma lista de sufixos de nomes de módulo (exemplo):
--peft.target_modules="['q_proj', 'v_proj']"
- Fornecer uma regex (exemplo; ajuste para os nomes de módulo reais no modelo):
--peft.target_modules='(model\\.vlm_with_expert\\.lm_expert\\..*\\.(down|gate|up)_proj|.*\\.(state_proj|action_in_proj|action_out_proj|action_time_mlp_in|action_time_mlp_out))'
Treinar totalmente alguns módulos (opcional)
Se você quiser que alguns módulos sejam totalmente treinados (em vez de apenas injetar LoRA), use --peft.full_training_modules. Por exemplo, treinar totalmente apenas state_proj:
--peft.full_training_modules="['state_proj']"
Sugestão de taxa de aprendizado (regra prática)
Taxas de aprendizado para LoRA costumam ser ~10× maiores do que para fine-tuning completo. Por exemplo, se o fine-tuning completo normalmente usa 1e-4, o LoRA pode começar em 1e-3. Se você usar um scheduler de taxa de aprendizado, a taxa de aprendizado final costuma ficar em torno de 1e-4 como referência.
(Opcional) Treinamento multi-GPU com Accelerate
Etapas de treinamento
Método 1: usar flags da CLI.
- Instale
accelerateno seu ambientelerobot.
pip install accelerate
- Inicie o treinamento multi-GPU com
accelerate launche as flags--multi_gpue--num_processes.
accelerate launch \
--multi_gpu \
--num_processes=2 \
$(which lerobot-train) \
--dataset.repo_id=${HF_USER}/my_dataset \
--policy.type=act \
--policy.repo_id=${HF_USER}/my_trained_policy \
--output_dir=outputs/train/act_multi_gpu \
--job_name=act_multi_gpu \
--wandb.enable=true
Principais flags do accelerate:
--multi_gpu: habilita treinamento multi-GPU.--num_processes: número de GPUs a usar (geralmente igual ao número de GPUs disponíveis na máquina).--mixed_precision=fp16: usa precisão mista fp16 (se o seu hardware suportar, você também pode usar bf16).
Observe: bf16 requer suporte de hardware e não está disponível em todas as GPUs.
| Precisão | Suporte de hardware |
|---|---|
| fp16 | Suportado por quase todas as GPUs NVIDIA |
| bf16 | Suportado apenas por algumas GPUs mais novas (Ampere e posteriores) |
Se a sua GPU não suportar bf16, escolha fp16 na configuração do Accelerate ou especifique fp16 explicitamente.
Método 2: usar um arquivo de configuração do accelerate (opcional).
Se você treina em múltiplas GPUs com frequência, pode salvar a configuração para evitar digitar repetidamente as mesmas flags.
accelerate config salva a configuração do seu hardware (número de GPUs, precisão mista, etc.) em um arquivo de configuração, para que você não precise reinserir essas opções ao executar accelerate launch depois. Isso não altera a lógica de treinamento do LeRobot; apenas reduz entradas repetidas na CLI.
Se você só usa multi-GPU ocasionalmente (ou se esta é a sua primeira vez), pular esta etapa é totalmente aceitável.
Na configuração interativa, para o cenário comum de “máquina única + múltiplas GPUs”, as escolhas típicas são:
- Ambiente de computação: Esta máquina
- Número de máquinas: 1
- Número de processos: número de GPUs que você quer usar
- IDs de GPU a usar: pressione Enter (usar todas as GPUs)
- Precisão mista: prefira fp16; escolha bf16 apenas se você souber que sua GPU o suporta
accelerate config
accelerate launch $(which lerobot-train) \
--dataset.repo_id=${HF_USER}/my_dataset \
--policy.type=act \
--policy.repo_id=${HF_USER}/my_trained_policy \
--output_dir=outputs/train/act_multi_gpu \
--job_name=act_multi_gpu \
--wandb.enable=true
Como multi-GPU afeta hiperparâmetros (e como ajustar)
LeRobot não ajusta automaticamente a taxa de aprendizado ou os passos de treinamento com base no número de GPUs, para evitar alterar silenciosamente o comportamento de treinamento. Isso é diferente de alguns outros frameworks de treinamento distribuído.
Se você quiser ajustar hiperparâmetros para multi-GPU, uma abordagem comum é:
- Passos: o batch size efetivo aumenta (batch_size × num_gpus), então você pode reduzir os passos aproximadamente proporcionalmente a
1 / num_gpuspara manter um número total semelhante de amostras vistas.
accelerate launch --num_processes=2 $(which lerobot-train) \
--batch_size=8 \
--steps=50000 \
--dataset.repo_id=lerobot/pusht \
--policy=act
- Taxa de aprendizado: como cada passo usa mais amostras, você geralmente pode escalar a taxa de aprendizado linearmente com o número de GPUs: new_lr = single_gpu_lr × num_gpus
accelerate launch --num_processes=2 $(which lerobot-train) \
--optimizer.lr=2e-4 \
--dataset.repo_id=lerobot/pusht \
--policy=act
Essas não são regras rígidas; são heurísticas comuns. Se você não tiver certeza, também pode manter a taxa de aprendizado e os passos inalterados, desde que o treinamento permaneça estável.
Para configuração avançada e solução de problemas, consulte a documentação do Accelerate: Accelerate.
(Opcional) Inferência assíncrona
Quando a inferência assíncrona não está habilitada, o fluxo de controle do LeRobot pode ser entendido como inferência sequencial / síncrona convencional: a política primeiro prevê um segmento de ações, depois executa esse segmento e só então espera pela próxima previsão.
Para modelos maiores, isso pode fazer com que o robô faça uma pausa perceptível enquanto espera pelo próximo bloco de ações.
O objetivo da inferência assíncrona é permitir que o robô execute o bloco de ações atual enquanto calcula o próximo com antecedência, reduzindo assim o tempo ocioso e melhorando a capacidade de resposta.
A inferência assíncrona é aplicável a políticas suportadas pelo LeRobot, incluindo políticas de ação baseadas em blocos como ACT, OpenVLA, Pi0 e SmolVLA.
Como a inferência é desacoplada do controle real, a inferência assíncrona também ajuda a aproveitar máquinas com recursos de computação mais fortes para realizar a inferência para o robô.
Você pode ler mais sobre inferência assíncrona no blog da Hugging Face
Primeiro, vamos apresentar alguns conceitos básicos:
-
Cliente: conecta-se ao braço robótico e às câmeras, coleta dados de observação (como imagens e poses do robô), envia essas observações para o servidor e recebe os blocos de ações retornados pelo servidor, executando-os em ordem.
-
Servidor: o dispositivo que fornece recursos de computação. Ele recebe dados da câmera e do braço robótico, realiza a inferência (isto é, o cálculo) para produzir blocos de ações e os envia de volta ao cliente. Pode ser o mesmo dispositivo conectado ao braço robótico e às câmeras, outro computador na mesma rede local ou um servidor em nuvem alugado na Internet.
-
Bloco de ações: uma sequência de comandos de ação do braço robótico obtida por inferência de política no lado do servidor.
Três cenários de implantação para inferência assíncrona
- Implantação em máquina única
O robô, as câmeras, o cliente e o servidor estão todos no mesmo dispositivo.
Este é o caso mais simples: o servidor pode escutar em 127.0.0.1, e o cliente também pode se conectar a 127.0.0.1:porta. O exemplo de comando na documentação oficial é para este cenário.
- Implantação em LAN
O robô e as câmeras estão conectados a um dispositivo leve, enquanto o servidor de política é executado em outra máquina de alta capacidade de computação na mesma rede local.
Nesse caso, o servidor deve escutar em um endereço acessível por outras máquinas, e o cliente também deve se conectar ao IP da LAN do servidor, em vez de 127.0.0.1.
- Implantação entre redes / em nuvem
O servidor de política é executado em um host em nuvem publicamente acessível, e o cliente se conecta a ele pela Internet pública.
Essa abordagem pode usar a GPU mais potente do host em nuvem. Quando as condições de rede são boas, o tempo de ida e volta da rede (latência de rede) às vezes pode ser relativamente pequeno em comparação com o tempo de inferência, mas isso depende do seu ambiente de rede real.
Observação de segurança: o pipeline de inferência assíncrona do LeRobot tem um risco relacionado a gRPC sem autenticação + desserialização com pickle. Se houver informações ou serviços importantes no servidor, não é recomendável expor o serviço diretamente à Internet em uma implantação pública. Uma abordagem mais segura é usar VPN ou tunelamento SSH, ou pelo menos restringir os IPs de origem permitidos no grupo de segurança ao IP público do seu próprio cliente.
Introdução à implantação de inferência assíncrona
Etapa 1: Configuração de ambiente
Primeiro, use pip para instalar as dependências adicionais necessárias para inferência assíncrona. Tanto o cliente quanto o servidor precisam ter o lerobot instalado junto com as dependências extras:
pip install -e ".[async]"
Etapa 2: Configuração e verificações de rede
- Problemas de proxy
Se o seu terminal atual estiver configurado para usar um proxy e a conexão se comportar de forma anormal, você pode desativar temporariamente as variáveis de ambiente de proxy:
unset http_proxy https_proxy ftp_proxy all_proxy HTTP_PROXY HTTPS_PROXY FTP_PROXY ALL_PROXY
Observação: o comando acima afeta apenas a sessão de terminal atual. Se você abrir outra janela de terminal, precisará executá-lo novamente.
- Abrir a porta no firewall / grupo de segurança
Implantação em máquina única: isso geralmente pode ser ignorado.
Implantação em LAN: você precisa abrir a porta de escuta no lado do servidor.
Exemplo de abertura da porta de escuta em uma configuração de LAN (executar no lado do servidor):
sudo ufw allow 8080/tcp
Implantação em nuvem: você precisa abrir essa porta no grupo de segurança do servidor em nuvem, e é recomendável restringir ao máximo os IPs de origem.
Se você estiver executando em um servidor em nuvem:
Abra a porta 8080 no grupo de segurança do console de gerenciamento do servidor ou use outra porta que já esteja aberta. Diferentes plataformas de serviços em nuvem lidam com isso de maneiras diferentes; consulte a documentação do seu provedor de nuvem.
- Confirmar o endereço IP
Esta etapa pode ser ignorada para implantação em máquina única (o endereço IP de uma única máquina é sempre 127.0.0.1).
Se for uma implantação em LAN:
Você precisa confirmar e memorizar o endereço IP da LAN do lado do servidor. Quando o cliente se conectar, o que deve ser preenchido é o IP da LAN da máquina que está executando o policy_server, não o IP do próprio cliente.
Linux / Jetson / Raspberry Pi:
hostname -I
Se vários endereços forem exibidos, geralmente escolha o que corresponde à interface de rede LAN atual, por exemplo 192.168.x.x.
Você também pode usar:
ip addr
para visualizar o campo inet sob a interface de rede atualmente conectada.
Windows:
ipconfig
Encontre um campo como Endereço IPv4 . . . . . . . . . . . : 192.168.14.140; esse é o endereço IP da LAN dessa máquina.
macOS:
ifconfig
Encontre o campo inet correspondente à interface de rede atualmente conectada; esse é o endereço IP da LAN.
Precisamos memorizar o endereço IP da LAN do lado do servidor. Usaremos <LAN IP address> para nos referir a ele.
Se for uma implantação em servidor na nuvem:
Procure o IP público no painel de controle do servidor. Geralmente ele é chamado de uma das seguintes formas:
Public IPv4
External IP
Public IP address
EIP
Public IP
Precisamos memorizar o endereço IP público. Usaremos<server public IP>para nos referir a ele.
- Teste de conexão
Implantação em máquina única: esta etapa pode ser ignorada
Implantação em LAN / nuvem: recomenda-se testar a partir do lado do cliente se a porta do servidor é alcançável. Exemplos de testes são os seguintes:
Exemplo de LAN: execute no lado do cliente
nc -vz <LAN IP address> 8080
Exemplo de nuvem: execute no lado do cliente
nc -vz <server public IP> 8080
Etapa 3: Iniciar o serviço
Cenário A: Implantação em máquina única
Inicie o serviço local em um terminal:
python -m lerobot.async_inference.policy_server \
--host=127.0.0.1 \
--port=8080
Depois que ele iniciar com sucesso, você precisa manter este terminal aberto. Você precisará abrir um novo terminal para executar outros comandos.
Cenário B: Implantação em LAN
Execute no lado do servidor:
python -m lerobot.async_inference.policy_server \
--host=0.0.0.0 \
--port=8080
Nesse caso, quando o cliente se conectar, o --server_address deve ser o endereço IP da LAN do lado do servidor, ou seja,<LAN IP address>:8080.
Cenário C: Implantação em servidor na nuvem
Execute no lado do servidor:
python -m lerobot.async_inference.policy_server \
--host=0.0.0.0 \
--port=8080
Nesse caso, quando o cliente se conectar, o --server_address deve ser o endereço IP público do servidor, ou seja, <server public IP>:8080.
Etapa 4: Escolher parâmetros de inferência
Execute no lado do cliente:
python -m lerobot.async_inference.robot_client \
--server_address=<ip address>:8080 \
--robot.type=so100_follower \
--robot.port=/dev/tty.usbmodem585A0076841 \
--robot.id=follower_so100 \
--robot.cameras="{ laptop: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}, phone: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}}" \
--task="dummy" \
--policy_type=your_policy_type \
--pretrained_name_or_path=user/model \
--policy_device=cuda \
--actions_per_chunk=50 \
--chunk_size_threshold=0.5 \
--aggregate_fn_name=weighted_average \
--debug_visualize_queue_size=True
Explicações dos parâmetros:
--server_address
Especifica o endereço e a porta do policy server. <ip address> deve ser substituído por 127.0.0.1 (máquina local), <LAN IP address> (LAN) ou<server public IP> (servidor na nuvem).
--robot.type, --robot.port, --robot.id, --robot.cameras
Parâmetros do dispositivo de hardware. Eles devem ser mantidos consistentes com os parâmetros usados durante a coleta do conjunto de dados.
--task
A descrição da tarefa. Políticas de visão e linguagem como SmolVLA podem determinar o alvo da ação com base no texto da tarefa.
--policy_type
Substitua isto pelo nome específico da política, por exemplo:
-
smolvla
-
act
-
--pretrained_name_or_path
Este valor deve ser substituído pelo caminho do modelo no lado do servidor ou por um caminho de modelo no Hugging Face.
--policy_device
Especifica o dispositivo de inferência usado no lado do servidor.
Pode ser cuda, mps ou cpu.
--actions_per_chunk=50
Especifica quantas ações são produzidas em cada inferência.
Quanto maior esse valor:
Vantagem: o buffer de ações é mais suficiente, tornando menos provável que se esgote Desvantagem: o horizonte de predição é maior, então o erro de controle pode se acumular de forma mais perceptível
--chunk_size_threshold=0.5
Especifica quando solicitar o próximo bloco de ações do servidor.
Este é um limite, geralmente no intervalo de 0 a 1.
Pode ser entendido como: quando a proporção restante da fila de ações atual cai abaixo desse limite, o cliente enviará uma nova observação com antecedência e solicitará o próximo bloco de ações.
Definir como 0.5 aqui significa:
quando o bloco de ações atual estiver aproximadamente pela metade consumido
o cliente começa a solicitar o próximo bloco de ações
Quanto maior esse valor, mais frequentemente as solicitações são enviadas e mais responsivo o sistema se torna, mas a carga no servidor também aumenta.
Quanto menor esse valor, mais o comportamento se aproxima da inferência síncrona.
--aggregate_fn_name=weighted_average
Especifica o método de agregação para intervalos de ações sobrepostos.
Na inferência assíncrona, quando o bloco de ações antigo ainda não foi totalmente executado, o novo bloco de ações já pode ter chegado.
Nesse caso, os dois blocos se sobrepõem em parte do intervalo de tempo, e é necessária uma função de agregação para combiná-los na ação final executada.
O significado de weighted_average é:
usar uma média ponderada para fundir a parte sobreposta.
Isso geralmente torna a troca de ações mais suave e reduz mudanças bruscas.
--debug_visualize_queue_size=True
Se deve visualizar o tamanho da fila de ações em tempo de execução.
Quando ativado, permite ver de forma mais direta se a fila atinge o fundo com frequência, o que ajuda a ajustar actions_per_chunk e chunk_size_threshold.
Etapa 5: Ajustar parâmetros com base no comportamento do robô
Na inferência assíncrona, há dois parâmetros adicionais que precisam de ajuste e que não existem na inferência síncrona:
Parâmetro Valor inicial sugerido Descrição
actions_per_chunk 50 Quantas ações a política produz de uma vez. Valores típicos: 10–50.
chunk_size_threshold 0.5 Quando a proporção restante da fila de ações é ≤ chunk_size_threshold, o cliente envia uma nova solicitação de bloco de ações. O intervalo de valores é [0, 1].
Quando --debug_visualize_queue_size=True, a mudança no tamanho da fila de ações será plotada em tempo de execução.
O que a inferência assíncrona precisa equilibrar é: a velocidade com que o servidor gera blocos de ações deve ser maior ou igual à velocidade com que o cliente consome blocos de ações. Caso contrário, a fila de ações ficará vazia e o robô começará a engasgar novamente (isso pode ser visto como a curva batendo no fundo na visualização da fila).
A velocidade com que o servidor gera blocos de ações é afetada por fatores como tamanho do modelo, tipo de dispositivo, VRAM / memória e poder de computação da GPU.
A velocidade com que o cliente consome blocos de ações é afetada pelo fps de execução configurado.
Se a fila frequentemente ficar vazia, você precisa aumentar actions_per_chunk, aumentar chunk_size_threshold ou reduzir o fps.
Se a curva da fila oscilar com frequência, mas as ações restantes na fila forem sempre suficientes, você pode diminuir chunk_size_threshold de forma apropriada.
Em geral:
a faixa empírica para actions_per_chunk é 10–50
a faixa empírica para chunk_size_threshold é 0.5–0.7; ao ajustar, recomenda-se começar em 0.5 e aumentá-lo gradualmente
Se você encontrar o seguinte erro:
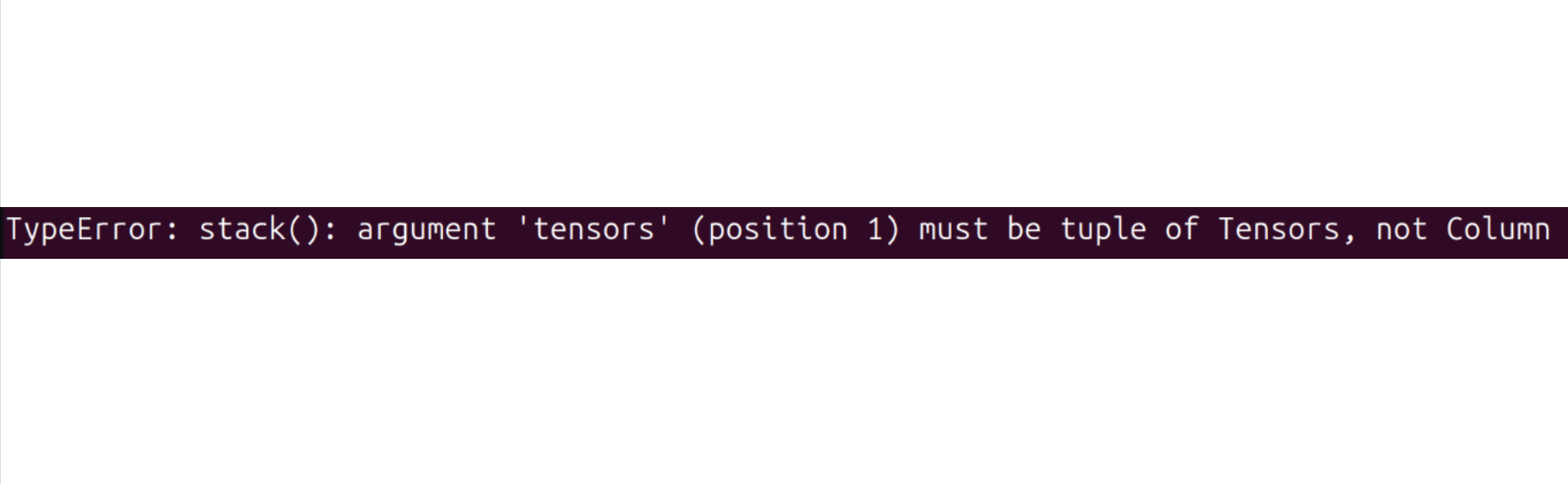
Tente executar o seguinte comando para resolvê-lo:
pip install datasets==2.19
O treinamento deve levar várias horas. Você encontrará checkpoints em outputs/train/act_so100_test/checkpoints.
Para retomar o treinamento a partir de um checkpoint, abaixo está um comando de exemplo para retomar do checkpoint last da política act_so101_test:
lerobot-train \
--config_path=outputs/train/act_so101_test/checkpoints/last/pretrained_model/train_config.json \
--resume=true
Fazer upload dos checkpoints da política
Quando o treinamento terminar, faça upload do checkpoint mais recente com:
huggingface-cli upload ${HF_USER}/act_so101_test \
outputs/train/act_so101_test/checkpoints/last/pretrained_model
Você também pode fazer upload de checkpoints intermediários com:
CKPT=010000
huggingface-cli upload ${HF_USER}/act_so101_test${CKPT} \
outputs/train/act_so101_test/checkpoints/${CKPT}/pretrained_model
FAQ
-
Se você estiver seguindo esta documentação/tutorial, faça git clone do repositório GitHub recomendado
https://github.com/Seeed-Projects/lerobot.git. O repositório recomendado nesta documentação é uma versão estável verificada; o repositório oficial do Lerobot é continuamente atualizado para a versão mais recente, o que pode causar problemas imprevistos, como diferentes versões de conjuntos de dados, comandos diferentes, etc. -
Se você encontrar o seguinte erro ao calibrar IDs de servos:
`Motor ‘gripper’ was not found, Make sure it is connected`Verifique cuidadosamente se o cabo de comunicação está conectado corretamente ao servo e se a fonte de alimentação está fornecendo a tensão correta.
-
Se você encontrar:
Could not connect on port "/dev/ttyACM0"E você pode ver que ACM0 existe ao executar
ls /dev/ttyACM*, isso significa que você esqueceu de conceder permissões à porta serial. Digitesudo chmod 666 /dev/ttyACM*no terminal para corrigir isso. -
Se você encontrar:
No valid stream found in input file. Is -1 of the desired media type?Instale o ffmpeg 7.1.1 usando
conda install ffmpeg=7.1.1 -c conda-forge.
-
Se você encontrar:
ConnectionError: Failed to sync read 'Present_Position' on ids=[1,2,3,4,5,6] after 1 tries. [TxRxResult] There is no status packet!Você precisa verificar se o braço robótico na porta correspondente está ligado e se os cabos de dados dos servos de barramento estão soltos ou desconectados. Se a luz de um servo não estiver acesa, isso significa que o cabo do servo anterior está solto.
-
Se você encontrar o seguinte erro ao calibrar o braço robótico:
Magnitude 30841 exceeds 2047 (max for sign_bit_index=11)Desligue e reinicie o braço robótico e tente calibrar novamente. Este método também pode ser usado se o ângulo MAX atingir um valor de dezenas de milhares durante a calibração. Se isso não funcionar, você precisa recalibrar os servos correspondentes, incluindo a calibração do ponto médio e a gravação do ID.
-
Se você encontrar durante a fase de avaliação:
File exists: 'home/xxxx/.cache/huggingface/lerobot/xxxxx/seeed/eval_xxxx'Exclua primeiro a pasta que começa com
eval_e depois execute o programa novamente. -
Se você encontrar durante a fase de avaliação:
`mean` is infinity. You should either initialize with `stats` as an argument or use a pretrained modelObserve que palavras-chave como "front" e "side" no parâmetro
--robot.camerasdevem ser estritamente consistentes com as usadas ao coletar o conjunto de dados. -
Se você reparou ou substituiu partes do braço robótico, exclua completamente os arquivos em
~/.cache/huggingface/lerobot/calibration/robotsou~/.cache/huggingface/lerobot/calibration/teleoperatorse recalibre o braço robótico. Caso contrário, mensagens de erro podem aparecer, pois as informações de calibração são armazenadas em arquivos JSON nesses diretórios. -
Treinar ACT em 50 conjuntos de dados leva aproximadamente 6 horas em um laptop com uma RTX 3060 (8GB) e cerca de 2–3 horas em computadores com GPUs RTX 4090 ou A100.
-
Durante a coleta de dados, garanta que a posição da câmera, o ângulo e a iluminação ambiente sejam estáveis. Reduza a quantidade de fundo instável e de pedestres capturados pela câmera, pois mudanças excessivas no ambiente de implantação podem fazer com que o braço robótico não consiga agarrar corretamente.
-
Para o comando de coleta de dados, certifique-se de que o parâmetro
num-episodesesteja configurado para coletar dados suficientes. Não pause manualmente no meio, pois a média e a variância dos dados são calculadas somente após a conclusão da coleta, e são necessárias para o treinamento. -
Se o programa indicar que não consegue ler dados de imagem da câmera USB, certifique-se de que a câmera USB não esteja conectada por meio de um hub. A câmera USB deve estar conectada diretamente ao dispositivo para garantir alta velocidade de transmissão de imagem.
-
Se você encontrar um bug como
AttributeError: module 'rerun' has no attribute 'scalar'. Did you mean: 'scalars'?, você pode fazer o downgrade da versão do rerun para resolver o problema.
pip3 install rerun-sdk==0.23
Se você encontrar problemas de software ou de dependências de ambiente que não possam ser resolvidos, além de verificar a seção de FAQ no final deste tutorial, relate o problema prontamente na plataforma LeRobot ou no canal LeRobot no Discord.
Citação
Projeto TheRobotStudio: SO-ARM10x
Projeto Huggingface: Lerobot
Dnsty: Jetson Containers
Suporte Técnico e Discussão de Produtos
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.