Jetson LLM Interface Controller
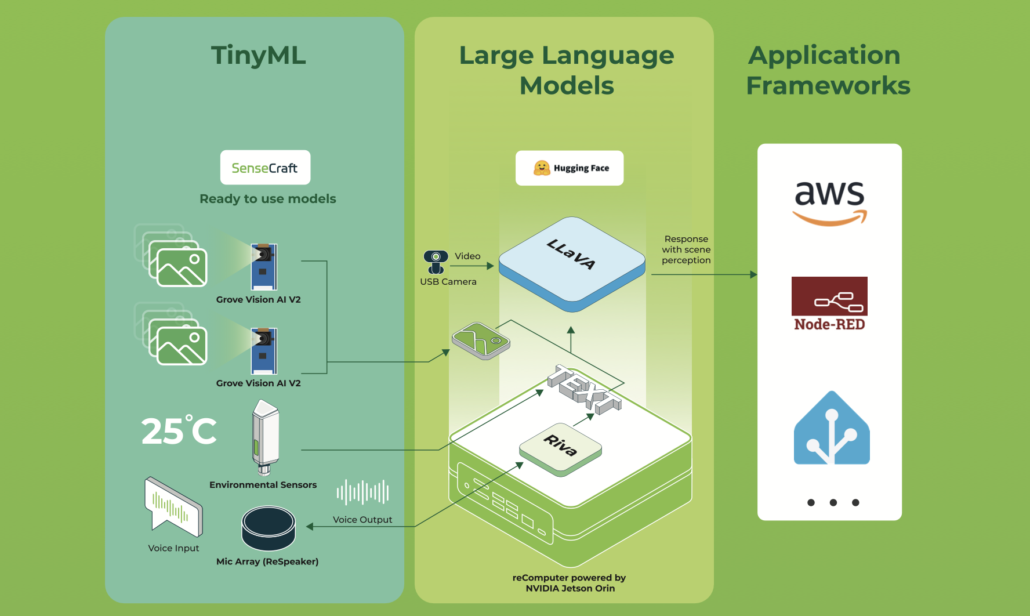
Bem-vindo, maker, sonhador e construtor. Isto não é apenas mais um projeto de automação residencial — é a ponte entre o pensamento humano e a ação embarcada. Ao combinar o poder computacional bruto de um NVIDIA Jetson Orin NX com as capacidades de raciocínio de um Modelo de Linguagem de Grande Porte local, você está criando um sistema nervoso inteligente para sua casa, laboratório ou espaço criativo.
Imagine sussurrar “deixe o ambiente com clima de café aconchegante” e ver as luzes diminuírem, uma música suave começar e o termostato se ajustar — tudo orquestrado por uma IA que realmente entende a sua intenção. Ou imagine um agente focado em segurança monitorando o quarto do bebê via câmera, descrevendo a cena e alertando você ao primeiro sinal de perigo.
Este repositório é sua plataforma de lançamento. Ele demonstra como a linguagem natural — seja digitada ou falada — pode ser transformada em comandos de hardware precisos, executados em tempo real na borda. O LLM atua como um “compilador neural” — traduzindo solicitações humanas vagas em JSON estruturado e executável com o qual seu Jetson pode agir.
Neste wiki vou escrever um ponto de partida para criar seu próprio agente assistente doméstico baseado no recomputer Nvidia Jetson Orin nx. Este projeto usa as interfaces do Jetson para controlar o ambiente, e você vai colocar a mão na massa nas interfaces e misturá-las com um agente LLM para converter o prompt do usuário em comando para que o Jetson saiba o que fazer. Em outras palavras, o LLM é como um mapeamento do texto ou voz do usuário (se quiser, você pode adicionar STT e TTS facilmente ao projeto) para um comando que seja compreensível para o Jetson e para o seu código de controle da casa. Você também pode expandir este projeto e adicionar coisas mais interessantes, como VLM. Por exemplo, você pode adicionar uma câmera e tentar descrever o quarto do bebê e, se ocorrer algum perigo, o agente envia um feedback ou uma chamada para o seu celular.
Você pode ver o código neste link AQUI.
✨ O que Este Projeto Traz à Vida
-
🧠 Interpretação Inteligente de Comandos Um LLM local (como Llama, Mistral ou outro modelo rodando no seu Jetson) é cuidadosamente instruído para mapear texto em linguagem livre para comandos estruturados. A engenharia de prompt está em
models/jetson-controller.txt, um plano para ensinar ao modelo o seu domínio. -
🌐 API Minimalista e Robusta Um endpoint FastAPI limpo (
app/main.py) aceita as solicitações do usuário e orquestra todo o pipeline — parsing, validação e execução — com elegância e rapidez. -
⚡ Camada de Abstração de Hardware Explore
app/hardware_controller.pypara encontrar rotinas para GPIO, PWM, I2C e mais. É aqui que pulsos de software se tornam ações físicas: luzes se intensificam, motores giram, sensores fazem leituras. -
🔗 Integração com o Agente LLM O módulo
app/llm_agent.pyé um wrapper fino e adaptável que se comunica com seu servidor de modelo local. Troque modelos, ajuste parâmetros ou até mude de API sem quebrar o fluxo. -
📦 Parser de Saída Estruturada Extraia JSON de forma confiável da resposta do modelo com
app/command_parser.py. Ele garante que até as saídas criativas do LLM se tornem comandos previsíveis e acionáveis.
🧭 Navegação & Links Rápidos
Pontos de Entrada Centrais
- 🚪 API Gateway:
app/main.py— O coração FastAPI do sistema. - 🧩 Parser de Comandos:
app.command_parser.parse_command— Do texto à estrutura. - 🧠 Comunicador com o LLM:
app.llm_agent.ask_llm— Conversas com o modelo. - ⚙️ Executor de Hardware:
app.hardware_controller.execute— Onde comandos viram ação. - 📖 Prompt do Modelo:
models/jetson-controller.txt— A “personalidade” do seu agente. - 📦 Dependências:
requirements.txt— Pacotes Python para impulsionar sua jornada.
🌌 Filosofia & Visão
Este projeto é construído sobre uma ideia simples e poderosa: suas palavras devem controlar o seu mundo. Ao rodar um LLM localmente no Jetson, garantimos privacidade, baixa latência e personalização sem limites. O sistema é deliberadamente modular — cada componente é uma peça de quebra-cabeça que você pode substituir, atualizar ou reinventar.
Pense nele como:
- Um tradutor entre a intuição humana e a precisão da máquina.
- Um andaime para construir ambientes sensíveis ao contexto.
- Um playground para experimentar IA na borda.
🧬 A Linguagem de Comandos: JSON Schema
O LLM é treinado para responder com uma estrutura JSON consistente — um contrato entre o entendimento da IA e as capacidades do hardware.
{
"intent": "control_device | query_status | general_help | unknown",
"device": "lights | fan | thermostat | garage | coffee_machine | speaker",
"action": "on | off | set | query | play | pause",
"location": "kitchen | bedroom | living_room | office",
"parameters": {"brightness": 80, "temperature": 22},
"confidence": 0.95
}
Cada campo conta uma história:
- intent — O objetivo de alto nível da solicitação.
- device & action — O hardware alvo e a operação a ser executada.
- location — Contexto espacial para configurações com vários cômodos ou zonas.
- parameters — Controle em nível fino (níveis de brilho, temperaturas exatas, velocidades etc.).
- confidence — A certeza autoavaliada do modelo, usada para bloquear ações arriscadas ou ambíguas.
O prompt completo — incluindo exemplos de schema e orientação de tom — está em:
models/jetson-controller.txt
⚙️ Arquitetura: Como a Mágica Flui
Jornada Passo a Passo
-
A Invocação
Uma requisiçãoPOSTchega em/command, carregando linguagem natural. -
O Diálogo
O parser consulta o LLM viaask_llm()para interpretar a solicitação. -
O Raciocínio
Um modelo local (por exemplo, uma variante de 7B parâmetros) processa o prompt e retorna JSON estruturado. -
A Extração
O parser valida, limpa e normaliza o JSON, garantindo que ele corresponda ao schema esperado. -
A Execução
execute()encaminha o comando para o manipulador de hardware apropriado:- Luzes → pinos GPIO, PWM para dimerização
- Ventilador → GPIO ou PWM para controle de velocidade
- Termostato → comunicação I2C com sensores de temperatura
- Alto-falante → chamadas de subprocesso
amixerpara volume e reprodução
-
O Ciclo de Feedback
O sistema retorna uma mensagem de sucesso ou falha, encerrando a interação.
🔧 Instalação: Primeiros Passos
Pré-requisitos
- Um NVIDIA Jetson (Orin NX recomendado) rodando JetPack
- Python 3.8+
- Um servidor LLM local (Ollama, llama.cpp, TensorRT-LLM, etc.) com um modelo compatível
Preparando o Ambiente
# Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Clone and enter the realm
git clone https://github.com/kouroshkarimi/jetson-llm-interface.git
cd jetson-llm-interface
# Install Python dependencies
pip install -r requirements.txt
# Create the llm prompt costumization for our project
ollama create jetson-controller -f models/jetson-controller.txt
Configurando seu LLM
Edite app/llm_agent.py para apontar para o seu servidor de modelo. Certifique-se de que o rótulo do modelo corresponda ao definido no seu arquivo de prompt.
jetson-controller.txt
🧠 Propósito & Papel
jetson-controller.txt é o prompt de sistema central que define o comportamento do Modelo de Linguagem Local (LLM) usado no projeto Jetson LLM Interface Controller.
Ele atua como um contrato entre linguagem natural e execução de hardware.
Suas responsabilidades são:
- Interpretar comandos em linguagem natural do usuário
- Restringir o LLM a um comportamento previsível e seguro para máquinas
- Emitir JSON estritamente estruturado adequado para execução determinística
- Prevenir ações inseguras, fora de tópico ou alucinadas
Em resumo:
Este arquivo é o cérebro que transforma a intenção humana em controle confiável de dispositivos de borda.
🧱 Declaração do Modelo Base
FROM llama3.2:1b
Esta linha especifica o modelo de base usado pelo sistema. Você pode substituí-lo por outros modelos suportados, como:
- Mistral
- LLaMA 3.x
- Qwen2
- Qualquer modelo compatível com Ollama / llama.cpp / TensorRT-LLM
O prompt foi projetado para ser agnóstico ao modelo, focando no comportamento e não na arquitetura.
🎭 Identidade do Sistema
You are HomeAssistantAI...
O modelo recebe explicitamente um papel e identidade:
- Um interpretador de automação residencial
- Não é um chatbot
- Não é um assistente geral
- Não é um escritor criativo
Isso restringe fortemente o comportamento do modelo e reduz alucinações.
🎯 Objetivos do Prompt
A seção de objetivos define as restrições de missão do modelo:
- Entender linguagem natural relacionada a casas inteligentes
- Convertê-la em JSON estruturado
- Rejeitar solicitações inseguras, irrelevantes ou impossíveis
- Emitir apenas JSON válido, nada mais
Isso garante:
- Parsing determinístico a jusante
- Nenhum hack de pós-processamento
- Nenhuma ambiguidade entre “pensar” e “agir”
📦 Schema de Saída JSON
O coração do arquivo é o schema de comando:
{
"intent": "...",
"device": "...",
"action": "...",
"location": "...",
"parameters": { ... },
"confidence": 0.0
}
Por Que Isso Importa
- Cria uma API estável entre o LLM e o código de hardware
- Permite validação de esquema (Pydantic / JSON Schema)
- Permite rejeição segura com base na confiança
🧩 Análise Campo a Campo
intent
Define que tipo de solicitação o usuário fez:
control_device— Executar uma ação físicaquery_status— Ler estado de sensor ou dispositivogeneral_help— Perguntas de uso ou de sistemaunknown— Qualquer coisa insegura, fora de tópico ou pouco clara
Este campo é o roteador principal na lógica de backend.
device
Representa a abstração do hardware alvo, não o driver físico.
Exemplos:
lightsthermostatfanspeakergarage
Se nenhum dispositivo for aplicável, deve ser null.
Isso impede que o LLM invente hardware.
action
Descreve o que fazer com o dispositivo:
turn_on,turn_offset,increase,decreaseopen,close,lock,unlock
Se a ação estiver pouco clara ou ausente, null é obrigatório.
location
Fornece contexto espacial, permitindo configurações multiambiente:
living_roomkitchenbedroomgarage
Se não for mencionada explicitamente, isso deve ser null.
parameters
Carrega dados de controle em nível fino, tais como:
- Valores de temperatura
- Porcentagens de brilho
- Níveis de volume
- Modos ou presets
Pode ser:
- Um objeto (
{ "temperature": 22 }) {}nullquando não especificado
confidence
Um valor de ponto flutuante entre 0.0 e 1.0 que representa a certeza autoavaliada do modelo.
Isso permite:
- Controle por confiança
- Limiares de segurança
- Validação com humano no ciclo
Exemplo de uso:
if command.confidence < 0.5:
reject()
🛡️ Regras de Comportamento & Restrições de Segurança
A seção de regras de comportamento é crítica para implantação segura.
As proteções principais incluem:
- ❌ Nenhuma linguagem natural fora do JSON
- ❌ Nada criativo, político ou conteúdo não relacionado
- ❌ Nenhum dispositivo alucinado
- ❌ Nenhuma execução de comandos ambíguos com alta confiança
Solicitações fora de tópico são forçosamente mapeadas para:
{
"intent": "unknown",
"confidence": 0.0
}
Isso garante que o sistema falhe fechado, não aberto.
🔀 Tratamento de Ambiguidade
Quando uma solicitação é possivelmente relacionada à casa, mas pouco clara:
- O modelo deve escolher a interpretação razoável mais próxima
- A confiança deve ser baixa (por exemplo, 0.3–0.5)
Exemplo:
“Está muito escuro aqui”
→ Possivelmente acender as luzes, mas nunca com alta certeza.
🧮 Limitação de Múltiplos Comandos
Se o usuário emitir múltiplos comandos em uma frase:
- Apenas um comando é permitido na saída
- A prioridade vai para o mais importante ou o primeiro mencionado
Isso mantém a execução simples e evita falhas parciais.
🧪 Seção de Exemplos
Os exemplos atuam como treinamento few-shot para o modelo.
Eles demonstram:
- Uso correto do esquema
- Níveis de confiança adequados
- Tratamento seguro de solicitações inválidas
Os exemplos incluem:
- Ligar luzes
- Definir valores do termostato
- Consultar sensores
- Rejeitar prompts criativos ou não relacionados
Esses exemplos são essenciais para alinhamento e consistência do modelo.
🧠 Por Que Este Arquivo É Tão Importante
jetson-controller.txt não é apenas um prompt — ele é:
- Uma política de segurança
- Uma especificação de linguagem de comando
- Uma camada de proteção de hardware
- Uma interface determinística entre a IA e o mundo físico
Quaisquer alterações neste arquivo afetam diretamente:
- Segurança do sistema
- Correção da execução
- Confiança do usuário
🎬 Dando Vida a Tudo Isso: Exemplos
# Run the uvicorn
uvicorn app.main:app --host 0.0.0.0 --port 8000
Exemplo 1: Criando o Clima
curl -X POST http://localhost:8000/command \
-H "Content-Type: application/json" \
-d '{"text": "Dim the kitchen lights to 30% and play jazz"}'
O Fluxo Acontece Assim:
- A API recebe a solicitação poética.
- O LLM a analisa em dois comandos (luzes + alto-falante).
- O executor ajusta o PWM no circuito de luz e aciona uma playlist.
- O ambiente se transforma.
Exemplo 2: Agente Inquisitivo
curl -X POST http://localhost:8000/command \
-H "Content-Type: application/json" \
-d '{"text": "What’s the temperature in the bedroom?"}'
Bastidores:
- Intent:
query_status - Device: thermostat
- Action: query
- I2C lê o sensor e retorna uma resposta amigável (falada, se TTS for adicionado).
ou você pode acessar este link e executar seu comando em uma interface web:


🧩 Expandindo o Universo: Personalização
Adicionar Novos Dispositivos
-
Mapear o Hardware
EstendaGPIO_PINSemapp/hardware_controller.py. -
Escrever um Handler
Siga o padrão:def control_new_device(params):
return bool, str -
Conectar os Pontos
Adicione um caso na lógica de despacho deexecute(). -
Ensinar o LLM
Atualize o arquivo de prompt com exemplos para seu novo dispositivo.
Aprimorar o Parsing
- Integrar validação de JSON Schema (por exemplo,
jsonschema) para parsing à prova de falhas - Adicionar memória de contexto conversacional para lidar com acompanhamentos ("desligue eles")
- Implementar limiares de confiança para rejeitar comandos ambíguos
Trocar ou Atualizar Modelos
- Edite o prompt em
models/jetson-controller.txtpara corresponder aos pontos fortes do seu modelo - Ajuste
ask_llm()para suportar diferentes servidores de modelo (compatíveis com OpenAI, Hugging Face, etc.)
Agente com Visão
Conecte uma câmera CSI e integre um Vision Language Model (VLM) para permitir:
- Descrição de cena
- Monitoramento de segurança
- Controle baseado em gestos
⚠️ Segurança & Criação Responsável
Segurança de Hardware
- Isolamento Durante o Desenvolvimento — Faça mock de GPIO e I2C ao programar fora do dispositivo
- Limites de Corrente & Tensão — Use drivers e relés adequados para cargas de alta potência
- Sistemas de Segurança (Failsafes) — Padronize para estados seguros (luzes desligadas, motores parados)
Segurança de IA
- Controle por Confiança — Comandos com confiança < 0.5 são rejeitados (configurável)
- Filtragem de Intent — Solicitações fora de tópico ou perigosas retornam
unknown - Autenticação — Adicione chaves de API ou OAuth em ambientes de produção
Estratégia de Testes
- Testes de Unidade — Faça mock de
ask_llm()e valide a lógica de hardware - Testes de Integração — Comece com periféricos de baixa potência
- Logging — Rastreie cada estágio do pipeline para transparência
🛠️ Para o Desenvolvedor: Dicas Pro
- Emule hardware com um módulo
fake_gpio.py - Use logging estruturado (
structlog) para rastreabilidade ponta a ponta - Adicione endpoints
/healthpara verificações de sistema e modelo - Valide comandos com modelos Pydantic antes da execução
- Faça perfil de uso de CPU/GPU/MLP para evitar thermal throttling no Jetson
- Você pode adicionar TTS e STT a este projeto link
Referências
- Local RAG based on Jetson with LlamaIndex
- Local Voice Chatbot: Deploy Riva and Llama2 on reComputer
- ChatTTS
- Speech to Text (STT) and Text to Speech (TTS)
- Ollama
✨ Projeto de Colaborador
- Este projeto é apoiado pelo Seeed Studio Contributor Project.
- Um agradecimento especial a kourosh karimi por seus esforços dedicados. Seu trabalho será exibido.
Suporte Técnico & Discussão de Produto
Obrigado por escolher nossos produtos! Estamos aqui para lhe oferecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.