Reconhecimento de Fala com TinyML usando Edge Impulse
Visão Geral
Desbloqueie o controle sem uso das mãos com detecção de comandos de voz em tempo real usando um sistema de Keyword Spotting (KWS) alimentado por TinyML. Ao combinar o array de microfones de alto desempenho ReSpeaker XVF3800 com o eficiente XIAO ESP32S3 e a plataforma Edge Impulse, trazemos reconhecimento de voz para dispositivos compactos e de baixo consumo. Treine, faça o deploy e escute — seu dispositivo estará sempre pronto para o seu próximo comando!
Hardware Necessário

Coleta de dados
Instalação do Firmware USB para o ReSpeaker XVF3800 com XIAO ESP32S3
Para começar a coleta de dados de áudio, certifique-se de que o seu ReSpeaker esteja gravado com o firmware USB, permitindo que ele funcione como um microfone USB.
Configurar o Ambiente Python
Em seguida, você precisa criar um ambiente python no seu laptop ou PC para coletar os dados de voz. Aqui vamos criar o respeaker-env
python -m venv respeaker-env
source respeaker-env/bin/activate
Instalar as Bibliotecas Necessárias:
pip install sounddevice scipy numpy
Encontrar o ID do Dispositivo ReSpeaker
Para gravar a partir da entrada de microfone correta, precisamos identificar o índice de dispositivo do microfone ReSpeaker.
import sounddevice as sd
devices = sd.query_devices()
for i, device in enumerate(devices):
print(f"Device {i}: {device['name']} (input channels: {device['max_input_channels']})")
Procure o nome de dispositivo que corresponda ao ReSpeaker (frequentemente nomeado algo como ReSpeaker XVF3800 USB 4-Mic Array) e anote o número de índice (por exemplo, Device 2).
Gravar Amostras de Áudio
O script a seguir permitirá que você grave amostras de áudio rotuladas, organizadas por pessoa e comando/palavra-chave.
import os
import sounddevice as sd
from scipy.io.wavfile import write
# === Settings ===
SAMPLERATE = 16000
CHANNELS = 1 # Mono input
DURATION = 10 # seconds
DEVICE_INDEX = 2 # Replace with correct device index
def record_audio(filename, samplerate=SAMPLERATE, channels=CHANNELS, duration=DURATION, device=DEVICE_INDEX):
print(f"Recording '{filename}' for {duration} seconds...")
recording = sd.rec(int(duration * samplerate),
samplerate=samplerate,
channels=channels,
dtype='int32',
device=device)
sd.wait()
write(filename, samplerate, recording)
print(f"Saved: {filename}")
def get_next_filename(directory, label):
existing = [f for f in os.listdir(directory) if f.startswith(label) and f.endswith('.wav')]
index = len(existing) + 1
return os.path.join(directory, f"{label}.{index}.wav")
def collect_samples():
while True:
sample_name = input("Enter sample name (e.g., PersonA): ").strip()
if not sample_name:
print("Sample name cannot be empty.")
continue
sample_dir = os.path.join(os.getcwd(), sample_name)
os.makedirs(sample_dir, exist_ok=True)
print(f"Directory created: {sample_dir}")
while True:
label = input("Enter sound/voice to record (e.g., yes, no): ").strip()
if not label:
print("Label cannot be empty.")
continue
while True:
filename = get_next_filename(sample_dir, label)
record_audio(filename)
cont = input("Record another sample for this label? (yes/no): ").strip().lower()
if cont != 'yes':
break
next_label = input("Do you want to record a different label? (yes/no): ").strip().lower()
if next_label != 'yes':
break
next_sample = input("Do you want to create a new sample? (yes/no): ").strip().lower()
if next_sample != 'yes':
print("Audio collection completed.")
break
if __name__ == "__main__":
collect_samples()
Exemplo de Estrutura de Pastas
/PersonA
├── red.1.wav
├── red.2.wav
├── blue.1.wav
└── blue.2.wav
/PersonB
├── red.1.wav
└── green.1.wav
A pasta de cada pessoa contém arquivos .wav rotulados que serão posteriormente enviados para o Edge Impulse para o treinamento do modelo.
Enviando e Preparando Dados de Áudio no Edge Impulse
Depois de coletar amostras de áudio brutas usando o ReSpeaker XVF3800 e organizá-las por rótulo, o próximo passo é enviá-las e processá-las no Edge Impulse Studio para treinar seu modelo de Keyword Spotting.
Criar um Novo Projeto no Edge Impulse
-
Acesse o Edge Impulse e faça login (ou crie uma conta se for novo).
-
Clique em "Create new project".
-
Forneça um nome para o seu projeto (por exemplo, "Voice Command KWS")
Enviar Amostras de Áudio Existentes
Para enviar os dados coletados:
-
- Navegue até a aba Data Acquisition.
-
- Clique em "Upload existing data" (canto superior direito).
-
- Selecione e envie a pasta que contém seus arquivos .wav
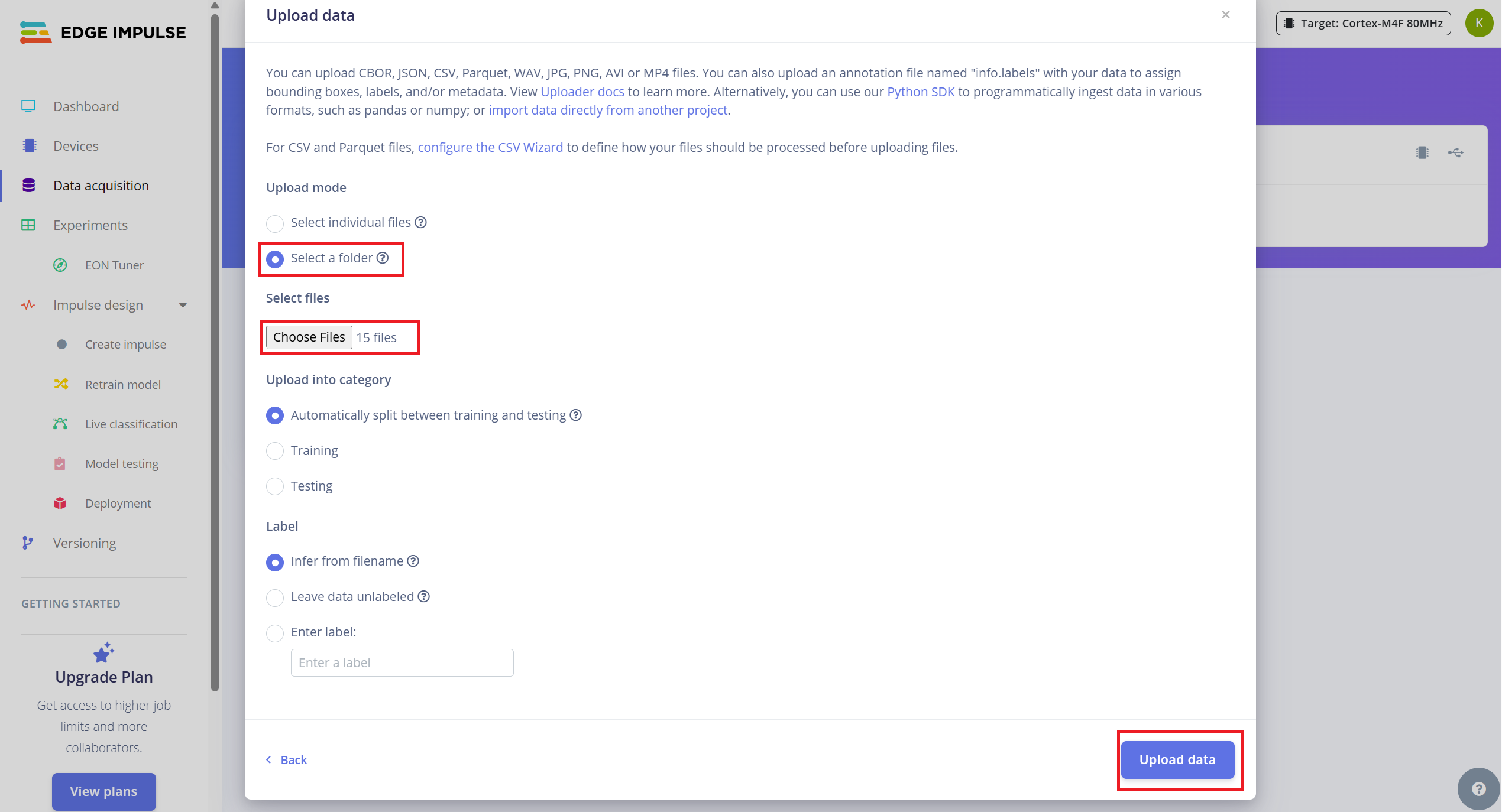
-
- Ative a opção para dividir automaticamente os dados em treinamento e teste (o Edge Impulse recomenda uma divisão de aproximadamente 80/20).
Dividir Áudio de 10 Segundos em Amostras de 1 Segundo
O Edge Impulse funciona melhor com clipes de áudio de 1 segundo para Keyword Spotting. Como as amostras originais foram gravadas em segmentos de 10 segundos, você precisará dividir cada uma em múltiplas amostras de 1 segundo.
Siga estes passos:
-
- Após o envio, vá para a página Data Acquisition.
-
- Encontre uma amostra (por exemplo, yes.1.wav) e clique nos três pontos (…) ao lado da amostra.
-
- Selecione "Split sample" no menu.
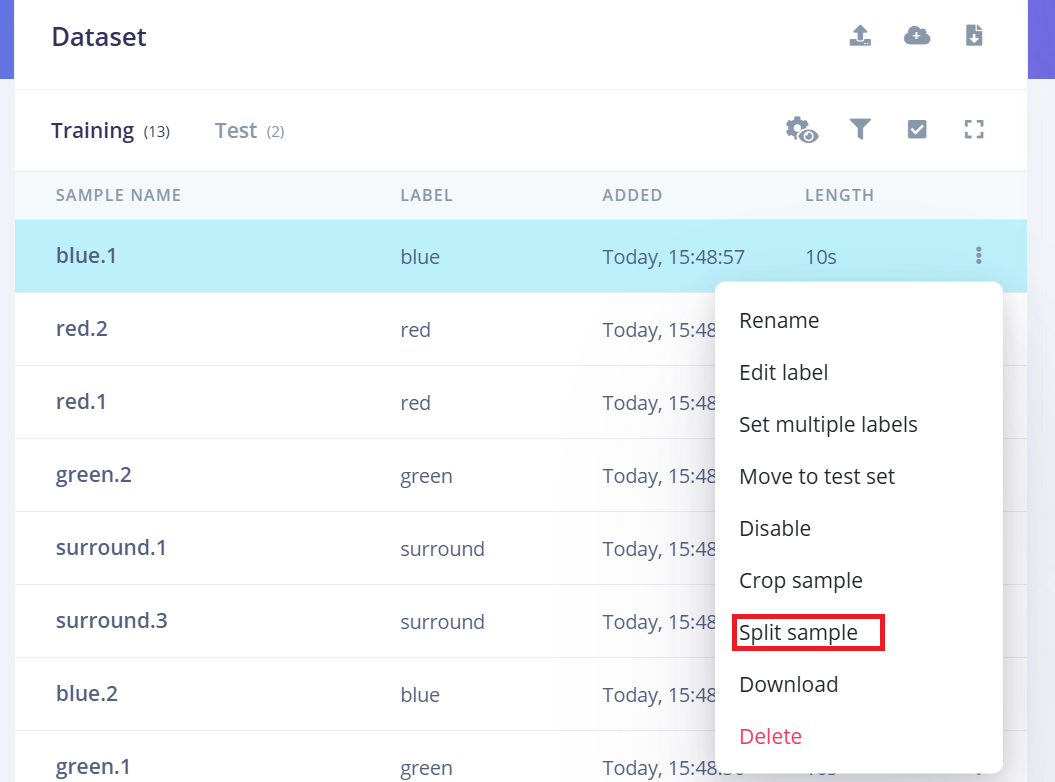
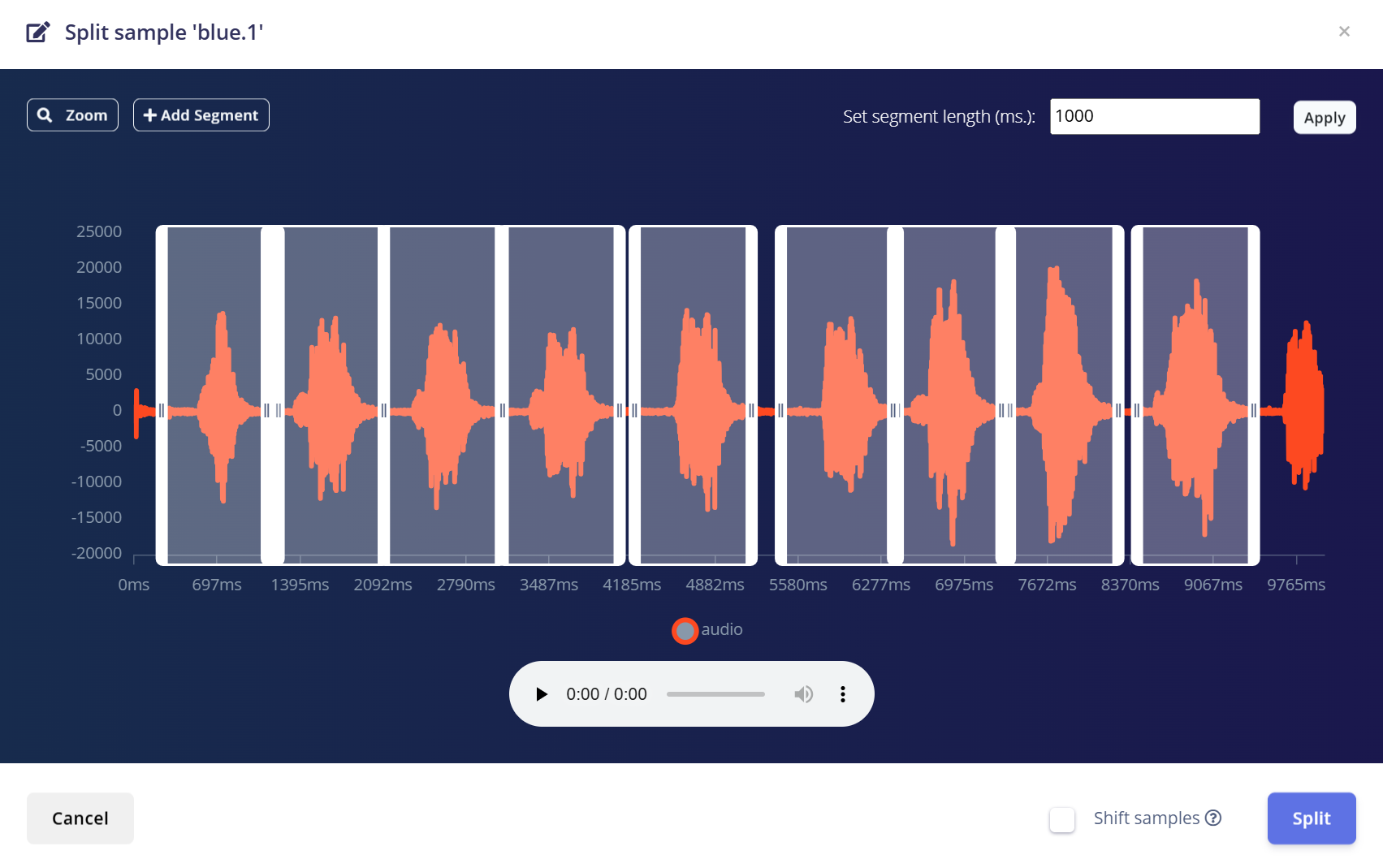
-
- Use a ferramenta para dividir a forma de onda em segmentos de 1 segundo.
- a. Você pode arrastar para ajustar os segmentos ou adicioná-los/removê-los conforme necessário.
-
- Clique em Save and Split.
Repita esse processo para cada amostra de 10 segundos em todas as classes, tanto de treinamento quanto de teste.
Isso garante que seu conjunto de dados esteja devidamente formatado e otimizado para treinar um modelo de alta precisão.
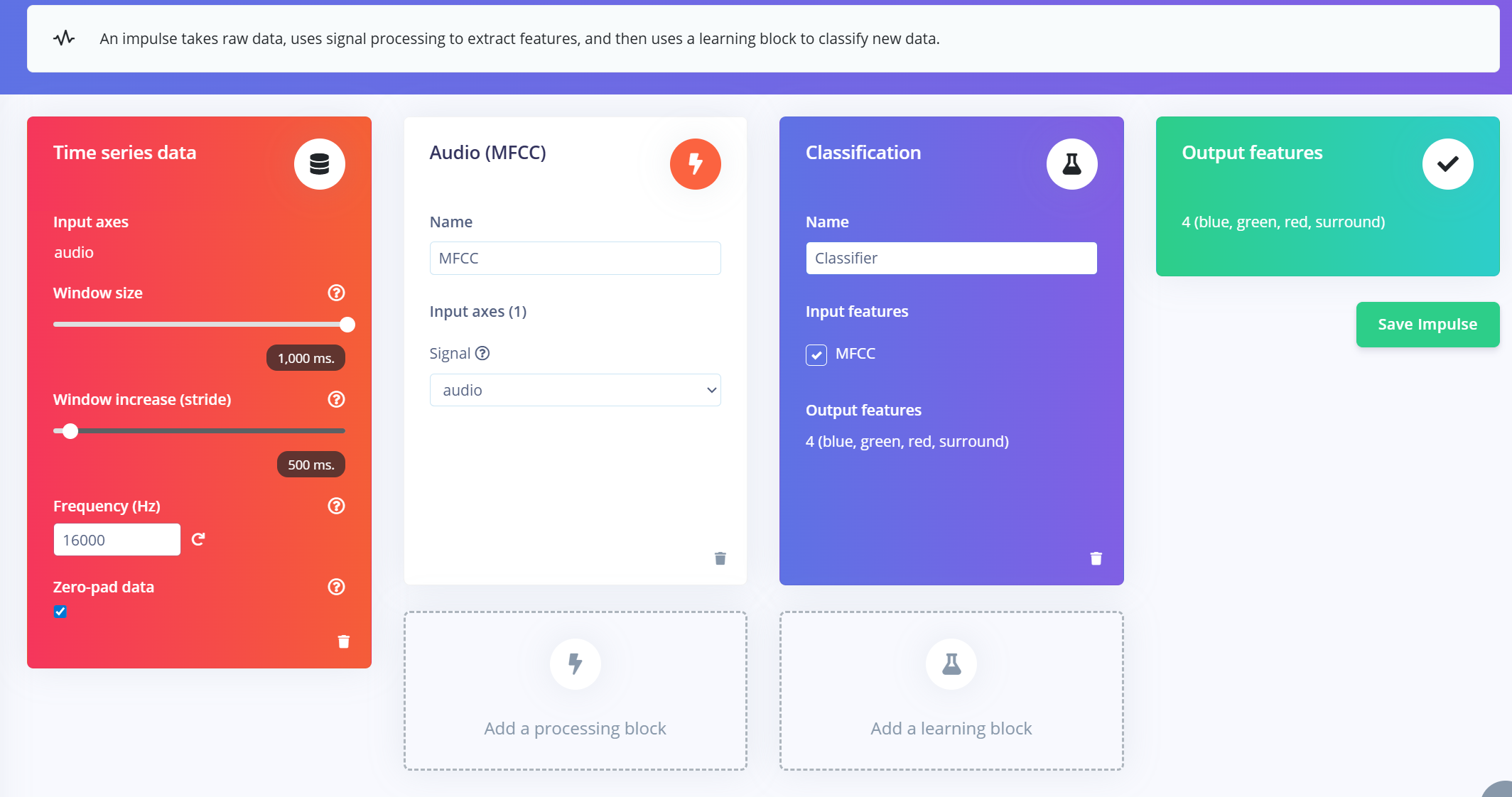
Criando o Impulse (Pré-processamento / Definição do modelo)
Um impulse no Edge Impulse define o pipeline de ponta a ponta que transforma dados brutos em um modelo de machine learning treinado. Ele inclui processamento de sinal, extração de características e um bloco de aprendizado para classificação.
Criar o Impulse
-
- Navegue até a aba "Impulse Design" no seu projeto Edge Impulse.
-
- Clique em “Create Impulse”.
-
- Configure a janela de entrada:
- a. Window size: 1000 ms (1 segundo)
- b. Window increase: 500 ms (janelas sobrepostas para aumentar os dados)
- c. Enable "Zero-pad data": Isso garante que segmentos mais curtos (por exemplo, 800 ms) sejam preenchidos com zeros, especialmente útil quando a remoção de ruído é aplicada durante a divisão das amostras.
Adicionar o Extrator de Características MFCC
Após criar a janela do impulse:
-
- Clique em “Add a processing block” e selecione MFCC (Mel Frequency Cepstral Coefficients).
- a. MFCC é um método amplamente utilizado para converter sinais de áudio em características 2D que representam padrões de frequência da voz.
- b. Essas características são perfeitas para modelos de reconhecimento baseados em voz.
-
- Defina os parâmetros do MFCC (os padrões funcionam bem na maioria dos casos):
- a. Formato de saída: 13 x 49 x 1
- b. Isso transforma seu clipe de áudio em uma “imagem” para classificação.
Adicionar um Bloco de Aprendizado
-
- Clique em “Add a learning block” e escolha “Classification (Keras)”.
-
- Isso cria uma Rede Neural Convolucional (CNN) personalizada que realizará classificação de imagens nas características MFCC.
-
- Agora você pode ir até a aba NN Classifier para personalizar e treinar o seu modelo.
Pré-processamento (MFCC)
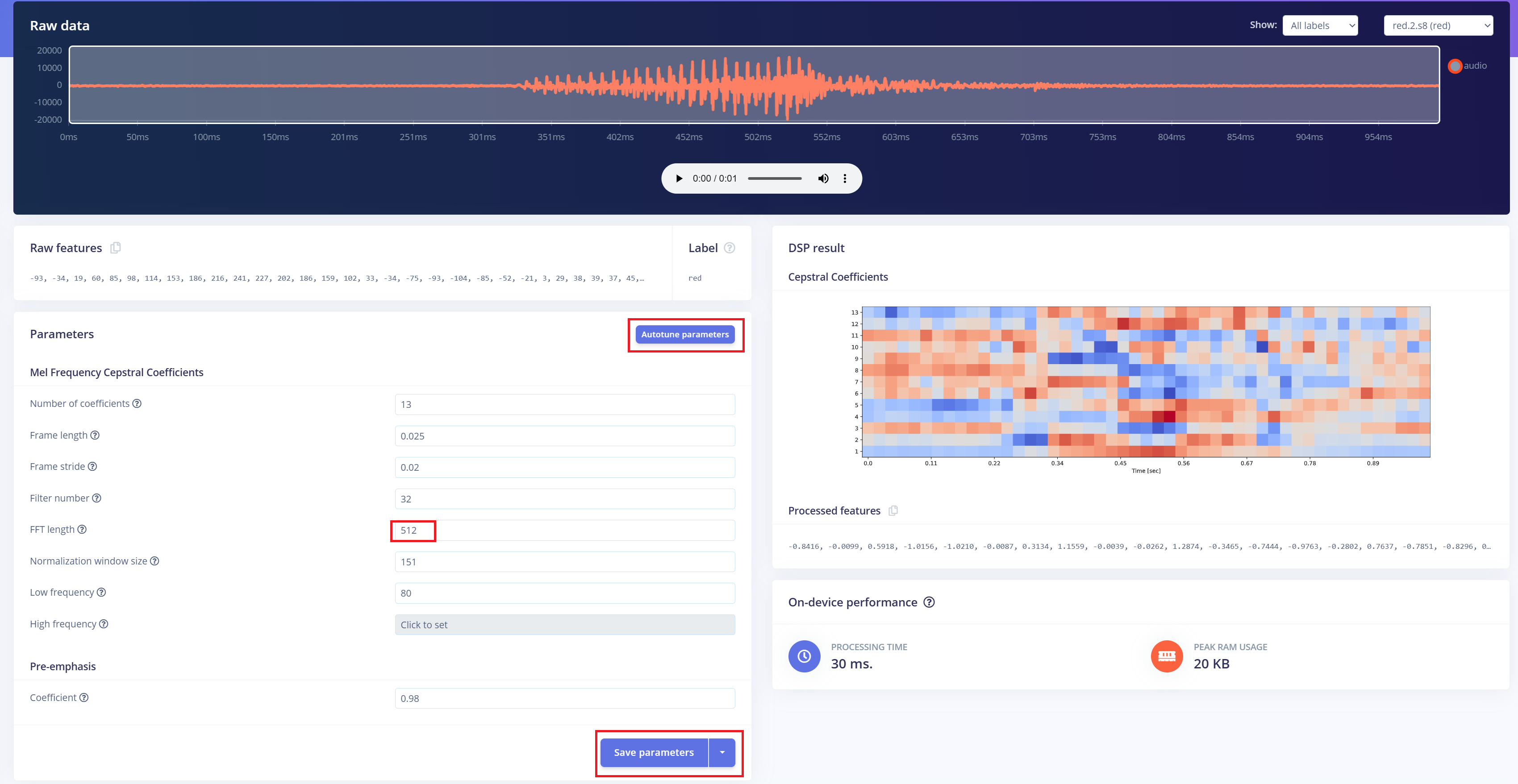
O próximo passo é gerar imagens de espectrograma a partir do áudio gravado, que serão usadas para o treinamento do modelo. Podemos usar os parâmetros padrão de DSP ou, como no nosso caso, utilizar o recurso DSP Autotune para otimizá-los automaticamente para um melhor desempenho.
Construindo um modelo de machine learning
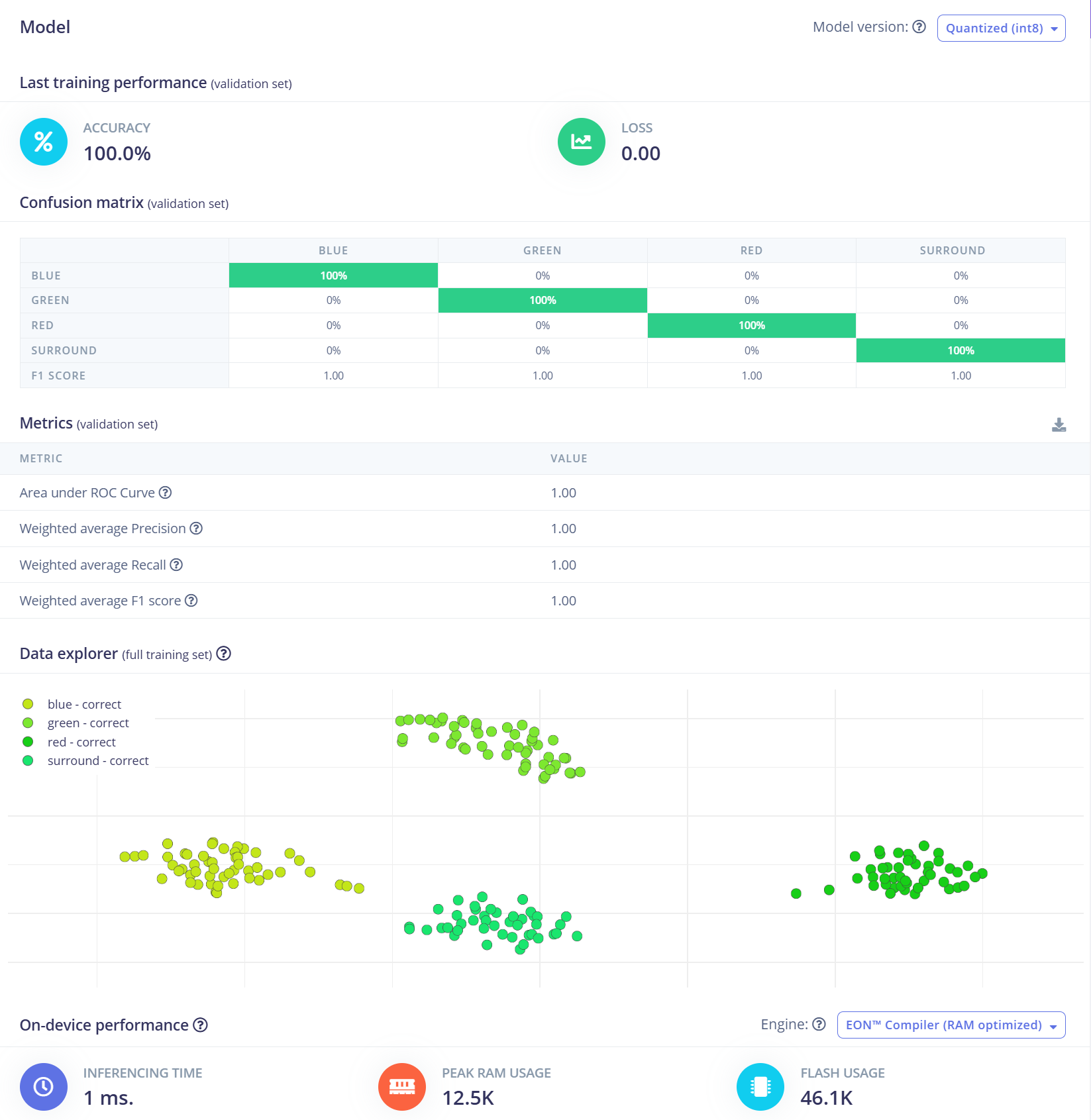
Para este projeto, usaremos um modelo de Rede Neural Convolucional (CNN). A arquitetura consiste em duas camadas Conv1D + MaxPooling com 8 e 16 filtros respectivamente, seguidas por uma camada Dropout de 0,25. Após o flattening, a camada densa final inclui quatro neurônios — um para cada classe. Treinaremos o modelo usando uma taxa de aprendizado de 0,005 ao longo de 100 épocas. Para melhorar a capacidade de generalização e robustez, serão aplicadas técnicas de aumento de dados, como ruído de fundo. Os resultados iniciais são promissores.
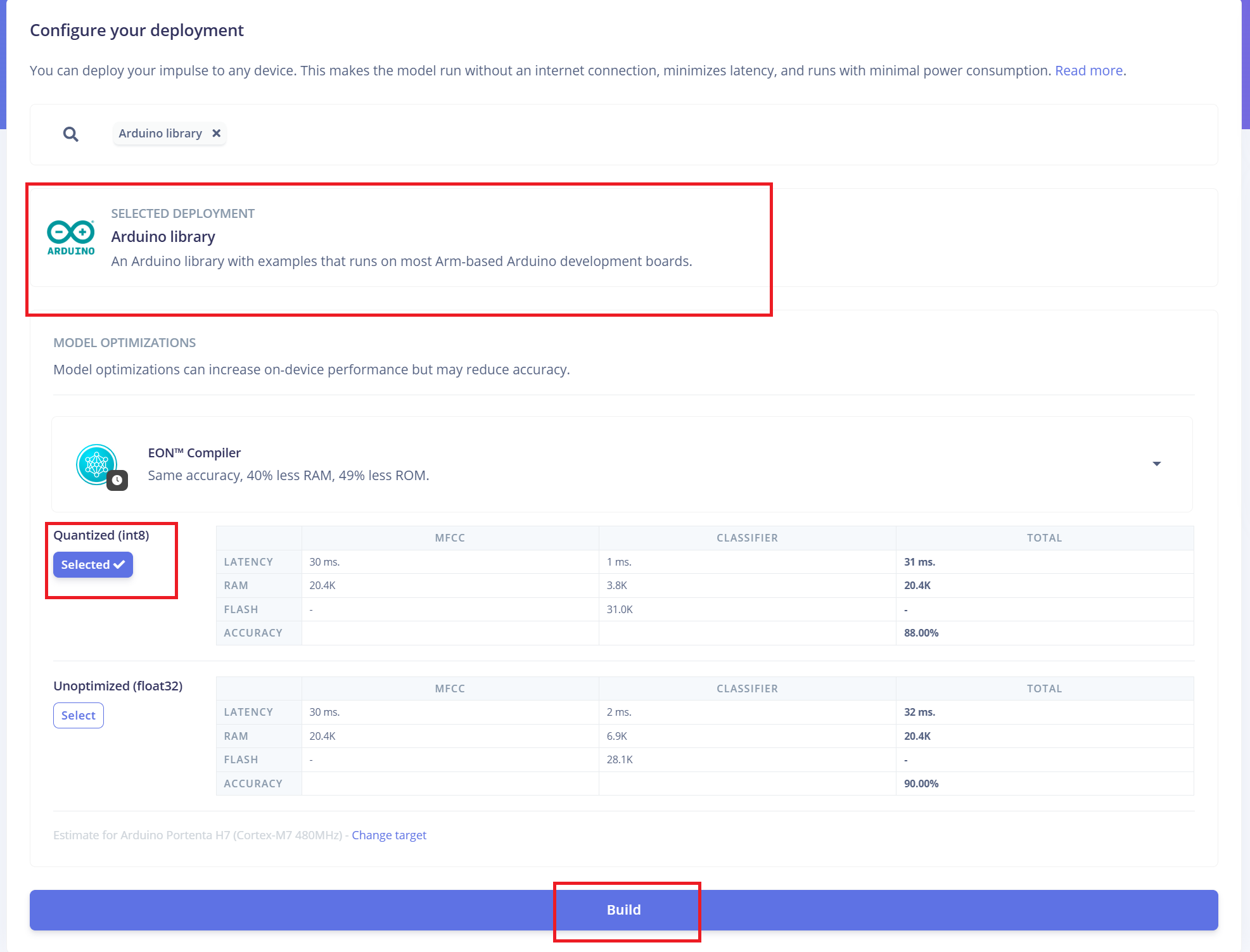
Fazendo o deploy no ReSpeaker XVF3800 com XIAO ESP32 S3
O Edge Impulse irá empacotar automaticamente todas as bibliotecas necessárias, funções de pré-processamento e o modelo treinado em um pacote para download. Para continuar:
- 1.Selecione "Arduino Library" como opção de implantação.
- 2.Na parte inferior, escolha o formato "Quantized (Int8)".
- 3.Clique em "Build" para gerar a biblioteca.
Quando o download for concluído:
- 4.Abra a Arduino IDE, vá até o menu Sketch.
- 5.Selecione "Include Library" > "Add .ZIP Library..."
- 6.Escolha o arquivo .zip baixado do Edge Impulse para adicioná-lo ao seu projeto Arduino.
Alternando o Firmware para o Modo I2S
Antes de enviar o código Arduino, você deve alternar o firmware do ReSpeaker XVF3800 para o modo I2S para habilitar a comunicação via protocolo I2C. Firmware Installation Guide
Integração do Código Arduino
O código Arduino fornecido pelo Edge Impulse exigirá algumas modificações para garantir a compatibilidade com o hardware ReSpeaker XVF3800 e XIAO ESP32S3: Atualize as definições dos pinos GPIO, taxa de amostragem I2S e outros parâmetros específicos de hardware de acordo com sua configuração.
#define EIDSP_QUANTIZE_FILTERBANK 0
#include <Kasun9603-project-1_inferencing.h> // Change with your one
#include "driver/i2s.h"
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
// ==== AUDIO CONFIG ====
#define I2S_PORT I2S_NUM_0
#define I2S_WS 7 // L/R clock
#define I2S_SD 43 // Serial Data In
#define I2S_SCK 8 // Bit Clock
#define SAMPLE_RATE 16000
#define I2S_SAMPLE_BITS 32
#define SAMPLE_BUFFER_SIZE 2048
// ==== INFERENCE STATE ====
typedef struct {
int16_t *buffer;
uint8_t buf_ready;
uint32_t buf_count;
uint32_t n_samples;
} inference_t;
static inference_t inference;
static int32_t i2s_samples[SAMPLE_BUFFER_SIZE];
static bool record_status = true;
static bool debug_nn = false;
// ==== FUNCTION DECLARATIONS ====
static bool microphone_inference_start(uint32_t n_samples);
static bool microphone_inference_record(void);
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr);
static void audio_inference_callback(uint32_t n_bytes);
static void capture_samples(void *arg);
static int i2s_init();
static void i2s_deinit();
void setup() {
Serial.begin(115200);
while (!Serial);
ei_printf("XVF3800 Keyword Spotting Inference Start\n");
ei_printf("Model info:\n");
ei_printf("\tFrame size: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);
ei_printf("\tSample length: %d ms\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / (SAMPLE_RATE / 1000));
ei_printf("\tInterval: %.2f ms\n", EI_CLASSIFIER_INTERVAL_MS);
if (!microphone_inference_start(EI_CLASSIFIER_RAW_SAMPLE_COUNT)) {
ei_printf("ERR: Audio buffer allocation failed.\n");
return;
}
ei_printf("Listening...\n");
}
void loop() {
if (!microphone_inference_record()) {
ei_printf("ERR: Failed to record audio.\n");
return;
}
signal_t signal;
signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT;
signal.get_data = µphone_audio_signal_get_data;
ei_impulse_result_t result = {0};
EI_IMPULSE_ERROR r = run_classifier(&signal, &result, debug_nn);
if (r != EI_IMPULSE_OK) {
ei_printf("ERR: Failed to run classifier (%d)\n", r);
return;
}
ei_printf("Predictions:\n");
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: ", result.classification[ix].label);
ei_printf_float(result.classification[ix].value);
ei_printf("\n");
}
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" Anomaly score: ");
ei_printf_float(result.anomaly);
ei_printf("\n");
#endif
}
// ==== INFERENCE AND AUDIO HANDLING ====
static void audio_inference_callback(uint32_t n_bytes) {
for (uint32_t i = 0; i < n_bytes / sizeof(int32_t); i++) {
int16_t val = i2s_samples[i] >> 16; // Convert from 32-bit signed to 16-bit
inference.buffer[inference.buf_count++] = val;
if (inference.buf_count >= inference.n_samples) {
inference.buf_ready = 1;
inference.buf_count = 0;
}
}
}
static void capture_samples(void *arg) {
size_t bytes_read;
while (record_status) {
i2s_read(I2S_PORT, (char *)i2s_samples, SAMPLE_BUFFER_SIZE * sizeof(int32_t), &bytes_read, portMAX_DELAY);
if (bytes_read > 0) {
audio_inference_callback(bytes_read);
} else {
ei_printf("ERR: I2S read failed\n");
}
}
vTaskDelete(NULL);
}
static bool microphone_inference_start(uint32_t n_samples) {
inference.buffer = (int16_t *)malloc(n_samples * sizeof(int16_t));
if (!inference.buffer) return false;
inference.buf_count = 0;
inference.n_samples = n_samples;
inference.buf_ready = 0;
if (i2s_init() != 0) {
ei_printf("ERR: I2S init failed\n");
return false;
}
xTaskCreate(capture_samples, "CaptureSamples", 4096, NULL, 1, NULL);
return true;
}
static bool microphone_inference_record(void) {
while (!inference.buf_ready) {
delay(10);
}
inference.buf_ready = 0;
return true;
}
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr) {
numpy::int16_to_float(&inference.buffer[offset], out_ptr, length);
return 0;
}
static int i2s_init() {
i2s_config_t i2s_config = {
.mode = (i2s_mode_t)(I2S_MODE_MASTER | I2S_MODE_RX),
.sample_rate = SAMPLE_RATE,
.bits_per_sample = (i2s_bits_per_sample_t)I2S_SAMPLE_BITS,
.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT,
.communication_format = I2S_COMM_FORMAT_I2S,
.intr_alloc_flags = ESP_INTR_FLAG_LEVEL1,
.dma_buf_count = 8,
.dma_buf_len = 512,
.use_apll = false,
.tx_desc_auto_clear = false,
.fixed_mclk = 0
};
i2s_pin_config_t pin_config = {
.bck_io_num = I2S_SCK,
.ws_io_num = I2S_WS,
.data_out_num = -1,
.data_in_num = I2S_SD
};
esp_err_t err;
err = i2s_driver_install(I2S_PORT, &i2s_config, 0, NULL);
if (err != ESP_OK) return err;
err = i2s_set_pin(I2S_PORT, &pin_config);
if (err != ESP_OK) return err;
err = i2s_zero_dma_buffer(I2S_PORT);
return err;
}
static void i2s_deinit() {
i2s_driver_uninstall(I2S_PORT);
}
Suporte Técnico & Discussão de Produtos
Obrigado por escolher nossos produtos! Estamos aqui para oferecer diferentes tipos de suporte e garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender diferentes preferências e necessidades.