Converter e Quantizar Modelos de IA

A ferramenta de conversão de modelos de IA da reCamera atualmente oferece suporte a frameworks como PyTorch, ONNX, TFLite e Caffe. Modelos de outros frameworks precisam ser convertidos para o formato ONNX. Para instruções sobre como converter modelos de outras arquiteturas de deep learning para ONNX, você pode consultar o site oficial do ONNX: https://github.com/onnx/tutorials.
O fluxograma para implantar modelos de IA na reCamera é mostrado abaixo.
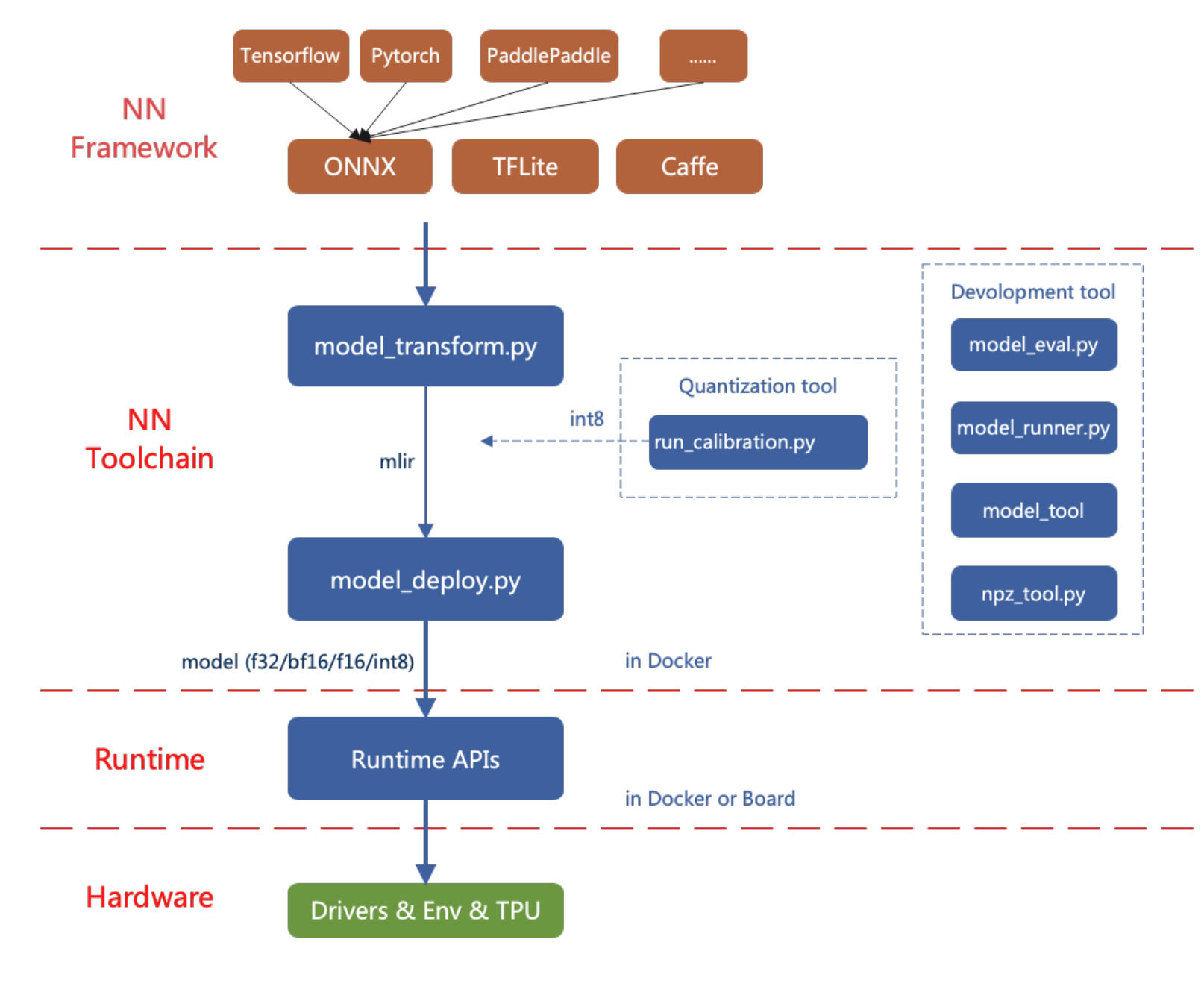
Este artigo apresenta como usar a ferramenta de conversão de modelos de IA da reCamera por meio de exemplos simples.
Configurar o ambiente de trabalho
Método 1: Instalação em uma imagem Docker (recomendado)
Baixe a imagem necessária do DockerHub (clique aqui) e recomendamos usar a versão 3.1:
docker pull sophgo/tpuc_dev:v3.1
Se você estiver usando Docker pela primeira vez, pode executar os seguintes comandos para instalação e configuração (necessário apenas na configuração inicial):
sudo apt install docker.io
sudo systemctl start docker
sudo systemctl enable docker
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp docker
Em seguida, crie um contêiner no diretório atual da seguinte forma:
docker run --privileged --name MyName -v $PWD:/workspace -it sophgo/tpuc_dev:v3.1
** Substitua "MyName" pelo nome desejado para o seu contêiner*
Use pip para instalar tpu_mlir dentro do contêiner Docker, assim como no Method 1:
pip install tpu_mlir[all]==1.7
Método 2: Instalação local
Primeiro verifique se o ambiente de sistema atual atende a:
Se não for atendido ou se a instalação falhar, escolha o Method 2 para instalar a ferramenta de conversão de modelo.
Instale tpu_mlir usando pip:
pip install tpu_mlir==1.7
As dependências exigidas por tpu_mlir variam ao lidar com modelos de diferentes frameworks. Para arquivos de modelo gerados por ONNX ou Torch, instale as dependências adicionais usando o seguinte comando:
pip install tpu_mlir[onnx]==1.7
pip install tpu_mlir[torch]==1.7
Atualmente, cinco configurações são suportadas: onnx, torch, tensorflow, caffe e paddle. Ou você pode usar o seguinte comando para instalar todas as dependências:
pip install tpu_mlir[all]==1.7
Quando o arquivo tpu_mlir-{version}.whl já existir localmente, você também pode usar o seguinte comando para instalá-lo:
pip install path/to/tpu_mlir-{version}.whl[all]
Converter e Quantizar Modelos de IA para o formato cvimodel
Preparando o ONNX
A reCamera já adaptou a série YOLO para inferência local. Portanto, esta seção usa yolo11n.onnx como exemplo para demonstrar como converter um modelo ONNX para o cvimodel.
O cvimodel é o formato de modelo de IA usado para inferência local na reCamera.
O método para converter e quantizar modelos PyTorch, TFLite e Caffe é o mesmo apresentado nesta seção.
Aqui está o link para download de yolo11n.onnx. Você pode clicar no link para baixar o modelo e copiá-lo para o seu Workspace para uso posterior.
Baixe o modelo: Download yolo11n.onnx Este arquivo ONNX pode ser usado diretamente nos exemplos das seções seguintes, sem a necessidade de modificar a versão IR ou a versão Opset.
Atualmente, o ONNX neste wiki é baseado em versão IR 8 e versão Opset 17. Se o seu arquivo ONNX for convertido a partir de um exemplo da Ultralytics após dezembro de 2024, ele poderá falhar nos processos subsequentes devido a uma versão mais alta.
Você pode visualizar as informações do arquivo ONNX usando o Netron:
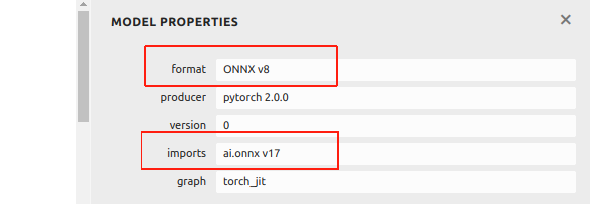
Se o seu arquivo ONNX for superior a IR v8 e Opset v17, , fornecemos um exemplo aqui para ajudá-lo a fazer o downgrade. Primeiro, instale onnx via pip:
pip install onnx
Puxe o programa para modificar a versão do arquivo ONNX a partir do GitHub:
git clone https://github.com/jjjadand/ONNX_Downgrade.git
cd ONNX_Downgrade/
Execute o script fornecendo os caminhos de arquivo do modelo de entrada e saída como argumentos de linha de comando:
python downgrade_onnx.py <input_model_path> <output_model_path> --target_ir_version <IR_version> --target_opset_version <Opset_version>
<input_model_path>: O caminho para o modelo ONNX original que você deseja fazer o downgrade.<output_model_path>: O caminho onde o modelo rebaixado será salvo.- --target_ir_version
<IR_version>: Opcional. A versão IR de destino para a qual será feito o downgrade. O padrão é 8. - --target_opset_version
<Opset_version>: Opcional. A versão Opset de destino para a qual será feito o downgrade. O padrão é 17.
Por exemplo, usando as versões padrão (IR v8, Opset v17):
python downgrade_onnx.py model_v12.onnx model_v8.onnx
Isso carregará model_v12.onnx, fará o downgrade para a versão IR 8, definirá a versão opset 17, validará e salvará o novo modelo como model_v8.onnx.
Usando versões personalizadas (IR v9, Opset v11):
python downgrade_onnx.py model_v12.onnx model_v9.onnx --target_ir_version 9 --target_opset_version 11
Isso carregará model_v12.onnx, fará o downgrade para a versão IR 9, definirá a versão opset 11, validará e salvará o novo modelo como model_v9.onnx.
- Para evitar erros, recomendamos usar ONNX com IR v8 e Opset v17.
Preparando o Workspace
Crie o diretório model_yolo11n no mesmo nível de tpu-mlir. Os arquivos de imagem geralmente fazem parte do conjunto de dados de treinamento do modelo, usados para calibração durante o processo de quantização subsequente.
Digite o seguinte comando no terminal:
git clone -b v1.7 --depth 1 https://github.com/sophgo/tpu-mlir.git
cd tpu-mlir
source ./envsetup.sh
./build.sh
mkdir model_yolo11n && cd model_yolo11n
cp -rf ${REGRESSION_PATH}/dataset/COCO2017 .
cp -rf ${REGRESSION_PATH}/image .
mkdir Workspace && cd Workspace
Depois de obter um arquivo ONNX utilizável, coloque-o no diretório Workspace que você criou. A estrutura de diretórios é a seguinte:
model_yolo11n
├── COCO2017
├── image
└── Workspace
└──yolo11n.onnx
As etapas subsequentes serão executadas no seu Workspace.
ONNX para MLIR
A conversão de ONNX para MLIR é uma etapa intermediária no processo de transformação do modelo. Antes de obter um modelo adequado para inferência na reCamera, você precisa primeiro converter o modelo ONNX para o formato MLIR. Este arquivo MLIR serve como uma ponte para gerar o modelo final otimizado para o mecanismo de inferência da reCamera.
Se a entrada for imagem, precisamos saber o pré-processamento do modelo antes de transferi-lo. Se o modelo usar arquivos npz pré-processados como entrada, nenhum pré-processamento precisa ser considerado. O processo de pré-processamento é formulado da seguinte forma ( x representa a entrada):
y = (x − mean) × scale
O intervalo de normalização do yolo11 é [0, 1], e a imagem do yolo11 oficial é RGB. Cada valor será multiplicado por 1/255, correspondendo respectivamente a 0.0, 0.0, 0.0 e 0.0039216, 0.0039216, 0.0039216 quando convertido em mean e scale. Os parâmetros para mean e scale diferem dependendo do modelo, pois são determinados pelo método de normalização usado para cada modelo específico.
Você pode consultar o seguinte comando de conversão de modelo no terminal:
model_transform \
--model_name yolo11n \
--model_def yolo11n.onnx \
--input_shapes "[[1,3,640,640]]" \
--mean "0.0,0.0,0.0" \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
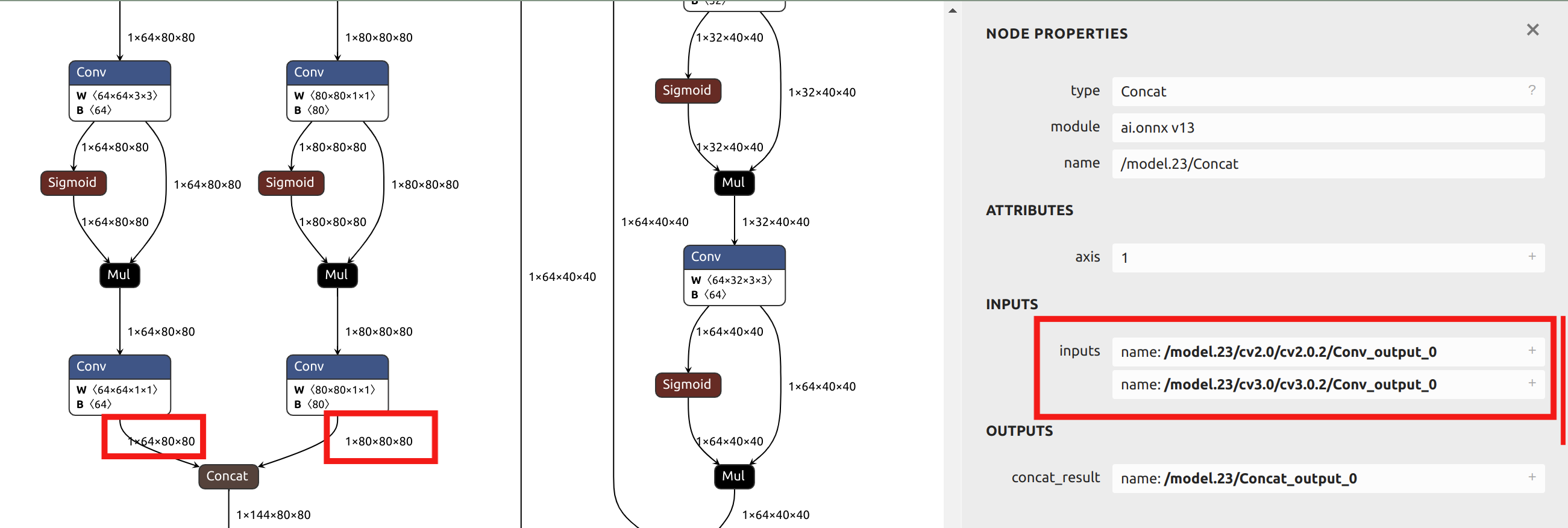
--output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" \
--test_input ../image/dog.jpg \
--test_result yolo11n_top_outputs.npz \
--mlir yolo11n.mlir
Após a conversão para um arquivo mlir, um arquivo ${model_name}_in_f32.npz será gerado, que é o arquivo de entrada para os modelos subsequentes.
Quanto à seleção do parâmetro --output_names, a conversão do modelo YOLO11 neste exemplo não escolhe a saída final chamada output0. Em vez disso, seleciona as seis saídas antes do head do modelo como parâmetro. Você pode importar o arquivo ONNX para o Netron para visualizar a estrutura do modelo.
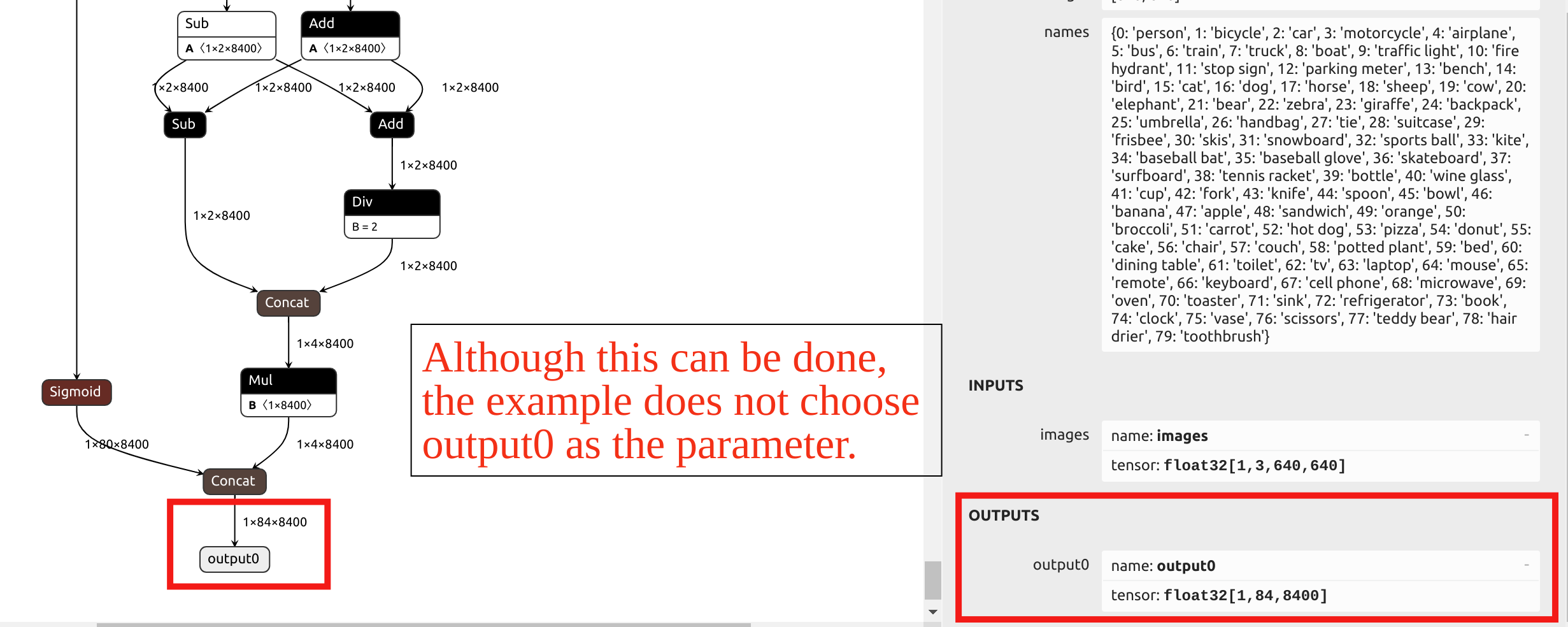
Os operadores no head do YOLO têm precisão muito baixa após a quantização INT8. Se output0 no final fosse escolhido como parâmetro, seria necessária quantização de precisão mista.
Como as seções subsequentes deste artigo fornecerão exemplos de quantização de precisão mista, e esta seção usa uma única precisão de quantização para o exemplo, as saídas antes do head são escolhidas como parâmetros. Ao visualizar o modelo ONNX no Netron, você pode ver as posições dos seis nomes de saída:
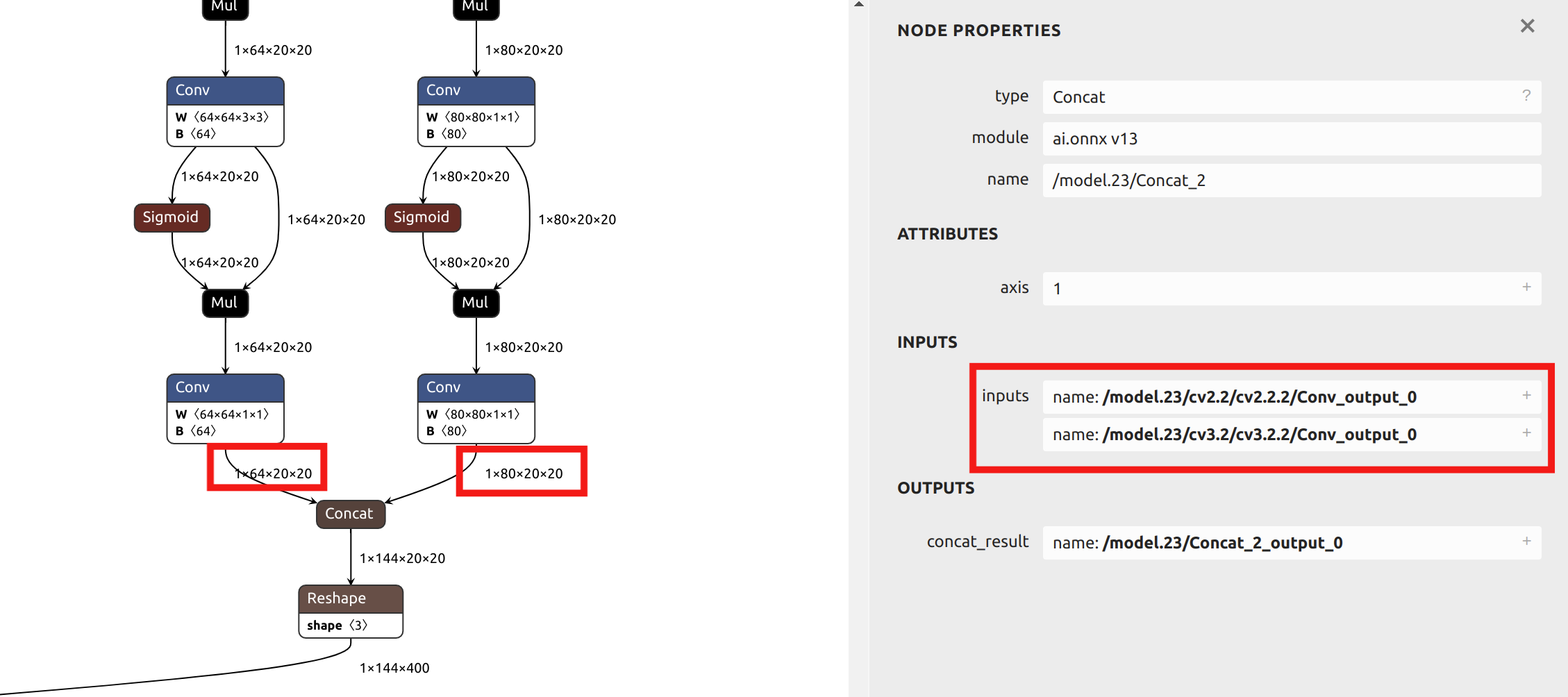
Descrição dos principais parâmetros para model_transform:
| Nome do Parâmetro | Obrigatório? | Descrição |
|---|---|---|
| model_name | Sim | Especifique o nome do modelo. |
| model_def | Sim | Especifique o arquivo de definição do modelo, como '.onnx', '.tflite' ou '.prototxt'. |
| input_shapes | Não | Especifique o formato de entrada, por exemplo, [[1,3,640,640]]. Uma matriz bidimensional que pode suportar múltiplas entradas. |
| input_types | Não | Especifique os tipos de entrada, como int32. Use vírgulas para separar múltiplas entradas. O padrão é float32. |
| resize_dims | Não | Especifique as dimensões para as quais a imagem original deve ser redimensionada. Se não for especificado, ela será redimensionada para o tamanho de entrada do modelo. |
| keep_aspect_ratio | Não | Se deve manter a proporção ao redimensionar. O padrão é false; se for true, o preenchimento com zeros será usado para áreas faltantes. |
| mean | Não | Valor médio para cada canal da imagem. O padrão é 0,0,0,0. |
| scale | Não | Valor de escala para cada canal da imagem. O padrão é 1.0,1.0,1.0. |
| pixel_format | Não | Tipo de imagem, que pode ser 'rgb', 'bgr', 'gray' ou 'rgbd'. O padrão é 'bgr'. |
| channel_format | Não | Tipo de canal para entrada de imagem, que pode ser 'nhwc' ou 'nchw'. Para entradas que não são de imagem, use 'none'. O padrão é 'nchw'. |
| output_names | Não | Especifique os nomes de saída. Se não for especificado, serão usados os nomes de saída padrão do modelo. |
| test_input | Não | Especifique um arquivo de entrada para validação, como uma imagem, arquivo npy ou npz. Se não for especificado, nenhuma validação de acurácia será realizada. |
| test_result | Não | Especifique o arquivo de saída para o resultado da validação. |
| excepts | Não | Especifique as camadas de rede a serem excluídas da validação, separadas por vírgulas. |
| mlir | Sim | Especifique o nome e o caminho do arquivo MLIR de saída. |
MLIR para F16 cvimodel
Se você quiser converter de mlir para cvimodel com precisão F16, pode inserir o seguinte comando de referência no terminal:
model_deploy \
--mlir yolo11n.mlir \
--quant_input \
--quantize F16 \
--customization_format RGB_PACKED \
--processor cv181x \
--test_input ../image/dog.jpg \
--test_reference yolo11n_top_outputs.npz \
--fuse_preprocess \
--tolerance 0.99,0.9 \
--model yolo11n_1684x_f16.cvimodel
Após uma conversão bem-sucedida, você obterá um arquivo cvimodel com precisão FP16 que pode ser usado diretamente para inferência. Se você precisar de um arquivo cvimodel com precisão INT8 ou precisão mista, consulte o conteúdo nas seções posteriores do artigo a seguir.
Descrição dos Principais Parâmetros de model_deploy:
| Nome do Parâmetro | Obrigatório? | Descrição |
|---|---|---|
| mlir | Sim | Arquivo MLIR |
| quantize | Sim | Tipo de quantização (F32/F16/BF16/INT8) |
| processor | Sim | Depende da plataforma que está sendo usada. A versão 2024 da reCamera seleciona "cv181x" como parâmetro. |
| calibration_table | Não | O caminho da tabela de calibração. Obrigatório quando for quantização INT8 |
| tolerance | Não | Tolerância para a similaridade mínima entre os resultados de inferência MLIR quantizado e MLIR fp32 |
| test_input | Não | O arquivo de entrada para validação, que pode ser uma imagem, npy ou npz. Nenhuma validação será realizada se não for especificado |
| test_reference | Não | Dados de referência para validar a tolerância do mlir (no formato npz). É o resultado de cada operador |
| compare_all | Não | Comparar todos os tensores, se definido |
| excepts | Não | Nomes das camadas de rede que precisam ser excluídas da validação. Separados por vírgula |
| op_divide | Não | Tentar dividir a op maior em várias ops menores para atingir o objetivo de economia de memória ion, adequado para alguns modelos específicos |
| model | Sim | Nome do arquivo de modelo de saída (incluindo caminho) |
| skip_validation | Não | Pular a verificação de correção do cvimodel para aumentar a eficiência de implantação; a verificação do cvimodel está ativada por padrão |
Após a compilação, é gerado um arquivo chamado yolo11n_1684x_f16.cvimodel. O modelo quantizado pode ter uma pequena perda de precisão, mas será mais leve e terá uma velocidade de inferência mais rápida.
MLIR para INT8 cvimodel
Geração da tabela de calibração
Antes de converter para o modelo INT8, é necessário executar a calibração para obter a tabela de calibração.
O número de dados de entrada fica entre cerca de 100 a 1000, de acordo com a situação.
Em seguida, use a tabela de calibração para gerar um cvimodel simétrico ou assimétrico. Geralmente, não é recomendado usar o assimétrico se o simétrico já atender aos requisitos, porque o desempenho do modelo assimétrico será ligeiramente pior do que o do modelo simétrico.
Aqui está um exemplo usando 100 imagens existentes do COCO2017 para realizar a calibração:
run_calibration \
yolo11n.mlir \
--dataset ../COCO2017 \
--input_num 100 \
-o yolo11n_calib_table
Após executar o comando acima, será gerado um arquivo chamado yolo11n_calib_table, que é usado como arquivo de entrada para a compilação subsequente do modelo INT8.
Descrição dos principais parâmetros de run_calibration:
| Parâmetro | Obrigatório? | Descrição |
|---|---|---|
| N/A | Sim | Especificar o arquivo MLIR |
| dataset | Não | Especificar o diretório de amostras de entrada, onde o caminho contém as imagens, arquivos npz ou npy correspondentes |
| data_list | Não | Especificar a lista de amostras; é obrigatório selecionar dataset ou data_list |
| input_num | Não | Especificar o número de amostras de calibração; se definido como 0, todas as amostras são usadas |
| tune_num | Não | Especificar o número de amostras de ajuste; o padrão é 10 |
| histogram_bin_num | Não | Número de bins para o histograma; o padrão é 2048 |
| o | Sim | Gerar o arquivo da tabela de calibração |
Compilar para cvimodel quantizado simétrico INT8
Após obter o arquivo yolo11n_cali_table, execute o seguinte comando para convertê-lo em um modelo quantizado simétrico INT8:
model_deploy \
--mlir yolo11n.mlir \
--quantize INT8 \
--quant_input \
--processor cv181x \
--calibration_table yolo11n_calib_table \
--test_input ../image/dog.jpg \
--test_reference yolo11n_top_outputs.npz \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--model yolo11n_1684x_int8_sym.cvimodel
Após a compilação, é gerado um arquivo chamado yolo11n_1684x_int8_sym.cvimodel. O modelo quantizado para INT8 é mais leve e possui velocidade de inferência mais rápida em comparação com modelos quantizados para F16/BF16.
Teste rápido
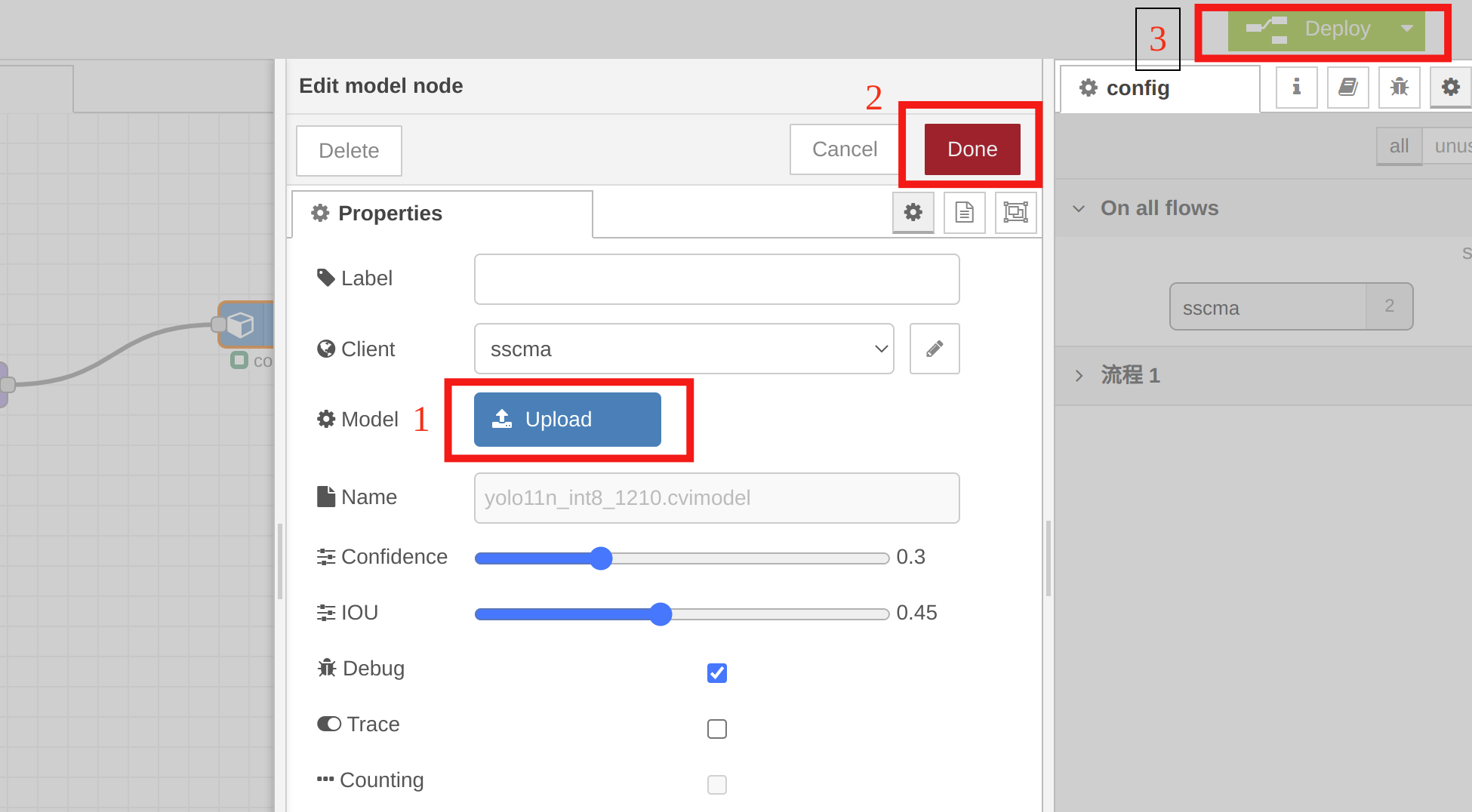
Você pode usar Node-RED na reCamera para visualização e verificar rapidamente o yolo11n_1684x_int8_sym.cvimodel convertido. Basta configurar alguns nós, como mostrado no vídeo de exemplo abaixo:
Você precisa selecionar o yolo11n_1684x_int8_sym.cvimodel no nó model para uma verificação rápida. Clique duas vezes no nó de modelo, clique em "Upload" para importar o modelo quantizado, depois clique em "Done" e, por fim, clique em "Deploy".
Podemos visualizar os resultados de inferência do modelo quantizado INT8 no nó preview. O cvimodel obtido por meio de métodos corretos de conversão e quantização ainda é confiável:
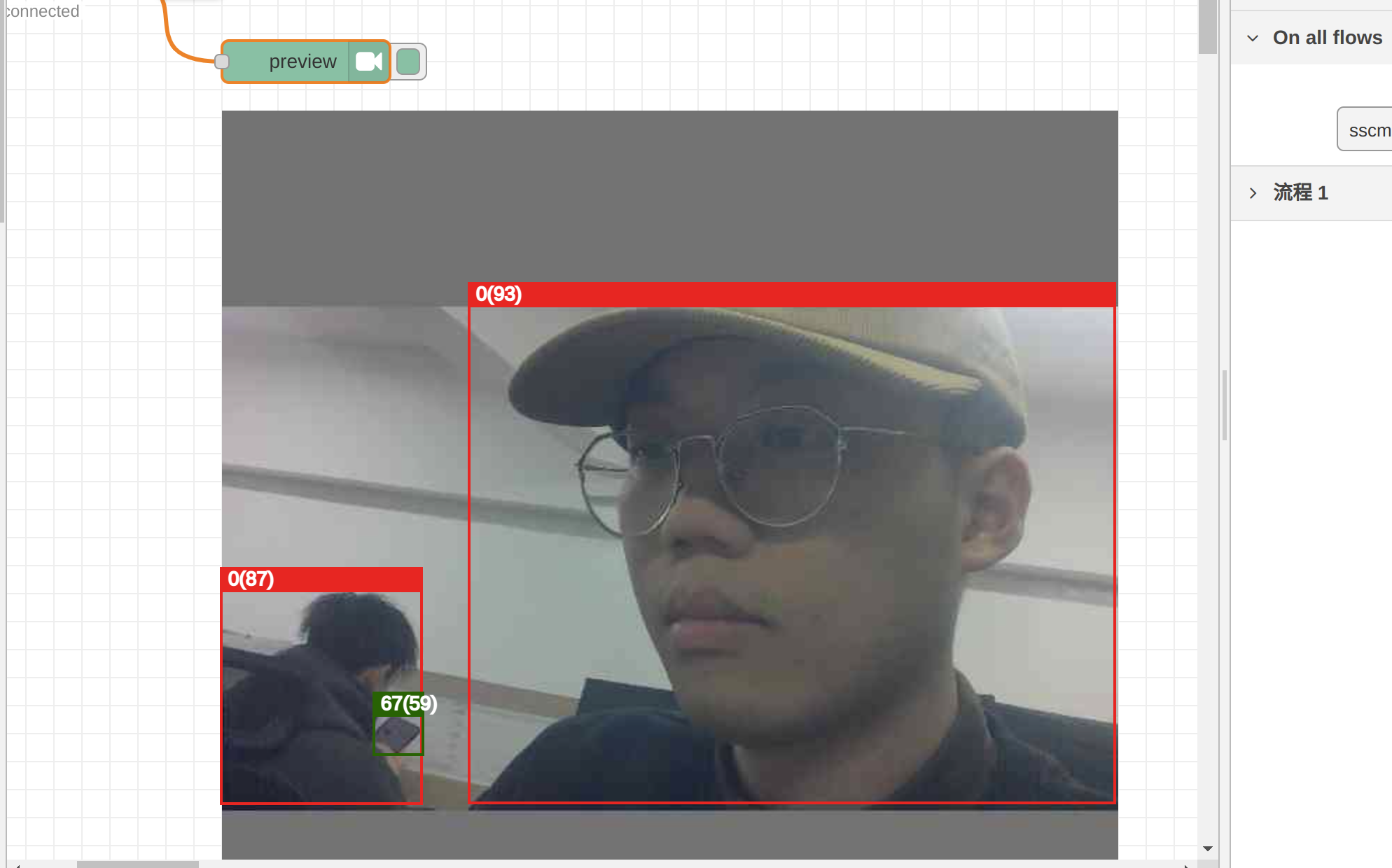
Atualmente, o Node-RED da reCamera suporta apenas testes de pré-visualização para um número limitado de modelos. No futuro, adaptaremos mais modelos. Se você importar um modelo personalizado no Node-RED ou não definir o tensor de saída especificado conforme mostrado em nosso exemplo, o backend do Node-RED não oferecerá suporte a testes de pré-visualização, mesmo que o seu cvimodel esteja correto.
Lançaremos tutoriais sobre pré-processamento e pós-processamento para vários modelos, para que você possa escrever seu próprio código para inferir o seu cvimodel personalizado.
Quantização de Precisão Mista
Quando a precisão de certas camadas em um modelo é facilmente afetada pela quantização, mas ainda precisamos de uma velocidade de inferência mais rápida, uma quantização de precisão única pode não ser mais adequada. Nesses casos, a quantização de precisão mista pode lidar melhor com a situação. Para camadas que são mais sensíveis à quantização, podemos escolher a quantização F16/BF16, enquanto para camadas com perda de precisão mínima, podemos usar INT8.
Em seguida, usaremos yolov5s.onnx como exemplo para demonstrar como converter e quantizar rapidamente o modelo em um cvimodel de precisão mista. Antes de ler esta seção, certifique-se de ter passado pelas seções anteriores do artigo, pois as operações desta seção se baseiam no conteúdo abordado anteriormente.
Aqui está o link para download de yolov5s.onnx. Você pode clicar no link para baixar o modelo e copiá-lo para seu workspace para uso posterior.
Baixe o modelo: Download yolov5s.onnx
Após baixar o modelo, coloque-o em seu workspace para as próximas etapas.
mkdir model_yolov5s && cd model_yolov5s
cp -rf ${REGRESSION_PATH}/dataset/COCO2017 .
cp -rf ${REGRESSION_PATH}/image .
mkdir workspace && cd workspace
A primeira etapa ainda é converter o modelo para o arquivo .mlir. Como a perda de precisão no head do YOLO é mínima ao usar quantização de precisão mista, diferente da abordagem anterior, escolheremos o nome de saída final no final, em vez das saídas antes do head, no parâmetro --output_names. Visualize o ONNx no Netron:
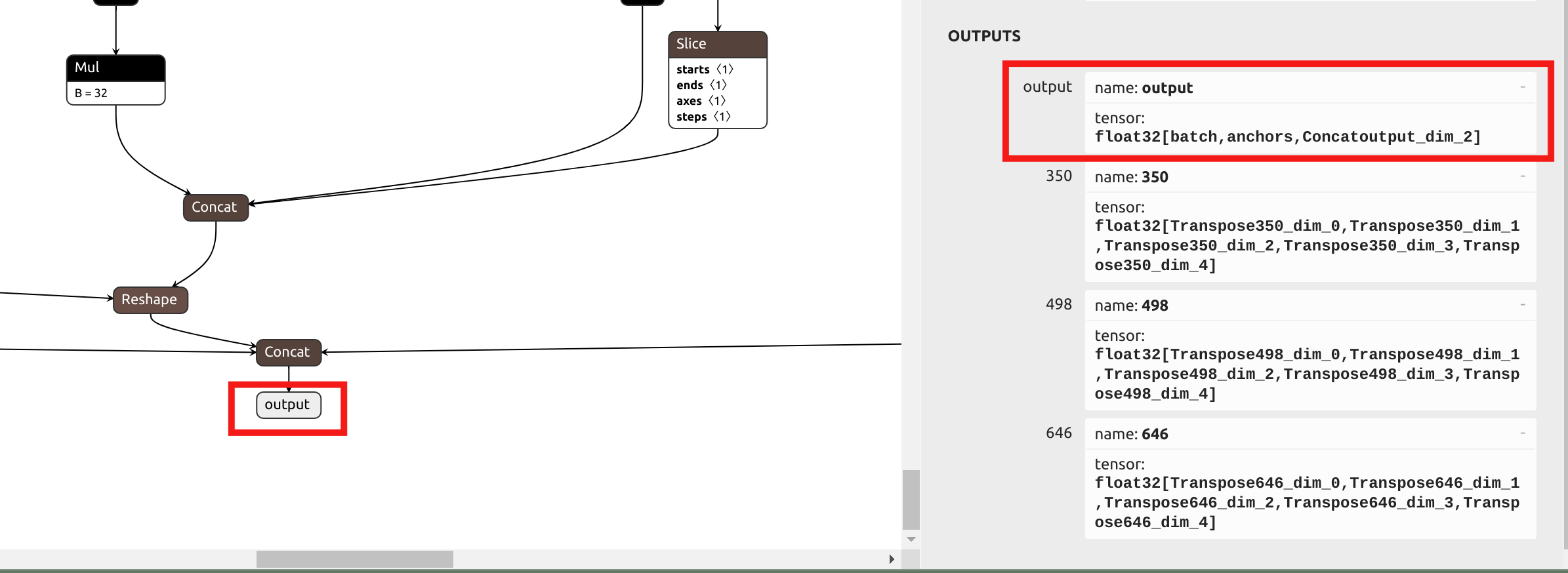
Como os parâmetros de normalização do yolov5 são os mesmos do yolo11, podemos obter o seguinte comando para o model_transform:
model_transform \
--model_name yolov5s \
--model_def yolov5s.onnx \
--input_shapes [[1,3,640,640]] \
--mean 0.0,0.0,0.0 \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
--output_names output \
--test_input ../image/dog.jpg \
--test_result yolov5s_top_outputs.npz \
--mlir yolov5s.mlir
Em seguida, também precisamos gerar a tabela de calibração, e esta etapa é a mesma da seção anterior:
run_calibration \
yolov5s.mlir \
--dataset ../COCO2017 \
--input_num 100 \
-o yolov5s_calib_table
Diferente da seção em que convertemos o modelo yolo11 quantizado simetricamente em int8, antes de executar o model_deploy, precisamos gerar uma tabela de quantização de precisão mista.** O comando de referência é o seguinte:
run_qtable \
yolov5s.mlir \
--dataset ../COCO2017 \
--calibration_table yolov5s_calib_table \
--processor cv181x \
--min_layer_cos 0.99 \
--expected_cos 0.999 \
-o yolov5s_qtable
A descrição dos parâmetros de run_qtable é mostrada na tabela abaixo:
| Parâmetro | Obrigatório? | Descrição |
|---|---|---|
| N/A | Sim | Especifique o arquivo MLIR |
| dataset | Não | Especifique o diretório de amostras de entrada, que contém arquivos de imagens, npz ou npy |
| data_list | Não | Especifique a lista de amostras; dataset ou data_list deve ser selecionado |
| calibration_table | Sim | Tabela de calibração de entrada |
| processor | Sim | Depende da plataforma que está sendo usada. A versão 2024 da reCamera seleciona "cv181x" como parâmetro. |
| fp_type | Não | Especifique o tipo de precisão em ponto flutuante para precisão mista, suporta auto, F16, F32, BF16; o padrão é auto |
| input_num | Não | Especifique o número de amostras de entrada; o padrão é 10 |
| expected_cos | Não | Especifique a similaridade de cosseno mínima esperada para a camada de saída final da rede; o padrão é 0,99 |
| min_layer_cos | Não | Especifique a similaridade de cosseno mínima para a saída de cada camada; valores abaixo deste limite usarão computação em ponto flutuante; o padrão é 0,99 |
| debug_cmd | Não | Especifique a string de comando de depuração para uso em desenvolvimento; o padrão é vazio |
| global_compare_layers | Não | Especifique as camadas a serem substituídas para comparação da saída final, por exemplo, 'layer1,layer2' ou 'layer1:0.3,layer2:0.7' |
| loss_table | Não | Especifique o nome do arquivo para salvar os valores de perda de todas as camadas quantizadas para tipos de ponto flutuante; o padrão é full_loss_table.txt |
Depois que a camada predecessora de cada camada é convertida para o modo de ponto flutuante correspondente com base em seu cos, o valor de cos calculado para essa camada é verificado. Se o cos ainda for menor que o parâmetro min_layer_cos, a camada atual e suas camadas sucessoras diretas serão configuradas para usar operações em ponto flutuante.
run_qtable recalcula o cos da saída de toda a rede após configurar cada par de camadas adjacentes para usar computação em ponto flutuante. Se o cos exceder o parâmetro expected_cos especificado, a busca é encerrada. Portanto, definir um expected_cos maior resultará em mais camadas sendo tentadas para operações em ponto flutuante.
Por fim, execute model_deploy para obter o cvimodel de precisão mista:
model_deploy \
--mlir yolov5s.mlir \
--quantize INT8 \
--quantize_table yolov5s_qtable \
--calibration_table yolov5s_calib_table \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--processor cv181x \
--model yolov5s_mix-precision.cvimodel
Após obter yolov5s_mix-precision.cvimodel, podemos usar model_tool para ver informações detalhadas sobre o modelo:
model_tool --info yolov5s_mix-precision.cvimodel
Informações-chave como TensorMap e WeightMap serão impressas no terminal:
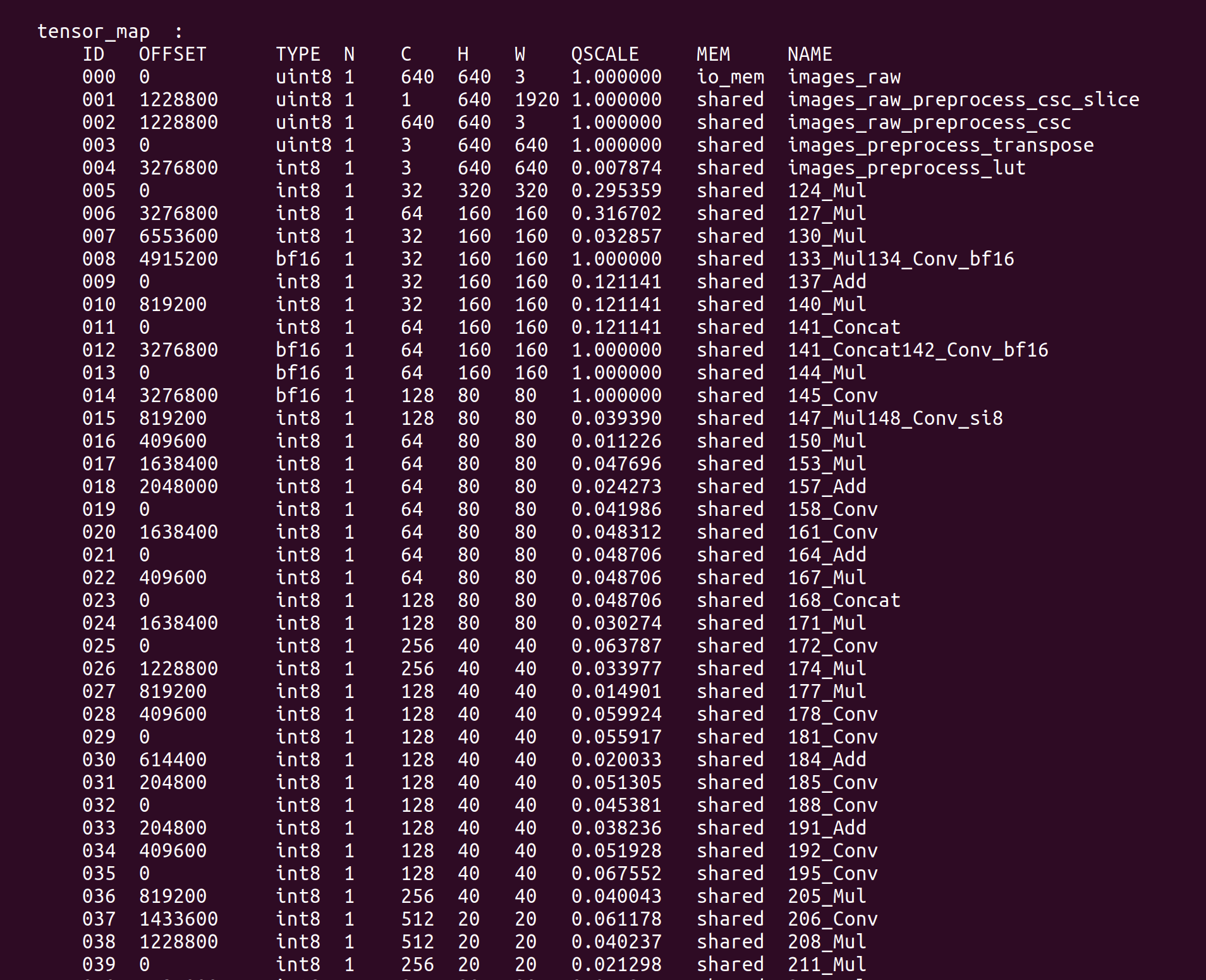
Podemos executar um exemplo na reCamera para verificar o modelo YOLOv5 quantizado em precisão mista. Puxe o exemplo de teste compilado:
git clone https://github.com/jjjadand/yolov5_Test_reCamera.git
Copie os exemplos compilados e yolov5s_mix-precision.cvimodel usando um software como o FileZilla para a reCamera. (Você pode revisar Introdução à reCamera)
Após a conclusão da cópia, execute o comando no terminal da recamera:
cp /path/to/yolov5s_mix-precision.cvimodel /path/to/yolov5_Test_reCamera/solutions/sscma-model/build/
cd yolov5_Test_reCamera/solutions/sscma-model/build/
sudo ./sscma-model yolov5s_mix-precision.cvimodel Dog.jpg Out.jpg
Visualize Out.jog, os resultados de inferência do modelo yolov5 quantizado em precisão mista são os seguintes:

Recursos
Suporte Técnico & Discussão de Produto
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja o mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.