Como executar VLM com interação por voz no reComputer Jetson
Introdução
Este guia fornece uma explicação detalhada sobre como executar um modelo de Linguagem Visual Multimodal (VLM) com interação por voz em um dispositivo reComputer Nvidia Jetson. O modelo aproveita os poderosos recursos computacionais da plataforma oficial Nvidia Jetson, combinados com o modelo open-source de conversão de fala em texto SenseVoice da Alibaba e o modelo de conversão de texto em fala (TTS) da coqui-ai, para realizar tarefas multimodais complexas. Seguindo este guia, você conseguirá instalar e operar este sistema com sucesso, habilitando-o com capacidades de reconhecimento visual e interação por voz, oferecendo assim soluções mais inteligentes para seus projetos.
Introdução ao VLM (Visual Language Model)
O Visual Language Model (VLM) é um modelo multimodal otimizado para a plataforma Nvidia Jetson. Ele combina processamento visual e de linguagem para lidar com tarefas complexas, como reconhecimento de objetos e geração de linguagem descritiva. O VLM é aplicável em áreas como direção autônoma, vigilância inteligente e casas inteligentes, oferecendo soluções inteligentes e intuitivas.

Introdução ao SenseVoice
SenseVoice é um modelo open-source focado em reconhecimento de fala multilíngue de alta precisão, reconhecimento de emoção na fala e detecção de eventos de áudio. Treinado com mais de 400.000 horas de dados, ele oferece suporte a mais de 50 idiomas e supera o modelo Whisper. O modelo SenseVoice-Small oferece latência ultrabaixa, processando 10 segundos de áudio em apenas 70 ms. Ele também fornece ajuste fino conveniente e suporta implantação em vários idiomas de programação, incluindo Python, C++, HTML, Java e C#.
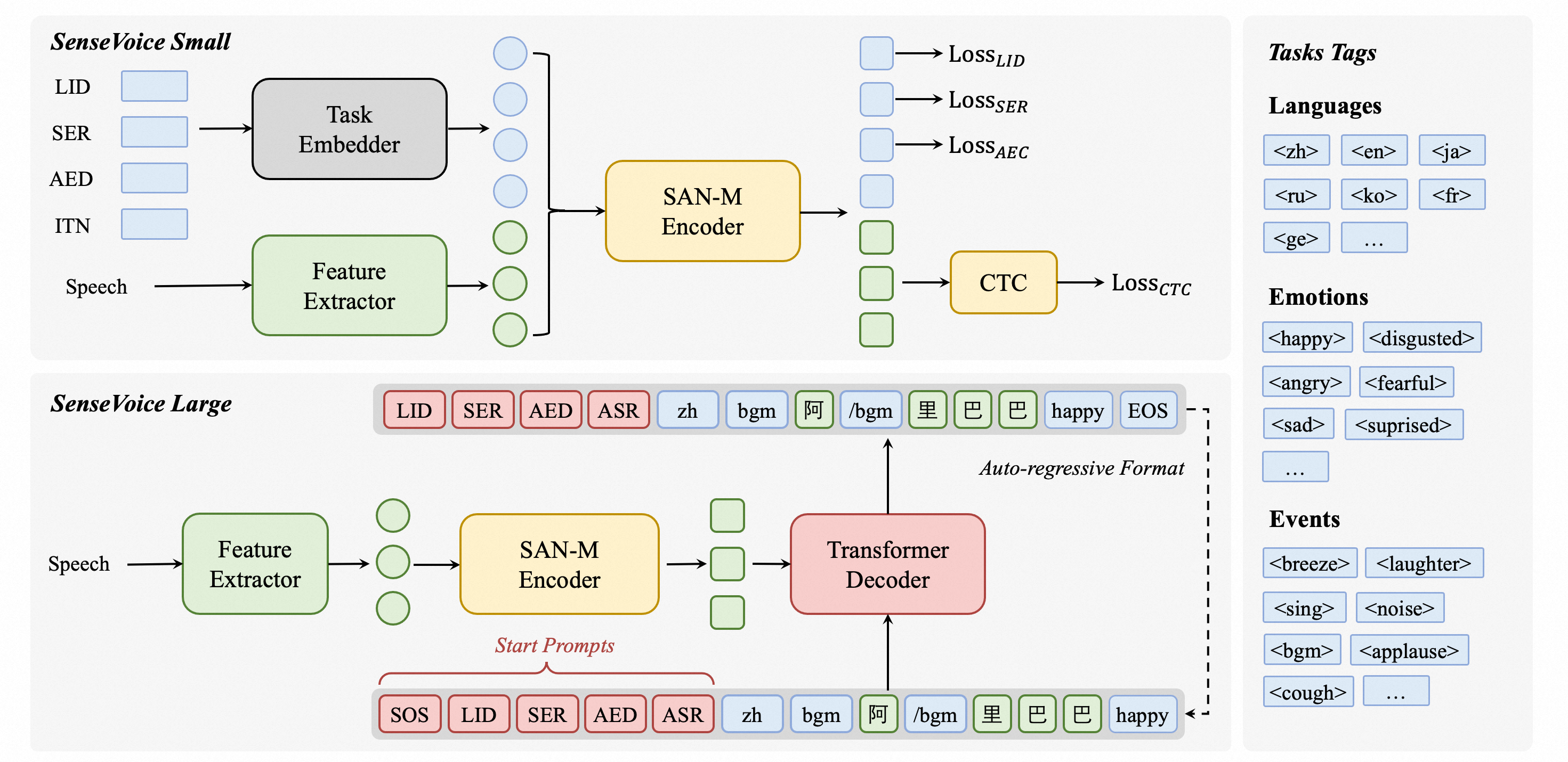
Introdução ao TTS (Text-to-Speech)
O modelo TTS é um modelo de deep learning de alto desempenho para tarefas de conversão de texto em fala. Ele inclui vários modelos como Tacotron2 e vocoders como MelGAN e WaveRNN. O modelo TTS oferece suporte a TTS multisspeaker, treinamento eficiente e fornece ferramentas para curadoria de conjuntos de dados e teste de modelos. Sua base de código modular permite a fácil implementação de novos recursos.

Pré-requisitos
- Dispositivo reComputer Jetson AGX Orin 64G ou reComputer Jetson J4012 16G com mais de 16 GB de memória.
- Microfone com alto-falante USB que não necessita de driver
- Uma câmera IP que possa fornecer um endereço de stream RTSP. Também incluímos instruções sobre como usar a ferramenta NVIDIA Nvstreamer para converter vídeos locais em streams RTSP.
Já testamos a viabilidade deste wiki no Developer Kit do reComputer Orin NX 16GB e AGX Orin 64GB.

Instalação
Inicializar o ambiente do sistema
-
Após instalar o sistema inicial com o JP6, você precisa verificar a instalação do
CUDAe de outras bibliotecas. Você pode verificá-las e instalá-las executandosudo apt-get install nvidia-jetpack. -
Instale
python3-pip,jtopedocker-ce. -
Instale as dependências necessárias executando os seguintes comandos:
sudo apt-get install libportaudio2 libportaudiocpp0 portaudio19-dev
sudo pip3 install pyaudio playsound subprocess wave keyboard
sudo pip3 --upgrade setuptools
sudo pip3 install sudachipy==0.5.2 -
Verifique se a entrada e saída de áudio, bem como o microfone com alto-falante USB, estão funcionando corretamente e se a conexão de rede é estável.
Instalar o VLM
A funcionalidade central deste projeto é o modelo de linguagem visual (VLM). Fornecemos um guia sobre como usar o VLM no reComputer Nvidia Jetson. Consulte este link para obter instruções de instalação e uso. Certifique-se de entender completamente como realizar inferência usando descrições de texto no VLM antes de prosseguir com as etapas a seguir.
Instalar Pytorch Torchaudio
Fornecemos um curso de IA Nvidia Jetson para iniciantes, que inclui instruções sobre como instalar PyTorch, Torchaudio e Torchvision. Baixe e instale esses pacotes de acordo com o ambiente do seu sistema.
Instalar Speech_vlm (Baseado em SenseVoice)
-
Clone os pacotes Speech_vlm:
cd ~/
git clone https://github.com/ZhuYaoHui1998/speech_vlm.git -
Instale o ambiente do Speech_vlm:
cd ~/speech_vlm
sudo pip3 install -r requement.txt
Instalar TTS (Baseado em Coqui-ai)
cd ~/speech_vlm/TTS
sudo pip3 install .[all]
Uso
A estrutura do repositório speech_vlm é a seguinte:
speech_vlm/
├── /TTS # Coqui-ai TTS program
├── config # VLM config
├── README.md #Project Introduction
├── requirements.txt #SenseVoice required environment libraries
├── compose.yaml #VLM Docker Compose startup file
├── delete_id.sh #Delete camera ID script
├── example_1.wav #Audio feedback sound tone template (replaceable)
├── model.py #SenseVoice main program
├── set_alerts.sh #Set up camera alerts
├── set_describe.sh #Text input to have the VLM describe the current scene
├── set_streamer_id.sh #Add RTSP camera to VLM
├── view_rtsp.py # View RTSP stream by opencv
└── vlm_voice.py # multimodal main program
-
Iniciar o VLM
cd ~/speech_vlm
sudo docker compose up -d
-
Adicionar stream RTSP ao VLM
Veja o conteúdo de set_streamer_id.sh no repositório speech_vlm:
#!/bin/bash
curl --location 'http://0.0.0.0:5010/api/v1/live-stream' \
--header 'Content-Type: application/json' \
--data '{"liveStreamUrl": "RTSP stream address"}'
Substitua 0.0.0.0 pelo endereço IP do dispositivo Jetson e substitua RTSP stream address pelo endereço de stream RTSP da câmera.
Por exemplo:
#!/bin/bash
curl --location 'http://192.168.49.227:5010/api/v1/live-stream' \
--header 'Content-Type: application/json' \
--data '{"liveStreamUrl": "rtsp://admin:[email protected]:554//Streaming/Channels/1"}'
Se você não tiver uma câmera RTSP, fornecemos instruções sobre como usar o NVStreamer para transmitir vídeos locais como RTSP e adicioná-los ao VLM.
Execute set_streamer_id.sh
cd ~/speech_vlm
sudo chmod +x ./set_streamer_id.sh
./set_streamer_id.sh
Obtivemos um ID de câmera; esse ID é muito importante e precisa ser anotado, assim:

- Executar vlm_voice.py
Você precisa substituir 0.0.0.0 nas duas linhas de código Python a seguir:
API_URL = 'http://0.0.0.0:5010/api/v1/chat/completions' # API endpoint
REQUEST_ID = "" # Request ID
pelo endereço IP do Jetson e preencher o ID da câmera retornado na Etapa 2 no lugar de REQUEST_ID.
vlm_voice.py
import pyaudio
import wave
import keyboard
import subprocess
import json
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
import time
import torch
from TTS.api import TTS
import os
# Get device
device = "cuda" if torch.cuda.is_available() else "cpu"
# Init TTS
api = TTS("tts_models/en/ljspeech/glow-tts").to(device)
# Configuration parameters
FORMAT = pyaudio.paInt16 # 16-bit resolution
CHANNELS = 1 # Mono channel
CHUNK = 1024 # Number of samples per chunk
OUTPUT_FILENAME = "output.wav" # Output file name
API_URL = 'http://192.168.49.227:5010/api/v1/chat/completions' # API endpoint
REQUEST_ID = "1388b691-3b9f-4bda-9d70-0ff0696f80f4" # Request ID
# Initialize PyAudio
audio = pyaudio.PyAudio()
# Prepare the list to store recording data
frames = []
# Initialize Micphone Rate
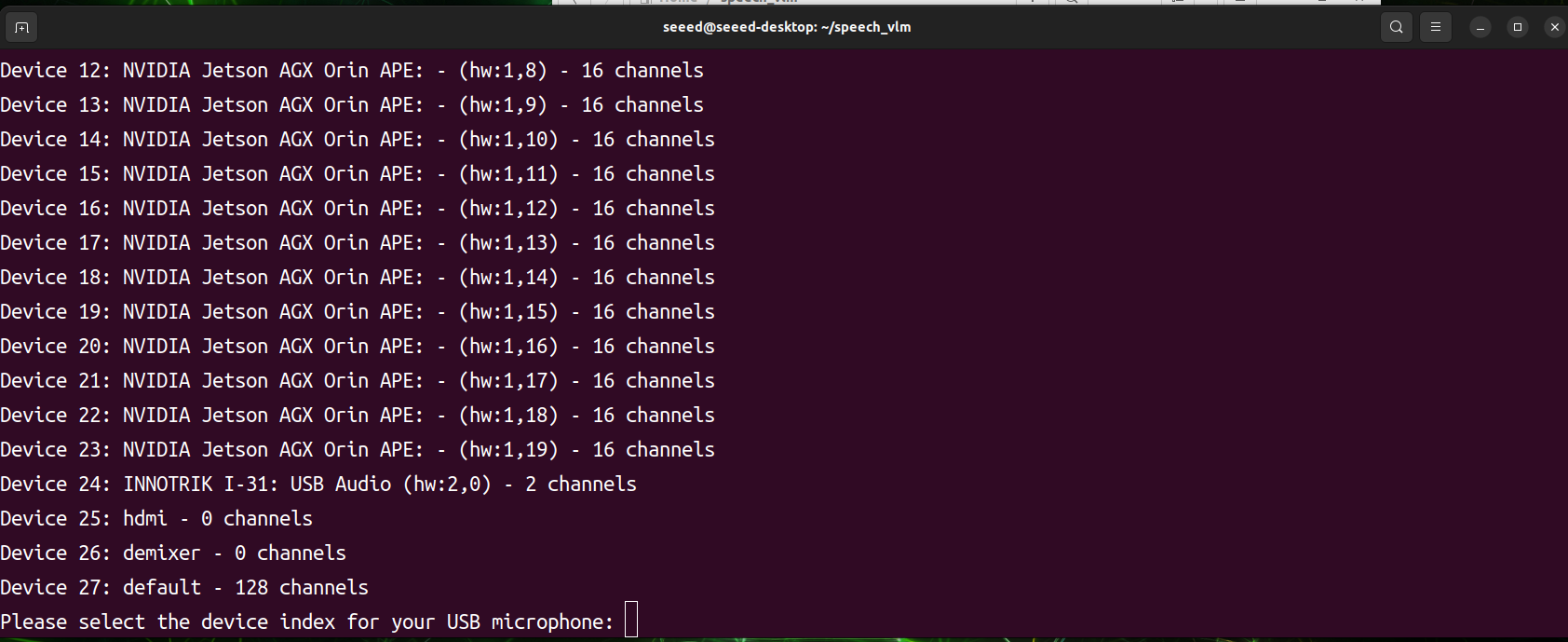
print("Available audio input devices:")
for i in range(audio.get_device_count()):
info = audio.get_device_info_by_index(i)
print(f"Device {i}: {info['name']} - {info['maxInputChannels']} channels")
device_index = int(input("Please select the device index for your USB microphone: "))
device_info = audio.get_device_info_by_index(device_index)
supported_sample_rates = [8000, 16000, 32000, 44100, 48000]
supported_rate=0
for rate in supported_sample_rates:
try:
if audio.is_format_supported(rate,
input_device=device_index,
input_channels=1,
input_format=pyaudio.paInt16):
supported_rate=rate
print(f"{rate} Hz is supported.")
except ValueError:
print(f"{rate} Hz is not supported.")
# Initialize the model
model = "./SenseVoiceSmall"
model = AutoModel(
model=model,
vad_model="./speech_fsmn_vad_zh-cn-16k-common-pytorch",
vad_kwargs={"max_single_segment_time": 30000},
trust_remote_code=True,
disable_log=True
)
def extract_content(json_response):
try:
# 解析JSON字符串
data = json.loads(json_response)
# 提取content部分
content = data["choices"][0]["message"]["content"]
print(f"{content}")
return content
except KeyError as e:
print(f"Key error: {e}")
except json.JSONDecodeError as e:
print(f"JSON decode error: {e}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
def start_recording():
global frames
frames = []
try:
stream = audio.open(format=FORMAT, channels=CHANNELS,
rate=supported_rate, input=True,
frames_per_buffer=CHUNK, input_device_index=device_index)
print("Recording started... Press '2' to stop recording.")
while True:
if keyboard.is_pressed('2'):
print("Recording stopped.")
break
data = stream.read(CHUNK)
frames.append(data)
stream.stop_stream()
stream.close()
except Exception as e:
print(f"An error occurred during recording: {e}")
def save_recording():
try:
waveFile = wave.open(OUTPUT_FILENAME, 'wb')
waveFile.setnchannels(CHANNELS)
waveFile.setsampwidth(audio.get_sample_size(FORMAT))
waveFile.setframerate(supported_rate)
waveFile.writeframes(b''.join(frames))
waveFile.close()
print(f"Recording saved as {OUTPUT_FILENAME}")
except Exception as e:
print(f"An error occurred while saving the recording: {e}")
def send_alert(text):
# Construct the JSON payload
payload = {
"messages": [
{
"role": "system",
"content": "You are a helpful AI assistant."
},
{
"role": "user",
"content": [
{
"type": "stream",
"stream": {
"stream_id": REQUEST_ID
}
},
{
"type": "text",
"text": text
}
]
}
],
"min_tokens": 1,
"max_tokens": 128
}
# Convert the payload to a JSON string
json_payload = json.dumps(payload)
# Execute the curl command using subprocess
curl_command = [
'curl', '--location', API_URL,
'--header', 'Content-Type: application/json',
'--data', json_payload
]
try:
result = subprocess.run(curl_command, check=True, capture_output=True, text=True)
##Get words
content_result=extract_content(result.stdout)
# TTS
api.tts_to_file(
str(content_result),
speaker_wav="./example_1.wav",
file_path="speech.wav"
)
# Convert audio rate
subprocess.run(['ffmpeg', '-i', 'speech.wav', '-ar',str(supported_rate), 'speech1.wav','-y'])
# Play audio
wf = wave.open('./speech1.wav', 'rb')
stream = audio.open(format=pyaudio.paInt16,
channels=1,
rate=supported_rate,
output=True,
output_device_index=device_index)
data = wf.readframes(1024)
while data:
stream.write(data)
data = wf.readframes(1024)
# Play audio
os.remove('speech.wav')
os.remove('speech1.wav')
stream.stop_stream()
stream.close()
wf.close() # Close the wave file as well
#print(f"Alert sent successfully: {result.stdout}")
except subprocess.CalledProcessError as e:
print(f"An error occurred while sending the alert: {e.stderr}")
finally:
# Even if an error occurs, try to close the stream
if stream.is_active():
stream.stop_stream()
os.remove('speech.wav')
os.remove('speech1.wav')
stream.close()
print("Welcome to the Recording and Speech-to-Text System!")
print("Press '1' to start recording, '2' to stop recording.")
while True:
if keyboard.is_pressed('1'):
print("Preparing to start recording...")
start_recording()
save_recording()
print("Processing the recording file, please wait...")
try:
res = model.generate(
input=f"./{OUTPUT_FILENAME}",
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True,
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(f"Speech-to-Text Result:\n{text}")
# Send the transcription result as an alert
send_alert(text)
except Exception as e:
print(f"An error occurred while processing the recording: {e}")
time.sleep(0.1) # Reduce CPU usage
Execute o python:
cd ~/speech_vlm
sudo python3 vlm_voice.py
Após o início do programa, ele fará a varredura de todos os dispositivos de entrada e saída de áudio. Você precisará selecionar manualmente o ID de índice do dispositivo de áudio desejado. O programa está prestes a começar a funcionar, então pressione 1 para gravar e 2 para enviar.
- Ver resultado
Nós preparamos um script view_rtsp.py para visualizar os resultados de saída. Você precisa substituir a parte do IP em rtsp_url = "rtsp://0.0.0.0:5011/out" pelo endereço IP do seu dispositivo Jetson.
viwe_rtsp.py
import cv2
rtsp_url = "rtsp://192.168.49.227:5011/out"
cap = cv2.VideoCapture(rtsp_url)
if not cap.isOpened():
print("Cannot open RTSP stream")
exit()
while True:
ret, frame = cap.read()
if not ret:
print("Failed to retrieve frame")
break
height, width = frame.shape[:2]
frame_resized = cv2.resize(frame, (int(width // 1.1), int(height // 1.1)))
cv2.imshow('RTSP Stream', frame_resized)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
sudo pip3 install opencv-python
cd ~/speech_vlm
sudo python3 view_rtsp.py
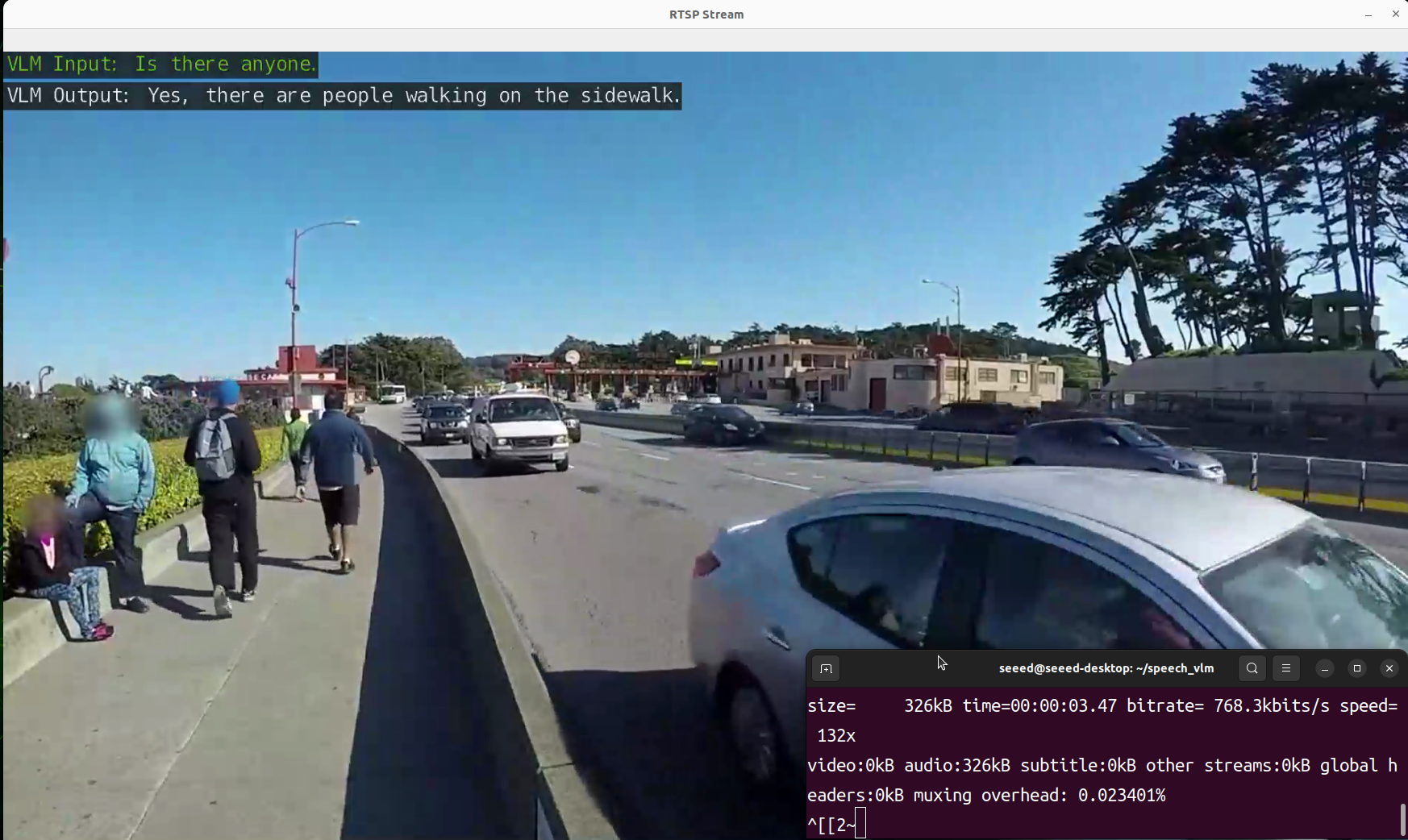
Demonstração
Suporte Técnico e Discussão de Produtos
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.