reSpeaker USB 4-Mic Array XVF3000 v3.0

Temos o prazer de apresentar formalmente o reSpeaker XVF3800 — uma atualização completa do reSpeaker XVF 3000. Com base na arquitetura de matriz de 4 microfones de seu antecessor, compatibilidade universal (Windows / macOS / Linux) e conveniência plug-and-play com firmware duplo (I2S / USB), o XVF3800 oferece um salto significativo tanto em fidelidade de áudio quanto em desempenho algorítmico.
Principais destaques da atualização
- Algoritmos de áudio com IA: Conjunto integrado com AEC (Cancelamento de Eco Acústico), AGC (Controle Automático de Ganho), detecção de DoA (Direção de Chegada), formação de feixe (beamforming), VAD (Detecção de Atividade de Voz), supressão de ruído e desreverberação — fornecendo uma base robusta para aplicações avançadas de voz.
- Captação de voz em campo distante 360°: Captação de voz precisa em um raio de 5 metros, atendendo facilmente sistemas de conferência, interação inteligente e cenários controlados por voz.
- Modos duplos de operação: Alternância flexível de firmware USB/I2S para atender a diversos requisitos de desenvolvimento e implantação.
- Detalhes e especificações do produto: ReSpeaker XVF3800 4-Mic Array Store Page
- Guia de início rápido e Wiki: reSpeaker XVF3800 Getting Started Guide | Seeed Studio Wiki
O ReSpeaker Mic Array v3.0 é a próxima evolução das matrizes de microfone USB da Seeed Studio, sucedendo o ReSpeaker Mic Array v2.0. Enquanto o v2.0 foi construído sobre o chipset XVF-3000 da XMOS e projetado como uma grande atualização em relação ao v1.0, o v3.0 foca em aprimorar a qualidade de áudio e o desempenho dos algoritmos, mesmo com uma quantidade física menor de microfones.
Comparado à matriz de 4 microfones do v2.0, o v3.0 também usa 4 microfones, mas integra algoritmos de processamento de áudio internos aprimorados, oferecendo captação de voz em campo distante mais nítida e melhor tratamento de ruído que seu antecessor. O v3.0 substitui o codec WM8960 do v2.0 por um codec TLV320AIC3104, contribuindo para uma captura de som de maior fidelidade.
Enquanto o v2.0 era frequentemente combinado com o ReSpeaker Core ou usado como placa de desenvolvimento, o v3.0 é mais um dispositivo USB plug-and-play — semelhante ao v2.0 no suporte à USB Audio Class 1.0 para compatibilidade total com Windows, macOS e Linux — mas ajustado para oferecer desempenho de interface de voz pronto para uso, sem necessidade de hardware adicional.
Em termos de recursos, ambos suportam captação de voz em campo distante e algoritmos de aprimoramento de fala como AEC (Cancelamento de Eco Acústico), VAD (Detecção de Atividade de Voz), DOA (Direção de Chegada), formação de feixe (Beamforming) e Supressão de Ruído, mas as otimizações de algoritmo do v3.0 fornecem áudio mais limpo em ambientes ruidosos do mundo real.
O sistema de LED permanece com 12 LEDs RGB programáveis em ambas as versões, mas o v3.0 é modelado com base no design mais recente do USB 4 Mic Array, tornando-o menor e mais simples que o formato orientado a desenvolvedores do v2.0, enquanto ainda mantém recursos-chave de interface de voz profissional.

![]()
Versão
| Versão do Produto | Mudanças | Data de Lançamento |
|---|---|---|
| ReSpeaker Mic Array v1.0 | Inicial | 15 Ago, 2016 |
| ReSpeaker Mic Array v2.0 | XVSM-2000 está EOL, mudar o MCU para XVF-3000 e reduzir os microfones de 7 para 4. | 25 Jan, 2018 |
| ReSpeaker Mic Array v3.0 | Codec alterado para TLV320AIC3104 | 19 Jan, 2021 |
Recursos
- Captação de voz em campo distante
- Suporta USB Audio Class 1.0 (UAC 1.0)
- Matriz de quatro microfones
- 12 LEDs RGB programáveis como indicadores
- Algoritmos e recursos de fala
- Detecção de Atividade de Voz
- Direção de Chegada
- Beamforming
- Supressão de Ruído
- Desreverberação
- Cancelamento de Eco Acústico
Especificação
- XVF-3000 da XMOS
- 4 microfones digitais de alto desempenho
- Suporta captação de voz em campo distante
- Algoritmo de fala em chip
- 12 LEDs RGB programáveis como indicadores
- Microfones: ST MP34DT01TR-M
- Sensibilidade: -26 dBFS (Omnidirecional)
- Ponto de sobrecarga acústica: 120 dBSPL
- SNR: 61 dB
- Fonte de alimentação: 5V DC via Micro USB ou conector de expansão
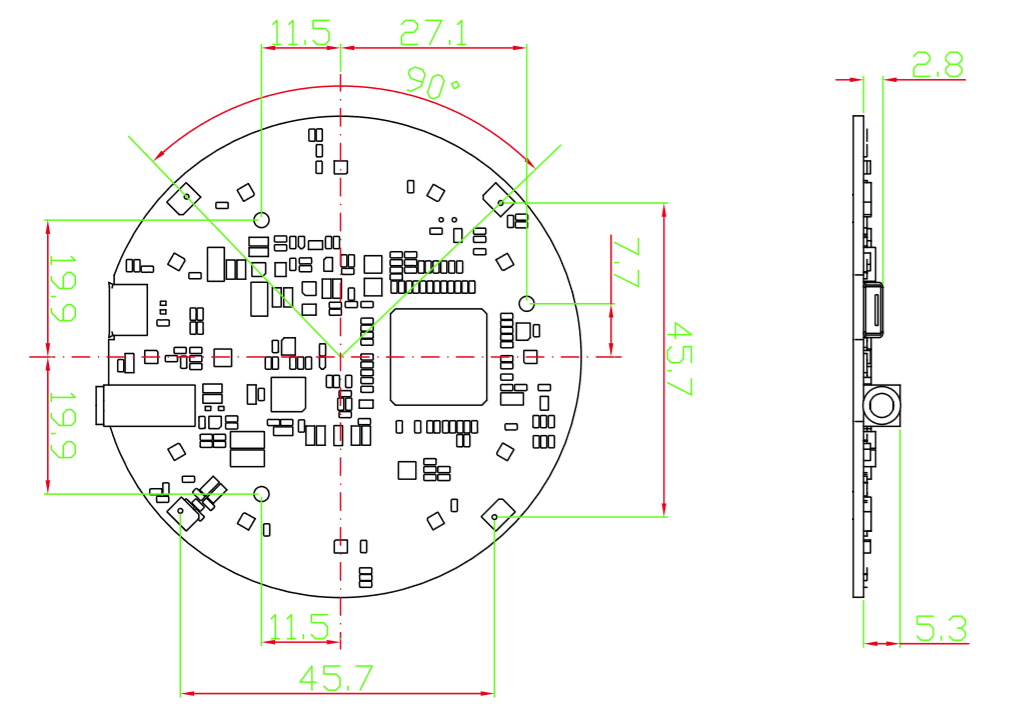
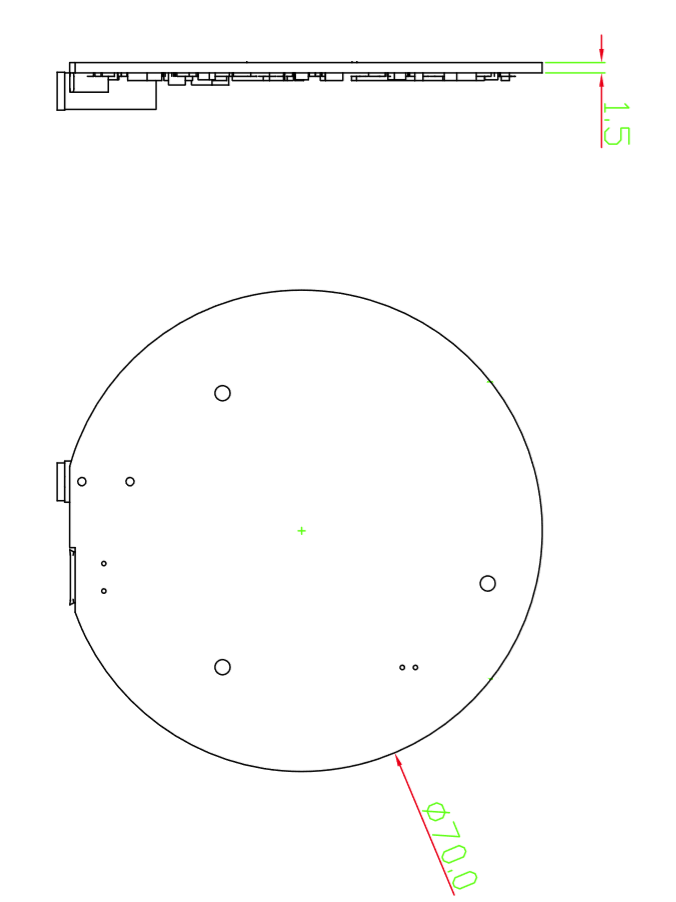
- Dimensões: 70 mm (diâmetro)
- Saída de conector de áudio P2 (3,5 mm)
- Consumo de energia: 5V, 180mA com LED ligado e 170mA com LED desligado
- Taxa máxima de amostragem: 16Khz
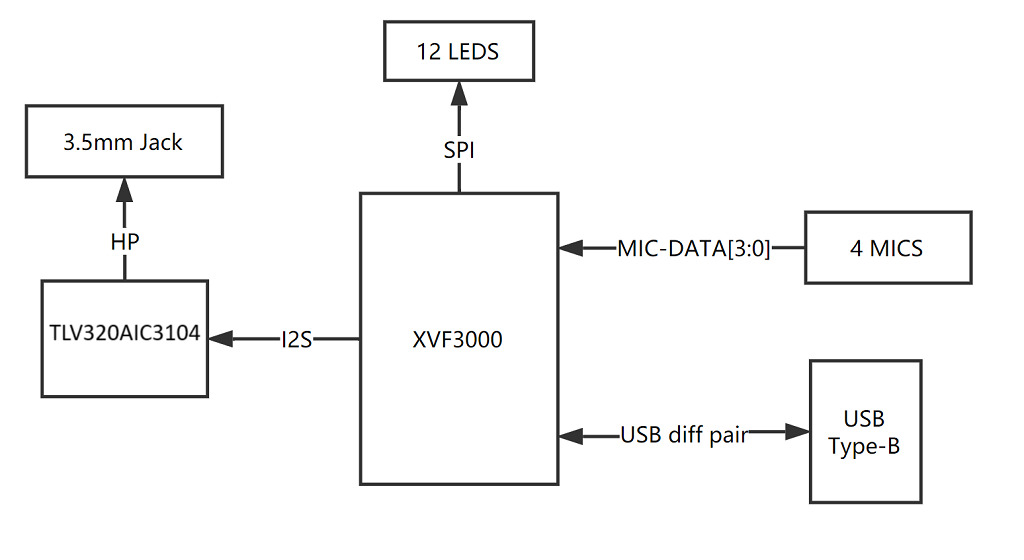
Visão geral do hardware

-
① XMOS XVF-3000: Integra algoritmos avançados de DSP que incluem Cancelamento de Eco Acústico (AEC), formação de feixe (beamforming), desreverberação, supressão de ruído e controle de ganho.
-
② Microfone Digital: O MP34DT01-M é um microfone digital MEMS omnidirecional, de ultra-compacto e baixo consumo, construído com um elemento de detecção capacitivo e uma interface IC.
-
③ LED RGB: LED RGB de três cores.
-
④ Porta USB: Fornece energia e controla a matriz de microfones.
-
⑤ Conector de fones de ouvido de 3,5 mm: Saída de áudio. Podemos conectar caixas de som ativas ou fones de ouvido nesta porta.
-
⑥ TLV320AIC3104: O TLV320AIC3104 é um codec estéreo de baixo consumo com drivers de alto-falante Classe D para fornecer 1 W por canal em cargas de 8 W.
Diagrama do sistema
Mapa de pinos

Dimensões
Aplicações
- Captura de voz via USB
- Smart Speaker
- Sistemas inteligentes de assistente de voz
- Gravadores de voz
- Sistema de conferência por voz
- Equipamentos de comunicação para reuniões
- Robô de interação por voz
- Assistente de voz automotivo
- Outros cenários de interface de voz
Primeiros Passos
O ReSpeaker Mic Array v3.0 é compatível com sistemas Windows, Mac, Linux e Android. Os scripts abaixo foram testados no Python2.7.
Para Android, testamos com o emteria.OS (Android 7.1) no Raspberry. Conectamos o mic array v3.0 à porta USB do Raspberry Pi e selecionamos o ReSpeaker mic array v3.0 como dispositivo de áudio. A seguir está a tela de gravação de áudio.

Esta é a tela de reprodução de áudio. Conectamos o alto-falante ao conector de áudio P2 (3,5 mm) do ReSpeaker mic array v3.0 e ouvimos o que gravamos.

Atualizar firmware
Existem 2 firmwares. Um inclui dados de 1 canal, enquanto o outro inclui dados de 6 canais (firmware de fábrica). Aqui está a tabela com as diferenças.
| Firmware | Channels | Nota |
|---|---|---|
| 1_channel_firmware.bin | 1 | Áudio processado para ASR |
| 6_channels_firmware.bin | 6 | Channel 0: processed audio for ASR Channel 1: mic1 raw data Channel 2: mic2 raw data Channel 3: mic3 raw data Channel 4: mic4 raw data Channel 5: merged playback |
Para Linux: O Mic array suporta USB DFU. Desenvolvemos um script em Python dfu.py para atualizar o firmware via USB.
sudo apt-get update
sudo pip install pyusb click
git clone https://github.com/respeaker/usb_4_mic_array.git
cd usb_4_mic_array
sudo python dfu.py --download MicArrayV3_firmware/6_channels_dfu_4.0.0_firmware.bin # The 6 channels version
# if you want to use 1 channel,then the command should be like:
sudo python dfu.py --download MicArrayV3_firmware/1_channel_dfu_4.0.0_firmware.bin
Para Windows/Mac: Não recomendamos usar Windows/Mac e máquina virtual Linux para atualizar o firmware.
Demo pronto para uso
Aqui está o exemplo de Cancelamento de Eco Acústico com o firmware de 6 canais.
- Passo 1. Conecte o cabo USB ao PC e o conector de áudio ao alto-falante.

- Passo 2. Selecione o mic array v3.0 como dispositivo de saída no PC.
- Passo 3. Inicie o Audacity para gravar.
- Passo 4. Primeiro toque música no PC e depois fale.
- Passo 5. Veremos a tela do Audacity como abaixo. Clique em Solo para ouvir o áudio de cada canal.

Áudio do Canal 0 (processado pelos algoritmos):
Canal1 Áudio(dados brutos do Mic1):
Canal5 Áudio(dados de reprodução):
Aqui está o vídeo sobre o DOA e o AEC.
Instalar o Driver de Controle de DFU e LED
- Windows: A gravação e reprodução de áudio funcionam bem por padrão. O driver Libusb-win32 só é necessário para controlar os LEDs e parâmetros de DSP no Windows. Usamos uma ferramenta prática - Zadig para instalar o driver libusb-win32 tanto para
SEEED DFUquanto paraSEEED Control(ReSpeaker Mic Array tem 2 dispositivos no Gerenciador de Dispositivos do Windows).

Certifique-se de que libusb-win32 esteja selecionado, não WinUSB ou libusbK.
- MAC: Nenhum driver é necessário.
- Linux: Nenhum driver é necessário.
Ajuste (Tuning)
Para Linux/Mac/Windows: Podemos configurar alguns parâmetros dos algoritmos integrados.
- Obtenha a lista completa de parâmetros, para mais informações, consulte o FAQ.
git clone https://github.com/respeaker/usb_4_mic_array.git
cd usb_4_mic_array
python tuning.py -p
- Exemplo#1, podemos desligar o Controle Automático de Ganho (AGC):
python tuning.py AGCONOFF 0
- Exemplo#2, podemos verificar o ângulo de DOA.
pi@raspberrypi:~/usb_4_mic_array $ sudo python tuning.py DOAANGLE
DOAANGLE: 180
Controlar os LEDs
Podemos controlar os LEDs do ReSpeaker Mic Array V2 através de USB. O dispositivo USB possui uma Interface de Classe Específica do Fabricante que pode ser usada para enviar dados por meio de USB Control Transfer. Nós usamos a biblioteca python pyusb e criamos a biblioteca python usb_pixel_ring.
O comando de controle de LED é enviado pelo usb.core.Device.ctrl_transfer() do pyusb, com os parâmetros conforme abaixo:
ctrl_transfer(usb.util.CTRL_OUT | usb.util.CTRL_TYPE_VENDOR | usb.util.CTRL_RECIPIENT_DEVICE, 0, command, 0x1C, data, TIMEOUT)
Aqui estão as APIs do usb_pixel_ring.
| Comando | Dados | API | Nota |
|---|---|---|---|
| 0 | [0] | pixel_ring.trace() | modo trace, mudança dos LEDs depende de VADe DOA |
| 1 | [red, green, blue, 0] | pixel_ring.mono() | modo mono, define todos os LEDs RGB para uma única cor, por exemplo Red(0xFF0000), Green(0x00FF00), Blue(0x0000FF) |
| 2 | [0] | pixel_ring.listen() | modo listen, semelhante ao modo trace, mas não desliga os LEDs |
| 3 | [0] | pixel_ring.speak() | modo de espera |
| 4 | [0] | pixel_ring.think() | modo speak |
| 5 | [0] | pixel_ring.spin() | modo spin |
| 6 | [r, g, b, 0] * 12 | pixel_ring.custimize() | modo custom, define cada LED para sua própria cor |
| 0x20 | [brightness] | pixel_ring.set_brightness() | define o brilho, faixa: 0x00~0x1F |
| 0x21 | [r1, g1, b1, 0, r2, g2, b2, 0] | pixel_ring.set_color_palette() | define a paleta de cores, por exemplo, pixel_ring.set_color_palette(0xff0000, 0x00ff00) junto com pixel_ring.think() |
| 0x22 | [vad_led] | pixel_ring.set_vad_led() | define o LED central: 0 - desligado, 1 - ligado, outro - depende do VAD |
| 0x23 | [volume] | pixel_ring.set_volume() | mostra o volume, faixa: 0 ~ 12 |
| 0x24 | [pattern] | pixel_ring.change_pattern() | define o padrão, 0 - padrão Google Home, outros - padrão Echo |
Para Linux: Aqui está o exemplo para controlar os LEDs. Por favor siga os comandos abaixo para executar a demonstração.
git clone https://github.com/respeaker/pixel_ring.git
cd pixel_ring
sudo python setup.py install
sudo python examples/usb_mic_array.py
Aqui está o código do usb_mic_array.py.
import time
from pixel_ring import pixel_ring
if __name__ == '__main__':
pixel_ring.change_pattern('echo')
while True:
try:
pixel_ring.wakeup()
time.sleep(3)
pixel_ring.think()
time.sleep(3)
pixel_ring.speak()
time.sleep(6)
pixel_ring.off()
time.sleep(3)
except KeyboardInterrupt:
break
pixel_ring.off()
time.sleep(1)
Para Windows/Mac: Aqui está o exemplo para controlar os LEDs.
- Passo 1. Baixe o pixel_ring.
git clone https://github.com/respeaker/pixel_ring.git
cd pixel_ring/pixel_ring
- Passo 2. Crie um led_control.py com o código abaixo e execute 'python led_control.py'
from usb_pixel_ring_v2 import PixelRing
import usb.core
import usb.util
import time
dev = usb.core.find(idVendor=0x2886, idProduct=0x0018)
print dev
if dev:
pixel_ring = PixelRing(dev)
while True:
try:
pixel_ring.wakeup(180)
time.sleep(3)
pixel_ring.listen()
time.sleep(3)
pixel_ring.think()
time.sleep(3)
pixel_ring.set_volume(8)
time.sleep(3)
pixel_ring.off()
time.sleep(3)
except KeyboardInterrupt:
break
pixel_ring.off()
Se você vir "None" impresso na tela, reinstale o driver libusb-win32.
DOA (Direction of Arrival)
Para Windows/Mac/Linux: Aqui está o exemplo para visualizar o DOA. O LED Verde é o indicador da direção da voz. Para o ângulo, consulte a visão geral de hardware.
- Passo 1. Baixe o usb_4_mic_array.
git clone https://github.com/respeaker/usb_4_mic_array.git
cd usb_4_mic_array
- Passo 2. Crie um DOA.py com o código abaixo dentro da pasta usb_4_mic_array e execute 'python DOA.py'
from tuning import Tuning
import usb.core
import usb.util
import time
dev = usb.core.find(idVendor=0x2886, idProduct=0x0018)
if dev:
Mic_tuning = Tuning(dev)
print Mic_tuning.direction
while True:
try:
print Mic_tuning.direction
time.sleep(1)
except KeyboardInterrupt:
break
- Passo 3. Veremos o DOA conforme abaixo.
pi@raspberrypi:~/usb_4_mic_array $ sudo python doa.py
184
183
175
105
104
104
103
VAD (Voice Activity Detection)
Para Windows/Mac/Linux: Aqui está o exemplo para visualizar o VAD. O LED Vermelho é o indicador do VAD.
- Passo 1. Baixe o usb_4_mic_array.
git clone https://github.com/respeaker/usb_4_mic_array.git
cd usb_4_mic_array
- Passo 2. Crie um VAD.py com o código abaixo dentro da pasta usb_4_mic_array e execute 'python VAD.py'
from tuning import Tuning
import usb.core
import usb.util
import time
dev = usb.core.find(idVendor=0x2886, idProduct=0x0018)
#print dev
if dev:
Mic_tuning = Tuning(dev)
print Mic_tuning.is_voice()
while True:
try:
print Mic_tuning.is_voice()
time.sleep(1)
except KeyboardInterrupt:
break
- Passo 3. Veremos o DOA conforme abaixo.
pi@raspberrypi:~/usb_4_mic_array $ sudo python VAD.py
0
0
0
1
0
1
0
Para o limiar do VAD, também podemos usar o GAMMAVAD_SR para defini-lo. Consulte Tuning para mais detalhes.
Extrair Voz
Usamos a biblioteca python PyAudio para extrair voz através de USB.
Para Linux: Podemos usar os comandos abaixo para gravar ou reproduzir a voz.
arecord -D plughw:1,0 -f cd test.wav # record, please use the arecord -l to check the card and hardware first
aplay -D plughw:1,0 -f cd test.wav # play, please use the aplay -l to check the card and hardware first
arecord -D plughw:1,0 -f cd |aplay -D plughw:1,0 -f cd # record and play at the same time
Também podemos usar script em Python para extrair a voz.
- Passo 1, precisamos executar o seguinte script para obter o número de índice do dispositivo do Mic Array:
sudo pip install pyaudio
cd ~
nano get_index.py
- Passo 2, copie o código abaixo e cole em get_index.py.
Se você estiver usando Python 3, este arquivo é adequado para uso get_index.py
import pyaudio
p = pyaudio.PyAudio()
info = p.get_host_api_info_by_index(0)
numdevices = info.get('deviceCount')
for i in range(0, numdevices):
if (p.get_device_info_by_host_api_device_index(0, i).get('maxInputChannels')) > 0:
print "Input Device id ", i, " - ", p.get_device_info_by_host_api_device_index(0, i).get('name')
-
Passo 3, pressione
Ctrl+Xpara sair e pressione Y para salvar. -
Passo 4, execute 'sudo python get_index.py' e veremos o ID do dispositivo como abaixo.
Input Device id 2 - ReSpeaker 4 Mic Array (UAC1.0): USB Audio (hw:1,0)
- Passo 5, altere
RESPEAKER_INDEX = 2para o número de índice. Execute o script Python record.py para gravar um discurso.
import pyaudio
import wave
RESPEAKER_RATE = 16000
RESPEAKER_CHANNELS = 6 # change base on firmwares, 1_channel_firmware.bin as 1 or 6_channels_firmware.bin as 6
RESPEAKER_WIDTH = 2
# run getDeviceInfo.py to get index
RESPEAKER_INDEX = 2 # refer to input device id
CHUNK = 1024
RECORD_SECONDS = 5
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(
rate=RESPEAKER_RATE,
format=p.get_format_from_width(RESPEAKER_WIDTH),
channels=RESPEAKER_CHANNELS,
input=True,
input_device_index=RESPEAKER_INDEX,)
print("* recording")
frames = []
for i in range(0, int(RESPEAKER_RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(RESPEAKER_CHANNELS)
wf.setsampwidth(p.get_sample_size(p.get_format_from_width(RESPEAKER_WIDTH)))
wf.setframerate(RESPEAKER_RATE)
wf.writeframes(b''.join(frames))
wf.close()
- Passo 6. Se você quiser extrair dados do canal 0 de 6 canais, siga o código abaixo. Para outro canal X, altere [0::6] para [X::6].
import pyaudio
import wave
import numpy as np
RESPEAKER_RATE = 16000
RESPEAKER_CHANNELS = 6 # change base on firmwares, 1_channel_firmware.bin as 1 or 6_channels_firmware.bin as 6
RESPEAKER_WIDTH = 2
# run getDeviceInfo.py to get index
RESPEAKER_INDEX = 3 # refer to input device id
CHUNK = 1024
RECORD_SECONDS = 3
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(
rate=RESPEAKER_RATE,
format=p.get_format_from_width(RESPEAKER_WIDTH),
channels=RESPEAKER_CHANNELS,
input=True,
input_device_index=RESPEAKER_INDEX,)
print("* recording")
frames = []
for i in range(0, int(RESPEAKER_RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
# extract channel 0 data from 6 channels, if you want to extract channel 1, please change to [1::6]
a = np.fromstring(data,dtype=np.int16)[0::6]
frames.append(a.tostring())
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(1)
wf.setsampwidth(p.get_sample_size(p.get_format_from_width(RESPEAKER_WIDTH)))
wf.setframerate(RESPEAKER_RATE)
wf.writeframes(b''.join(frames))
wf.close()
Para Windows:
- Passo 1. Executamos o comando abaixo para instalar pyaudio.
pip install pyaudio
- Passo 2. Use get_index.py para obter o índice do dispositivo.
C:\Users\XXX\Desktop>python get_index.py
Input Device id 0 - Microsoft Sound Mapper - Input
Input Device id 1 - ReSpeaker 4 Mic Array (UAC1.0)
Input Device id 2 - Internal Microphone (Conexant I)
- Passo 3. Modifique o índice do dispositivo e os canais de record.py e então extraia a voz.
C:\Users\XXX\Desktop>python record.py
* recording
* done recording
Se virmos "Error: %1 is not a valid Win32 application.", instale a versão Win32 do Python.
Para MAC:
- Passo 1. Executamos o comando abaixo para instalar pyaudio.
pip install pyaudio
- Passo 2. Use get_index.py para obter o índice do dispositivo.
MacBook-Air:Desktop XXX$ python get_index.py
Input Device id 0 - Built-in Microphone
Input Device id 2 - ReSpeaker 4 Mic Array (UAC1.0)
- Passo 3. Modifique o índice do dispositivo e os canais de record.py e então extraia a voz.
MacBook-Air:Desktop XXX$ python record.py
2018-03-24 14:53:02.400 Python[2360:16629] 14:53:02.399 WARNING: 140: This application, or a library it uses, is using the deprecated Carbon Component Manager for hosting Audio Units. Support for this will be removed in a future release. Also, this makes the host incompatible with version 3 audio units. Please transition to the API's in AudioComponent.h.
* recording
* done recording
FAQ
P1: Parâmetros dos algoritmos embutidos
pi@raspberrypi:~/usb_4_mic_array $ python tuning.py -p
name type max min r/w info
-------------------------------
AECFREEZEONOFF int 1 0 rw Adaptive Echo Canceler updates inhibit.
0 = Adaptation enabled
1 = Freeze adaptation, filter only
AECNORM float 16 0.25 rw Limit on norm of AEC filter coefficients
AECPATHCHANGE int 1 0 ro AEC Path Change Detection.
0 = false (no path change detected)
1 = true (path change detected)
AECSILENCELEVEL float 1 1e-09 rw Threshold for signal detection in AEC [-inf .. 0] dBov (Default: -80dBov = 10log10(1x10-8))
AECSILENCEMODE int 1 0 ro AEC far-end silence detection status.
0 = false (signal detected)
1 = true (silence detected)
AGCDESIREDLEVEL float 0.99 1e-08 rw Target power level of the output signal.
[−inf .. 0] dBov (default: −23dBov = 10log10(0.005))
AGCGAIN float 1000 1 rw Current AGC gain factor.
[0 .. 60] dB (default: 0.0dB = 20log10(1.0))
AGCMAXGAIN float 1000 1 rw Maximum AGC gain factor.
[0 .. 60] dB (default 30dB = 20log10(31.6))
AGCONOFF int 1 0 rw Automatic Gain Control.
0 = OFF
1 = ON
AGCTIME float 1 0.1 rw Ramps-up / down time-constant in seconds.
CNIONOFF int 1 0 rw Comfort Noise Insertion.
0 = OFF
1 = ON
DOAANGLE int 359 0 ro DOA angle. Current value. Orientation depends on build configuration.
ECHOONOFF int 1 0 rw Echo suppression.
0 = OFF
1 = ON
FREEZEONOFF int 1 0 rw Adaptive beamformer updates.
0 = Adaptation enabled
1 = Freeze adaptation, filter only
FSBPATHCHANGE int 1 0 ro FSB Path Change Detection.
0 = false (no path change detected)
1 = true (path change detected)
FSBUPDATED int 1 0 ro FSB Update Decision.
0 = false (FSB was not updated)
1 = true (FSB was updated)
GAMMAVAD_SR float 1000 0 rw Set the threshold for voice activity detection.
[−inf .. 60] dB (default: 3.5dB 20log10(1.5))
GAMMA_E float 3 0 rw Over-subtraction factor of echo (direct and early components). min .. max attenuation
GAMMA_ENL float 5 0 rw Over-subtraction factor of non-linear echo. min .. max attenuation
GAMMA_ETAIL float 3 0 rw Over-subtraction factor of echo (tail components). min .. max attenuation
GAMMA_NN float 3 0 rw Over-subtraction factor of non- stationary noise. min .. max attenuation
GAMMA_NN_SR float 3 0 rw Over-subtraction factor of non-stationary noise for ASR.
[0.0 .. 3.0] (default: 1.1)
GAMMA_NS float 3 0 rw Over-subtraction factor of stationary noise. min .. max attenuation
GAMMA_NS_SR float 3 0 rw Over-subtraction factor of stationary noise for ASR.
[0.0 .. 3.0] (default: 1.0)
HPFONOFF int 3 0 rw High-pass Filter on microphone signals.
0 = OFF
1 = ON - 70 Hz cut-off
2 = ON - 125 Hz cut-off
3 = ON - 180 Hz cut-off
MIN_NN float 1 0 rw Gain-floor for non-stationary noise suppression.
[−inf .. 0] dB (default: −10dB = 20log10(0.3))
MIN_NN_SR float 1 0 rw Gain-floor for non-stationary noise suppression for ASR.
[−inf .. 0] dB (default: −10dB = 20log10(0.3))
MIN_NS float 1 0 rw Gain-floor for stationary noise suppression.
[−inf .. 0] dB (default: −16dB = 20log10(0.15))
MIN_NS_SR float 1 0 rw Gain-floor for stationary noise suppression for ASR.
[−inf .. 0] dB (default: −16dB = 20log10(0.15))
NLAEC_MODE int 2 0 rw Non-Linear AEC training mode.
0 = OFF
1 = ON - phase 1
2 = ON - phase 2
NLATTENONOFF int 1 0 rw Non-Linear echo attenuation.
0 = OFF
1 = ON
NONSTATNOISEONOFF int 1 0 rw Non-stationary noise suppression.
0 = OFF
1 = ON
NONSTATNOISEONOFF_SR int 1 0 rw Non-stationary noise suppression for ASR.
0 = OFF
1 = ON
RT60 float 0.9 0.25 ro Current RT60 estimate in seconds
RT60ONOFF int 1 0 rw RT60 Estimation for AES. 0 = OFF 1 = ON
SPEECHDETECTED int 1 0 ro Speech detection status.
0 = false (no speech detected)
1 = true (speech detected)
STATNOISEONOFF int 1 0 rw Stationary noise suppression.
0 = OFF
1 = ON
STATNOISEONOFF_SR int 1 0 rw Stationary noise suppression for ASR.
0 = OFF
1 = ON
TRANSIENTONOFF int 1 0 rw Transient echo suppression.
0 = OFF
1 = ON
VOICEACTIVITY int 1 0 ro VAD voice activity status.
0 = false (no voice activity)
1 = true (voice activity)
Q2: ImportError: No module named usb.core
A2: Execute sudo pip install pyusb para instalar o pyusb.
pi@raspberrypi:~/usb_4_mic_array $ sudo python tuning.py DOAANGLE
Traceback (most recent call last):
File "tuning.py", line 5, in <module>
import usb.core
ImportError: No module named usb.core
pi@raspberrypi:~/usb_4_mic_array $ sudo pip install pyusb
Collecting pyusb
Downloading pyusb-1.0.2.tar.gz (54kB)
100% |████████████████████████████████| 61kB 101kB/s
Building wheels for collected packages: pyusb
Running setup.py bdist_wheel for pyusb ... done
Stored in directory: /root/.cache/pip/wheels/8b/7f/fe/baf08bc0dac02ba17f3c9120f5dd1cf74aec4c54463bc85cf9
Successfully built pyusb
Installing collected packages: pyusb
Successfully installed pyusb-1.0.2
pi@raspberrypi:~/usb_4_mic_array $ sudo python tuning.py DOAANGLE
DOAANGLE: 180
Q3: Você tem o exemplo para a aplicação Raspberry alexa?
A3: Sim, podemos conectar o mic array v3.0 à porta usb do Raspberry e seguir o Raspberry Pi Quick Start Guide with Script para fazer a interação por voz com a alexa.
Q4: Você tem o exemplo para o Mic array v3.0 com sistema ROS?
A4: Sim, agradecemos ao Yuki por compartilhar o pacote para integrar o ReSpeaker Mic Array v2 com ROS (Robot Operating System) Middleware.
Q5: Como habilitar a porta de áudio de 3,5 mm para receber o sinal assim como a porta usb?
A5: Baixe o novo firmware e grave o XMOS seguindo o guia How to update firmware.
Recursos
- [PDF] ReSpeaker MicArray v3.0 Esquemático
- [PDF] ReSpeaker MicArray v3.0 Resumo do Produto
- [PDF] ReSpeaker MicArray v3.0 Modelo 3D
- [SKP] ReSpeaker MicArray v3.0 Modelo 3D
- [STP] ReSpeaker MicArray v3.0 Modelo 3D
- [PDF] XVF3000 Resumo do Produto
- [PDF] XVF3000 Folha de Dados
- [Github] ReSpeaker Mic Array v2 com ROS (Robot Operating System) Middleware
Suporte Técnico & Discussão de Produto
Obrigado por escolher nossos produtos! Estamos aqui para lhe fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.