Detecção de Palavras-Chave com TensorFlow Lite
Introdução
Este projeto demonstra como usar o TensorFlow Lite para detecção de palavras-chave no ReSpeaker 2-Mics Pi HAT v2. A detecção de palavras-chave permite a identificação em tempo real de palavras pré-definidas a partir de entrada de áudio, possibilitando aplicações como dispositivos controlados por voz e sistemas interativos. Iremos guiá-lo pelas etapas para treinar um modelo TensorFlow Lite, implantá-lo no ReSpeaker HAT e executar o reconhecimento de voz localmente.
Requisitos de Hardware e Software
- Hardware: Raspberry Pi com ReSpeaker 2-Mics Pi HAT v2
- Software: TensorFlow Lite, Google Colab, Python e bibliotecas de suporte
Aplicações
A detecção de palavras-chave pode ser aplicada em:
- Dispositivos de casa inteligente
- Robôs controlados por voz
- Quiosques interativos
O que é o TensorFlow Lite?
TensorFlow Lite é uma versão leve do TensorFlow projetada para dispositivos móveis e embarcados. Ele possibilita inferência de aprendizado de máquina com baixa latência e binários pequenos, tornando-o ideal para executar modelos em dispositivos de borda como o Raspberry Pi.
Treinar e Obter o Modelo TensorFlow Lite
Conjunto de Dados
Usaremos um subconjunto do conjunto de dados Speech Commands para o treinamento. O conjunto de dados contém arquivos de áudio WAV de pessoas dizendo diferentes palavras, coletados pelo Google e disponibilizados sob uma licença CC BY. O conjunto de dados pode ser baixado daqui. Para mais informações sobre conjuntos de dados, consulte este guia.
Por que Usar o Google Colab?
Google Colab é uma plataforma em nuvem para executar notebooks Jupyter. Ele oferece acesso gratuito a recursos de GPU, tornando-o uma excelente escolha para treinar modelos de aprendizado de máquina sem exigir poder de computação local.
Etapas
Agora usaremos um Notebook do Google Colab para realizar o treinamento de dados e gerar um modelo TensorFlow Lite no formato .tflite.
-
Etapa 1. Abra este Notebook Python
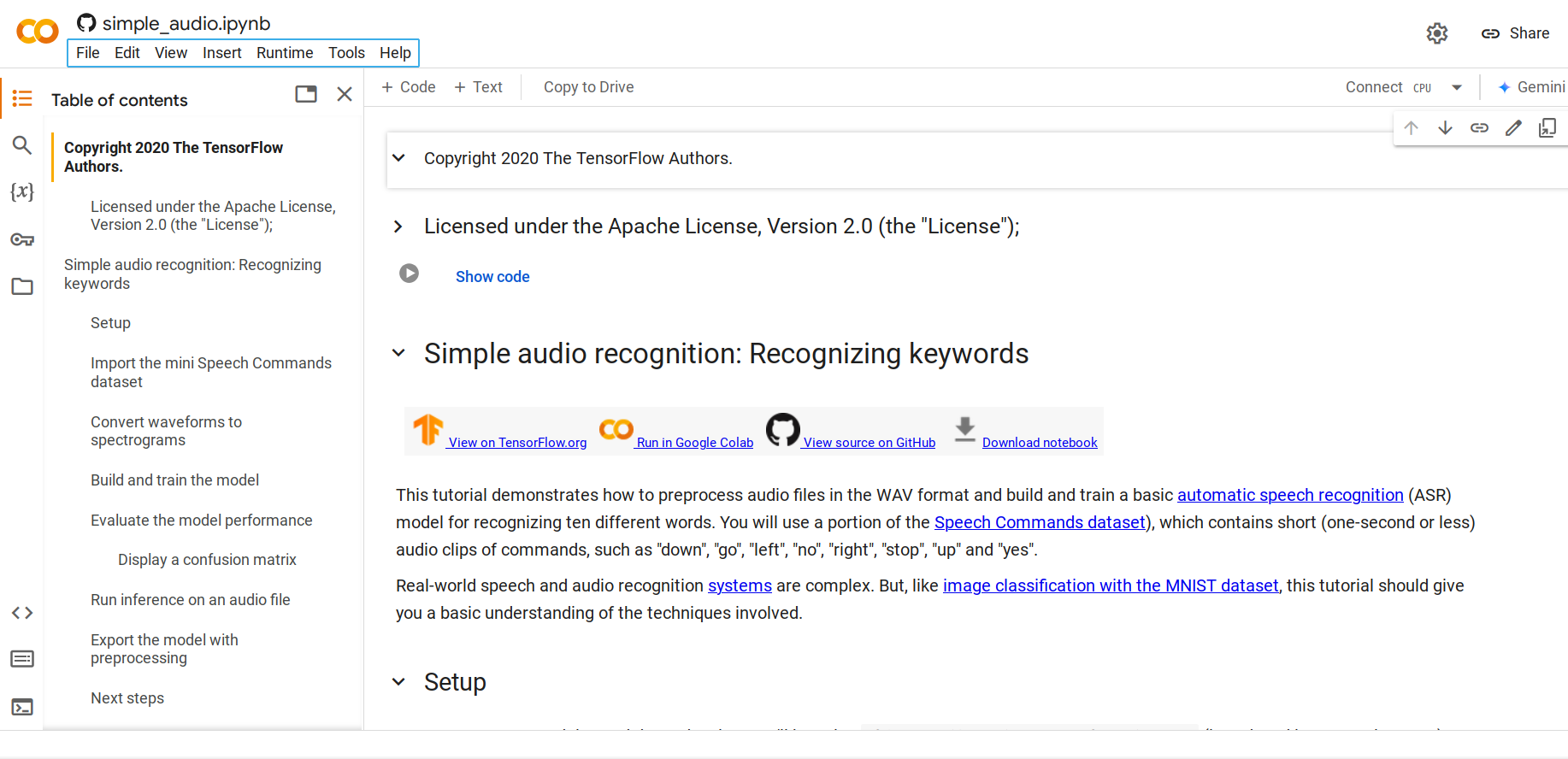
Por padrão, ele carregará o conjunto de dados mini Speech Commands, que é uma versão menor do conjunto de dados Speech Commands. O conjunto de dados original consiste em mais de 105.000 arquivos de áudio no formato de arquivo de áudio WAV (Waveform) de pessoas dizendo 35 palavras diferentes. Esses dados foram coletados pelo Google e lançados sob uma licença CC BY.
-
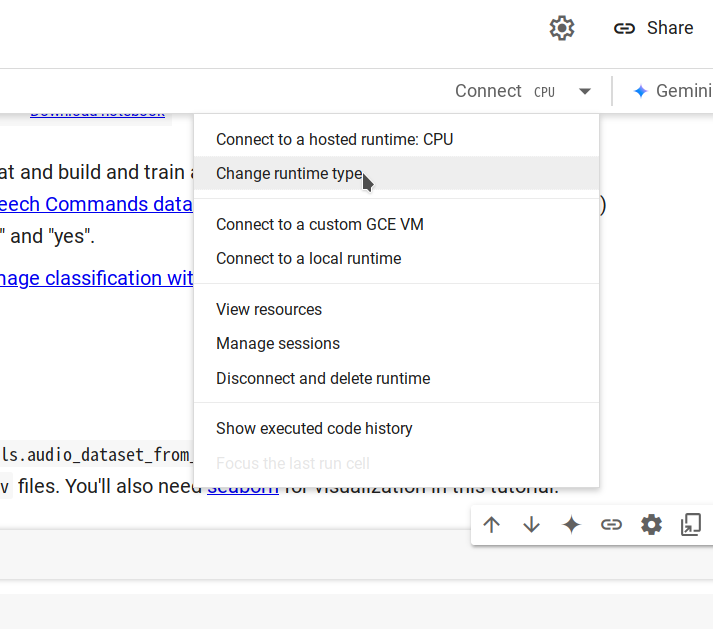
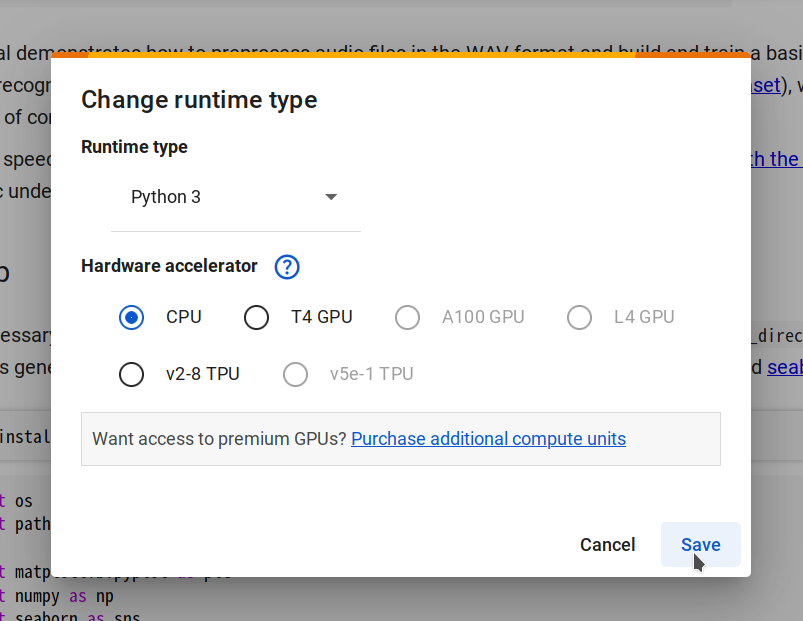
Etapa 2. Conecte-se a um novo runtime selecionando Changing runtime type -> CPU -> Save, depois clique em Connect.
-
Etapa 3. Navegue até
Runtime > Run allpara executar todas as células de código. Este processo levará cerca de 10 minutos para ser concluído.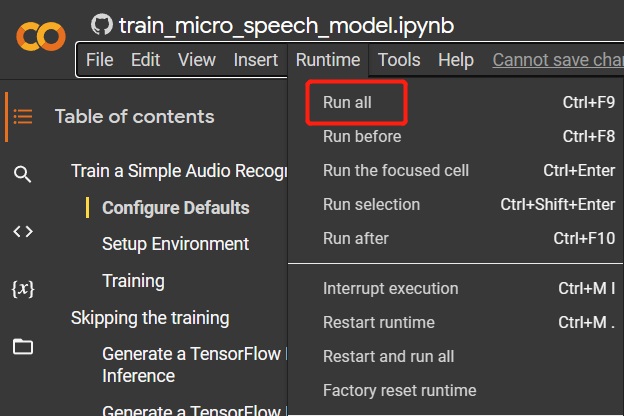
-
Etapa 4. Depois que todas as células de código forem executadas, anexe uma nova célula e execute o seguinte código para gerar o arquivo de modelo
.tflite.converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
with open('model.tflite', 'wb') as f:
f.write(tflite_model)
-
Etapa 5. Clique com o botão direito no arquivo
model.tflitegerado e selecione Download para salvar o arquivo em seu computador.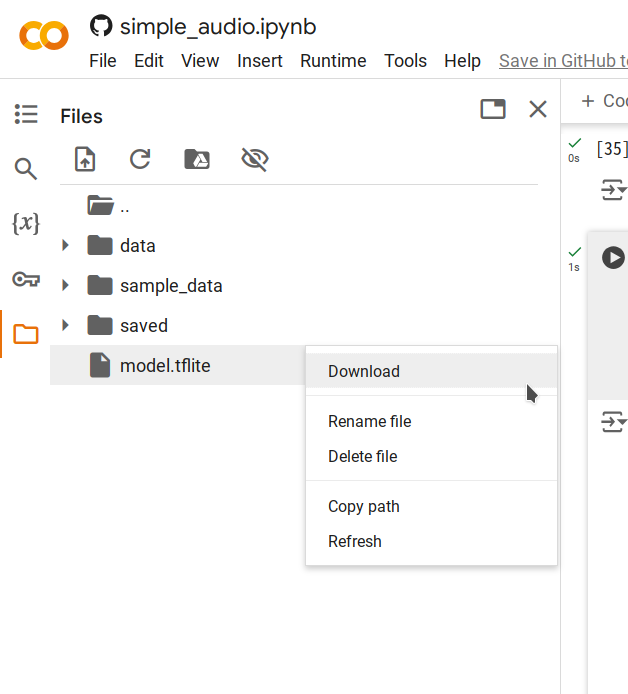
Inferência Local
Executando o Script de Inferência
O script inference.py executa as seguintes etapas:
- Carrega o modelo TensorFlow Lite treinado.
- Processa o áudio de entrada em um espectrograma adequado para inferência.
- Executa a inferência e gera a palavra-chave detectada juntamente com as pontuações de confiança para cada rótulo.
Etapas para Execução
-
Envie o arquivo de modelo
model.tflitepara o seu Pi; neste exemplo, nós o colocamos em~/speech_recognition/model.tflite. -
Salve o seguinte script como
~/speech_recognition/inference.py:import numpy as np
from scipy import signal
from tflite_runtime.interpreter import Interpreter
import soundfile as sf
MODEL_PATH = 'model.tflite'
LABELS = ['no', 'yes', 'down', 'go', 'left', 'up', 'right', 'stop']
def get_spectrogram(waveform, expected_time_steps=124, expected_freq_bins=129):
_, _, Zxx = signal.stft(
waveform,
fs=16000,
nperseg=255,
noverlap=124,
nfft=256
)
spectrogram = np.abs(Zxx)
if spectrogram.shape[0] != expected_freq_bins:
spectrogram = np.pad(spectrogram, ((
0, expected_freq_bins - spectrogram.shape[0]), (0, 0)), mode='constant')
if spectrogram.shape[1] != expected_time_steps:
spectrogram = np.pad(spectrogram, ((
0, 0), (0, expected_time_steps - spectrogram.shape[1])), mode='constant')
if spectrogram.shape != (expected_freq_bins, expected_time_steps):
raise ValueError(
f"Invalid spectrogram shape. Got {spectrogram.shape}, expected ({expected_freq_bins}, {expected_time_steps})."
)
spectrogram = np.transpose(spectrogram)
return spectrogram
def preprocess_audio(file_path):
waveform, sample_rate = sf.read(file_path)
if sample_rate != 16000:
raise ValueError("Expected sample rate is 16 kHz")
if len(waveform.shape) > 1:
waveform = waveform[:, 0]
spectrogram = get_spectrogram(waveform)
spectrogram = spectrogram[..., np.newaxis]
spectrogram = spectrogram[np.newaxis, ...]
return spectrogram
def run_inference(file_path):
spectrogram = preprocess_audio(file_path)
interpreter = Interpreter(MODEL_PATH)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
input_shape = input_details[0]['shape']
if spectrogram.shape != tuple(input_shape):
raise ValueError(
f"Expected input shape {input_shape}, got {spectrogram.shape}"
)
interpreter.set_tensor(
input_details[0]['index'], spectrogram.astype(np.float32))
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])[0]
prediction = np.argmax(output_data)
confidence = np.exp(output_data) / \
np.sum(np.exp(output_data))
print(f"command: {LABELS[prediction].upper()}")
for label, conf in zip(LABELS, confidence):
print(f"{label}: {conf:.2%}")
if __name__ == "__main__":
audio_file_path = 'test_audio.wav'
run_inference(audio_file_path) -
Grave um som usando o seguinte comando; as palavras-chave disponíveis são:
no,yes,down,go,left,up,right,stop.$ arecord -D "plughw:2,0" -f S16_LE -r 16000 -d 1 -t wav ~/speech_recognition/test_audio.wav -
Execute o script:
$ python3 inference.py
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
command: YES
no: 8.74%
yes: 21.10%
down: 5.85%
go: 14.57%
left: 11.02%
up: 8.25%
right: 10.53%
stop: 19.94%
Interpretando os Resultados
O script gera o comando detectado (por exemplo, YES) e as pontuações de confiança para todos os rótulos. Isso fornece insights sobre as previsões do modelo e permite avaliar seu desempenho.
Suporte Técnico & Discussão de Produtos
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.