Processamento de Dados IoT em Tempo Real em Node Alimentado por Apache Kafka
Nosso node de processamento de ponta, Kafka-ESP32, combina o poder do Apache Kafka e dos microcontroladores ESP32C6 para fornecer uma solução eficiente para lidar com fluxos de dados de IoT. Usando o XIAO ESP32C6 com o sensor ambiental DHT20, os dados são coletados e enviados perfeitamente para o Apache Kafka via ESP32C6. Os recursos de mensagens de alta taxa de transferência e baixa latência do Kafka permitem o processamento e a análise de dados em tempo real, enquanto sua arquitetura distribuída possibilita escalabilidade sem esforço. O Kafka-ESP32 capacita você a desenvolver aplicações e integrações personalizadas, revolucionando a forma como você gerencia e utiliza seus ativos de IoT no cenário atual orientado a dados.
Materiais Necessários
Este exemplo vai apresentar o uso do XIAO ESP32C6 com o sensor de temperatura e umidade Grove DHT20 para concluir a tarefa SageMaker do AWS IoT Core. Abaixo estão todos os dispositivos de hardware necessários para concluir esta rotina.
| XIAO ESP32C6 | DHT20 | Placa de Extensão |
|---|---|---|
 |  |  |
Instalação do Docker
Por que usar Docker? Porque o Docker pode simular o ambiente de múltiplos computadores em uma única máquina e implantar aplicações com grande facilidade. Portanto, neste projeto, vamos usar o Docker para configurar o ambiente e melhorar a eficiência.
Etapa 1. Baixar o Docker
De acordo com o seu computador, baixe o tipo de instalador correspondente. Clique aqui para acessar.
Se o seu computador for Windows, não instale o Docker até terminar a Etapa 2.
Etapa 2. Instalar o WSL (Windows Subsystem for Linux)
Esta etapa é para Windows. Você pode pular esta etapa se o seu computador for Mac ou Linux.
- Execute o seguinte código como administrador.
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
-
Baixe esta ferramenta por aqui e clique duas vezes para instalá-la.
-
Vá até a sua Microsoft Store para pesquisar e baixar a versão de Linux que você preferir, aqui eu instalei o Ubuntu.
- Depois de instalar o Linux, você precisa abri-lo e definir seu nome de usuário e senha, e então aguardar um minuto para a inicialização.
- Execute os seguintes comandos para usar o WSL.
- Depois de instalar o WSL, agora você pode clicar duas vezes no instalador do Docker para instalá-lo. Quando você vir a seguinte imagem, significa que está funcionando.
Implantar Serviços
Antes de começarmos, quero apresentar a função de cada serviço neste projeto.
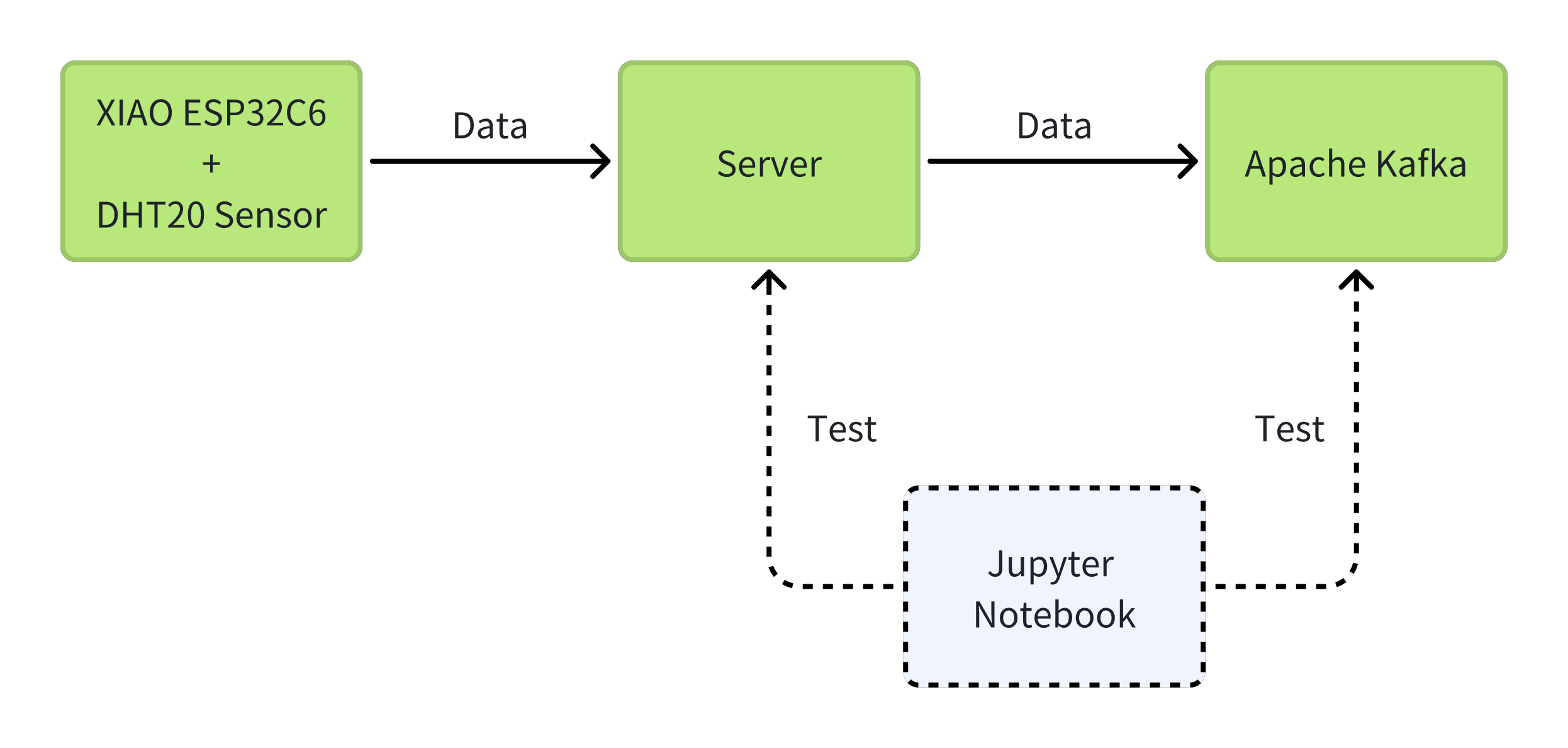
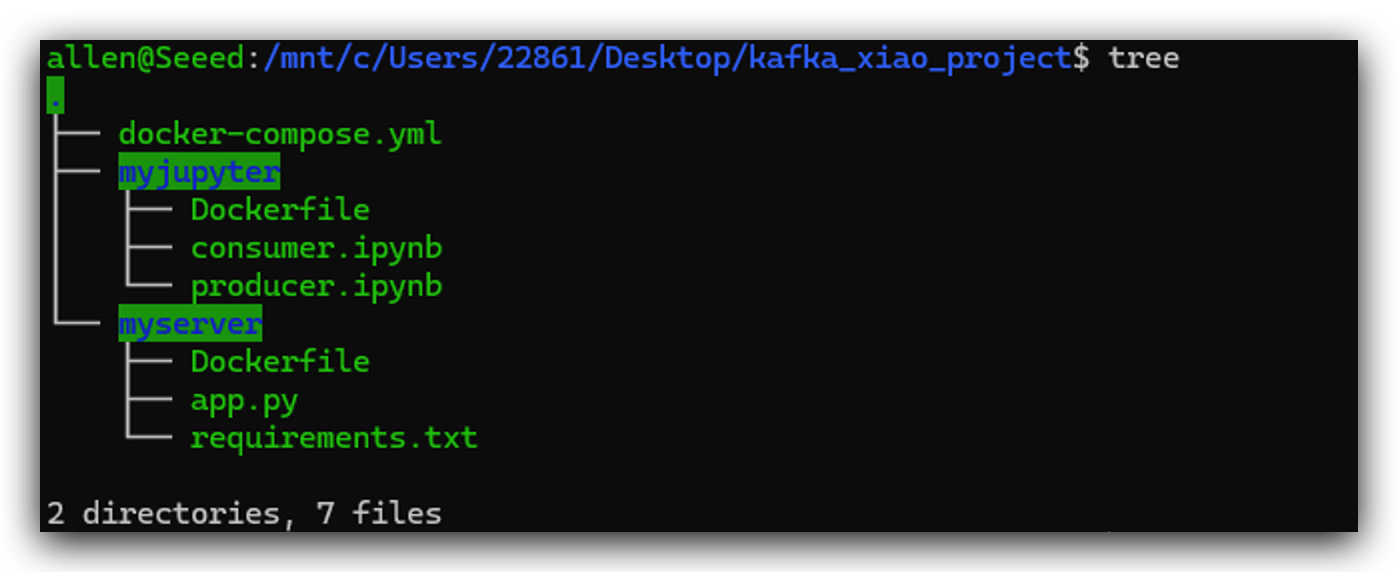
Aqui está a estrutura de diretórios deste projeto para sua referência. Vou criar esses arquivos um por um nas etapas a seguir. A posição de cada arquivo é muito importante. Eu recomendo fortemente que você consulte esta estrutura de diretórios. Crie um diretório kafka_xiao_project e inclua esses arquivos.
Etapa 3. Implantar um Servidor Python
Devido à falta de desempenho do dispositivo MCU, ele não pode ser usado diretamente como cliente do Kafka. Então você precisa construir um servidor para fazer o trânsito de dados. Esta etapa é para construir um servidor simples com Python. O XIAO ESP32C6 serve principalmente para coletar dados de ambiente do DHT20 e enviá-los ao servidor.
- Primeiro precisamos criar o arquivo app.py, que é o que o servidor executa.
from flask import Flask
from kafka import KafkaProducer, KafkaConsumer
app = Flask(__name__)
@app.route('/favicon.ico')
def favicon():
return '', 204
@app.route('/<temperature>/<humidity>')
def send_data(temperature, humidity):
producer = KafkaProducer(bootstrap_servers='kafka:9092')
data = f'Temperature: {temperature}, Humidity: {humidity}'
producer.send('my_topic', data.encode('utf-8'))
return f'Temperature: {temperature}, Humidity: {humidity}'
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5001)
- Crie requirements.txt, que é a biblioteca de dependências.
flask
kafka-python
- Crie o Dockerfile
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["python", "app.py"]
- Depois de criar esses 3 arquivos, podemos então construir uma imagem Docker executando o seguinte código.
docker build -t pyserver .
Etapa 4. Implantar o Jupyter Notebook
O Jupyter Notebook é usado principalmente para depuração, e é uma ferramenta muito boa de se usar. Além disso, podemos usar Python para operar o Kafka.
- Primeiro crie o Dockerfile.
FROM python:3.9
RUN pip install jupyter
WORKDIR /notebook
EXPOSE 8888
CMD ["jupyter", "notebook", "--ip=0.0.0.0", "--port=8888", "--no-browser", "--allow-root"]
- Construa a imagem Docker do Jupyter.
docker build -t jupyter .
Etapa 5. Iniciar o Cluster Docker
Podemos usar docker-compose.yml para construir o cluster Docker. Cada serviço no docker-compose representa um computador independente e usamos kafka-net para conectá-los entre si.
- Então primeiro precisamos criar docker-compose.yml.
services:
zookeeper:
container_name: zookeeper
hostname: zookeeper
image: docker.io/bitnami/zookeeper
ports:
- "2181:2181"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
networks:
- kafka-net
kafka:
container_name: kafka
hostname: kafka
image: docker.io/bitnami/kafka
ports:
- "9092:9092"
- "9093:9093"
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CFG_BROKER_ID=0
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_LISTENERS=INTERNAL://kafka:9092,EXTERNAL://localhost:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka:9092,EXTERNAL://localhost:9093
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL
depends_on:
- zookeeper
networks:
- kafka-net
jupyter:
image: jupyter:latest
depends_on:
- kafka
volumes:
- ./myjupyter:/notebook
ports:
- "8888:8888"
environment:
- JUPYTER_ENABLE_LAB=yes
networks:
- kafka-net
pyserver:
image: pyserver:latest
depends_on:
- kafka
volumes:
- ./myserver/app.py:/app/app.py
ports:
- "5001:5001"
networks:
- kafka-net
networks:
kafka-net:
driver: bridge
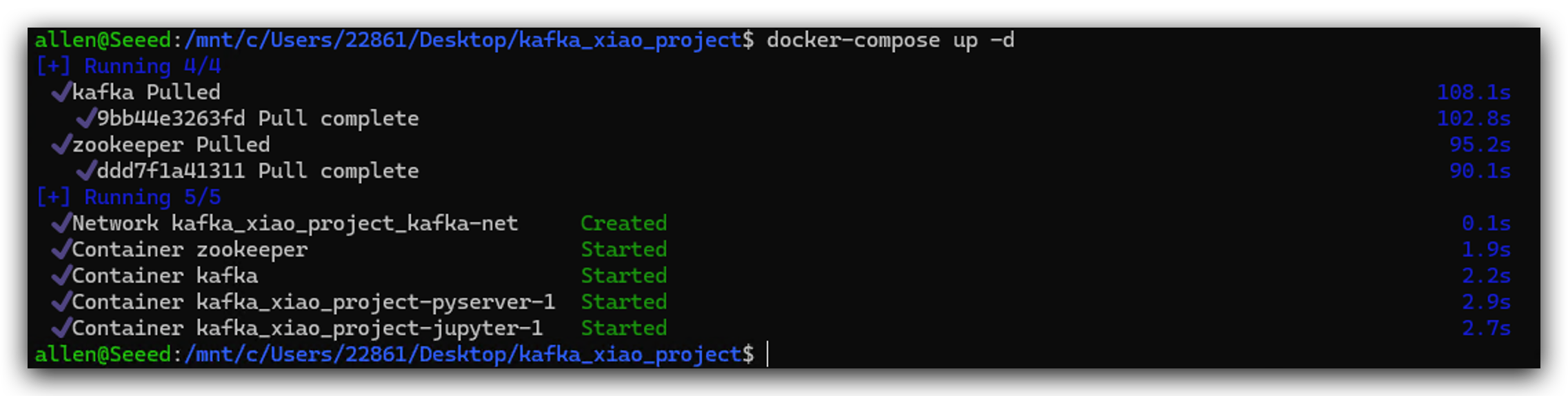
- E então iniciamos este cluster Docker executando o seguinte comando.
docker-compose up -d
É possível que a porta esteja ocupada, você pode alterar a porta de 5001 para 5002 etc., ou fechar o aplicativo que está ocupando a porta.
- Nas próximas operações vamos testar se tudo está funcionando bem. Primeiro abrimos o software docker desktop e clicamos em pyserver.
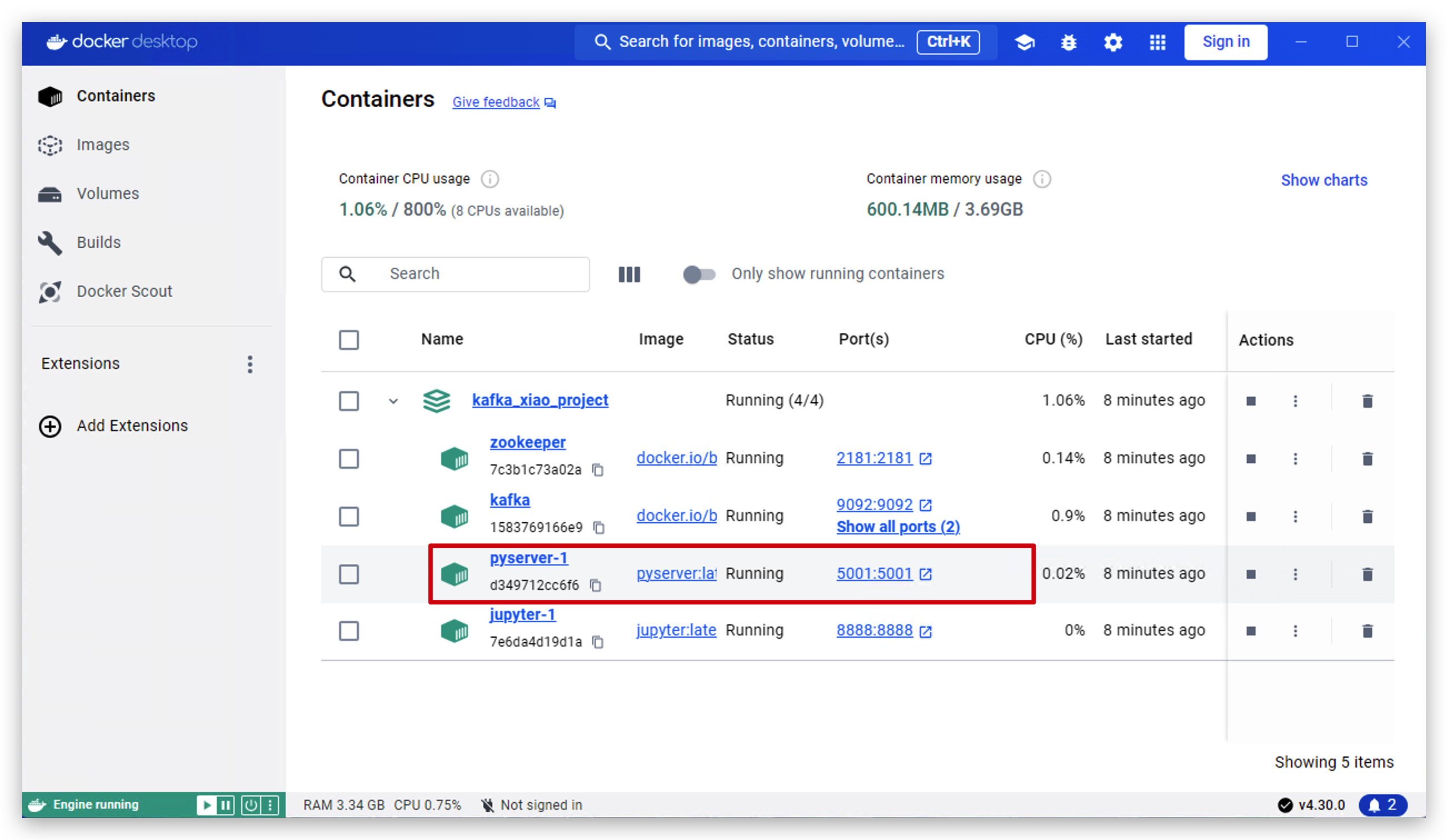
- Agora o servidor está rodando em
http://127.0.0.1:5001. Clique neste link para abri‑lo.
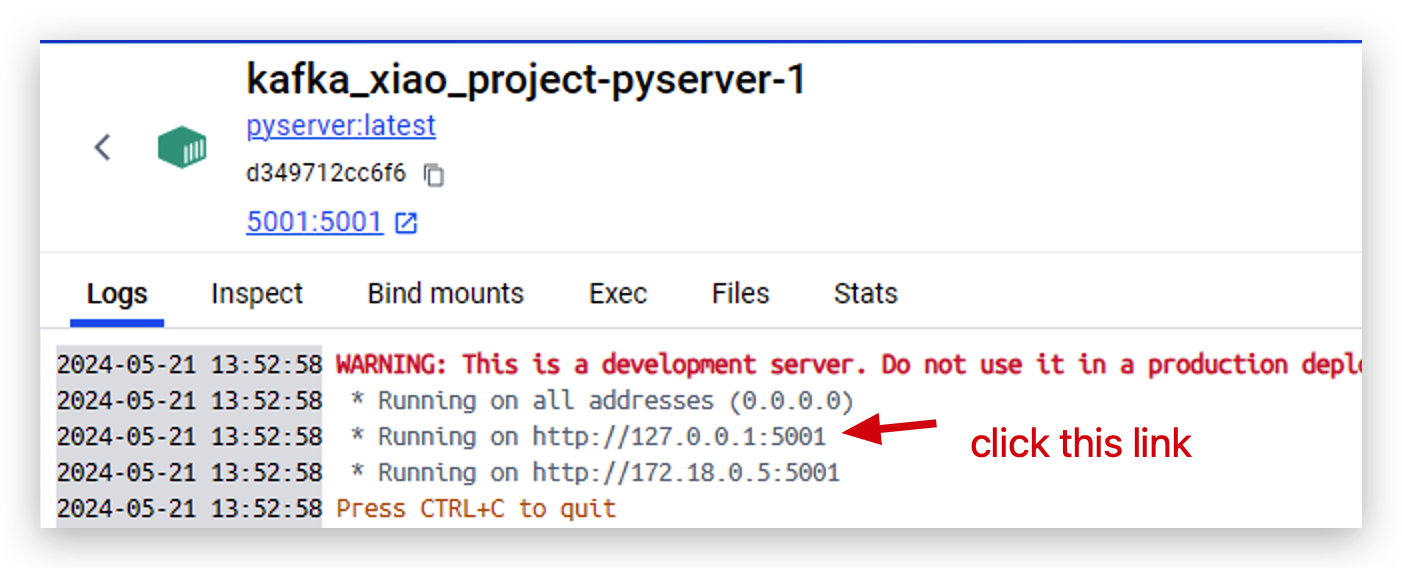
- Em seguida, insira dois parâmetros neste formato para testar se o cluster docker está funcionando bem.
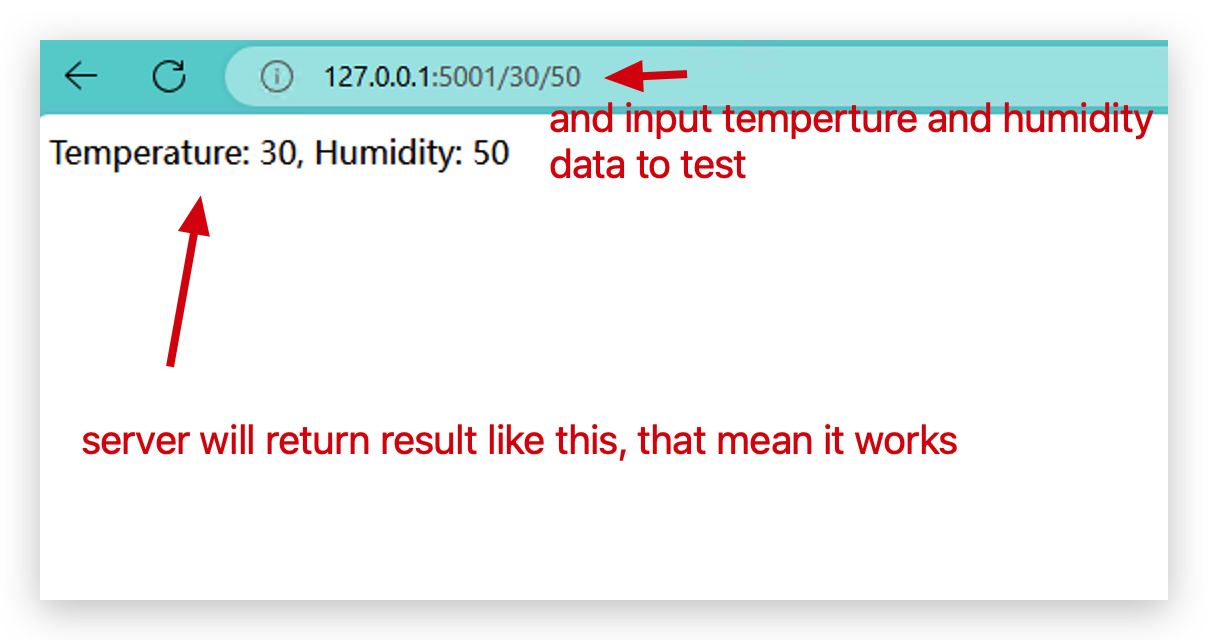
- Vamos entrar no Kafka para ver se os dados foram enviados para o Kafka.
docker exec -it kafka bash
cd opt/bitnami/kafka/bin/
kafka-console-consumer.sh --bootstrap-server localhost:9093 --topic my_topic --from-beginning

- Podemos tentar novamente com parâmetros diferentes e você poderá ver que os dados são enviados ao Kafka imediatamente. Agora, parabéns! Seu cluster docker está funcionando perfeitamente.
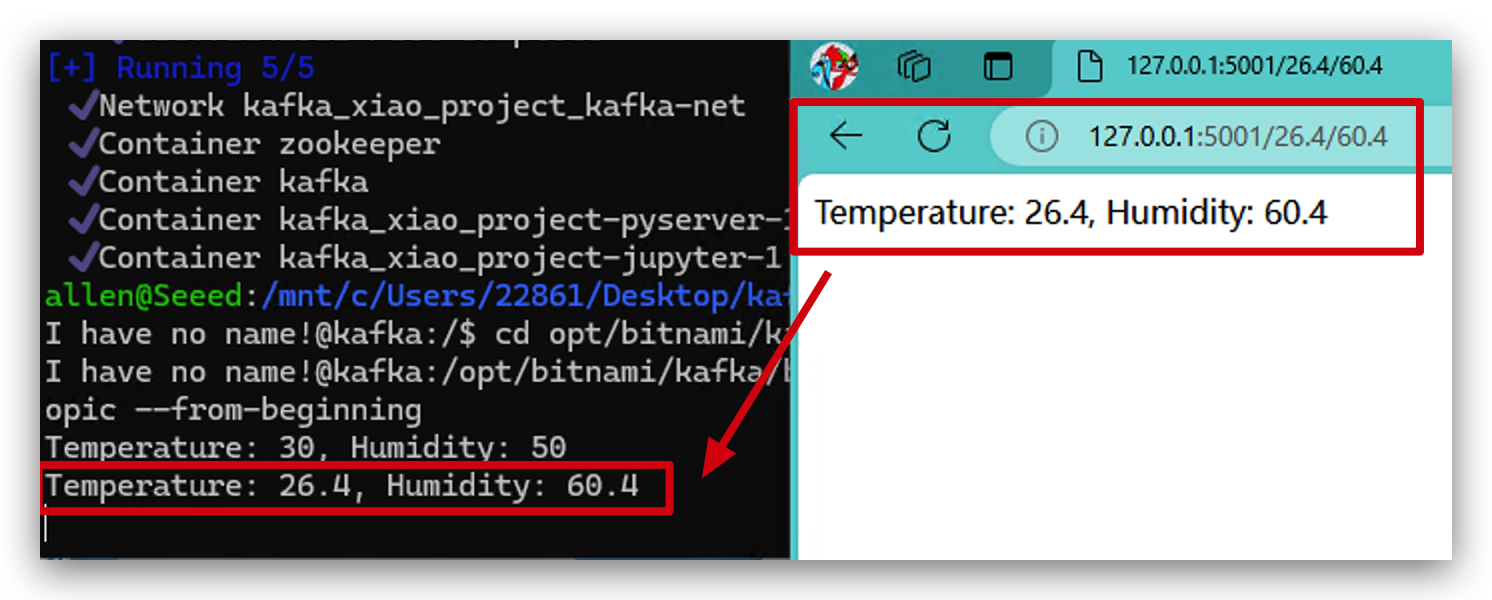
Passo 7. Testar o Kafka com Python
Esta etapa é principalmente sobre como usar Python para manipular o Kafka. Você também pode pular esta etapa. Não há impacto nas operações gerais do projeto.
- Abra o docker desktop e clique em jupyter.
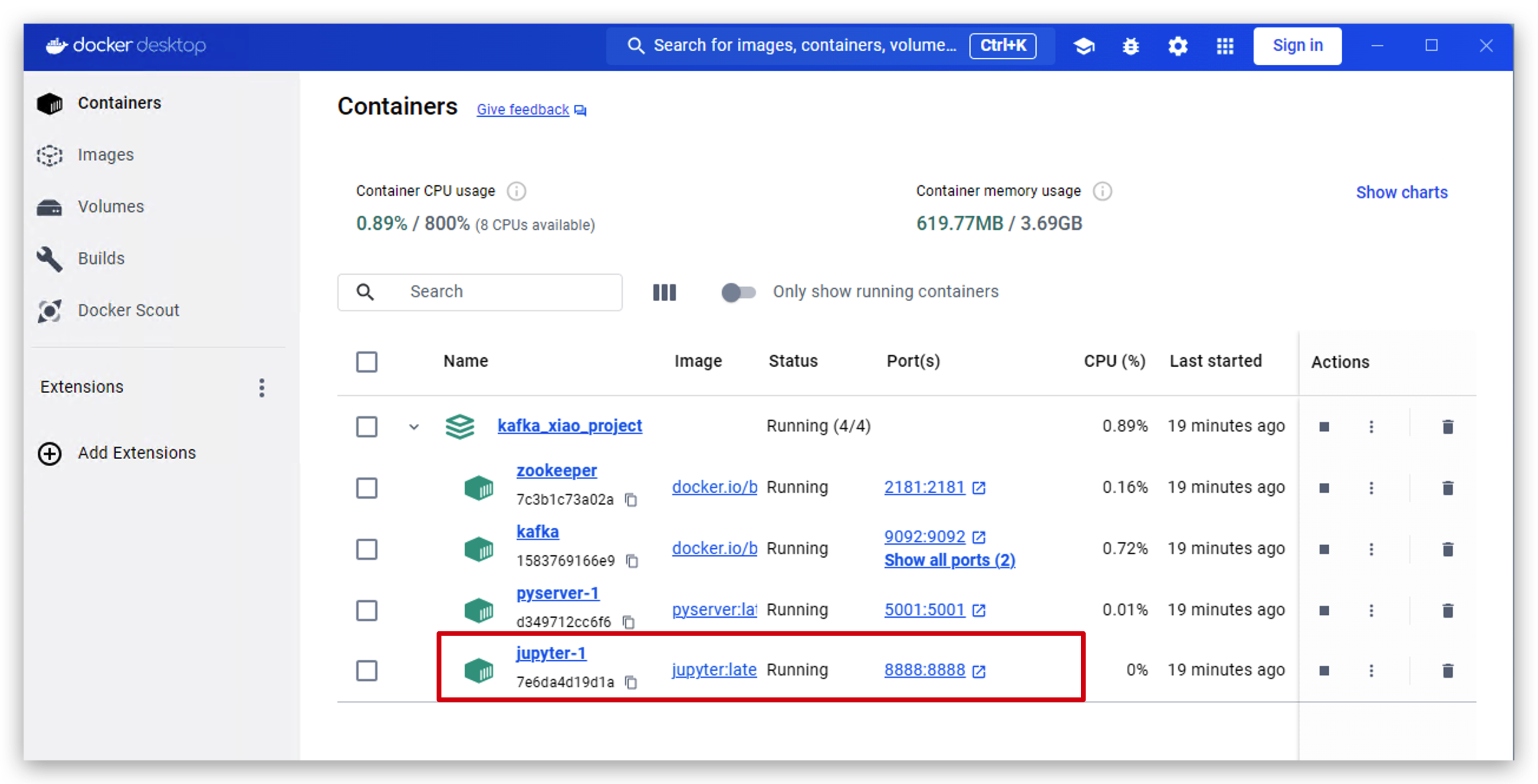
- Clique neste link para acessar o jupyter.
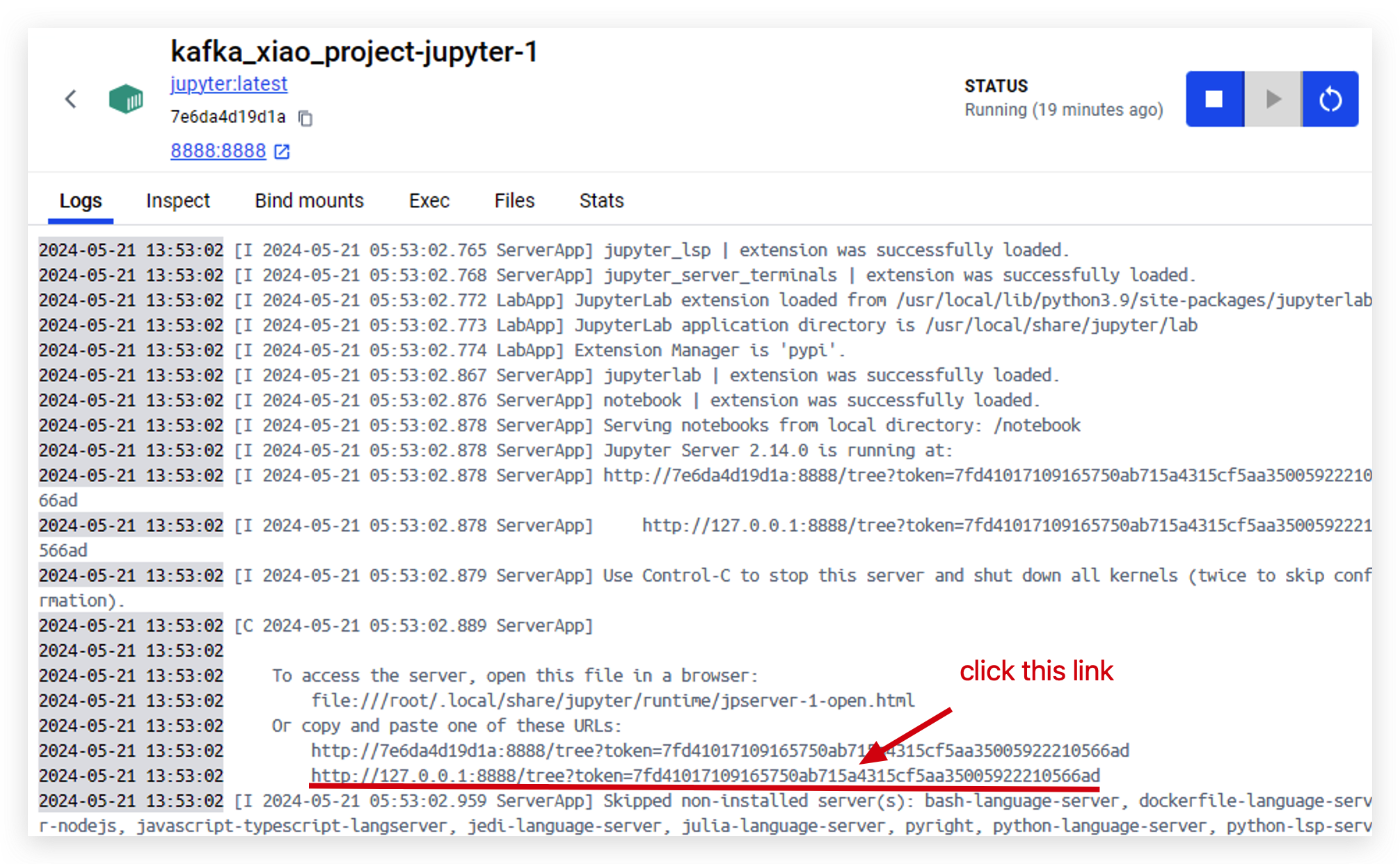
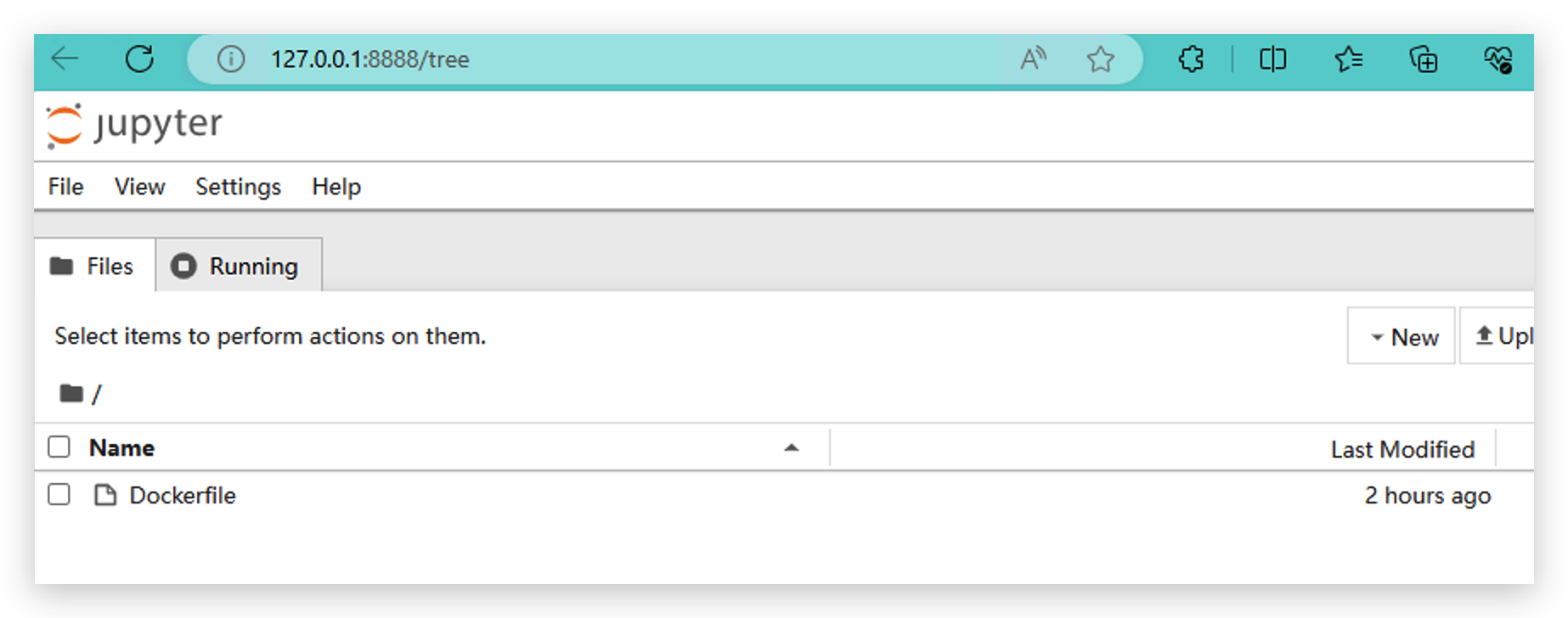
- Quando você acessar o jupyter com sucesso, verá esta página.
- Clique com o botão direito do mouse e crie um New Notebook, usando Python3(ipykernel).
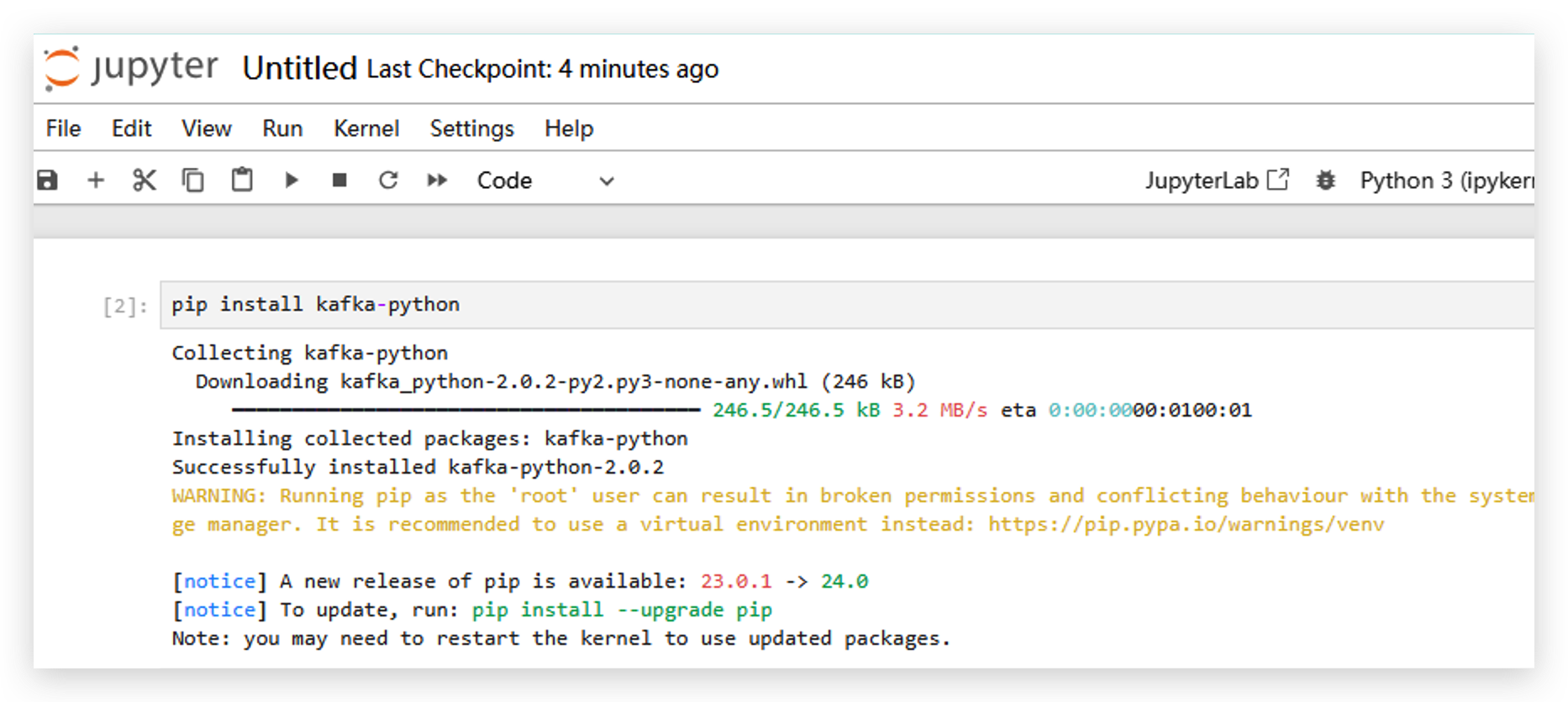
- Instale a biblioteca kafka-python executando
pip install kafka-python.
- Depois de instalar essa biblioteca, precisamos reiniciar o jupyter.
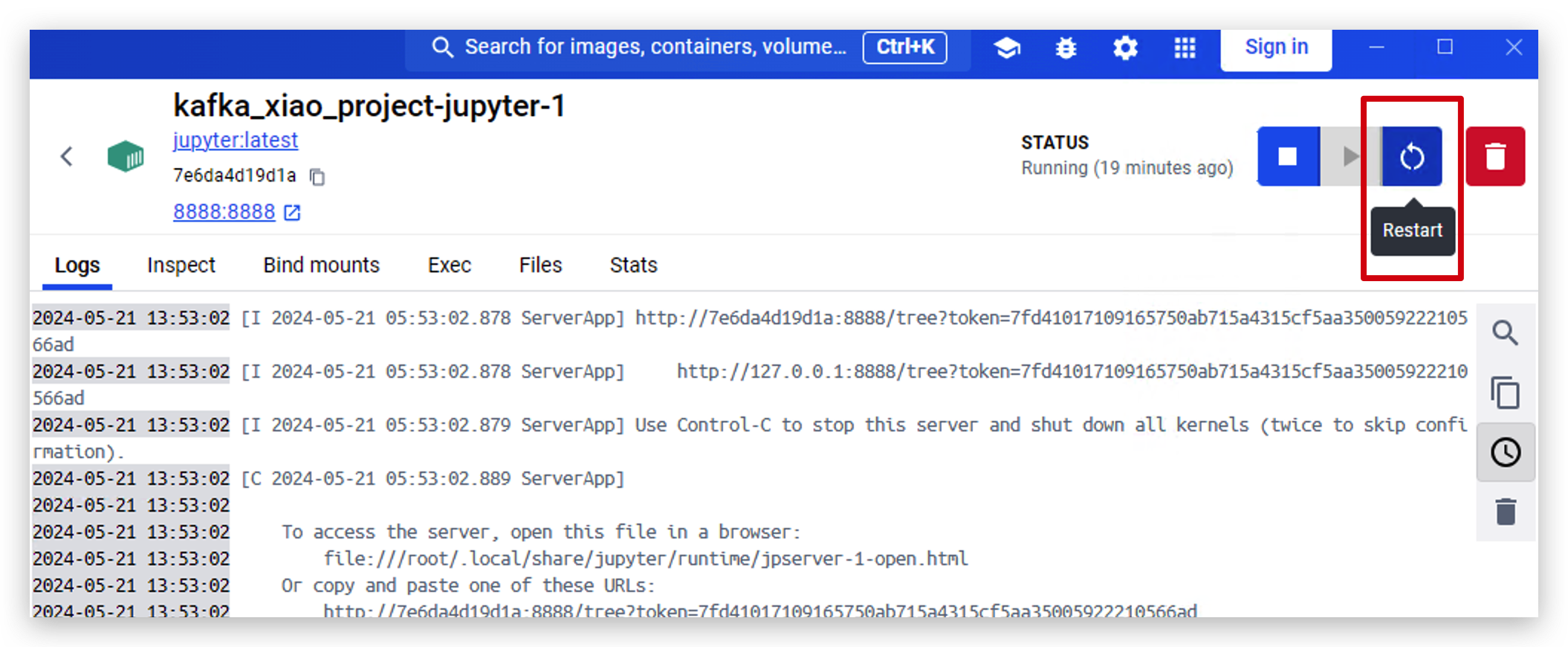
- Agora execute o código a seguir para enviar alguns dados para o Kafka usando Python.
from kafka import KafkaProducer, KafkaConsumer
#initialize producer
producer = KafkaProducer(bootstrap_servers='localhost:9093')
#send message
producer.send('my_topic', b'Hello, Kafka2')
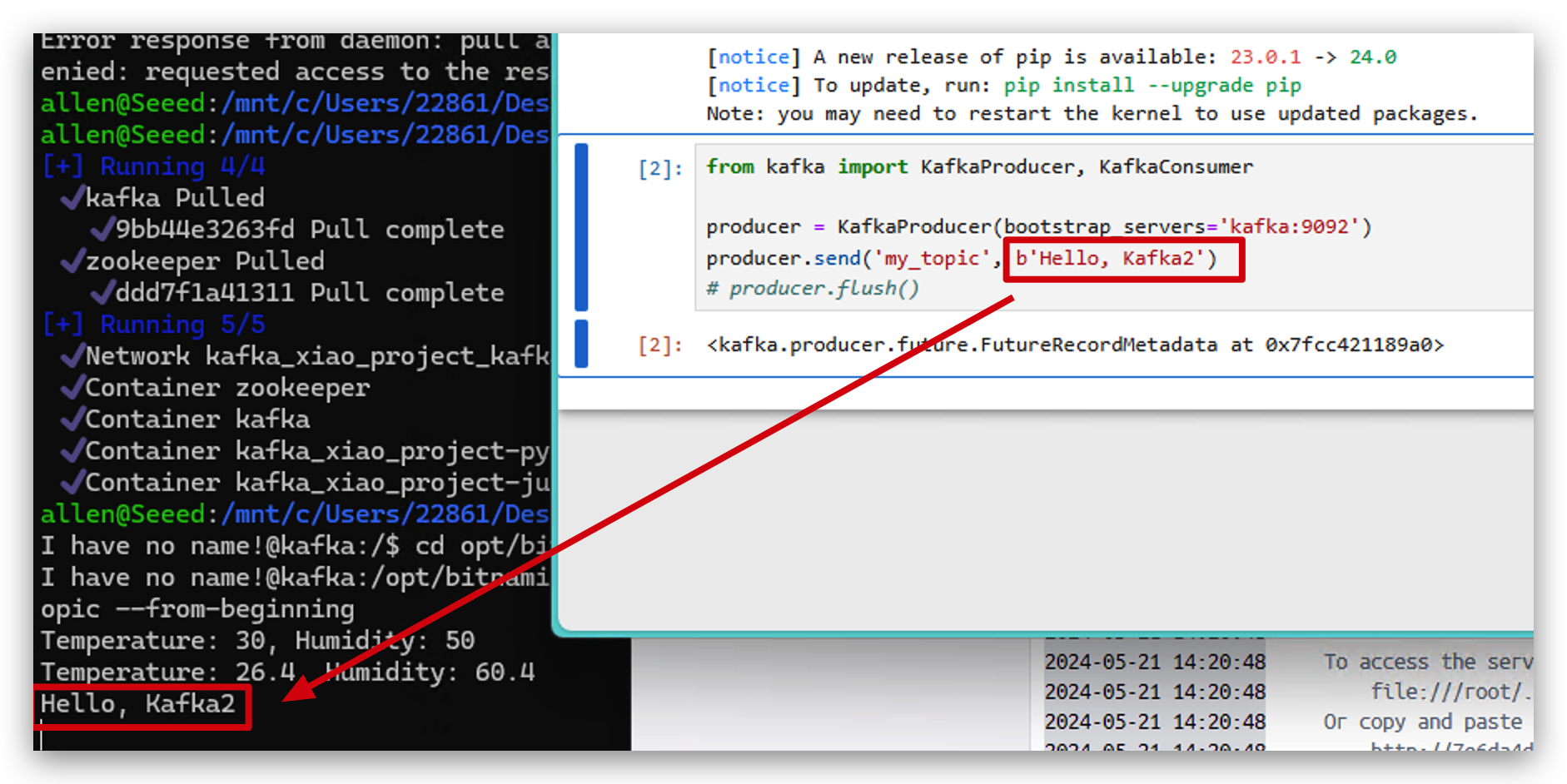
- Você também pode verificar esses dados no kafka.
from kafka import KafkaConsumer
# initialize consumer
consumer = KafkaConsumer(
'my_topic',
bootstrap_servers='localhost:9093',
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='group1'
)
# receive data and print
for message in consumer:
print(f"Received message: {message.value.decode('utf-8')}")
XIAO ESP32C6 e Apache Kafka
Kafka é uma plataforma de streaming distribuída que possibilita o processamento em tempo real de fluxos de dados em grande escala. Ela permite o envio e recebimento de mensagens de dados entre sistemas no modelo publish-subscribe, oferecendo tolerância a falhas, persistência e alta taxa de transferência. O Kafka é amplamente utilizado para construir pipelines de dados em tempo real e aplicações de streaming em vários domínios.
Agora, vamos usar o XIAO ESP32C6 e o sensor de temperatura e umidade DHT20 para coletar dados e enviá‑los ao Kafka em tempo real.
Passo 8. Coletar Dados e Enviar para o Apache Kafka
- Copie o código a seguir para a sua IDE do Arduino.
#include <WiFi.h>
#include <HTTPClient.h>
//Change to your wifi name and password here.
const char* ssid = "Maker_2.4G";
const char* password = "15935700";
//Change to your computer IP address and server port here.
const char* serverUrl = "http://192.168.1.175:5001";
void setup() {
Serial.begin(115200);
WiFi.begin(ssid, password);
while (WiFi.status() != WL_CONNECTED) {
delay(1000);
Serial.println("Connecting to WiFi...");
}
Serial.println("Connected to WiFi");
}
void loop() {
if (WiFi.status() == WL_CONNECTED) {
HTTPClient http;
//Create access link
String url = serverUrl;
url += "/";
url += "30.532"; // tempertature
url += "/";
url += "60.342"; // humidity
http.begin(url);
int httpResponseCode = http.GET();
//Get http response and print
if (httpResponseCode == 200) {
String response = http.getString();
Serial.println("Server response:");
Serial.println(response);
} else {
Serial.print("HTTP error code: ");
Serial.println(httpResponseCode);
}
http.end();
} else {
Serial.println("WiFi disconnected");
}
delay(5000); // access server in every 5s.
}
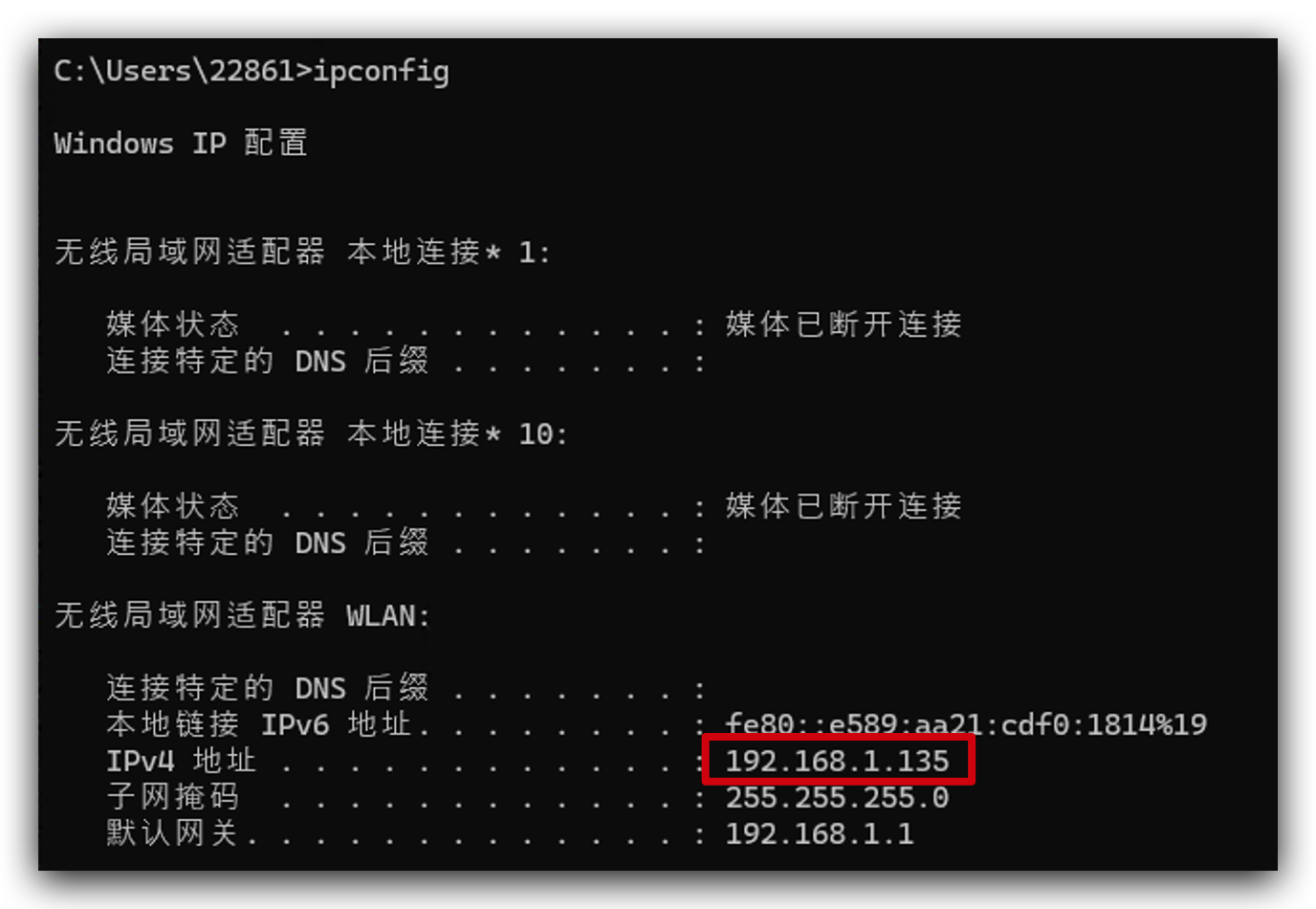
Se você não sabe qual é o endereço IP do seu computador, você pode executar ipconfig (Windows) ou ifconfig | grep net (Mac ou Linux) para verificá‑lo.
- Use o cabo Type‑C para conectar o seu computador ao C6 e use o cabo Grove para conectar a porta I2C da placa de extensão XIAO ao sensor DHT20.

- Escolha sua placa de desenvolvimento.
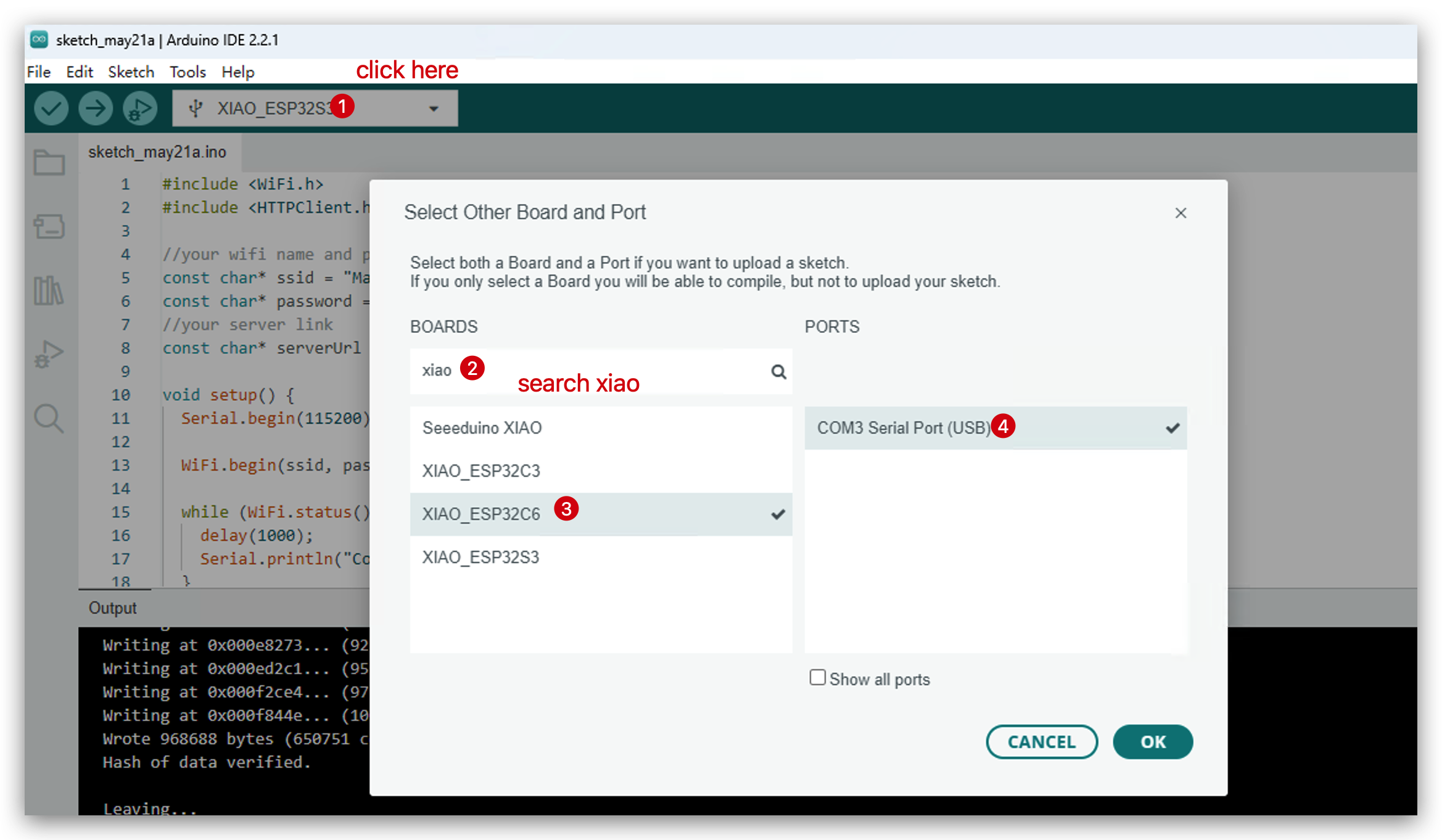
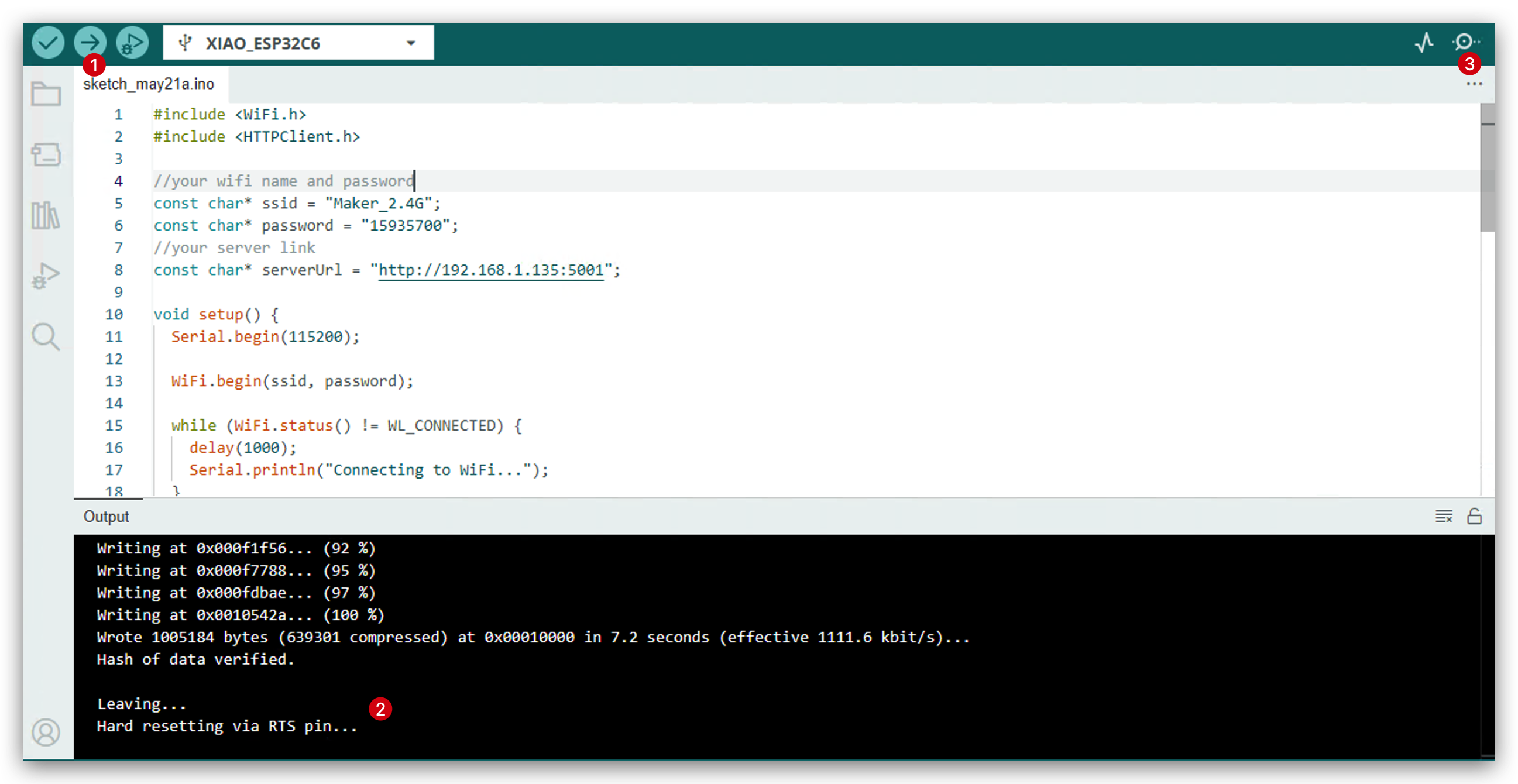
- Faça o upload do código e abra o monitor serial.
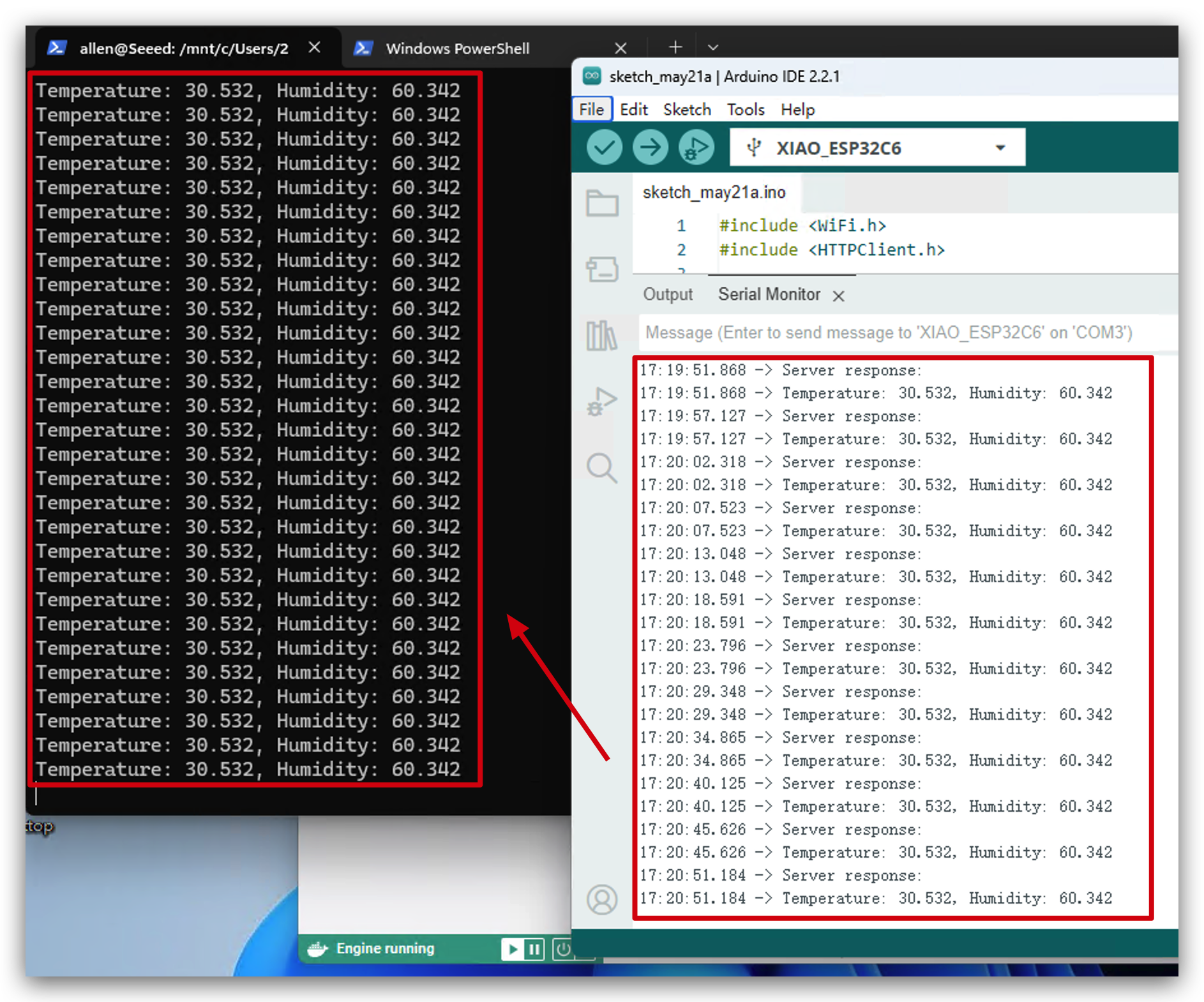
- Abra o Windows PowerShell em que o kafka está em execução. Agora você verá que os dados de ambiente estão sendo enviados para o Kafka. Parabéns! Você executou este projeto com sucesso!
Recursos
- [Link] Introdução ao Apache Kafka
Suporte Técnico & Discussão de Produto
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.