Implantando Modelos de Conjuntos de Dados para o XIAO ESP32S3
Bem-vindo a este tutorial abrangente em que embarcaremos em uma jornada para transformar seu conjunto de dados em um modelo totalmente funcional para implantação no XIAO ESP32S3. Neste guia, navegaremos pelos passos iniciais de rotulagem do nosso conjunto de dados com as ferramentas intuitivas do Roboflow, avançando para o treinamento do modelo dentro do ambiente colaborativo do Google Colab.
Em seguida, passaremos para a implantação do nosso modelo treinado usando o SenseCraft Model Assistant, um processo que faz a ponte entre o treinamento e a aplicação no mundo real. Ao final deste tutorial, você não só terá um modelo personalizado rodando no XIAO ESP32S3, como também estará equipado com o conhecimento para interpretar e utilizar os resultados das previsões do seu modelo.
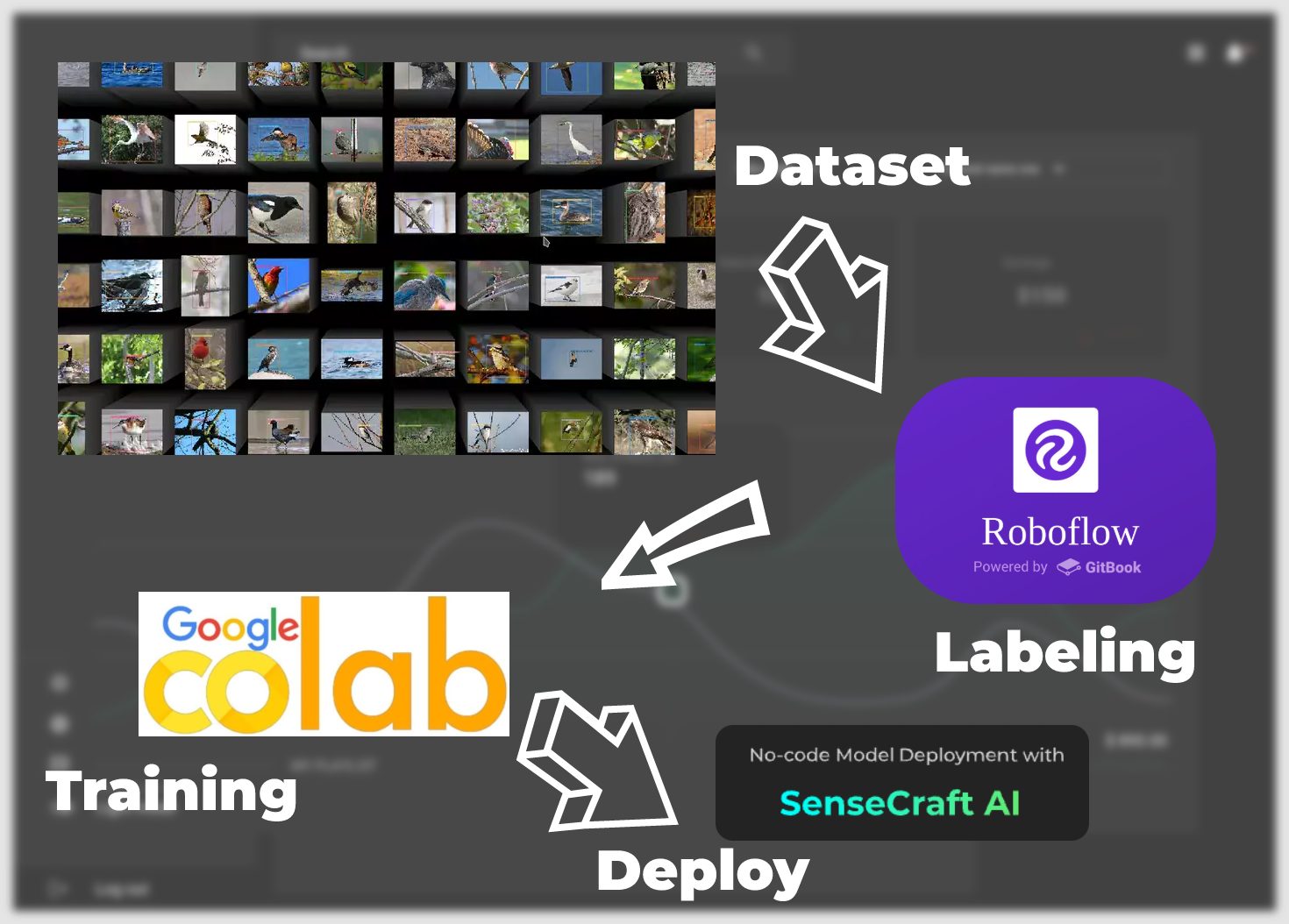
Do conjunto de dados ao modelo em execução, teremos as seguintes etapas principais.
-
Conjuntos de Dados Rotulados —— Este capítulo foca em como obter conjuntos de dados que possam ser treinados em modelos. Existem duas maneiras principais de fazer isso. A primeira é usar os conjuntos de dados rotulados fornecidos pela comunidade Roboflow, e a outra é usar suas próprias imagens específicas de cenário como conjuntos de dados, mas você precisa realizar manualmente todo o processo de rotulagem.
-
Treinar Modelo Exportado do Conjunto de Dados —— Este capítulo foca em como treinar para obter um modelo que possa ser implantado no XIAO ESP32S3 com base no conjunto de dados obtido na primeira etapa, usando a plataforma Google Colab.
-
Carregar modelos via SenseCraft Model Assistant —— Esta seção descreve como usar o arquivo de modelo exportado para carregar o modelo no XIAO ESP32S3 usando o SenseCraft Model Assistant.
-
Protocolos comuns e aplicações do modelo —— Por fim, apresentaremos o formato unificado de comunicação de dados do SenseCraft AI para que você possa aproveitar ao máximo o potencial dos seus dispositivos e modelos para criar aplicações que se encaixem nos seus cenários.
Então vamos nos aprofundar e começar o empolgante processo de dar vida aos seus dados.
Materiais Necessários
Antes de começar, talvez seja necessário preparar os seguintes equipamentos.
| Seeed Studio XIAO ESP32S3 | Seeed Studio XIAO ESP32S3 Sense |
|---|---|
 |  |
Tanto as versões XIAO ESP32S3 quanto Sense podem ser usadas como conteúdo para este tutorial, mas como a versão padrão do produto não permite o uso da placa de expansão de câmera, recomendamos que você use a versão Sense.
Conjuntos de Dados Rotulados
No conteúdo desta seção, permitimos que os usuários escolham livremente os conjuntos de dados que possuem. Isso inclui fotos da comunidade ou fotos próprias da cena. Este tutorial apresentará os dois cenários dominantes. O primeiro é usar conjuntos de dados rotulados prontos fornecidos pela comunidade Roboflow. O outro é usar imagens de alta resolução que você tirou e rotulou no conjunto de dados. Leia os diferentes tutoriais abaixo de acordo com suas necessidades.
Etapa 1: Crie uma conta gratuita no Roboflow
Roboflow fornece tudo o que você precisa para rotular, treinar e implantar soluções de visão computacional. Para começar, crie uma conta gratuita no Roboflow.
Depois de revisar e aceitar os termos de serviço, você será solicitado a escolher entre um de dois planos: o Plano Público e o Plano Starter.
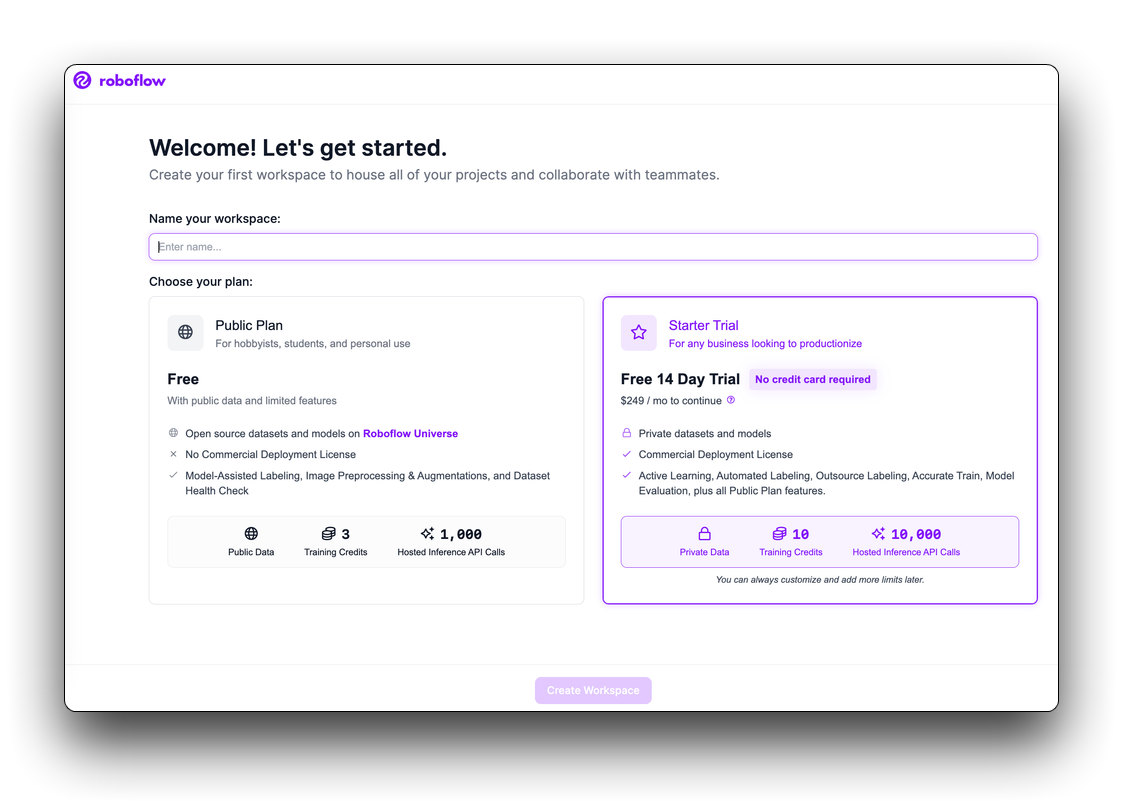
Em seguida, será solicitado que você convide colaboradores para o seu workspace. Esses colaboradores podem ajudá-lo a anotar imagens ou gerenciar os projetos de visão no seu workspace. Depois de convidar pessoas para o seu workspace (se desejar), você poderá criar um projeto.
Escolha como obter seu conjunto de dados
- Baixar Conjuntos de Dados Rotulados usando Roboflow
- Use your own images as a dataset
Escolher um conjunto de dados adequado do Roboflow para uso direto envolve determinar o conjunto de dados que melhor se encaixa nos requisitos do seu projeto, considerando aspectos como tamanho, qualidade, relevância e licença do conjunto de dados.
Etapa 2. Explore o Roboflow Universe
Roboflow Universe é uma plataforma onde você pode encontrar vários conjuntos de dados. Visite o site do Roboflow Universe e explore os conjuntos de dados disponíveis.
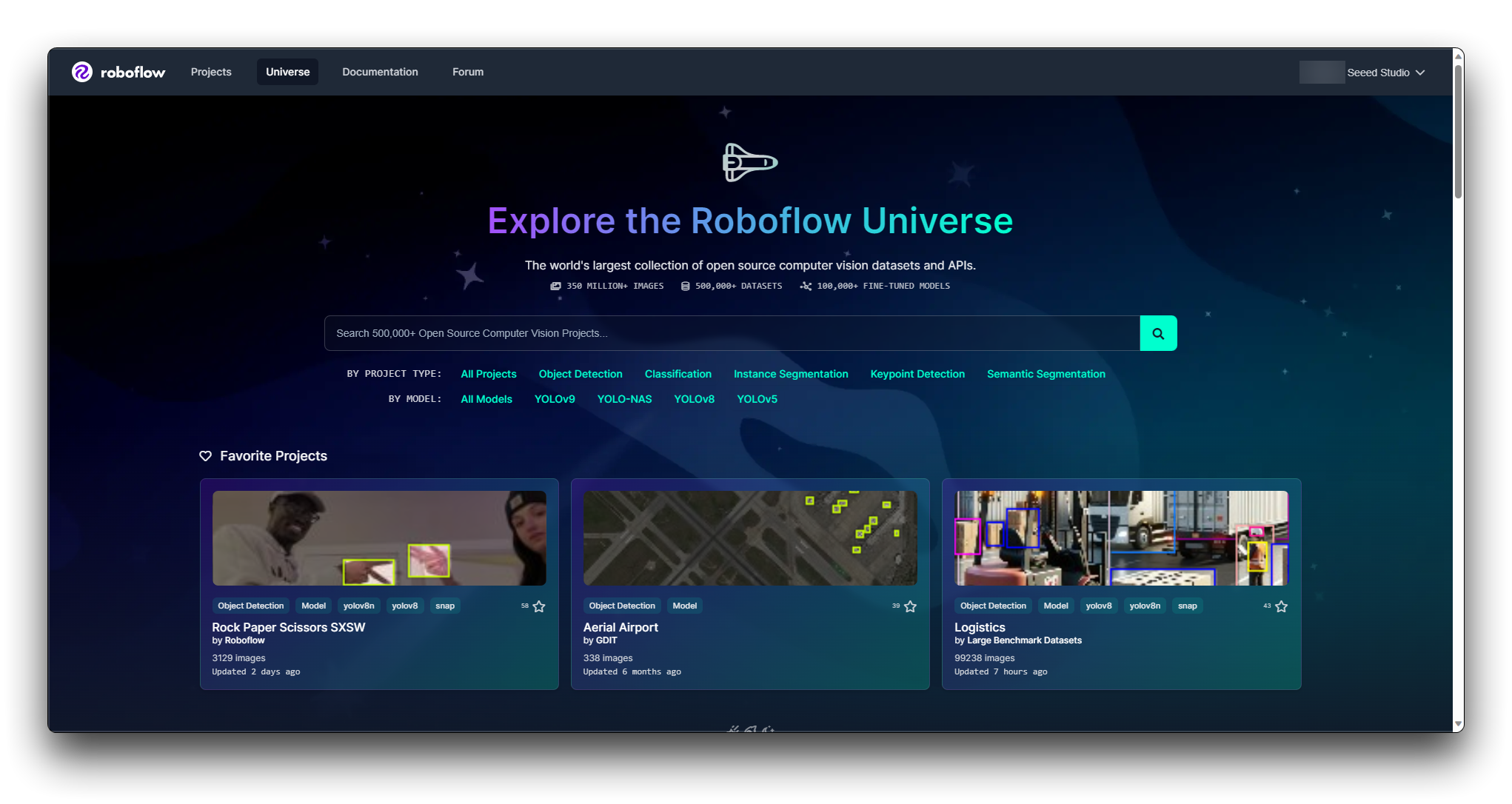
Roboflow fornece filtros e uma função de pesquisa para ajudá-lo a encontrar conjuntos de dados. Você pode filtrar conjuntos de dados por domínio, número de classes, tipos de anotação e muito mais. Utilize esses filtros para reduzir os conjuntos de dados que atendem aos seus critérios.
Etapa 3. Avalie Conjuntos de Dados Individuais
Depois de ter uma lista reduzida, avalie cada conjunto de dados individualmente. Procure por:
Qualidade das Anotações: Verifique se as anotações são precisas e consistentes.
Tamanho do Conjunto de Dados: Certifique-se de que o conjunto de dados seja grande o suficiente para que seu modelo aprenda de forma eficaz, mas não tão grande a ponto de ser difícil de manipular.
Balanceamento de Classes: O conjunto de dados deve idealmente ter um número equilibrado de exemplos para cada classe.
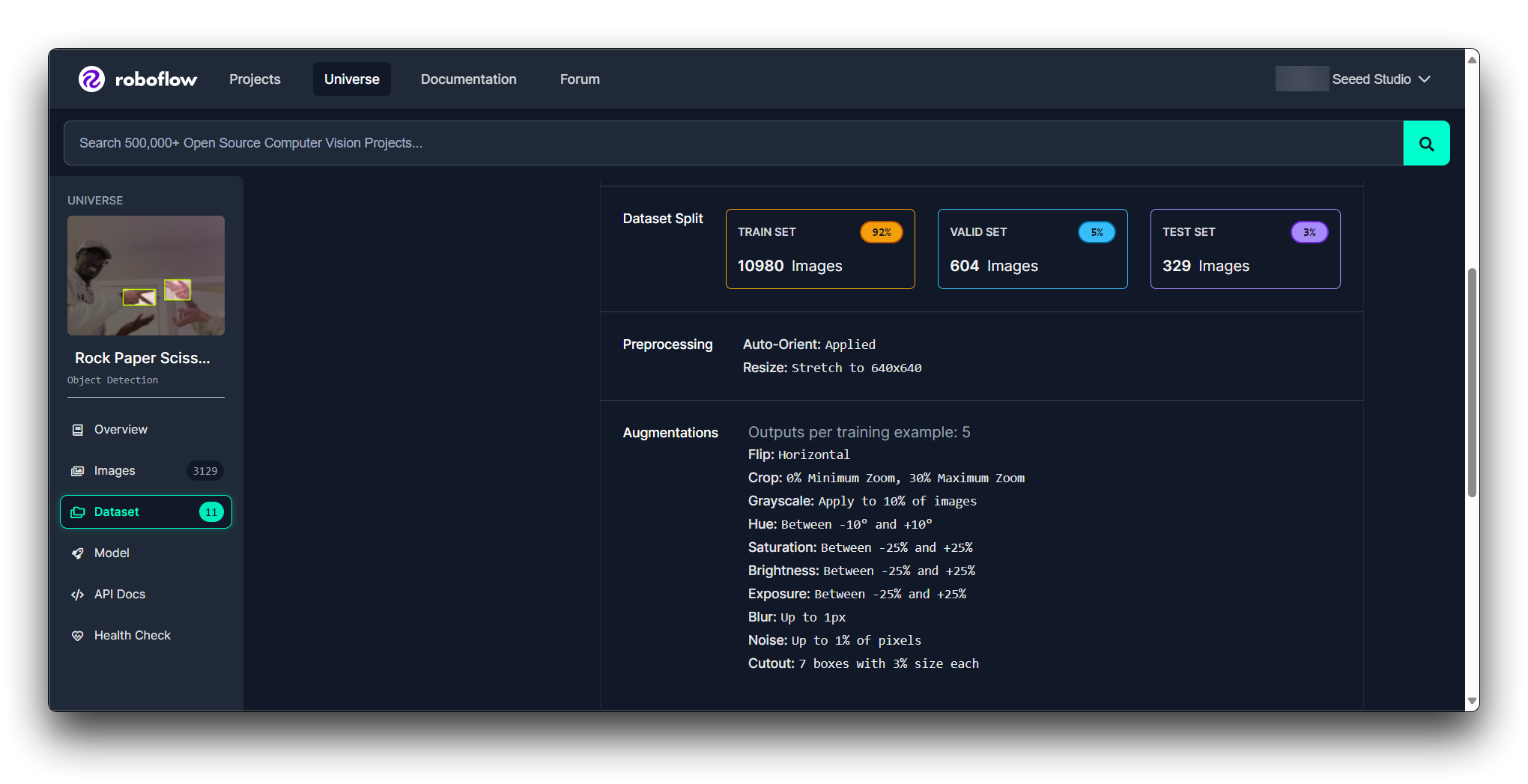
Licença: Revise a licença do conjunto de dados para garantir que você possa usá-lo conforme pretendido.
Documentação: Revise qualquer documentação ou metadados que acompanhem o conjunto de dados para entender melhor seu conteúdo e quaisquer etapas de pré-processamento que já tenham sido aplicadas.
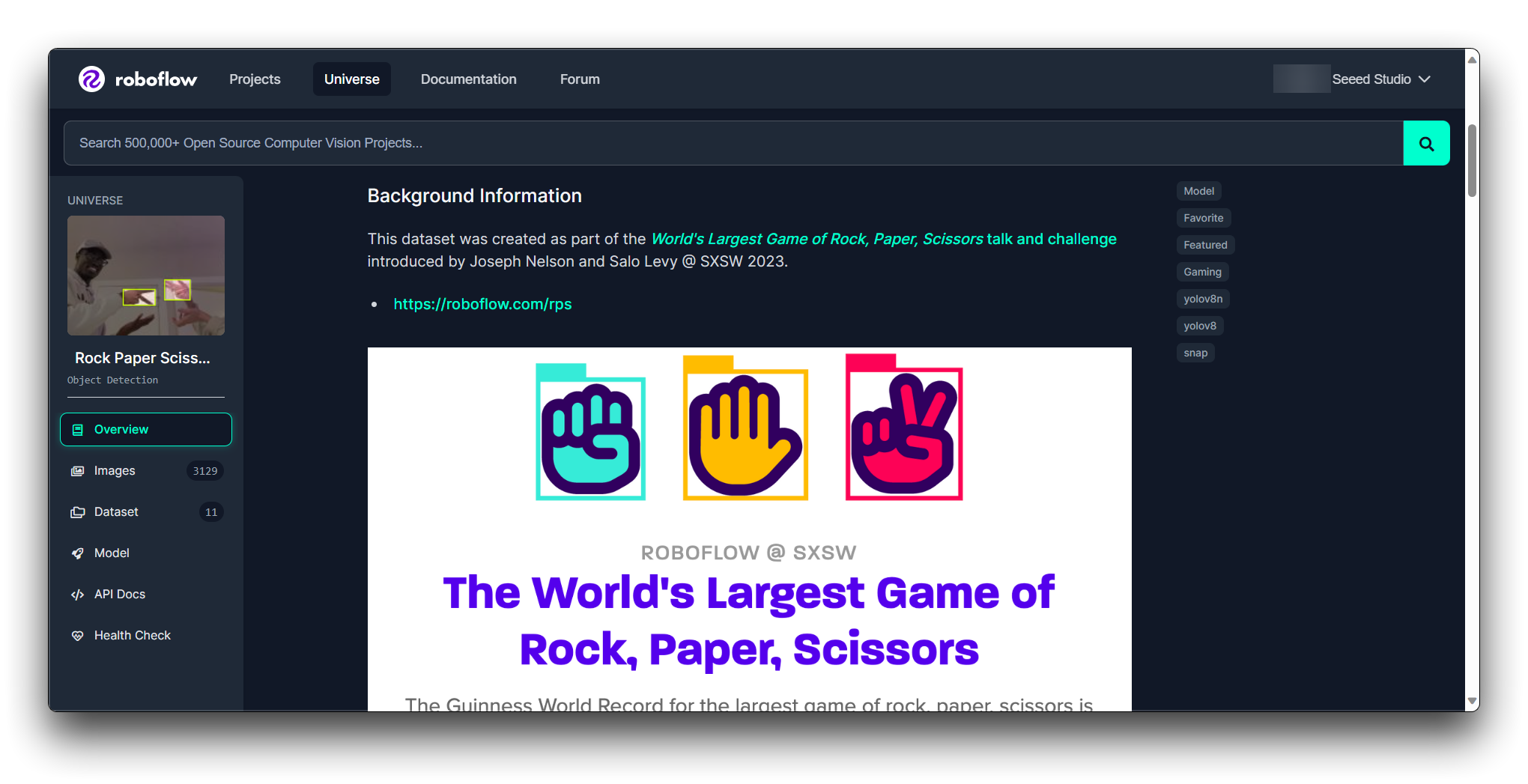
Você pode descobrir a condição do modelo por meio do Roboflow Health Check.
Etapa 4. Baixe a Amostra
Se você encontrar o conjunto de dados de sua escolha, então você tem a opção de baixá-lo e usá-lo. Normalmente, o Roboflow permite que você baixe uma amostra do conjunto de dados. Teste a amostra para ver se ela se integra bem ao seu fluxo de trabalho e se é adequada para o seu modelo.
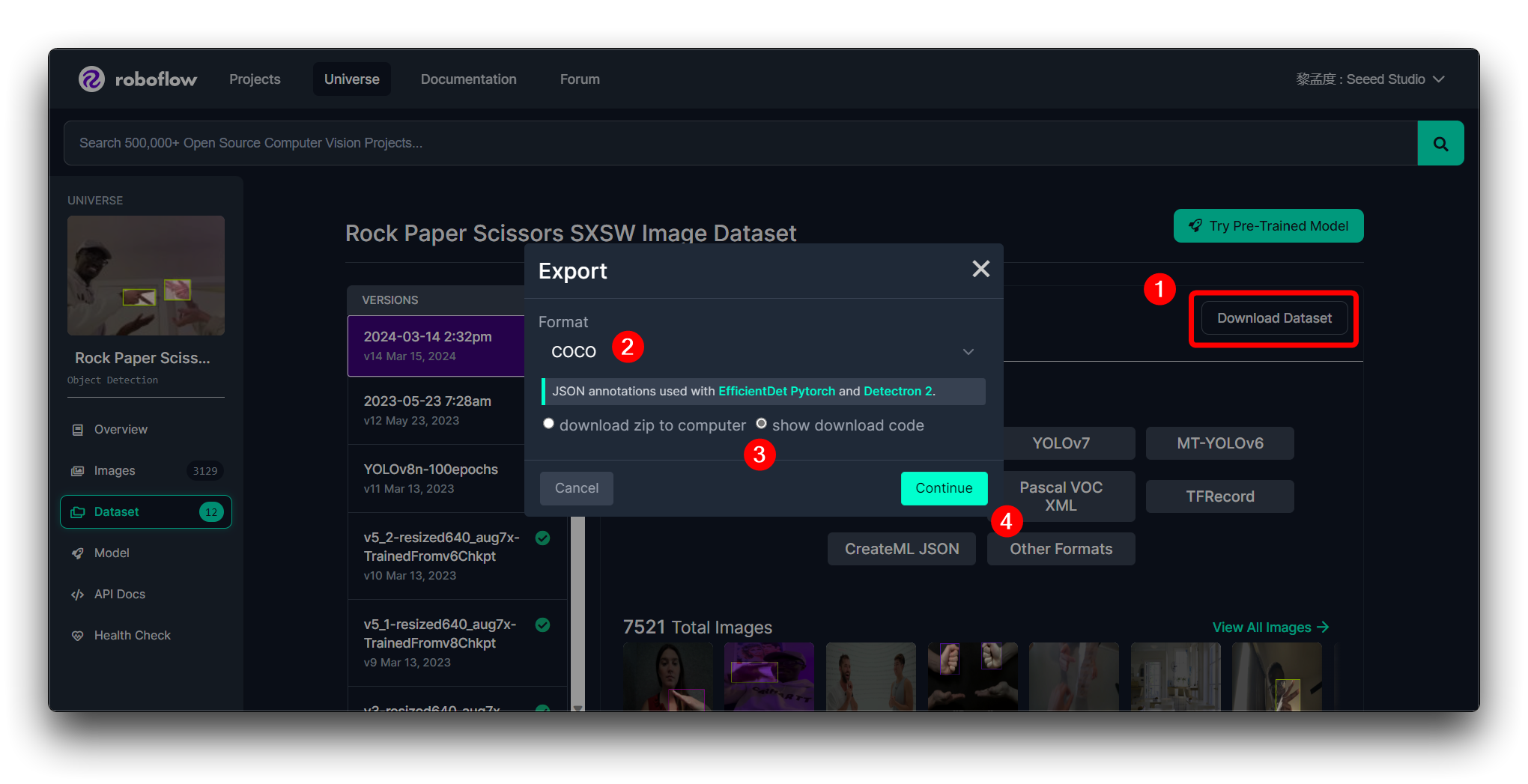
Para continuar com as etapas subsequentes, recomendamos que você exporte o conjunto de dados no formato mostrado abaixo.
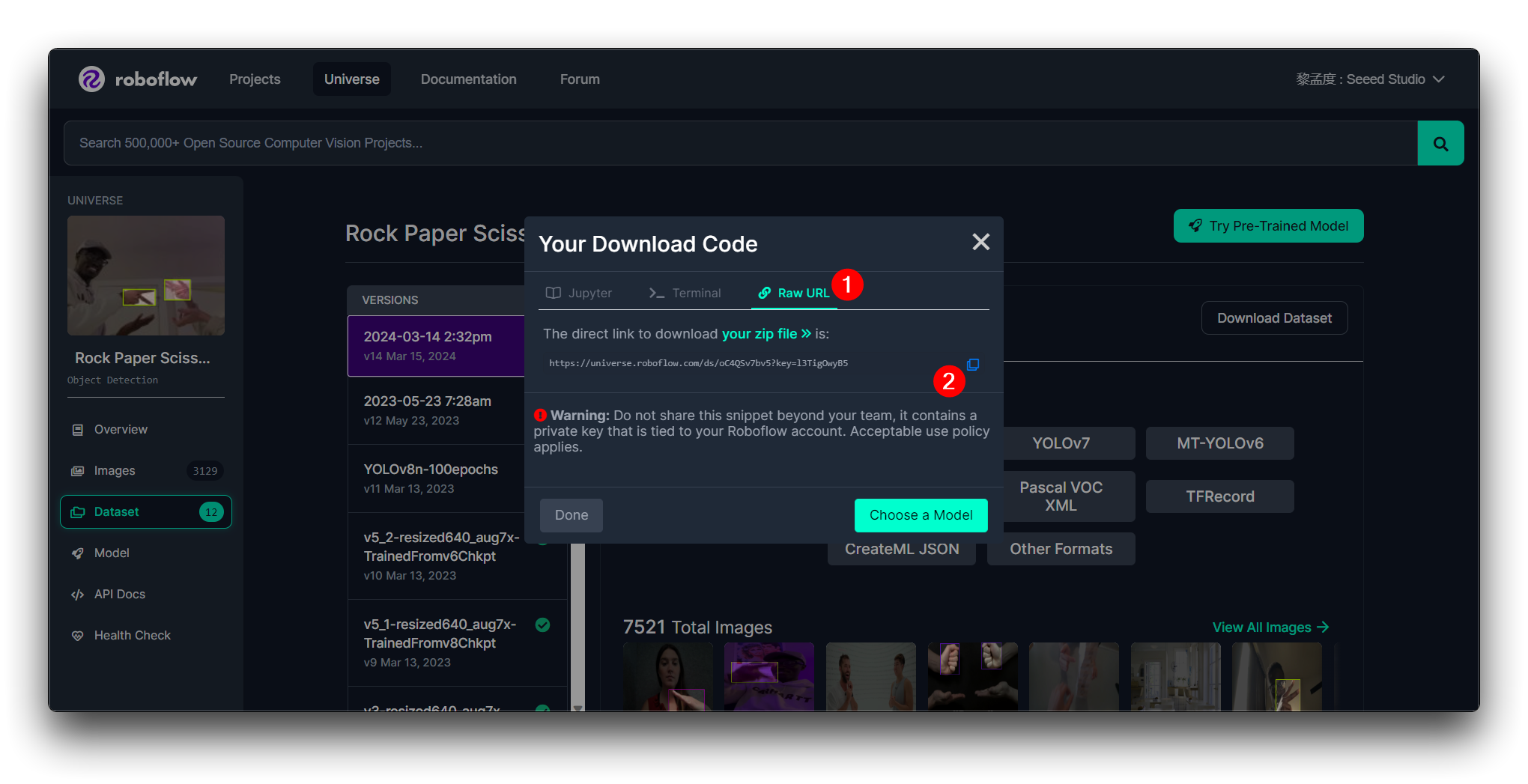
Você então obterá a Raw URL para este modelo, guarde-a com cuidado, usaremos esse link na etapa de treinamento do modelo um pouco mais adiante.
Se você estiver usando o Roboflow pela primeira vez e não tiver absolutamente nenhum julgamento sobre a seleção de conjuntos de dados, a etapa de treinar um modelo com um conjunto de dados para realizar um teste inicial para ver o desempenho pode ser essencial. Isso pode ajudá-lo a avaliar se o conjunto de dados atenderá às suas necessidades.
Se o conjunto de dados atender às suas necessidades e tiver um bom desempenho nos testes iniciais, então é provável que seja adequado para o seu projeto. Caso contrário, talvez seja necessário continuar a busca ou considerar expandir o conjunto de dados com mais imagens.
Aqui, usarei a imagem de gestos de pedra-papel-tesoura como demonstração para guiá-lo nas tarefas de upload de imagens, rotulagem e exportação de um conjunto de dados no Roboflow.
Recomendamos fortemente que você use o XIAO ESP32S3 para tirar fotos do seu conjunto de dados, o que é o melhor para o XIAO ESP32S3. Um programa de exemplo para o XIAO ESP32S3 Sense tirar fotos pode ser encontrado no link da Wiki abaixo.
Etapa 2. Criar um Novo Projeto e Fazer Upload de Imagens
Depois de fazer login no Roboflow, clique em Create Project.
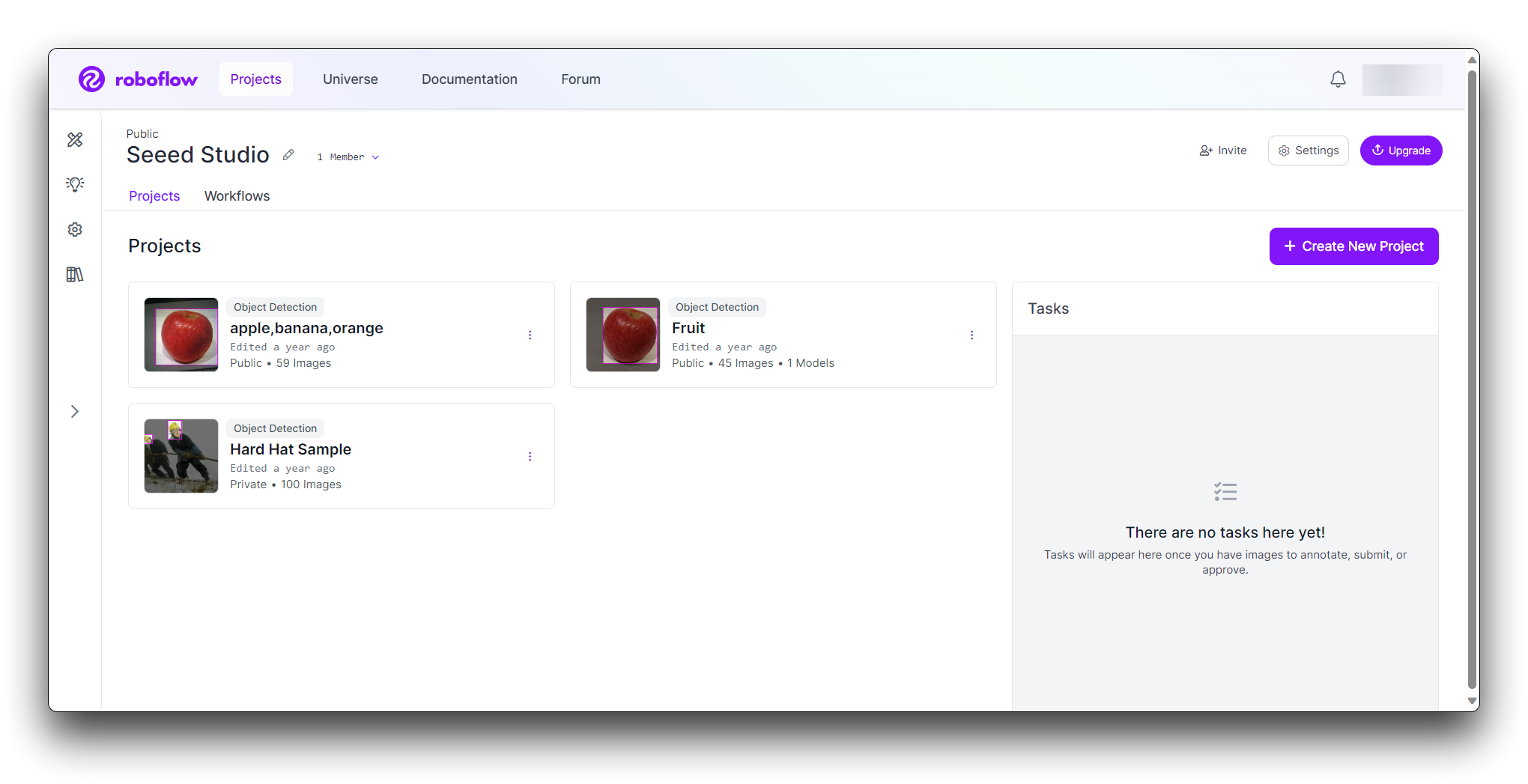
Dê um nome ao seu projeto (por exemplo, "Pedra-Papel-Tesoura"). Defina seu projeto como Object Detection. Defina os Output Labels como Categorical (já que Pedra, Papel e Tesoura são categorias distintas).
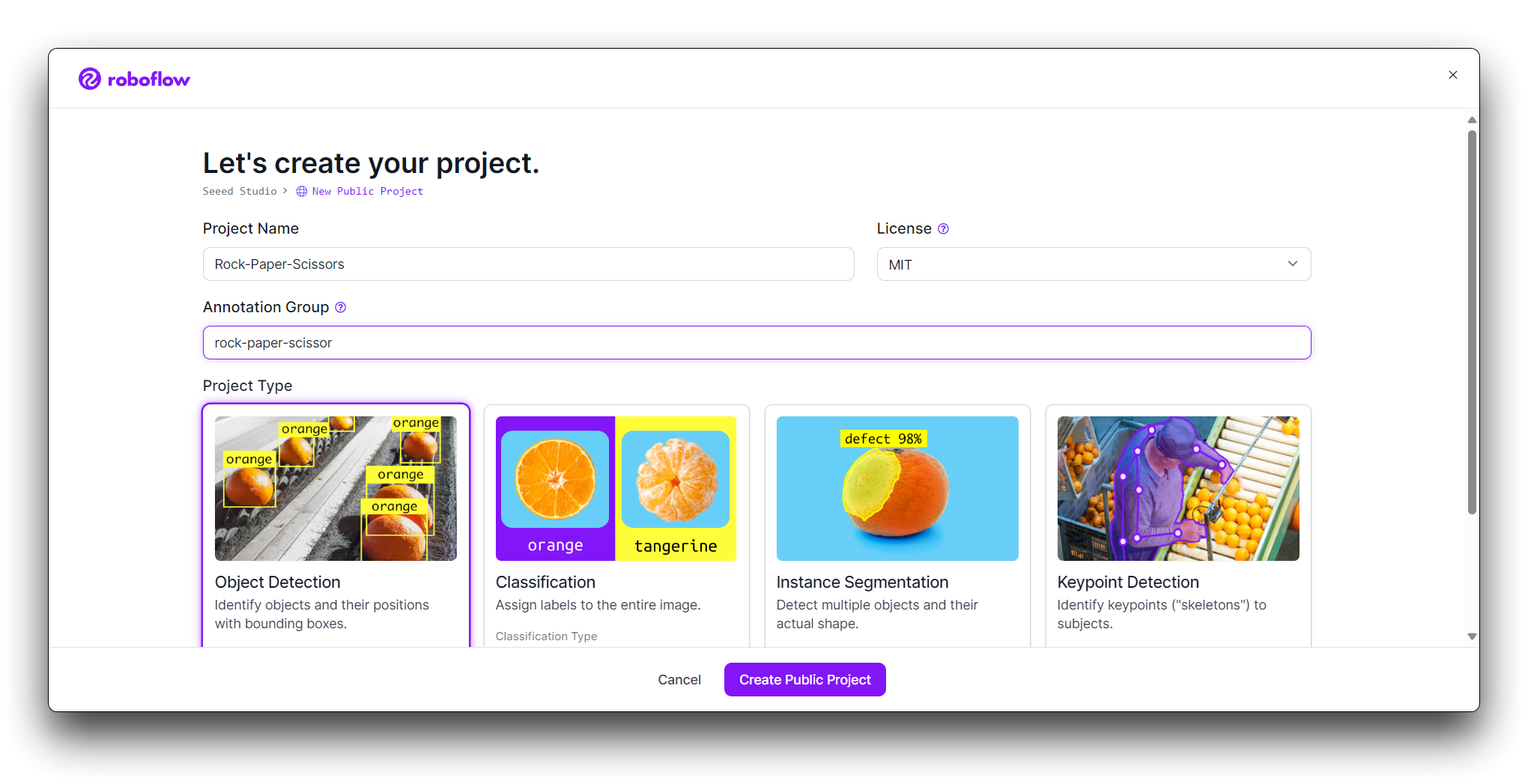
Agora é hora de enviar suas imagens de gestos com a mão.
Colete imagens dos gestos de pedra, papel e tesoura. Certifique-se de ter uma variedade de planos de fundo e condições de iluminação. Na página do seu projeto, clique em "Add Images".
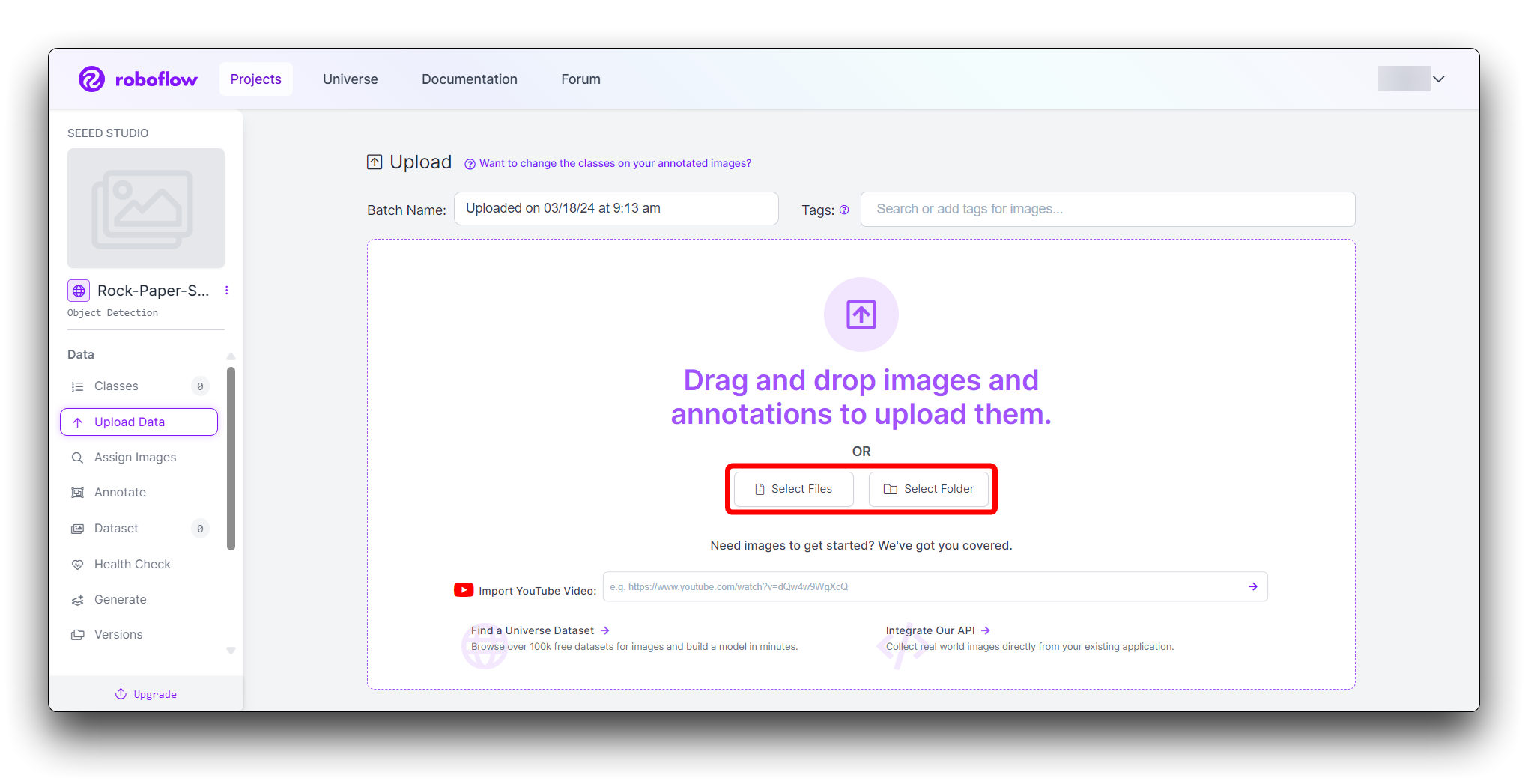
Você pode arrastar e soltar suas imagens ou selecioná-las no seu computador. Envie pelo menos 100 imagens de cada gesto para obter um conjunto de dados robusto.
Como o tamanho do conjunto de dados é determinado?
Ele geralmente depende de vários fatores: modelo da tarefa, complexidade da tarefa, pureza dos dados e assim por diante. Por exemplo, o modelo de detecção do corpo humano envolve um grande número de pessoas, uma grande variedade, a tarefa é mais complexa, então é necessário coletar mais dados. Outro exemplo é o modelo de detecção de gestos, que só precisa detectar os três tipos de "pedra", "tesoura" e "papel" (cloth), e requer menos categorias, portanto o conjunto de dados coletado é de cerca de 500.
Passo 3: Anotando Imagens
Depois de enviar, você precisará anotar as imagens rotulando os gestos das mãos.
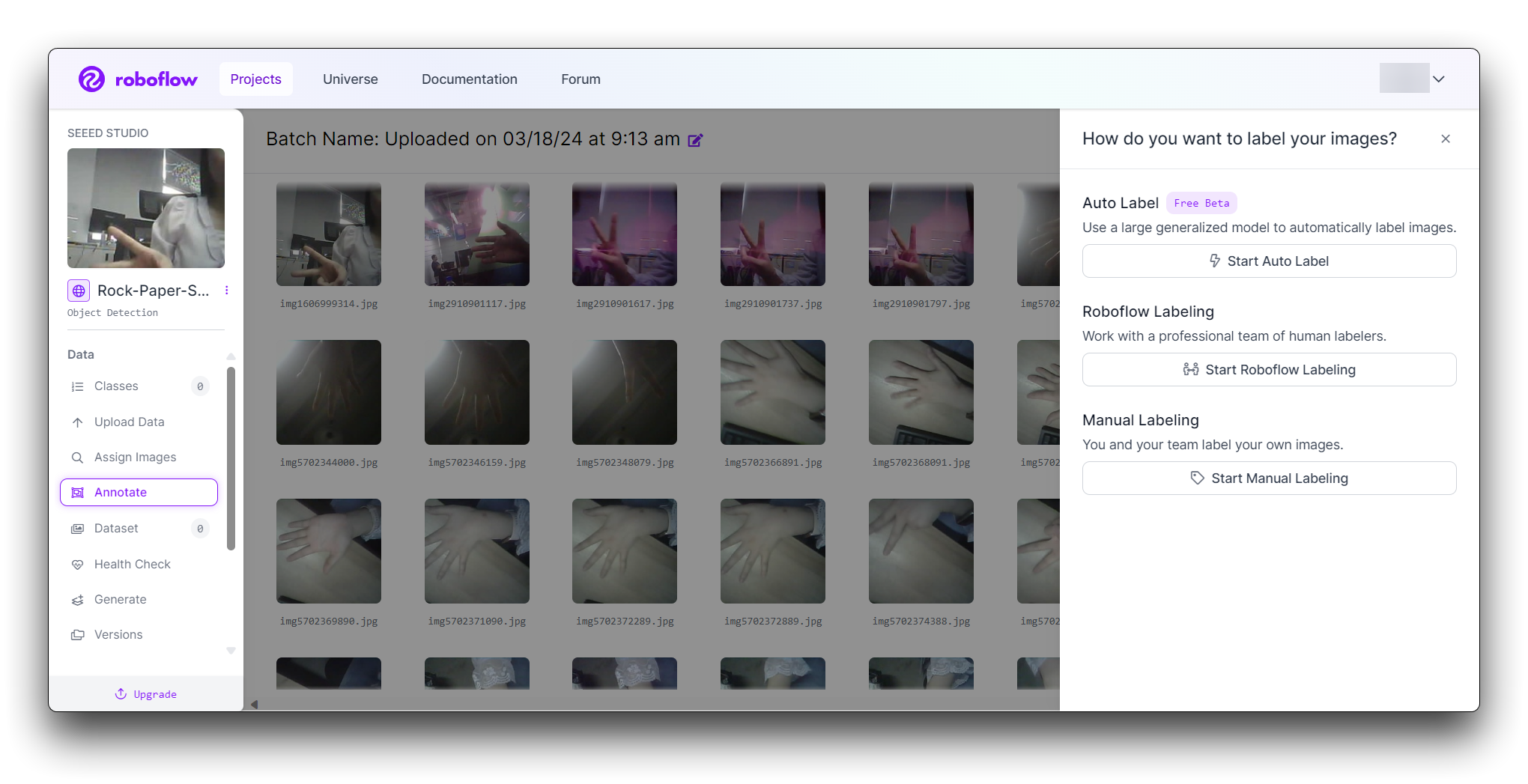
O Roboflow oferece três maneiras diferentes de rotular imagens: Auto Label, Roboflow Labeling e Manual Labeling.
- Auto Label: Usa um grande modelo generalizado para rotular automaticamente as imagens.
- Roboflow Labeling: Trabalhe com uma equipe profissional de anotadores humanos. Sem volumes mínimos. Sem compromissos antecipados. As anotações de Bounding Box começam em $0,04 e as anotações de Polígono começam em $0,08.
- Manual Labeling: Você e sua equipe rotulam suas próprias imagens.
A seguir é descrito o método mais usado de rotulagem manual.
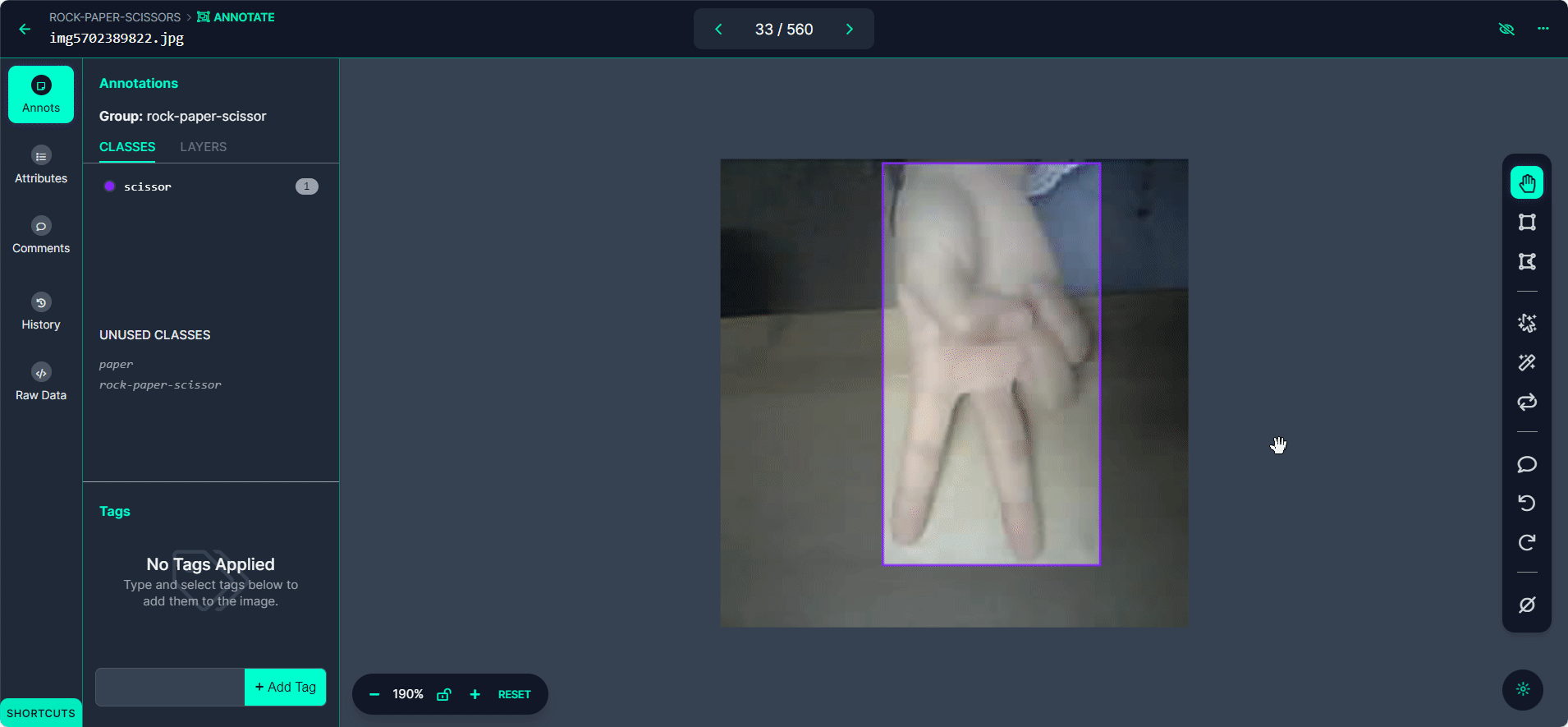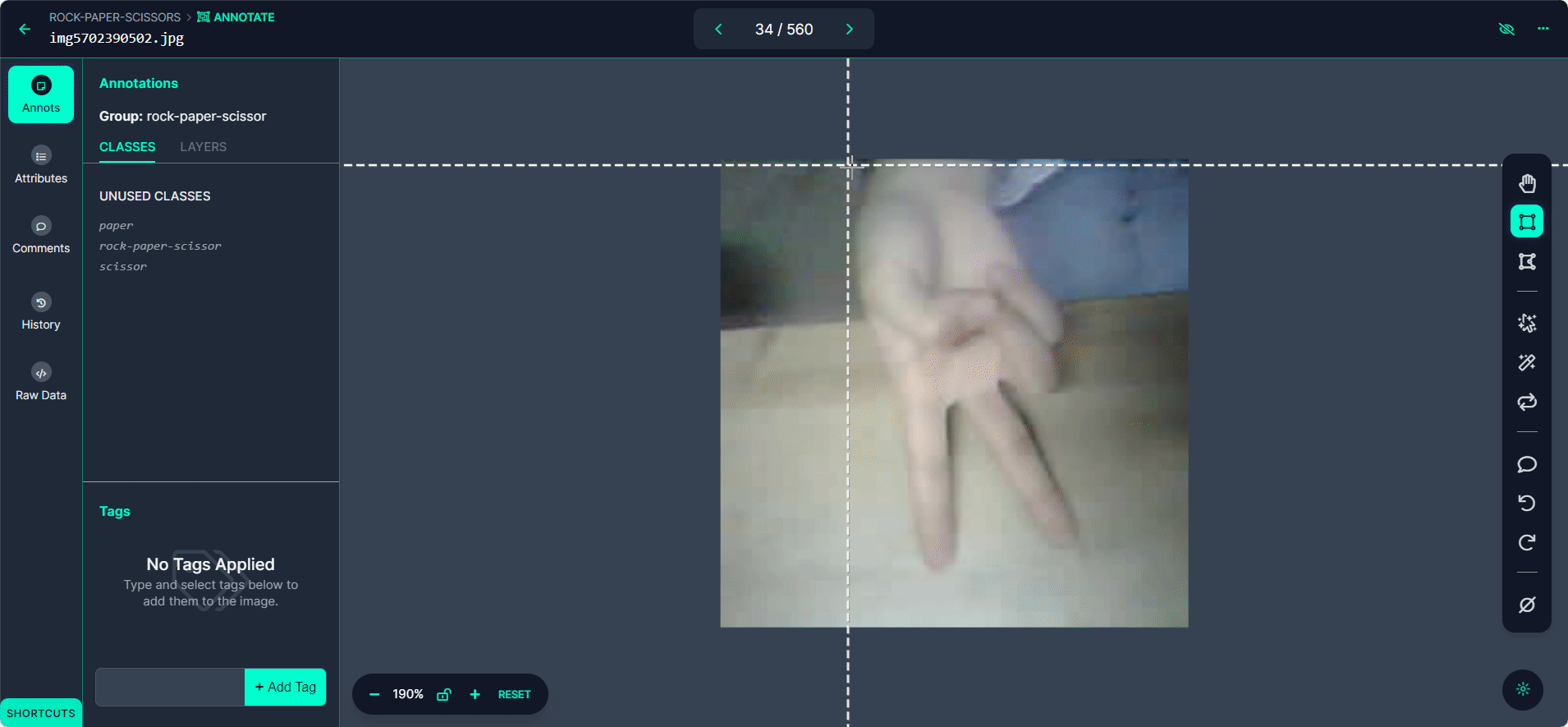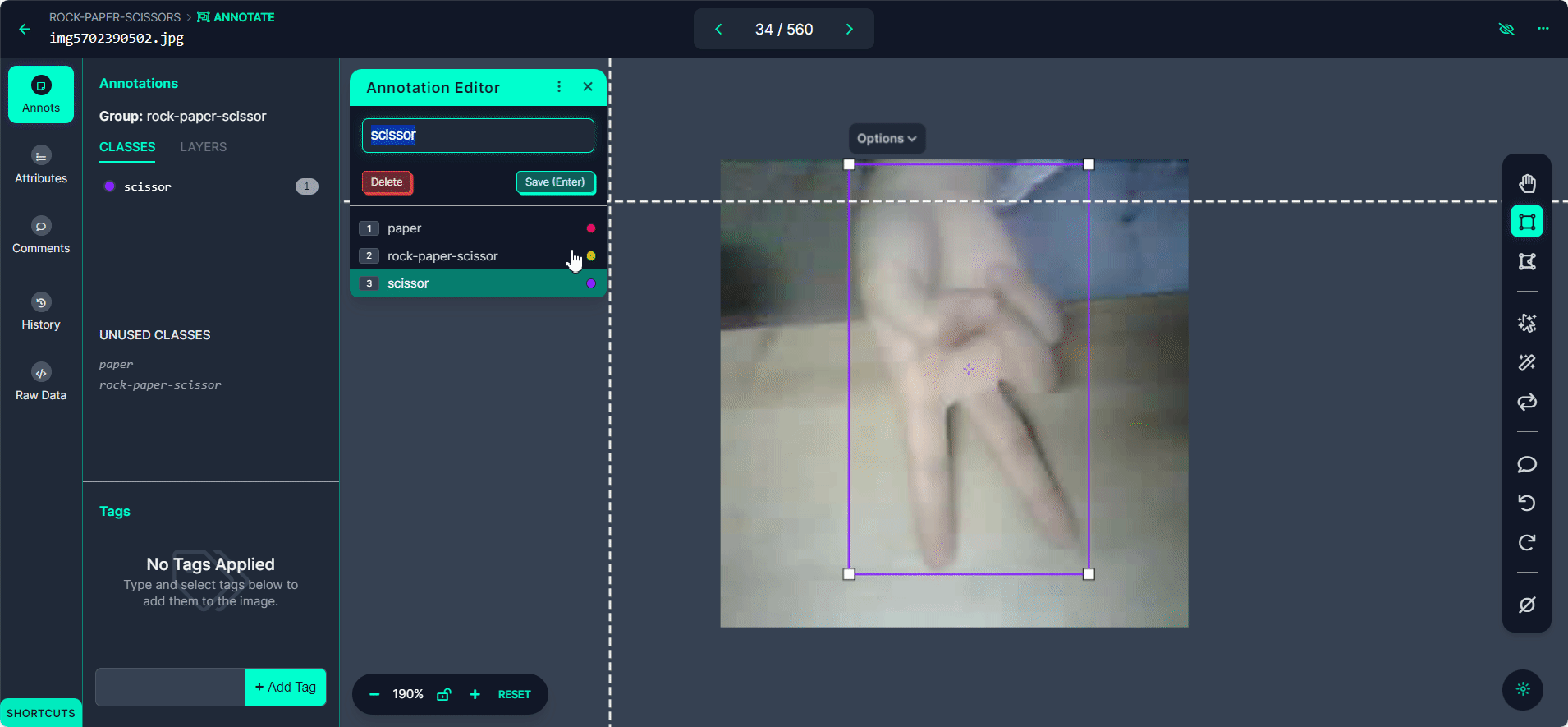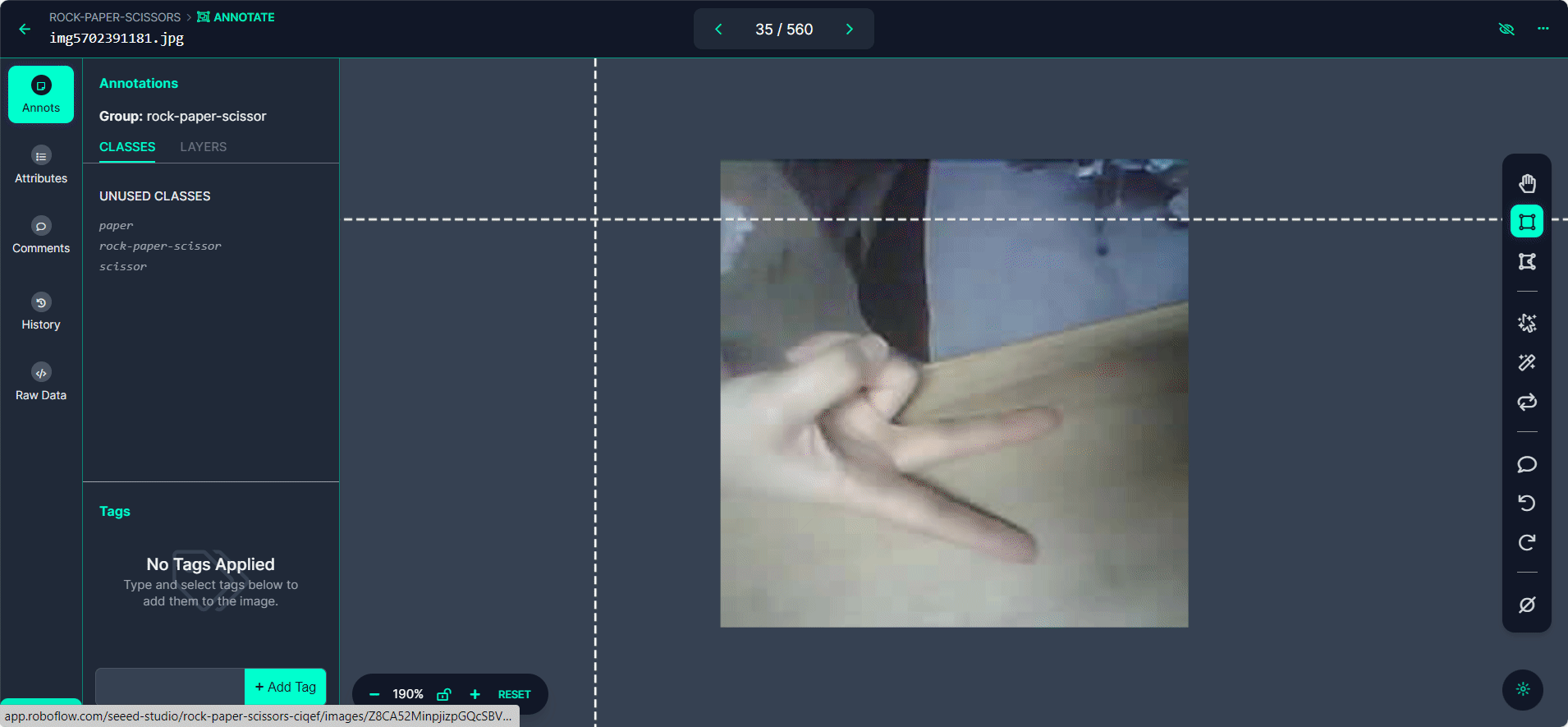
Clique no botão "Manual Labeling". O Roboflow carregará a interface de anotação.
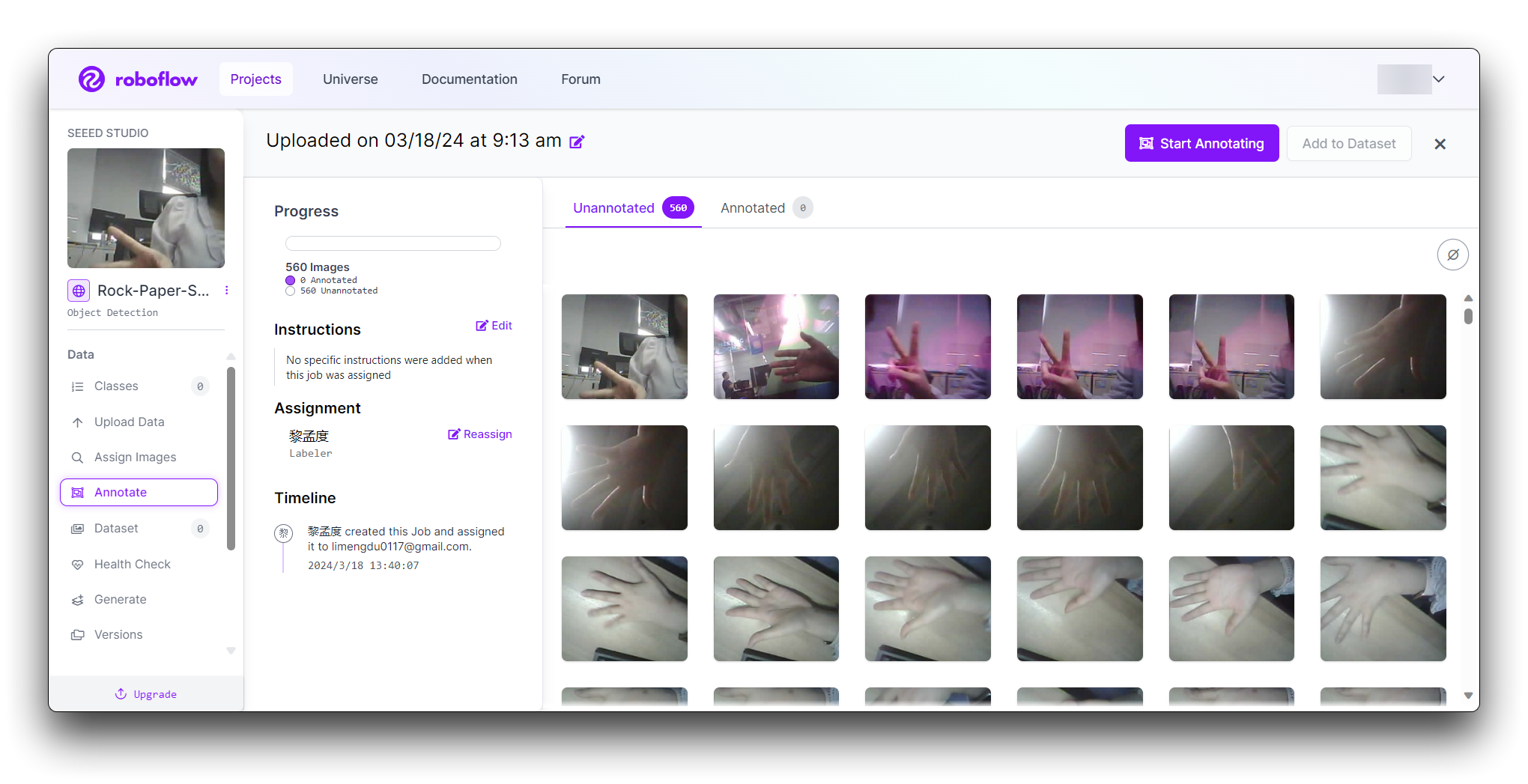
Selecione o botão "Start Annotating". Desenhe caixas delimitadoras ao redor do gesto da mão em cada imagem.
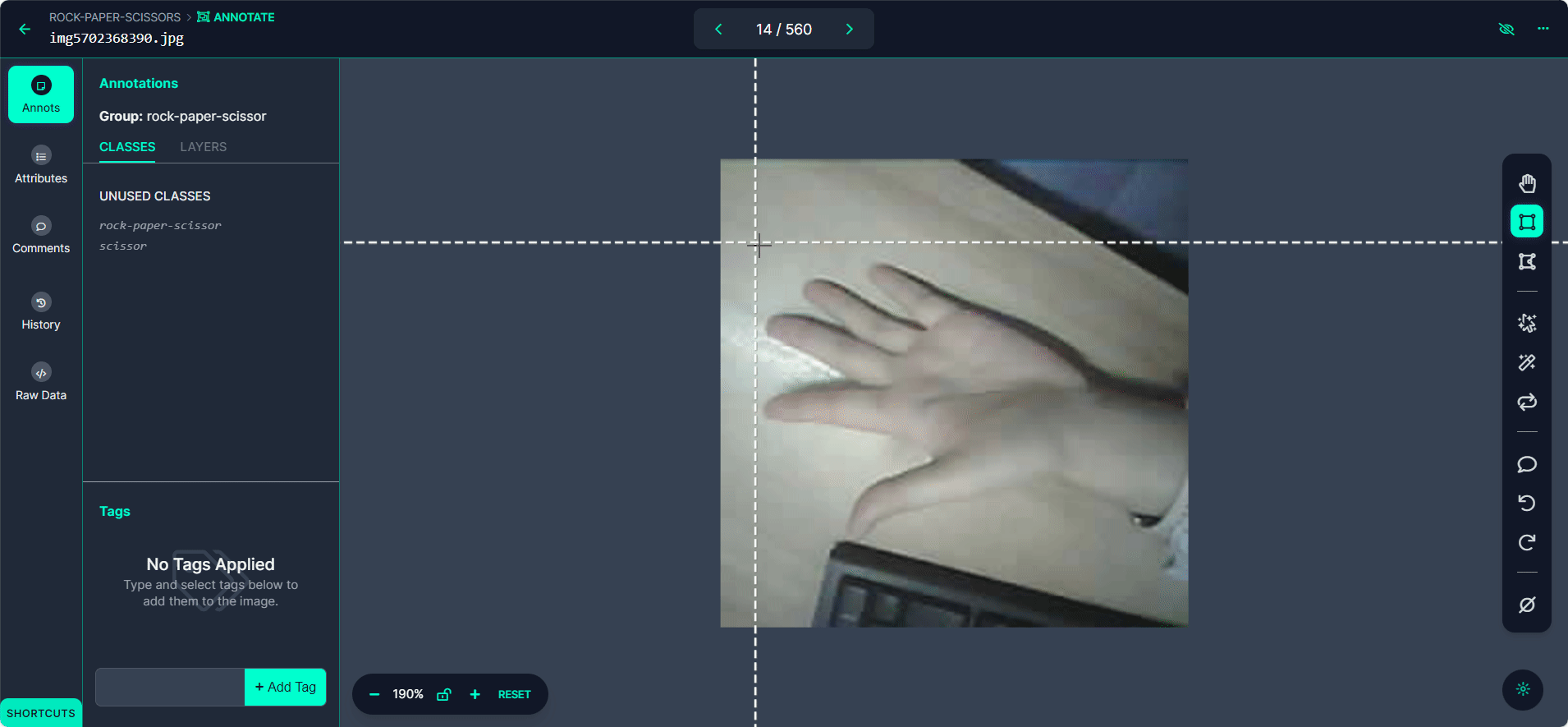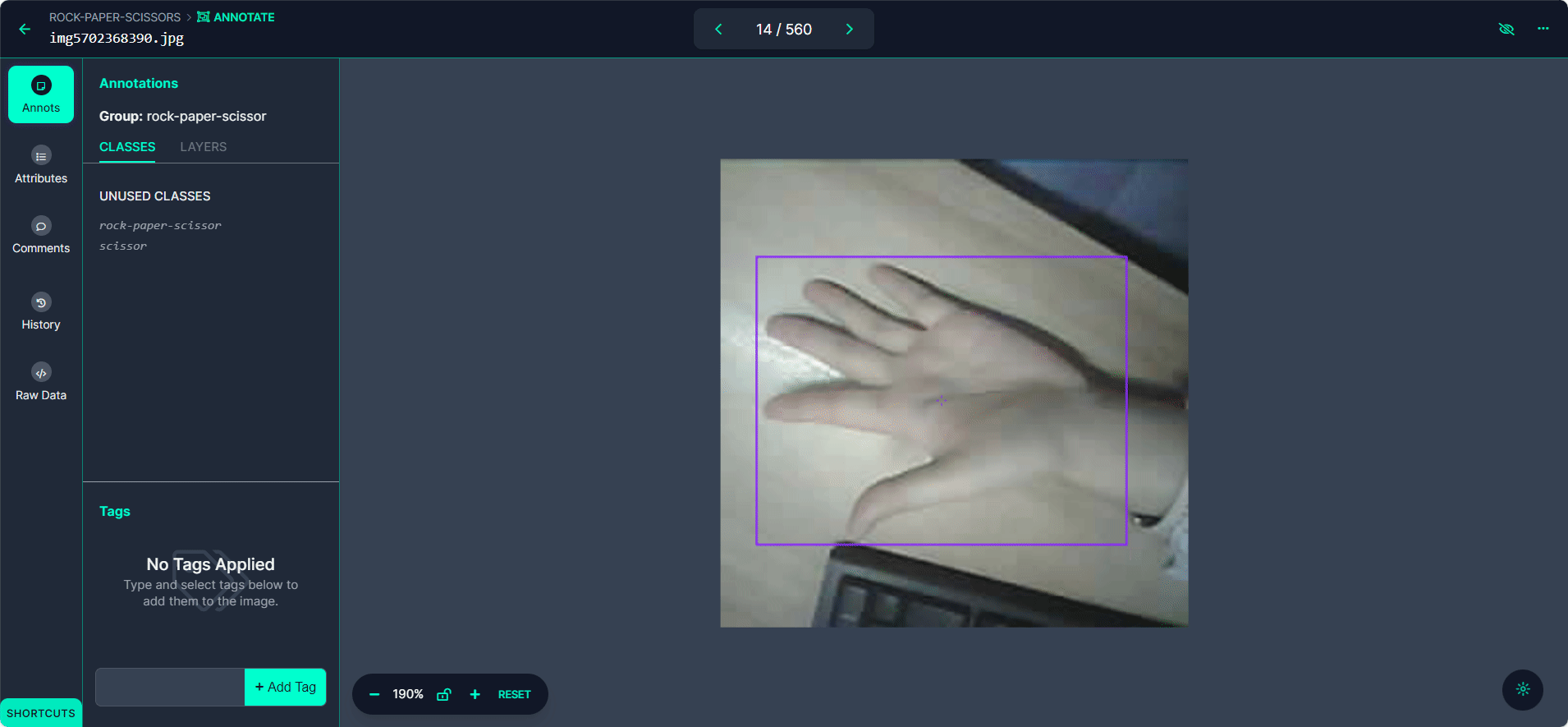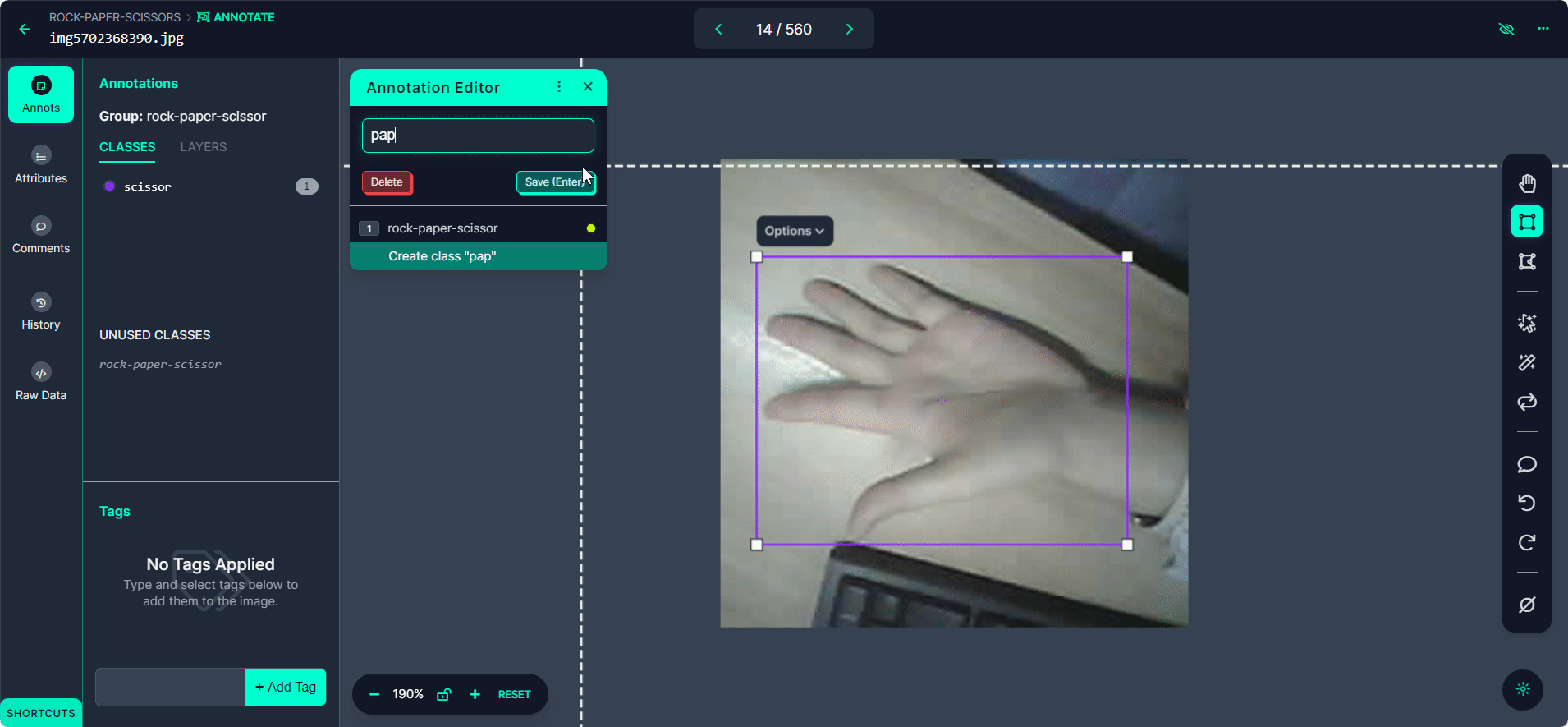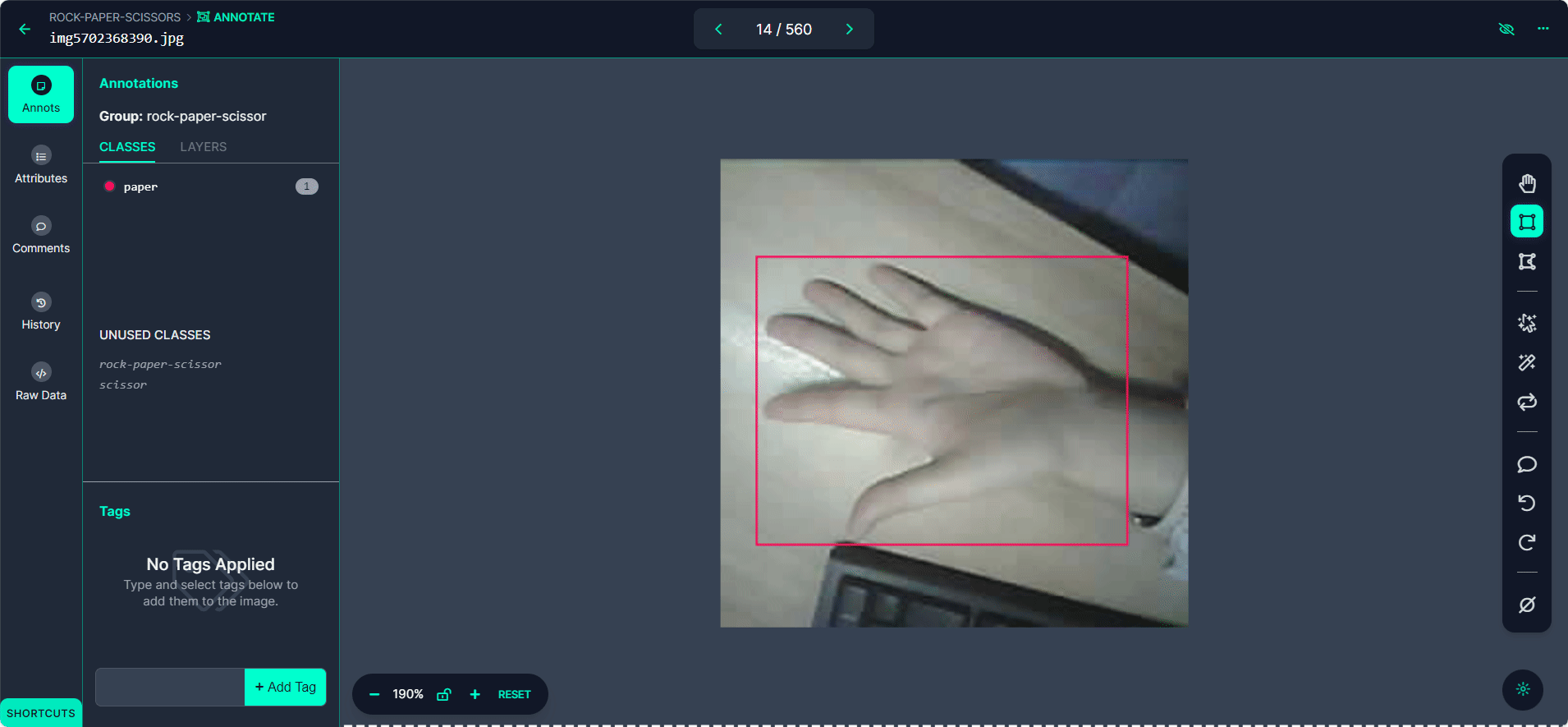
Rotule cada caixa delimitadora como "Rock", "Paper" ou "Scissors".
Use o botão ">" para percorrer seu conjunto de dados, repetindo o processo de anotação para cada imagem.
Passo 4: Revisar e Editar Anotações
É essencial garantir que as anotações estejam corretas.
Revise cada imagem para garantir que as caixas delimitadoras estejam desenhadas e rotuladas corretamente. Se você encontrar algum erro, selecione a anotação para ajustar a caixa delimitadora ou alterar o rótulo.
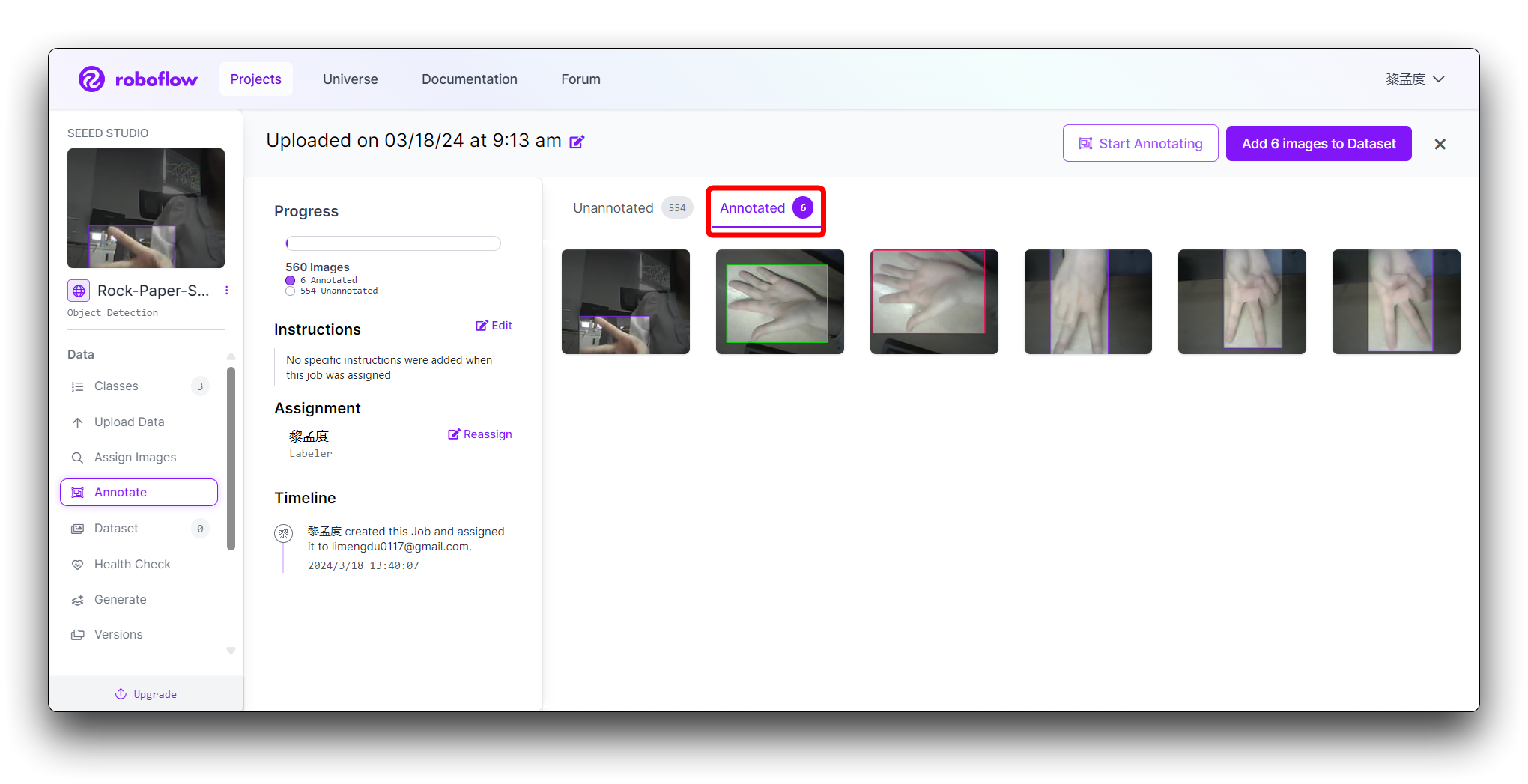
A rotulagem incorreta afeta o desempenho geral do treinamento e alguns conjuntos de dados podem ser descartados se não atenderem aos requisitos de rotulagem. Aqui estão algumas demonstrações de má rotulagem.

Passo 5: Gerando e Exportando o Conjunto de Dados
Depois que todas as imagens forem anotadas. Em Annotate clique no botão Add x images to Dataset no canto superior direito.
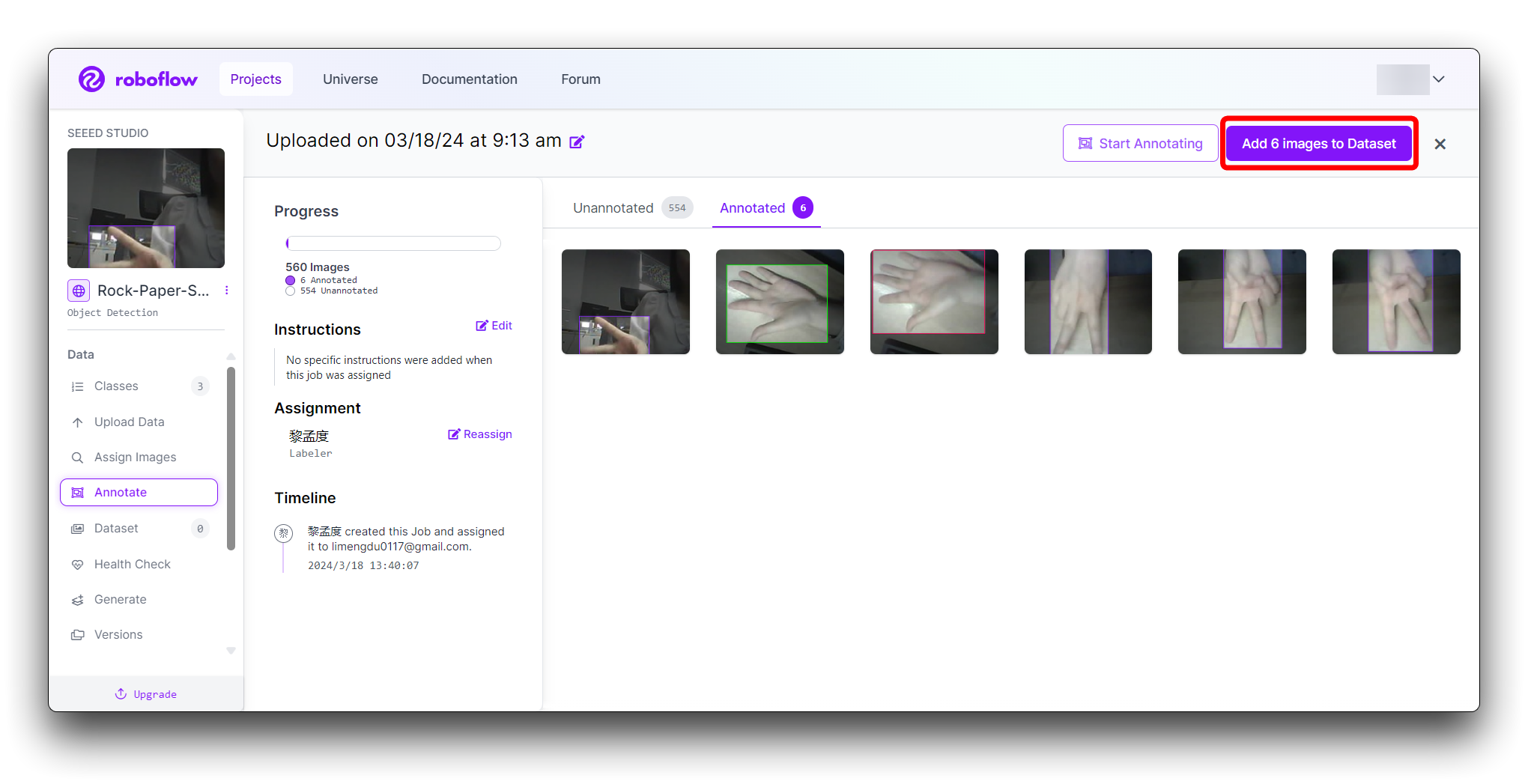
Em seguida, clique no botão Add Images na parte inferior da nova janela pop-up.
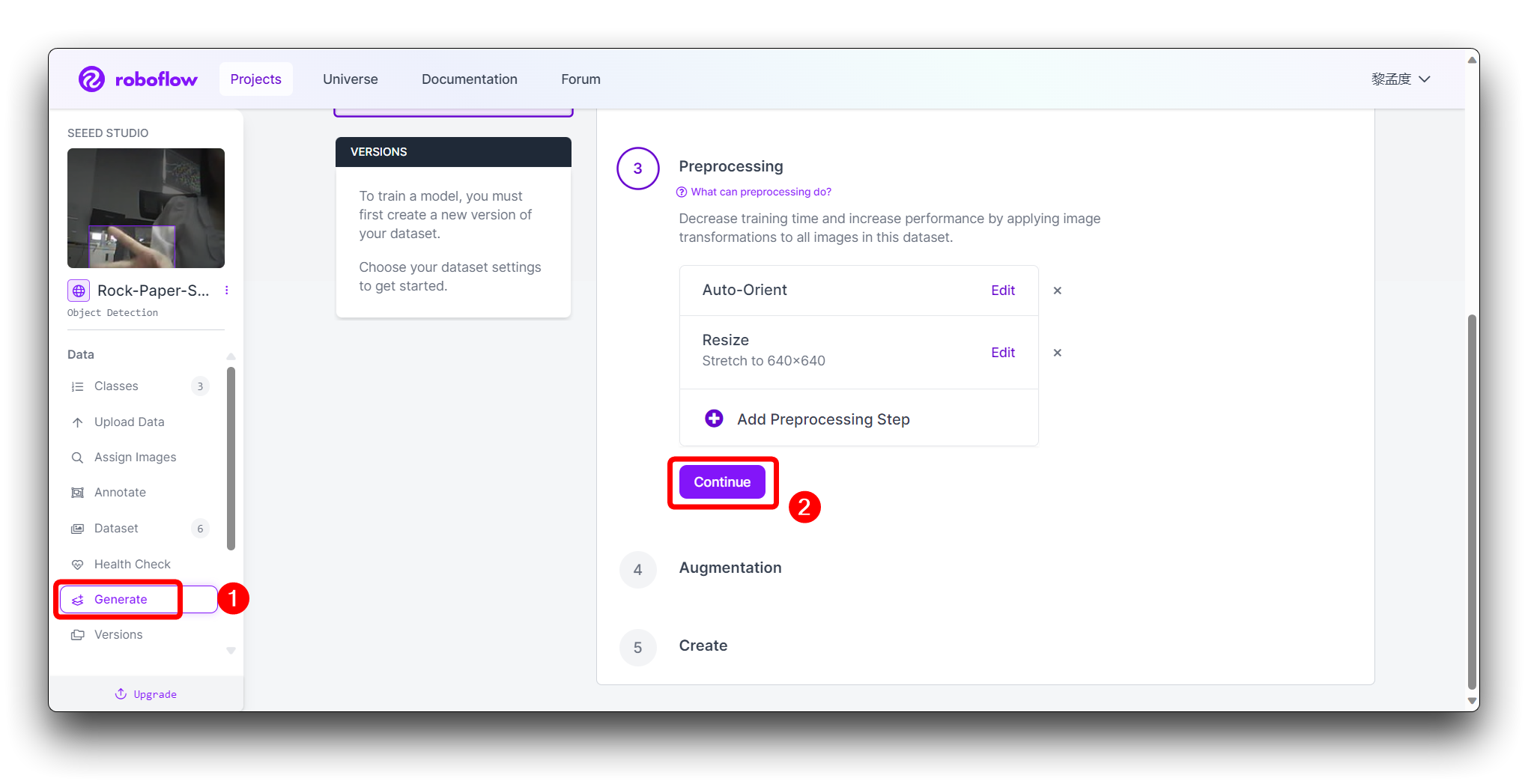
Clique em Generate na barra de ferramentas à esquerda e clique em Continue na terceira etapa Preprocessing.
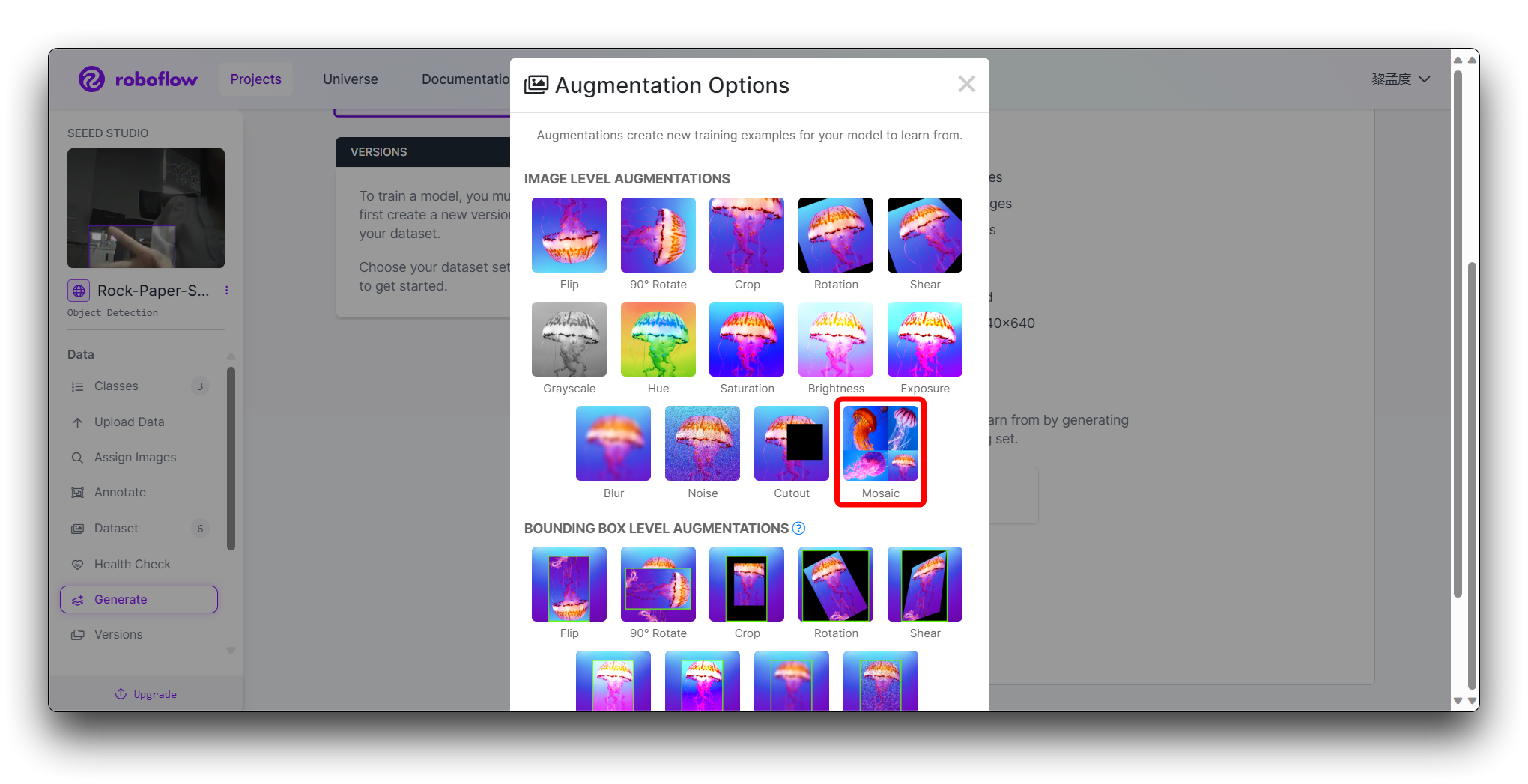
Na etapa Augmentation no passo 4, selecione Mosaic, o que aumenta a capacidade de generalização.
Na etapa final Create, calcule de forma razoável o número de imagens de acordo com o boost do Roboflow; em geral, quanto mais imagens você tiver, mais tempo levará para treinar o modelo. No entanto, ter mais imagens não necessariamente tornará o modelo mais preciso; isso depende principalmente se o conjunto de dados é bom o suficiente ou não.
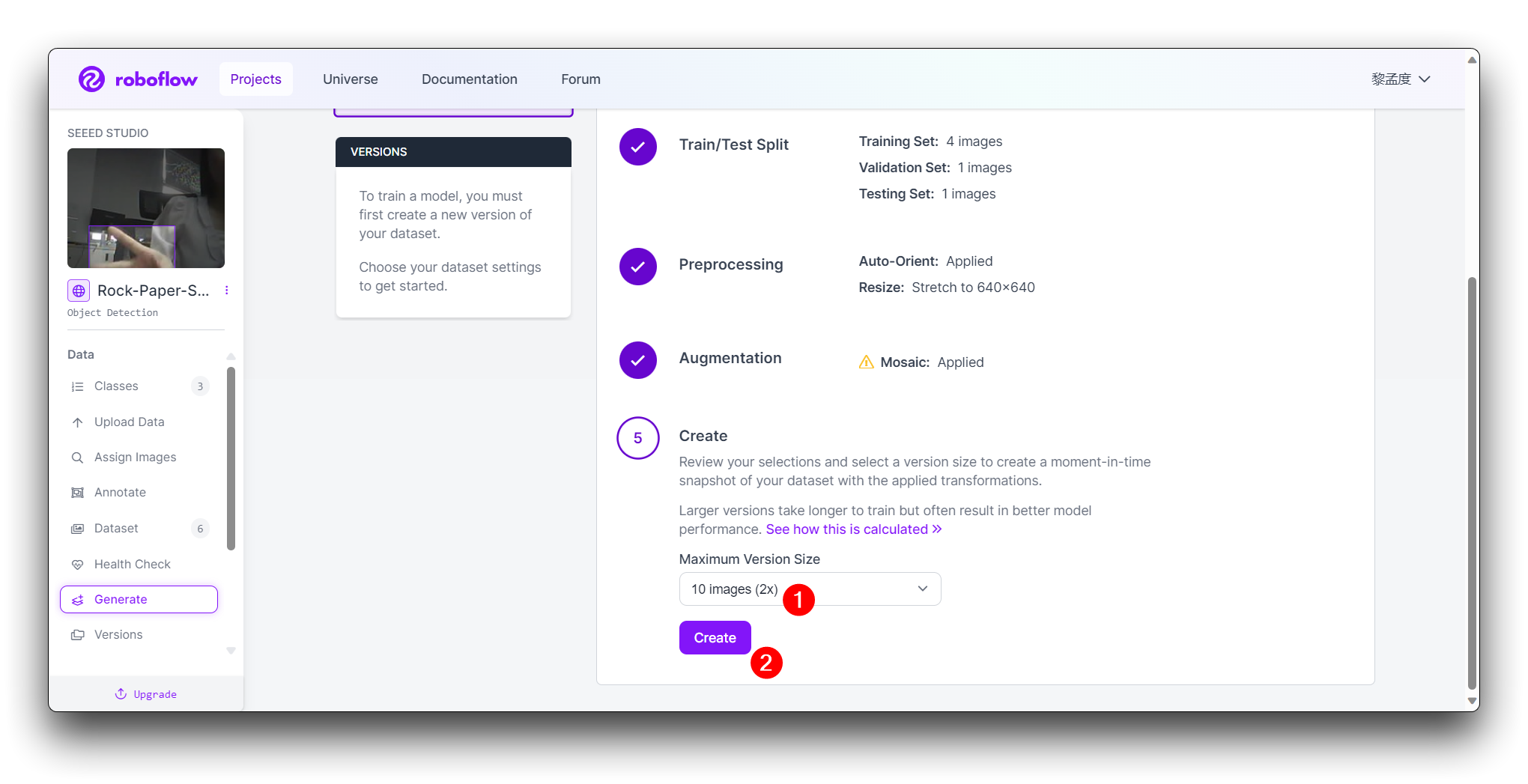
Clique em Create para criar uma versão do seu conjunto de dados. O Roboflow irá processar as imagens e anotações, criando um conjunto de dados versionado. Depois que o conjunto de dados for gerado, clique em Export Dataset. Escolha o formato COCO que corresponda aos requisitos do modelo que você irá treinar.
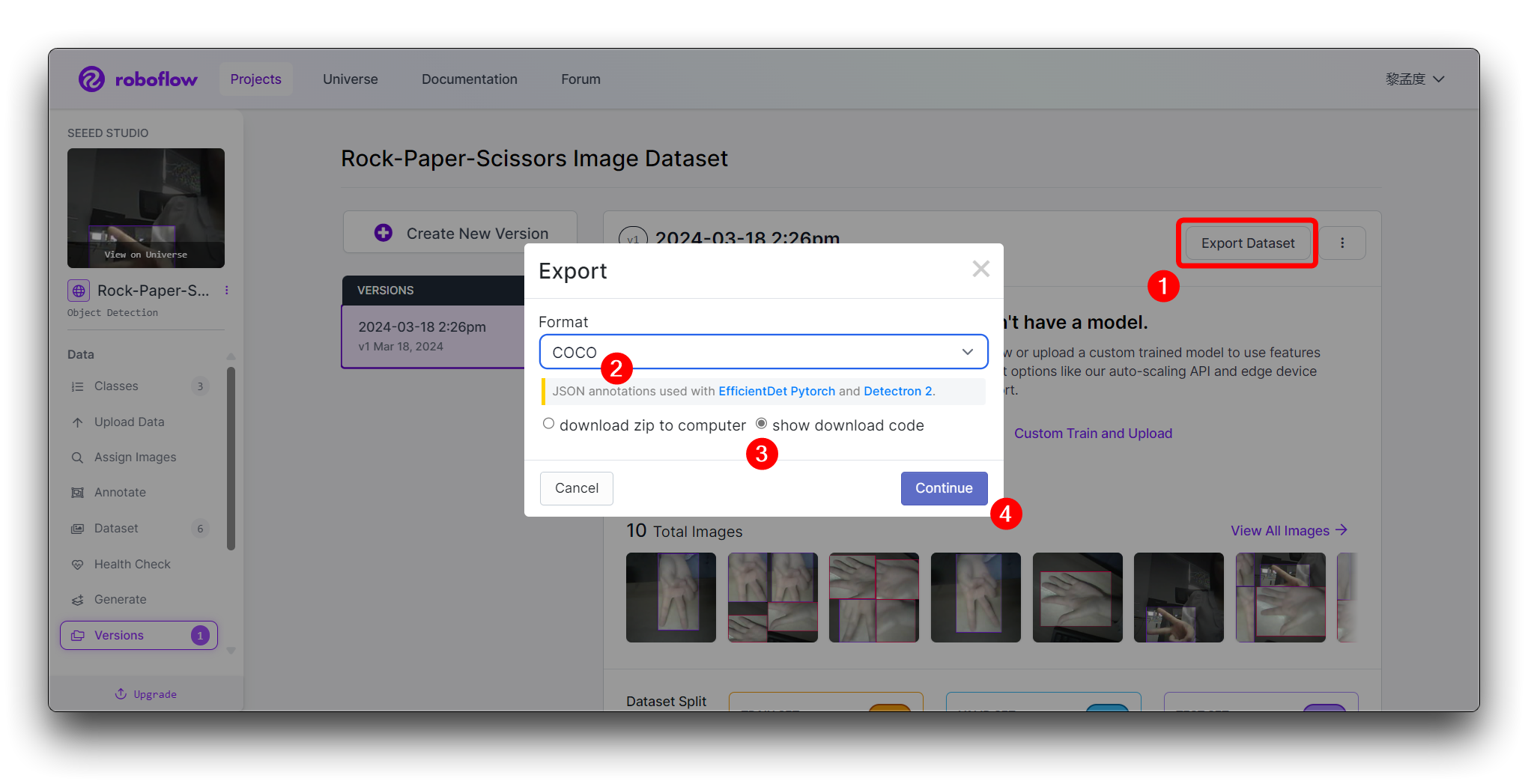
Clique em Continue e então você obterá a Raw URL para este modelo. Guarde-a, usaremos o link na etapa de treinamento do modelo um pouco mais tarde.
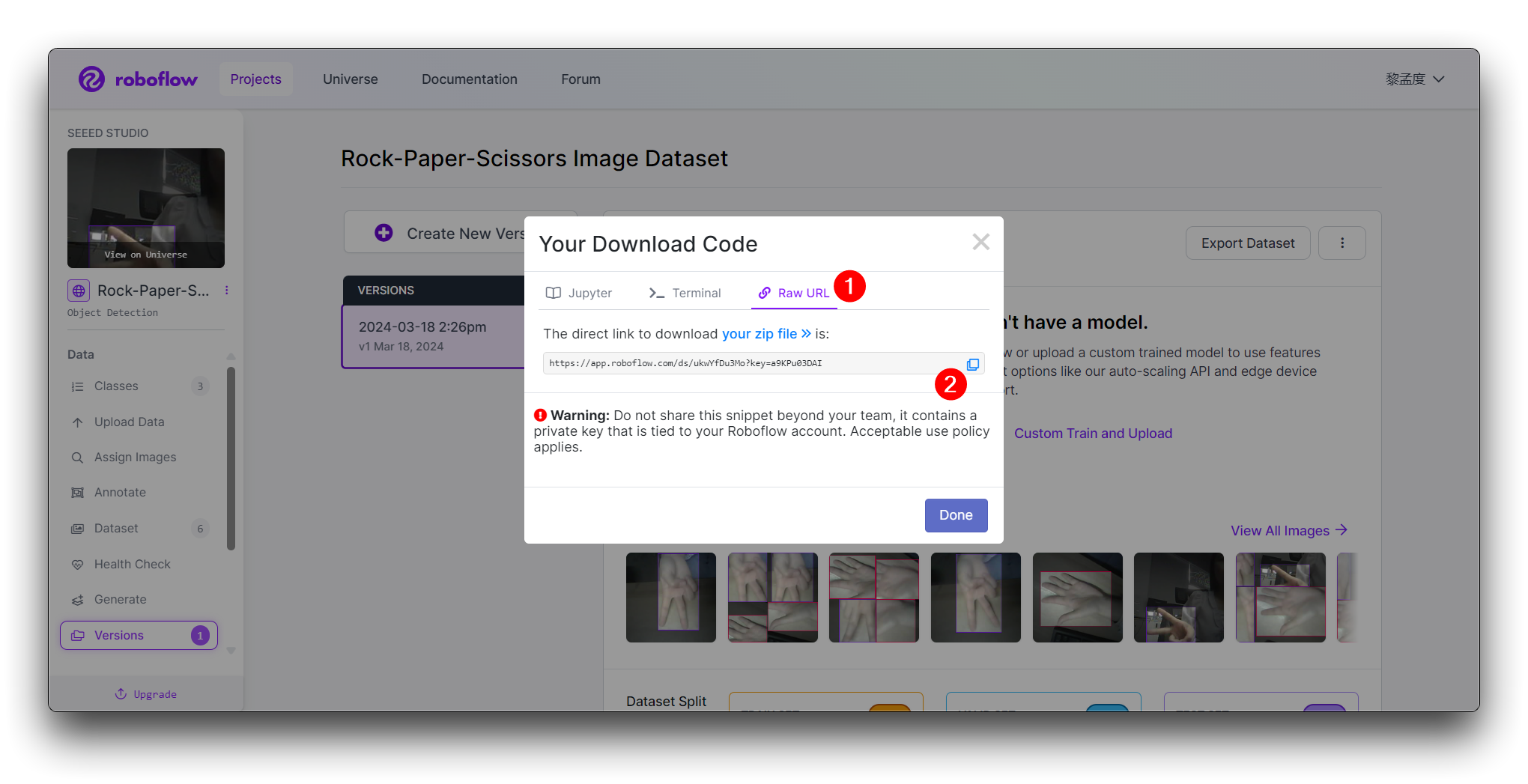
Parabéns! Você usou com sucesso o Roboflow para enviar, anotar e exportar um conjunto de dados para um modelo de detecção de gestos de mão Pedra-Papel-Tesoura. Com seu conjunto de dados pronto, você pode prosseguir para treinar um modelo de aprendizado de máquina usando plataformas como o Google Colab.
Lembre-se de manter seu conjunto de dados diversificado e bem anotado para melhorar a precisão do seu modelo futuro. Boa sorte com o treinamento do seu modelo e divirta-se classificando gestos de mão com o poder da IA!
Treinando o Modelo com o Conjunto de Dados Exportado
Passo 1. Acessar o Notebook do Colab
Você pode encontrar diferentes tipos de arquivos de código do Google Colab para modelos na Wiki do SenseCraft Model Assistant. Se você não souber qual código escolher, pode escolher qualquer um deles, dependendo da classe do seu modelo (object detection ou image classification).
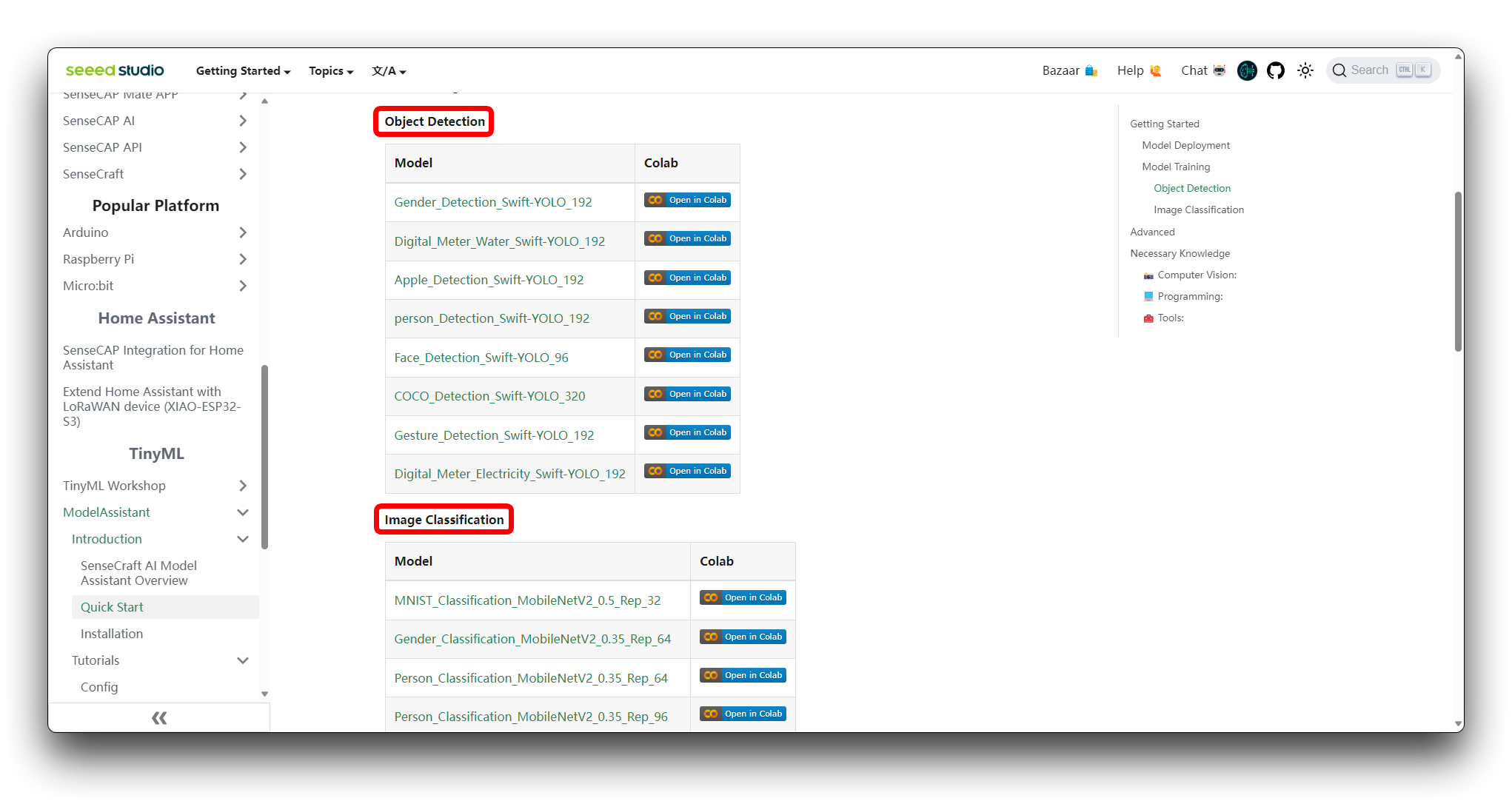
Se você ainda não estiver conectado à sua conta do Google, faça login para acessar todas as funcionalidades do Google Colab.
Clique em "Connect" para alocar recursos para sua sessão do Colab.

Passo 2. Adicionar seu Conjunto de Dados do Roboflow
Antes de executar oficialmente o bloco de código passo a passo, precisamos modificar o conteúdo do código para que ele possa usar o conjunto de dados que preparamos. Temos que fornecer uma URL para baixar o conjunto de dados diretamente para o sistema de arquivos do Colab.
Encontre a seção Download the dataset no código. Você verá o seguinte programa de exemplo.
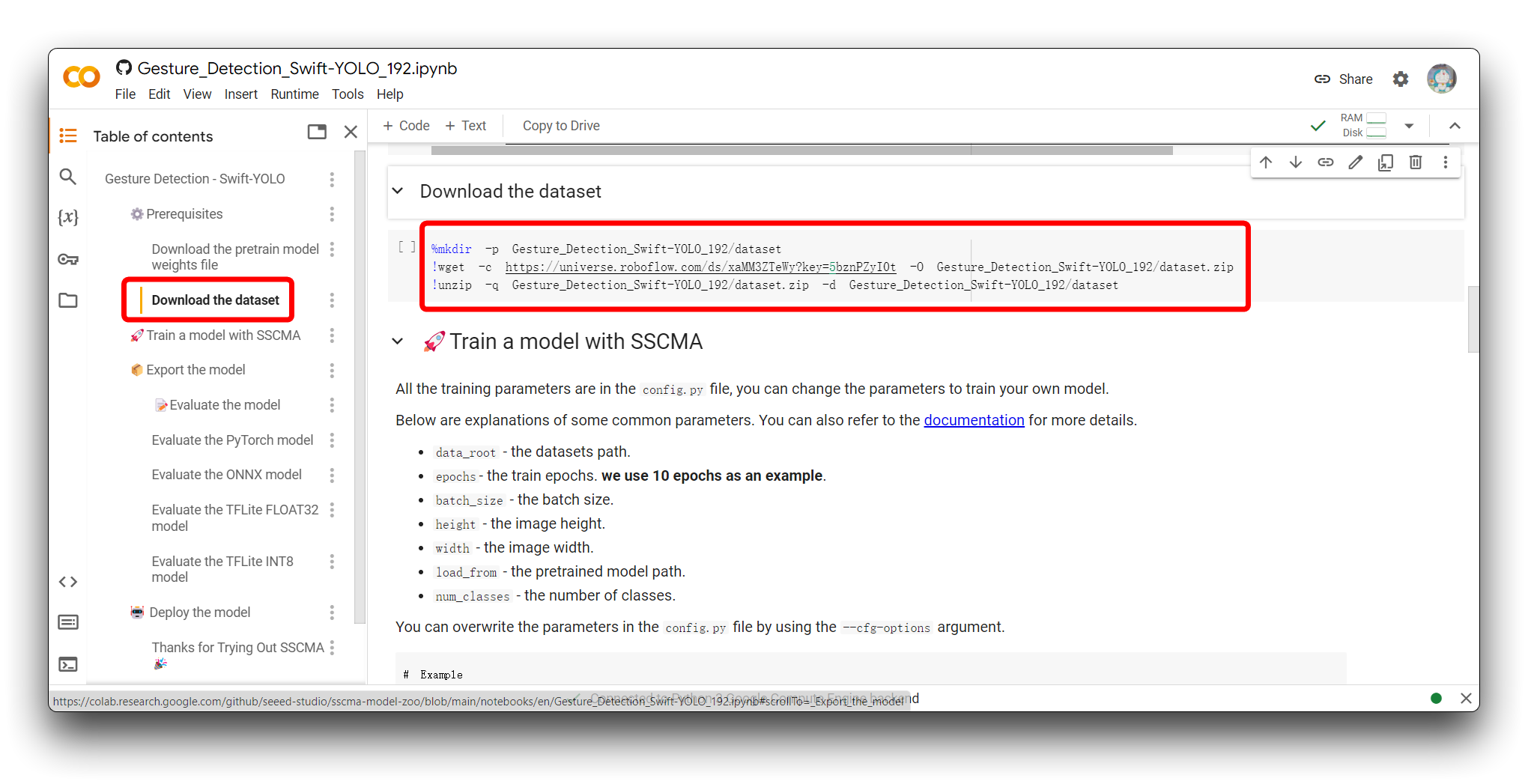
%mkdir -p Gesture_Detection_Swift-YOLO_192/dataset
!wget -c https://universe.roboflow.com/ds/xaMM3ZTeWy?key=5bznPZyI0t -O Gesture_Detection_Swift-YOLO_192/dataset.zip
!unzip -q Gesture_Detection_Swift-YOLO_192/dataset.zip -d Gesture_Detection_Swift-YOLO_192/dataset
Este trecho de código é usado para criar um diretório, baixar um conjunto de dados do Roboflow e descompactá-lo no diretório recém-criado dentro de um ambiente do Google Colab. Aqui está uma explicação do que cada linha faz:
-
%mkdir -p Gesture_Detection_Swift-YOLO_192/dataset:- Esta linha cria um novo diretório chamado
Gesture_Detection_Swift-YOLO_192e um subdiretório chamadodataset. A flag-pgarante que o comando não retorne um erro se o diretório já existir e cria quaisquer diretórios pai necessários.
- Esta linha cria um novo diretório chamado
-
!wget -c https://universe.roboflow.com/ds/xaMM3ZTeWy?key=5bznPZyI0t -O Gesture_Detection_Swift-YOLO_192/dataset.zip:- Esta linha usa
wget, um utilitário de linha de comando, para baixar o conjunto de dados a partir da URL do Roboflow fornecida. A flag-cpermite retomar o download se ele for interrompido. A flag-Oespecifica o local de saída e o nome do arquivo para o arquivo baixado, neste caso,Gesture_Detection_Swift-YOLO_192/dataset.zip.
- Esta linha usa
-
!unzip -q Gesture_Detection_Swift-YOLO_192/dataset.zip -d Gesture_Detection_Swift-YOLO_192/dataset:- Esta linha usa o comando
unzippara extrair o conteúdo do arquivodataset.zippara o diretóriodatasetque foi criado anteriormente. A flag-qexecuta o comandounzipem modo silencioso, suprimindo a maior parte das mensagens de saída.
- Esta linha usa o comando
Para personalizar este código para o link do seu próprio modelo do Roboflow:
-
Substitua
Gesture_Detection_Swift-YOLO_192pelo nome de diretório desejado onde você quer armazenar seu conjunto de dados. -
Substitua a URL do conjunto de dados do Roboflow (
https://universe.roboflow.com/ds/xaMM3ZTeWy?key=5bznPZyI0t) pelo link do seu conjunto de dados exportado (É a URL bruta que obtivemos na última etapa em Conjuntos de Dados Rotulados). Certifique-se de incluir o parâmetro key se for necessário para acesso. -
Ajuste o nome do arquivo de saída no comando
wgetse necessário (-O your_directory/your_filename.zip). -
Certifique-se de que o diretório de saída no comando
unzipcorresponde ao diretório que você criou e que o nome do arquivo corresponde ao que você definiu no comandowget.
Se você alterar o nome de um diretório de pasta Gesture_Detection_Swift-YOLO_192, observe que você precisará fazer alterações em outros nomes de diretório no código que foram usados antes da alteração, caso contrário um erro pode ocorrer!
Etapa 3. Ajuste dos parâmetros do modelo
A próxima etapa é ajustar os parâmetros de entrada do modelo. Por favor, pule para a seção Train a model with SSCMA e você verá o seguinte trecho de código.
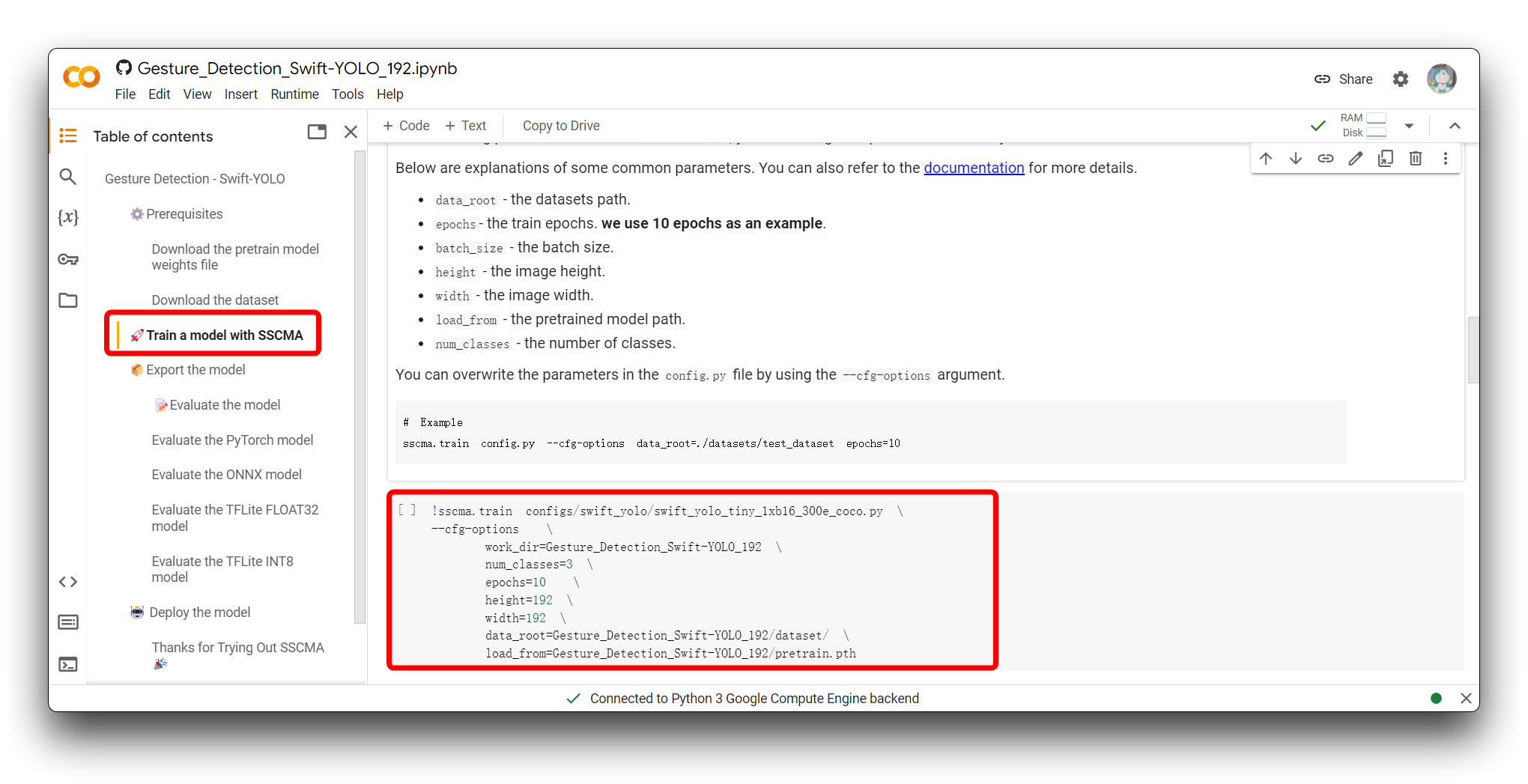
!sscma.train configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.py \
--cfg-options \
work_dir=Gesture_Detection_Swift-YOLO_192 \
num_classes=3 \
epochs=10 \
height=192 \
width=192 \
data_root=Gesture_Detection_Swift-YOLO_192/dataset/ \
load_from=Gesture_Detection_Swift-YOLO_192/pretrain.pth
Este comando é usado para iniciar o processo de treinamento de um modelo de aprendizado de máquina, especificamente um modelo YOLO (You Only Look Once), usando o framework SSCMA (Seeed Studio SenseCraft Model Assistant). O comando inclui várias opções para configurar o processo de treinamento. Aqui está o que cada parte faz:
-
!sscma.trainé o comando para iniciar o treinamento dentro do framework SSCMA. -
configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.pyespecifica o arquivo de configuração para o treinamento, que inclui definições como a arquitetura do modelo, cronograma de treinamento, estratégias de aumento de dados, etc. -
--cfg-optionspermite que você substitua as configurações padrão especificadas no arquivo.pypelas que você fornece na linha de comando. -
work_dir=Gesture_Detection_Swift-YOLO_192define o diretório onde as saídas do treinamento, como logs e checkpoints do modelo salvos, serão armazenadas. -
num_classes=3especifica o número de classes que o modelo deve aprender a reconhecer. Depende do número de rótulos que você tem, por exemplo pedra, papel e tesoura devem ser três rótulos. -
epochs=10define o número de ciclos de treinamento (épocas) a serem executados. Os valores recomendados ficam entre 50 e 100. -
height=192ewidth=192definem a altura e a largura das imagens de entrada que o modelo espera.
Nós realmente não recomendamos que você altere o tamanho da imagem no código do Colab, pois esse valor é um tamanho de conjunto de dados mais apropriado que verificamos ser uma combinação de tamanho, precisão e velocidade de inferência. Se você estiver usando um conjunto de dados que não é desse tamanho, e talvez queira considerar mudar o tamanho da imagem para garantir a precisão, então, por favor, não exceda 240x240.
-
data_root=Gesture_Detection_Swift-YOLO_192/dataset/define o caminho para o diretório onde os dados de treinamento estão localizados. -
load_from=Gesture_Detection_Swift-YOLO_192/pretrain.pthfornece o caminho para um arquivo de checkpoint de modelo pré-treinado a partir do qual o treinamento deve ser retomado ou usado como ponto de partida para aprendizado por transferência.
Para personalizar este comando para o seu próprio treinamento, você deve:
-
Substituir
configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.pypelo caminho para o seu próprio arquivo de configuração se você tiver um personalizado. -
Alterar
work_dirpara o diretório onde você deseja que as saídas do treinamento sejam salvas. -
Atualizar
num_classespara corresponder ao número de classes no seu próprio conjunto de dados. Depende do número de rótulos que você tem, por exemplo pedra, papel, tesoura devem ser três rótulos. -
Ajustar
epochspara o número desejado de épocas de treinamento para o seu modelo. Os valores recomendados ficam entre 50 e 100. -
Definir
heightewidthpara corresponder às dimensões das imagens de entrada do seu modelo. -
Alterar
data_rootpara apontar para o diretório raiz do seu conjunto de dados. -
Se você tiver um arquivo de modelo pré-treinado diferente, atualize o caminho de
load_fromde acordo.
Etapa 4. Execute o código do Google Colab
A maneira de executar o bloco de código é clicar no botão de play no canto superior esquerdo do bloco de código.
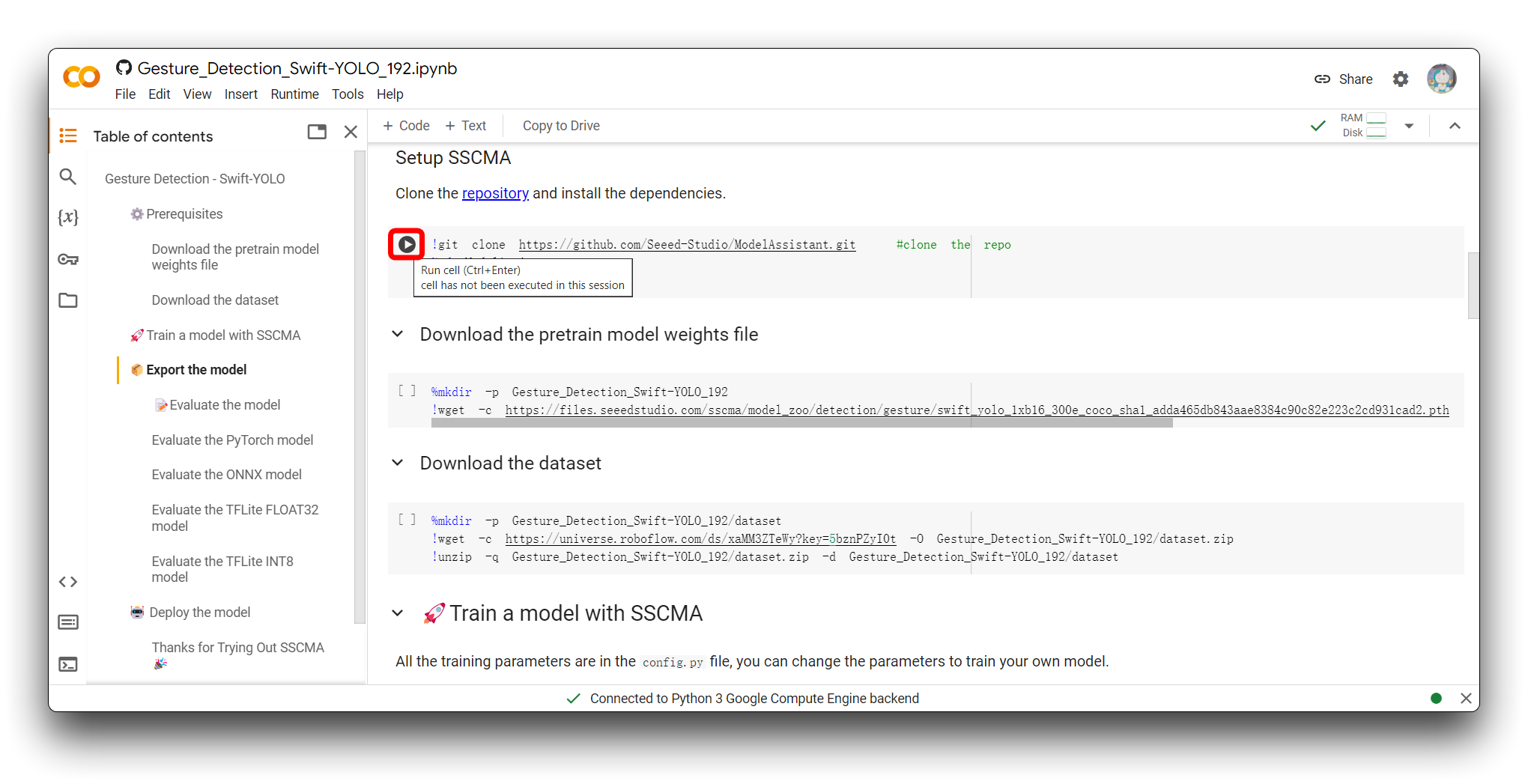
O bloco de código será executado após você clicar no botão e, se tudo correr bem, você verá o sinal de que a execução do bloco de código foi concluída - um símbolo de tique aparece à esquerda do bloco. Como mostrado na figura, este é o efeito após a execução do primeiro bloco de código ser concluída.
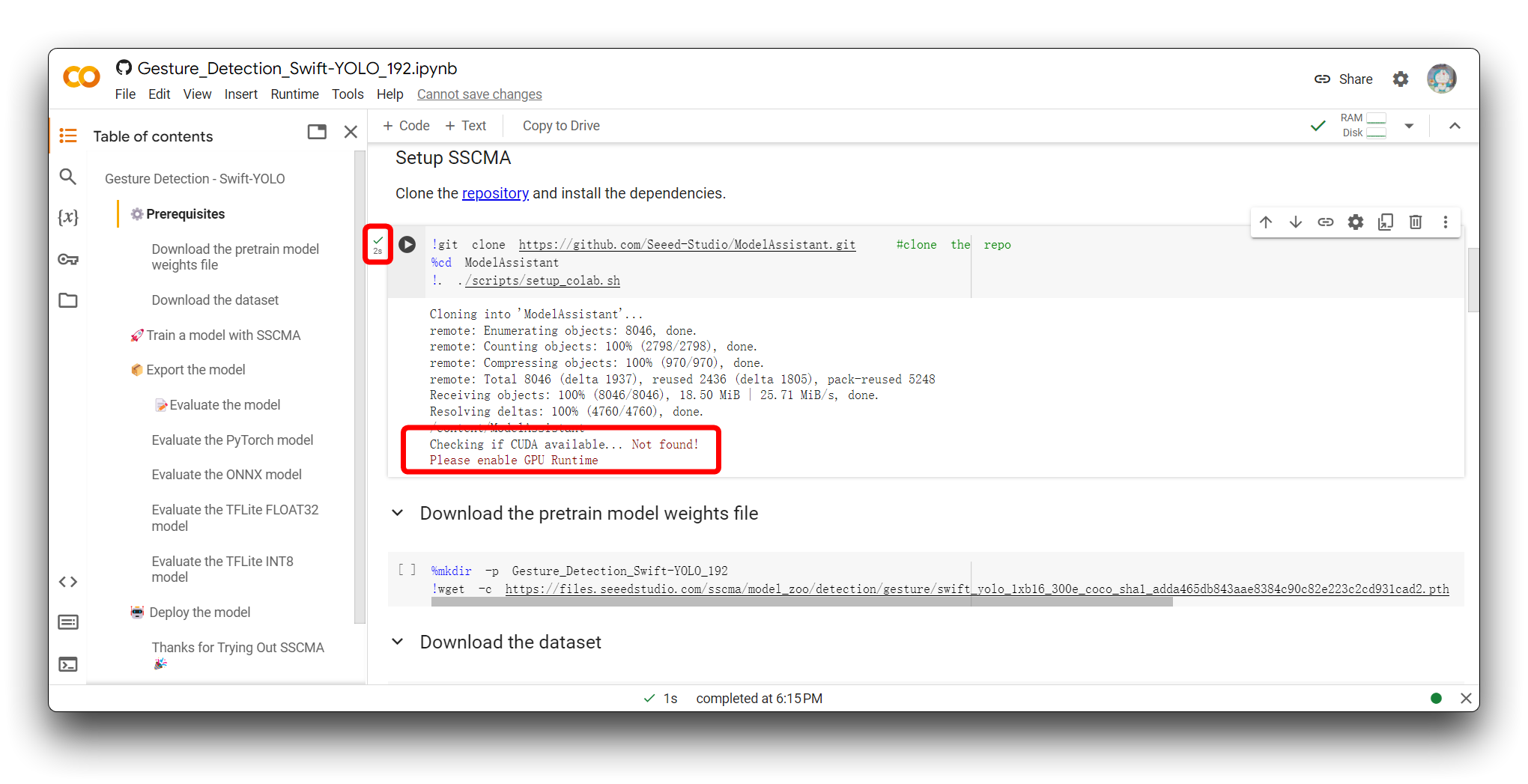
Se você encontrar a mesma mensagem de erro que a minha na imagem acima, verifique se está usando uma T4 GPU, por favor não use CPU para este projeto.
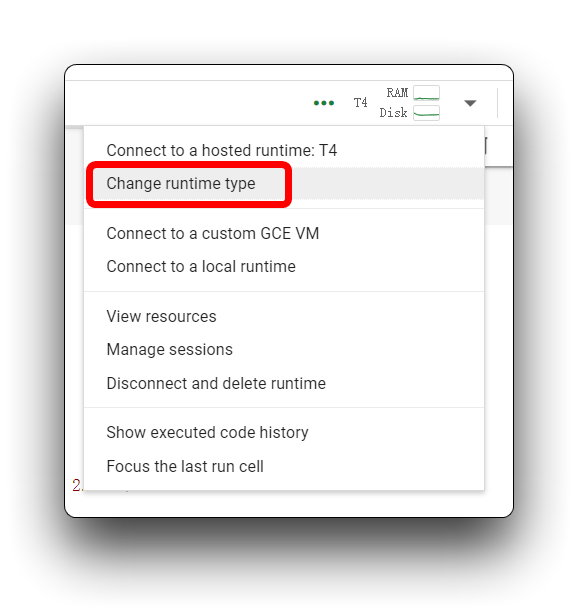
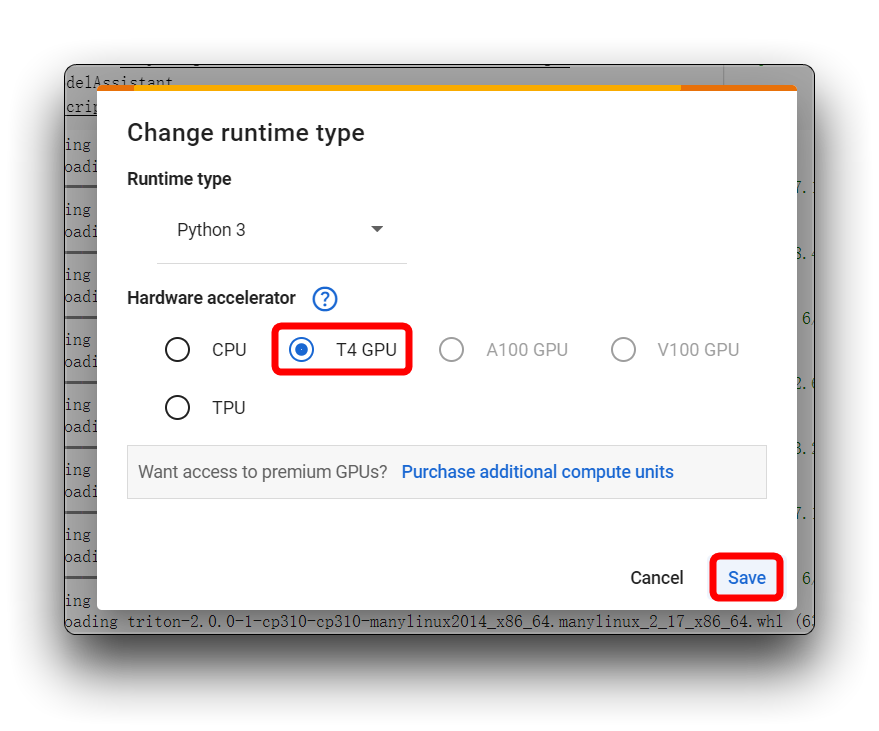
Em seguida, reexecute o bloco de código. Para o primeiro bloco de código, se tudo correr bem, você verá o resultado mostrado abaixo.
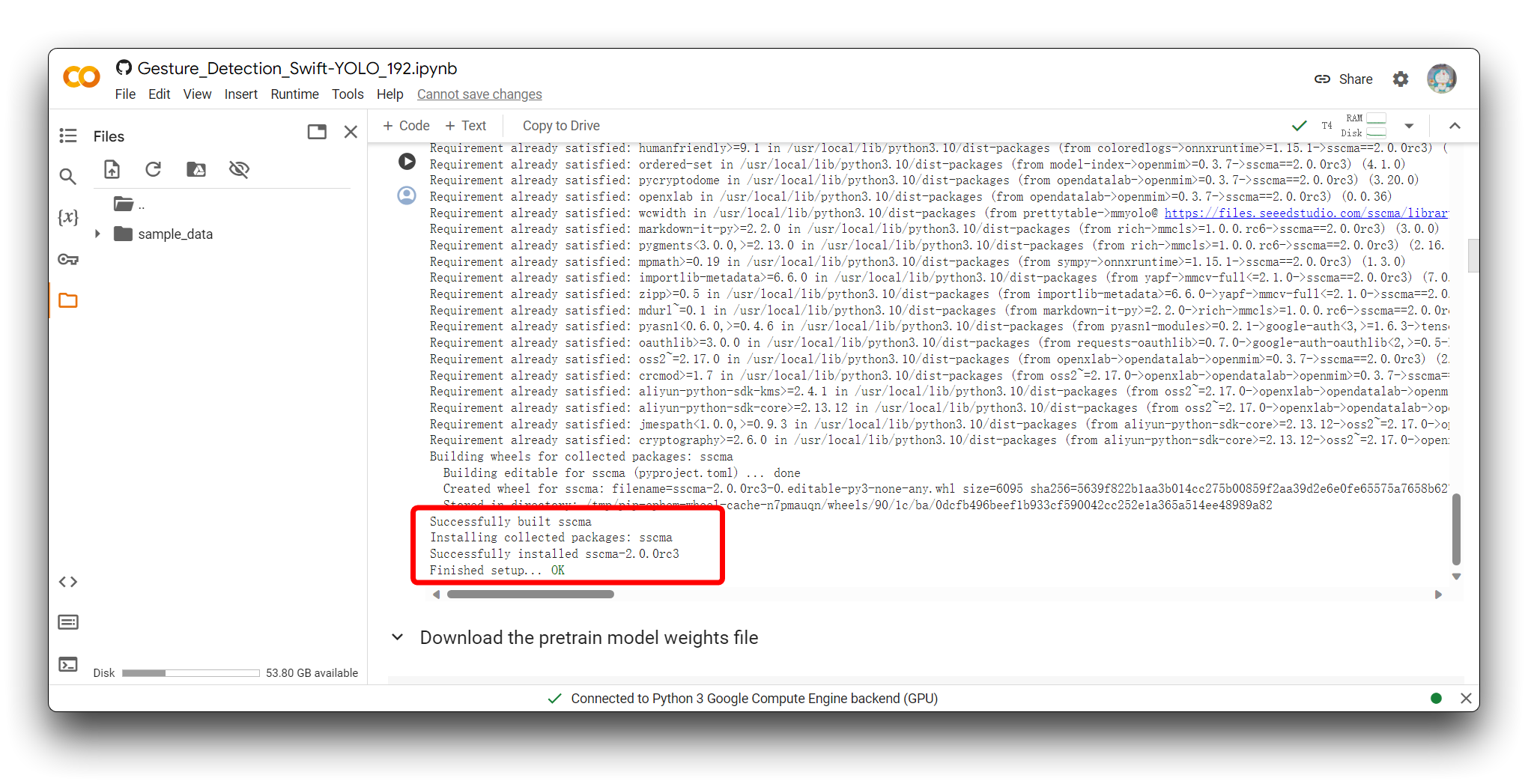
Em seguida, execute todos os blocos de código de Download the pretrain model weights file até Export the model. E certifique-se de que cada bloco de código esteja livre de erros.
Avisos que aparecem no código podem ser ignorados.
Etapa 5. Avalie o modelo
Quando você chegar à seção Evaluate the model, você terá a opção de executar o bloco de código Evaluate the TFLite INT8 model.
Avaliar o modelo TFLite INT8 envolve testar as previsões do modelo quantizado em relação a um conjunto de dados de teste separado para medir sua precisão e métricas de desempenho, avaliar o impacto da quantização na precisão do modelo e analisar seu tempo de inferência e uso de recursos para garantir que ele atenda às restrições de implantação para dispositivos de borda.
O trecho a seguir é a parte válida do resultado depois que executei este bloco de código.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.450
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.929
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.361
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.474
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.456
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.515
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.529
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.529
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.536
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.537
03/19 01:38:43 - mmengine - INFO - bbox_mAP_copypaste: 0.450 0.929 0.361 -1.000 0.474 0.456
{'coco/bbox_mAP': 0.45, 'coco/bbox_mAP_50': 0.929, 'coco/bbox_mAP_75': 0.361, 'coco/bbox_mAP_s': -1.0, 'coco/bbox_mAP_m': 0.474, 'coco/bbox_mAP_l': 0.456}
FPS: 128.350449 fram/s
Os resultados da avaliação incluem uma série de métricas de Precisão Média (AP) e Revocação Média (AR), calculadas para diferentes limiares de Intersection over Union (IoU) e tamanhos de objetos, que são comumente usadas para avaliar o desempenho de modelos de detecção de objetos.
-
AP@[IoU=0.50:0.95 | area=all | maxDets=100] = 0.450
- Esta pontuação é a precisão média do modelo em uma faixa de limiares de IoU de 0.50 a 0.95, incrementada em 0.05. Um AP de 0.450 indica que seu modelo tem precisão moderada nessa faixa. Esta é uma métrica chave comumente usada para o conjunto de dados COCO.
-
AP@[IoU=0.50 | area=all | maxDets=100] = 0.929
- Em um limiar de IoU de 0.50, o modelo atinge uma alta precisão média de 0.929, sugerindo que ele detecta objetos com muita precisão sob um critério de correspondência mais permissivo.
-
AP@[IoU=0.75 | area=all | maxDets=100] = 0.361
- Com um limiar de IoU mais rigoroso de 0.75, a precisão média do modelo cai para 0.361, indicando uma queda no desempenho sob critérios de correspondência mais estritos.
-
AP@[IoU=0.50:0.95 | area=small/medium/large | maxDets=100]
- As pontuações de AP variam para objetos de tamanhos diferentes. No entanto, o AP para objetos pequenos é -1.000, o que pode indicar falta de dados de avaliação para objetos pequenos ou baixo desempenho do modelo na detecção de objetos pequenos. As pontuações de AP para objetos médios e grandes são 0.474 e 0.456, respectivamente, sugerindo que o modelo detecta objetos médios e grandes relativamente melhor.
-
AR@[IoU=0.50:0.95 | area=all | maxDets=1/10/100]
- As taxas médias de recall para diferentes valores de
maxDetssão bastante consistentes, variando de 0,515 a 0,529, o que indica que o modelo recupera de forma confiável a maioria das instâncias verdadeiramente positivas.
- As taxas médias de recall para diferentes valores de
-
FPS: 128.350449 fram/s
- O modelo processa imagens em uma taxa muito rápida de aproximadamente 128,35 quadros por segundo durante a inferência, indicando potencial para aplicações em tempo real ou quase em tempo real.
No geral, o modelo apresenta desempenho excelente com um IoU de 0,50 e moderado com um IoU de 0,75. Ele funciona melhor na detecção de objetos médios e grandes, mas pode ter problemas para detectar objetos pequenos. Além disso, o modelo infere em alta velocidade, tornando-o adequado para cenários que exigem processamento rápido. Se a detecção de objetos pequenos for crítica em uma aplicação, talvez seja necessário otimizar ainda mais o modelo ou coletar mais dados de objetos pequenos para melhorar o desempenho.
Passo 6. Baixar o arquivo de modelo exportado
Após a seção Export the model, você obterá os arquivos de modelo em vários formatos, que serão armazenados na pasta ModelAssistant por padrão. Neste tutorial, o diretório armazenado é Gesture_Detection_Swift_YOLO_192.
Às vezes o Google Colab não atualiza automaticamente o conteúdo de uma pasta. Nesse caso, talvez você precise atualizar o diretório de arquivos clicando no ícone de atualizar no canto superior esquerdo.
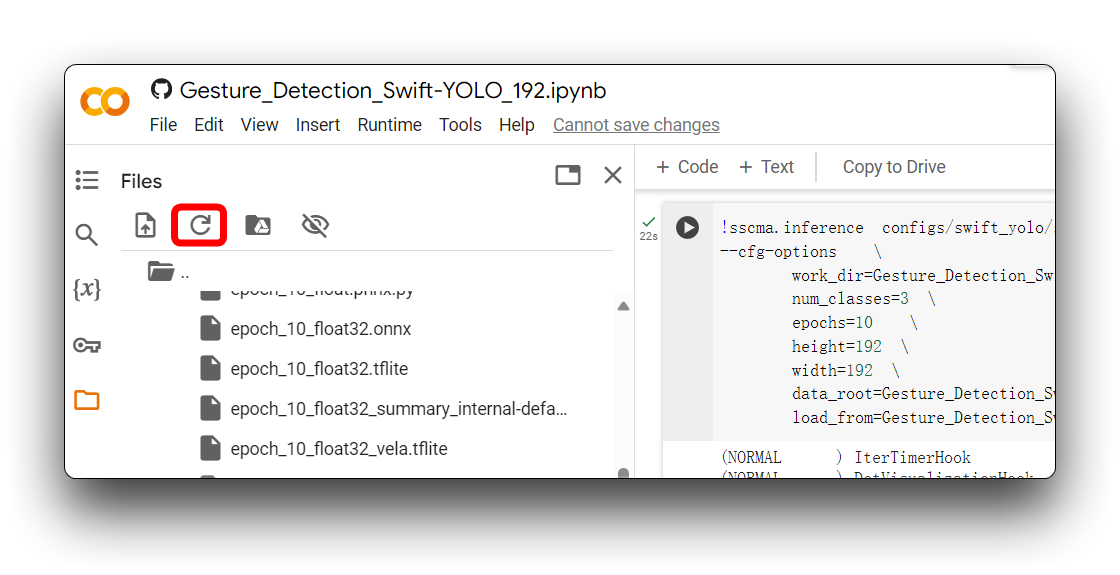
No diretório acima, os arquivos de modelo .tflite estão disponíveis para XIAO ESP32S3 e Grove Vision AI V2. Para o XIAO ESP32S3 Sense, certifique-se de selecionar o arquivo de modelo que utiliza o formato xxx_int8.tflite. Nenhum outro formato pode ser usado pelo XIAO ESP32S3 Sense.
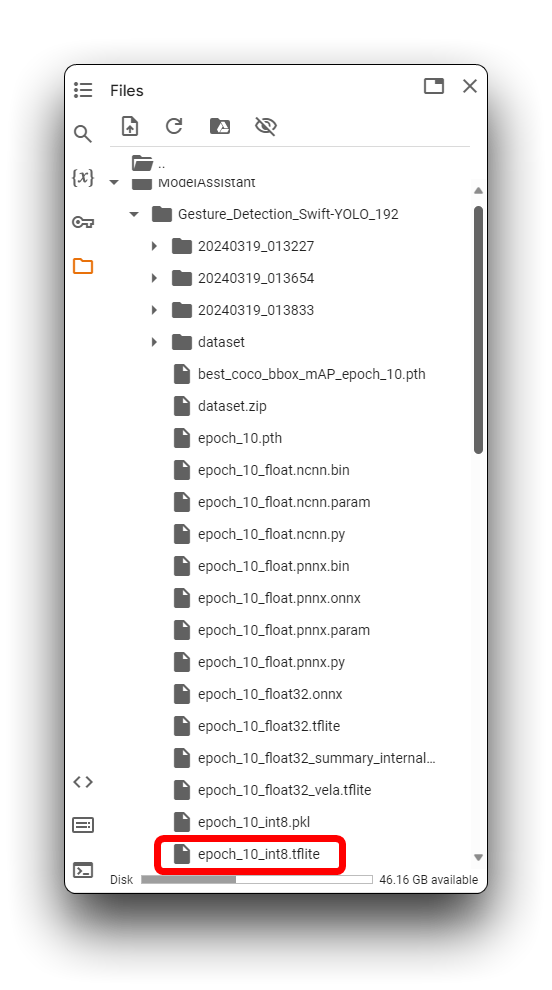
Depois de encontrar os arquivos de modelo, baixe-os localmente para o seu computador o mais rápido possível, o Google Colab pode esvaziar seu diretório de armazenamento se você ficar inativo por muito tempo!
Então, com as etapas realizadas aqui, exportamos com sucesso arquivos de modelo que podem ser suportados pelo XIAO ESP32S3, em seguida vamos implantar o modelo no dispositivo.
Enviar modelos via SenseCraft Model Assistant
Passo 7. Enviar modelo personalizado para o XIAO ESP32S3
Em seguida, vamos para a página Model Assistant.
Conecte o dispositivo após selecionar XIAO ESP32S3 e, em seguida, selecione Upload Custom AI Model na parte inferior da página.
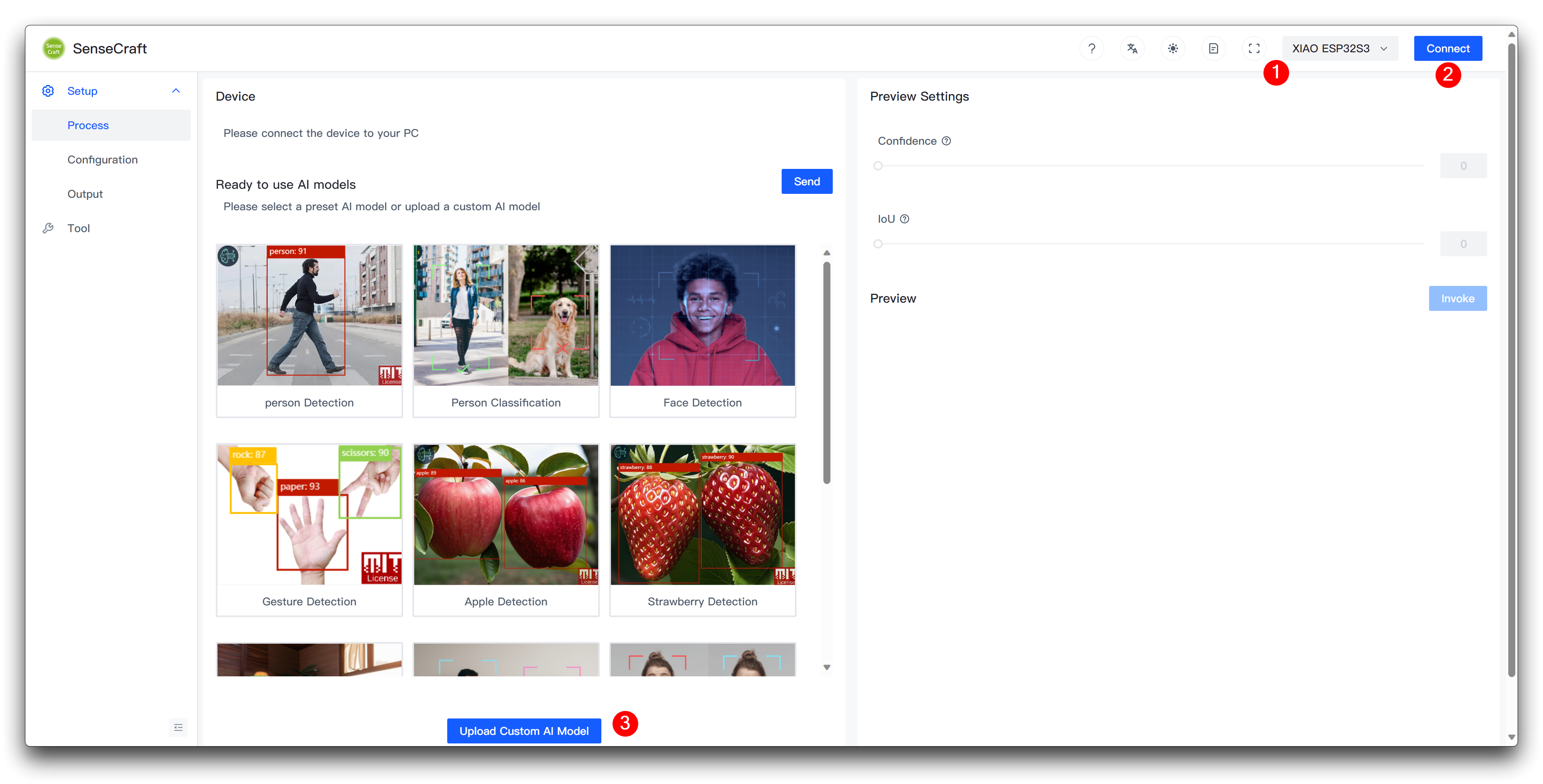
Você então precisará preparar o nome do modelo, o arquivo do modelo e os rótulos. Quero destacar aqui como esse elemento do ID do rótulo é determinado.
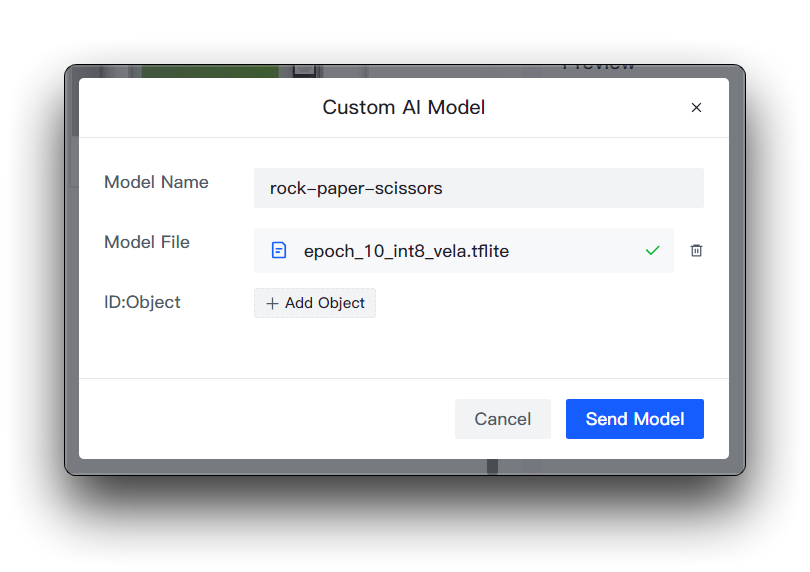
Se você estiver baixando o dataset do Roboflow diretamente
Se você baixou o dataset do Roboflow diretamente, então você pode visualizar as diferentes categorias e sua ordem na página Health Check. Basta seguir a ordem inserida aqui.
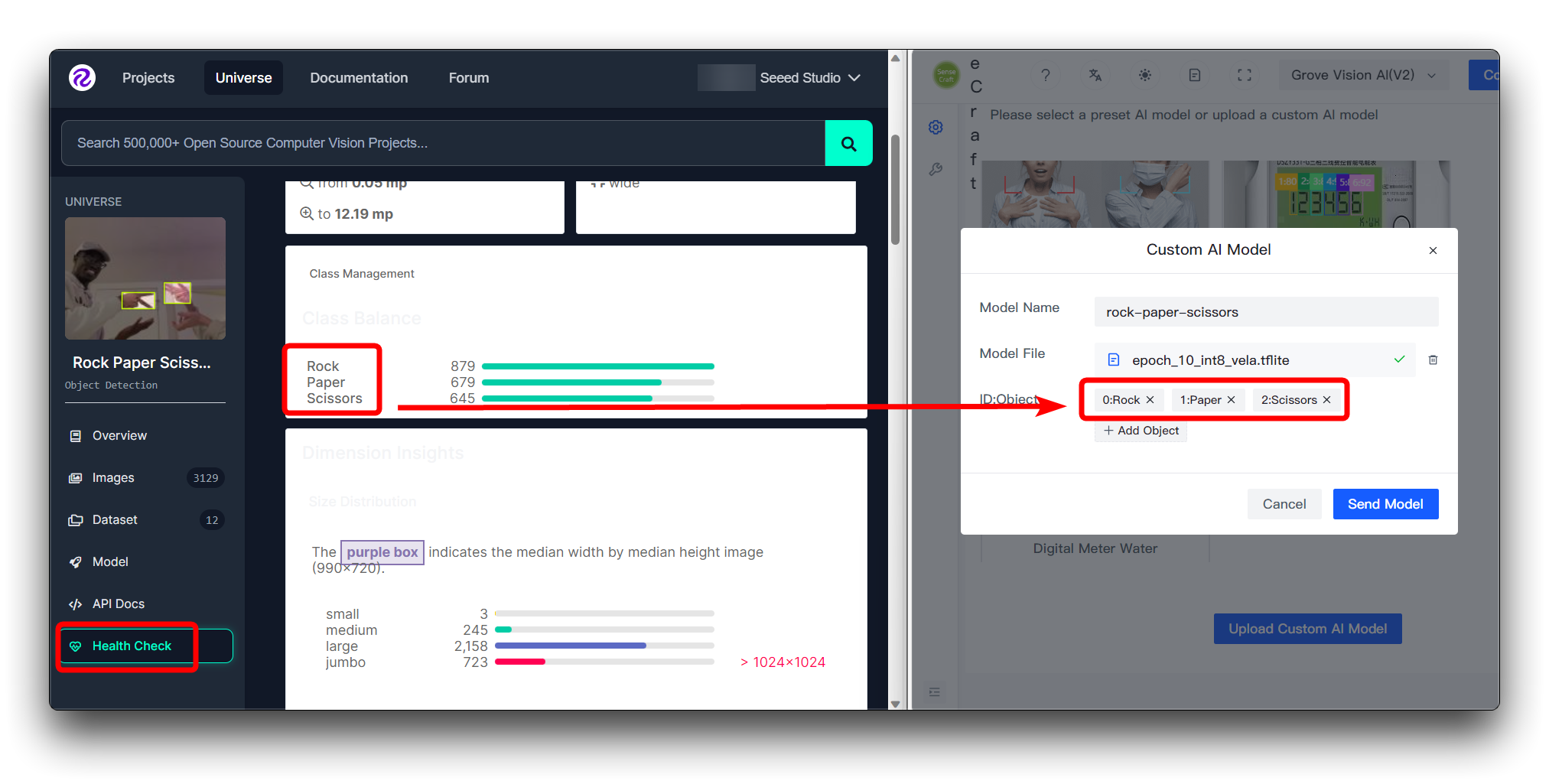
Você não precisa preencher os números em ID:Object, basta preencher diretamente o nome da categoria, os números e os dois-pontos na frente das categorias na imagem são adicionados automaticamente.
Se você estiver usando um dataset personalizado
Se você estiver usando um dataset personalizado, então você pode visualizar as diferentes categorias e sua ordem na página Health Check. Basta seguir a ordem inserida aqui.
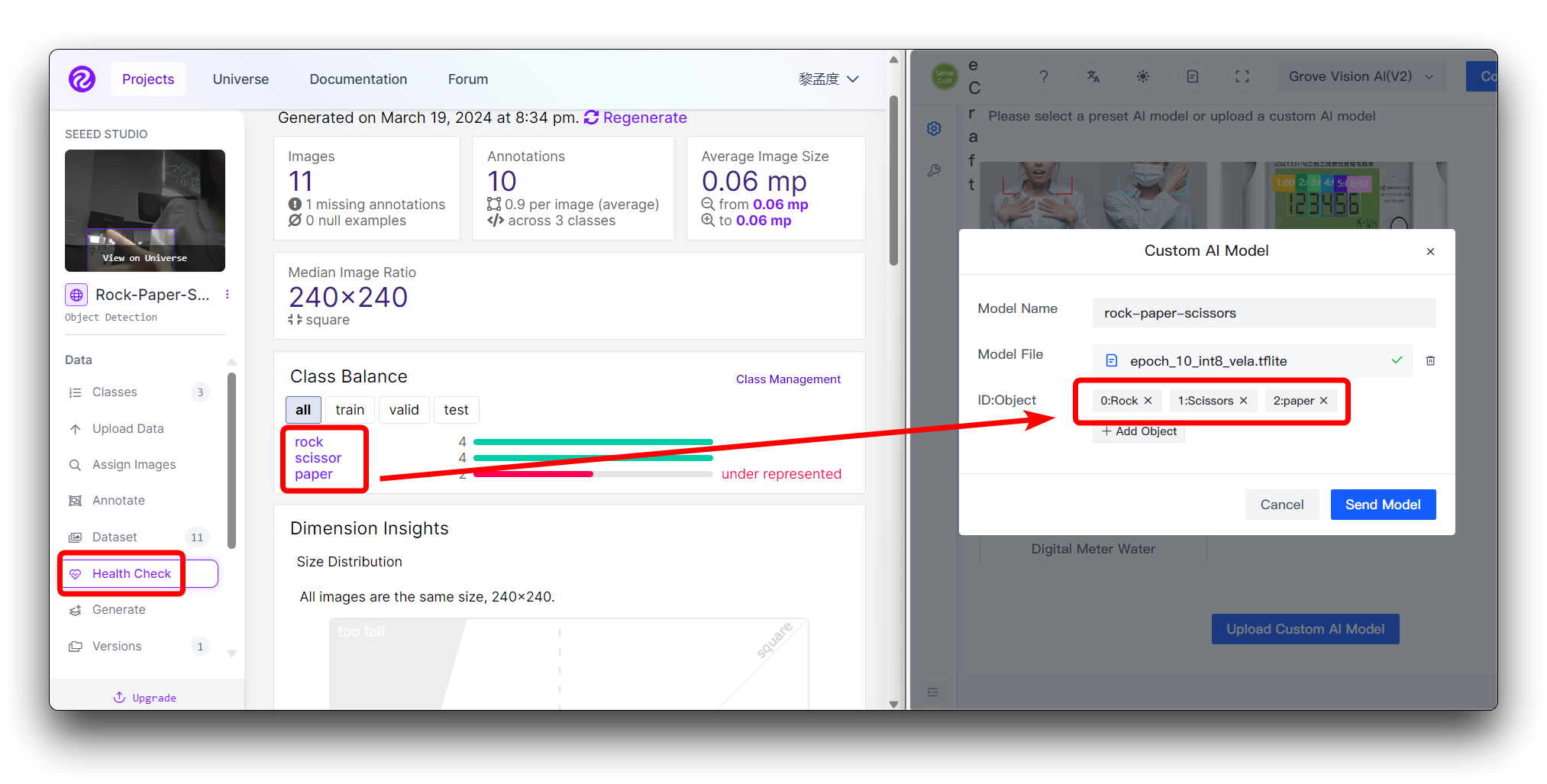
Você não precisa preencher os números em ID:Object, basta preencher diretamente o nome da categoria, os números e os dois-pontos na frente das categorias na imagem são adicionados automaticamente.
Em seguida, clique em Send Model no canto inferior direito. Isso pode levar cerca de 3 a 5 minutos. Se tudo correr bem, então você poderá ver os resultados do seu modelo nas janelas Model Name e Preview acima.
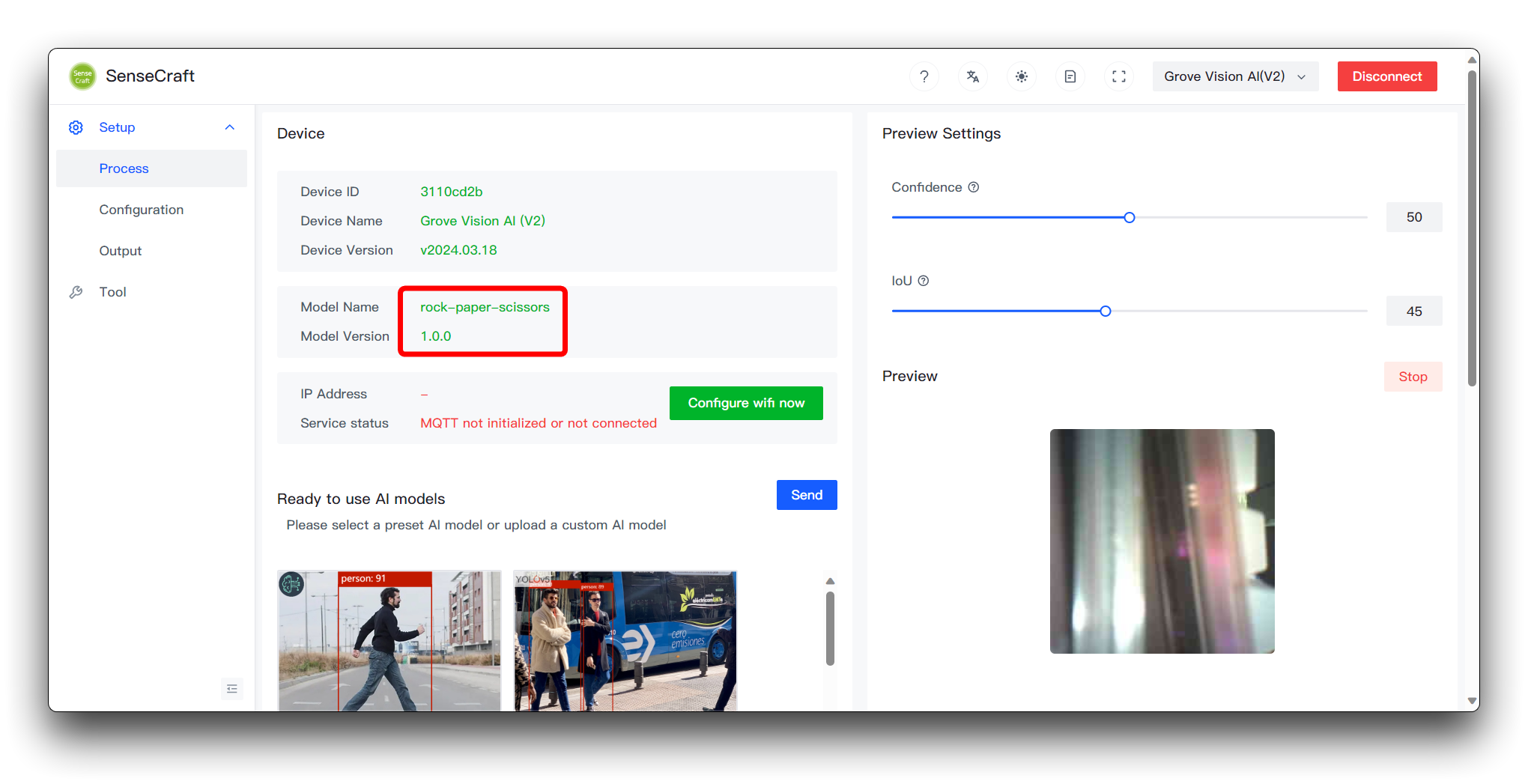
Tendo chegado até aqui, parabéns, você conseguiu treinar e implantar com sucesso um modelo próprio.
Protocolos comuns e aplicações do modelo
Durante o processo de envio de um modelo personalizado, além dos arquivos de modelo que podemos visualizar sendo enviados, há também o firmware do dispositivo que precisa ser transferido para o dispositivo. No firmware do dispositivo, há um conjunto de protocolos de comunicação estabelecidos que especificam o formato de saída dos resultados do modelo e o que o usuário pode fazer com os modelos.
Devido a questões de espaço, não vamos detalhar as especificidades desses protocolos neste wiki, vamos detalhar esta seção por meio de documentação no Github. Se você estiver interessado em um desenvolvimento mais aprofundado, acesse aqui.
Suporte Técnico & Discussão de Produtos
1. E se eu seguir os passos e acabar com resultados de modelo insatisfatórios?
Se a precisão de reconhecimento do seu modelo for insatisfatória, você pode diagnosticá-la e melhorá-la considerando os seguintes aspectos:
-
Qualidade e Quantidade de Dados
- Problema: O dataset pode ser muito pequeno ou carecer de diversidade, ou pode haver imprecisões nas anotações.
- Solução: Aumente o tamanho e a diversidade dos dados de treinamento e realize limpeza de dados para corrigir quaisquer erros de anotação.
-
Processo de Treinamento
- Problema: O tempo de treinamento pode ser insuficiente ou a taxa de aprendizado pode estar configurada incorretamente, impedindo que o modelo aprenda de forma eficaz.
- Solução: Aumente o número de épocas de treinamento, ajuste a taxa de aprendizado e outros hiperparâmetros e implemente early stopping para evitar overfitting.
-
Desbalanceamento de Classes
- Problema: Algumas classes têm significativamente mais amostras do que outras, levando o modelo a favorecer a classe majoritária.
- Solução: Use pesos de classe, faça oversampling das classes minoritárias ou undersampling das classes majoritárias para equilibrar os dados.
Ao analisar cuidadosamente e implementar melhorias direcionadas, você pode aprimorar progressivamente a precisão do seu modelo. Lembre-se de usar um conjunto de validação para testar o desempenho do modelo após cada modificação, a fim de garantir a eficácia das suas melhorias.
2. Por que vejo a mensagem Invoke failed na implantação do SenseCraft depois de seguir os passos do Wiki?
Se você encontrar um Invoke failed, então você treinou um modelo que não atende aos requisitos para uso com o dispositivo. Concentre-se nas seguintes áreas.
- Verifique se você modificou o tamanho da imagem no Colab. O tamanho de compactação padrão é 192x192, o Grove Vision AI V2 requer que o tamanho da imagem seja compactado como quadrado, por favor não use um tamanho não quadrado para compactação. Também não use um tamanho muito grande (recomenda-se não mais que 240x240).
Suporte Técnico & Discussão de Produtos
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.