Convert and Quantize AI Models

The AI model conversion tool of reCamera currently supports frameworks such as PyTorch, ONNX, TFLite, and Caffe. Models from other frameworks need to be converted into ONNX format. For instructions on how to convert models from other deep learning architectures to ONNX, you can refer to the official ONNX website: https://github.com/onnx/tutorials.
The flow diagram for deploying AI models on reCamera is shown below.
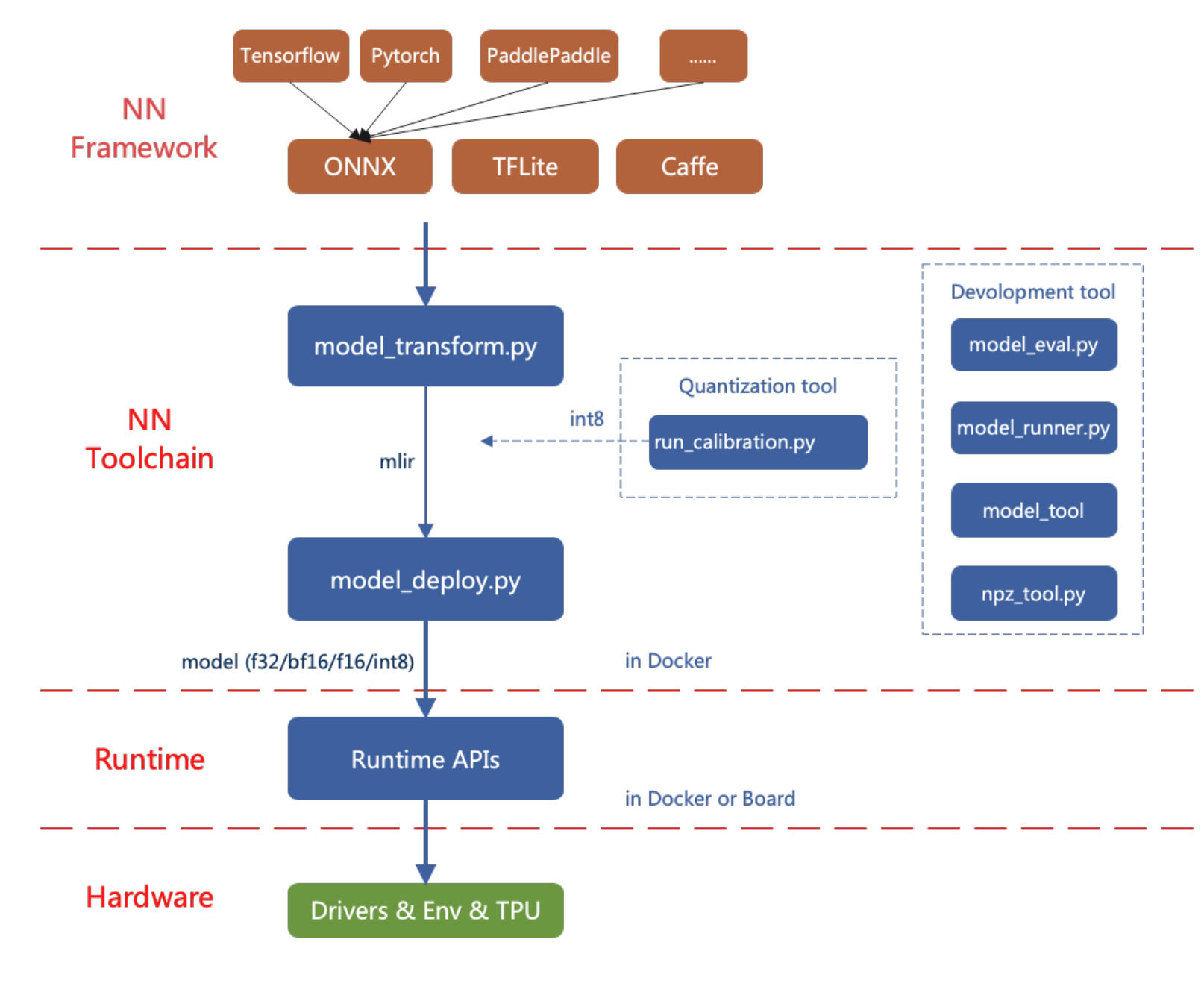
This article introduces how to use reCamera's AI model conversion tool through simple examples.
Set up the working environment
Method 1: Installation in a Docker Image (recommend)
Download the required image from DockerHub (click here) and we recommend using version 3.1:
docker pull sophgo/tpuc_dev:v3.1
If you are using Docker for the first time, you can run the following commands for installation and configuration (only needed for the first-time setup):
sudo apt install docker.io
sudo systemctl start docker
sudo systemctl enable docker
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp docker
Then create a container in the current directory as follows:
docker run --privileged --name MyName -v $PWD:/workspace -it sophgo/tpuc_dev:v3.1
** Replace "MyName" with the desired name for your container*
Use pip to install tpu_mlir inside the Docker container, just like in Method 1:
pip install tpu_mlir[all]==1.7
Method 2: Local Installation
First check whether the current system environment meets:
If it is not satisfied or the installation fails, choose Method 2 to install the model conversion tool.
Install tpu_mlir using pip:
pip install tpu_mlir==1.7
The dependencies required by tpu_mlir vary when handling models from different frameworks. For model files generated by ONNX or Torch, install the additional dependencies using the following command:
pip install tpu_mlir[onnx]==1.7
pip install tpu_mlir[torch]==1.7
Currently, five configurations are supported: onnx, torch, tensorflow, caffe, and paddle. Or you can use the following command to install all dependencies:
pip install tpu_mlir[all]==1.7
When the tpu_mlir-{version}.whl file already exists locally, you can also use the following command to install it:
pip install path/to/tpu_mlir-{version}.whl[all]
Convert and Quantize AI Models to the cvimodel Format
Preparing the ONNX
reCamera has already adapted the YOLO series for local inference. Therefore, this section uses yolo11n.onnx as an example to demonstrate how to convert an ONNX model to the cvimodel.
The cvimodel is the AI model format used for local inference on reCamera.
The method for converting and quantizing PyTorch, TFLite, and Caffe models is the same as that in this section.
Here is the download link for yolo11n.onnx. You can click the link to download the model and copy it to your Workspace for further use.
Download the model: Download yolo11n.onnx This ONNX file can be directly used for the examples in the following sections without the need to modify the IR version or Opset version.
Currently, ONNX in this wiki is based on IR version 8 and Opset version 17. If your ONNX file is converted from an example by Ultralytics after December 2024, it may in subsequent processes due to a higher version.
You can view the information of the ONNX file using Netron:
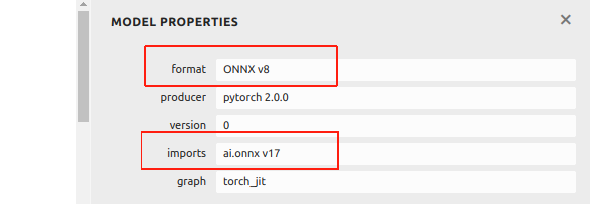
If your ONNX file is higher than IR v8 and Opset v17, , we provide a example here to help you downgrade it. Firstly, installing onnx via pip:
pip install onnx
Pull the program for modifying the version of the ONNX file from GitHub:
git clone https://github.com/jjjadand/ONNX_Downgrade.git
cd ONNX_Downgrade/
Run the script by providing the input and output model file paths as command-line arguments:
python downgrade_onnx.py <input_model_path> <output_model_path> --target_ir_version <IR_version> --target_opset_version <Opset_version>
<input_model_path>: The path to the original ONNX model you want to downgrade.<output_model_path>: The path where the downgraded model will be saved.- --target_ir_version
<IR_version>: Optional. The target IR version to downgrade to. Default is 8. - --target_opset_version
<Opset_version>: Optional. The target Opset version to downgrade to. Default is 17.
For example, using Default Versions (IR v8, Opset v17):
python downgrade_onnx.py model_v12.onnx model_v8.onnx
This will load model_v12.onnx, downgrade it to IR version 8, set opset version 17, validate, and save the new model as model_v8.onnx.
Using Custom Versions (IR v9, Opset v11):
python downgrade_onnx.py model_v12.onnx model_v9.onnx --target_ir_version 9 --target_opset_version 11
This will load model_v12.onnx, downgrade it to IR version 9, set opset version 11, validate, and save the new model as model_v9.onnx.
- To avoid errors, we recommend using ONNX with IR v8 and Opset v17.
Preparing the Workspace
Create the model_yolo11n directory at the same level as tpu-mlir. The image files are usually part of the model’s training dataset, used for calibration during the subsequent quantization process.
Enter the following command in the terminal:
git clone -b v1.7 --depth 1 https://github.com/sophgo/tpu-mlir.git
cd tpu-mlir
source ./envsetup.sh
./build.sh
mkdir model_yolo11n && cd model_yolo11n
cp -rf ${REGRESSION_PATH}/dataset/COCO2017 .
cp -rf ${REGRESSION_PATH}/image .
mkdir Workspace && cd Workspace
After obtaining a usable ONNX file, place it in the Workspace directory you created.The directory structure is as follows:
model_yolo11n
├── COCO2017
├── image
└── Workspace
└──yolo11n.onnx
Subsequent steps will be carried out in your Workspace.
ONNX to MLIR
The conversion from ONNX to MLIR is an intermediate step in the model transformation process. Before obtaining a model suitable for inference on reCamera, you need to first convert the ONNX model to the MLIR format. This MLIR file serves as a bridge to generate the final model optimized for reCamera's inference engine.
If the input is image, we need to know the preprocessing of the model before transferring it. If the model uses preprocessed npz files as input, no preprocessing needs to be considered. The preprocessing process is formulated as follows ( x represents the input):
y = (x − mean) × scale
The normalization range of yolo11 is [0, 1], and the image of the official yolo11 is RGB. Each value will be multiplied by 1/255, respectively corresponding to 0.0, 0.0, 0.0 and 0.0039216, 0.0039216, 0.0039216 when it is converted into mean and scale. The parameters for mean and scale differ depending on the model, as they are determined by the normalization method used for each specific model.
You can refer to the following model conversion command in terminal:
model_transform \
--model_name yolo11n \
--model_def yolo11n.onnx \
--input_shapes "[[1,3,640,640]]" \
--mean "0.0,0.0,0.0" \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
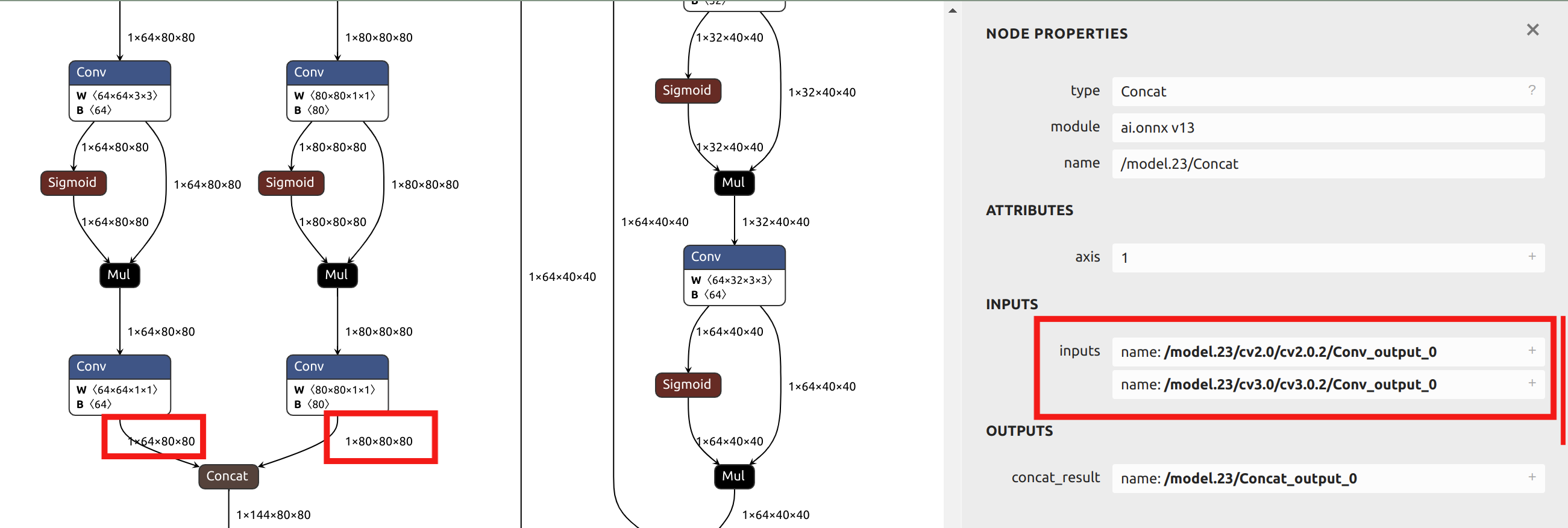
--output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" \
--test_input ../image/dog.jpg \
--test_result yolo11n_top_outputs.npz \
--mlir yolo11n.mlir
After converting to an mlir file, a ${model_name}_in_f32.npz file will be generated, which is the input file for the subsequent models.
Regarding the selection of the --output_names parameter, the YOLO11 model conversion in this example does not choose the final output named output0. Instead, it selects the six outputs before the model's head as the parameter. You can import the ONNX file into Netron to view the model structure.
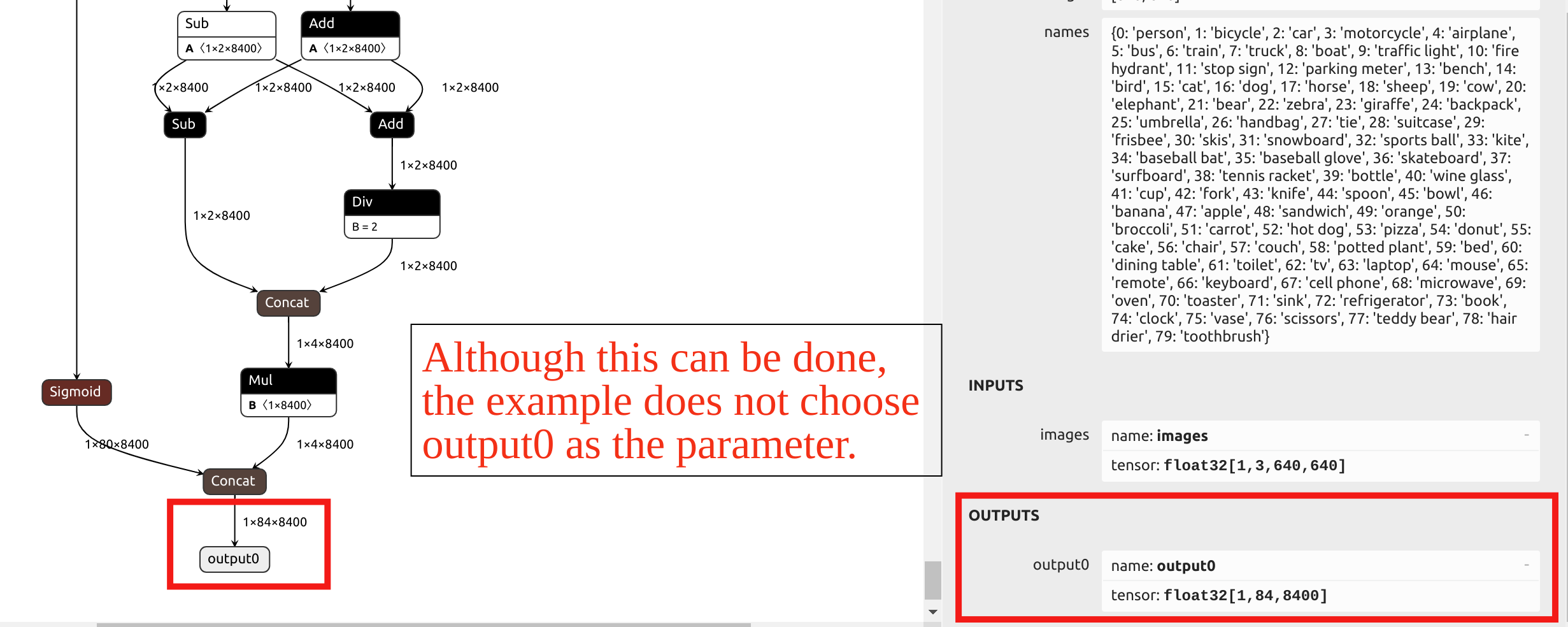
The operators in the YOLO's head have very low accuracy after INT8 quantization. If output0 at the very end were chosen as the parameter, mixed-precision quantization would be required.
Since the subsequent sections of this article will provide examples of mixed-precision quantization, and this section uses a single quantization precision for the example, the outputs before the head are chosen as parameters. By visualizing the ONNX model in Netron, you can see the positions of the six output names:
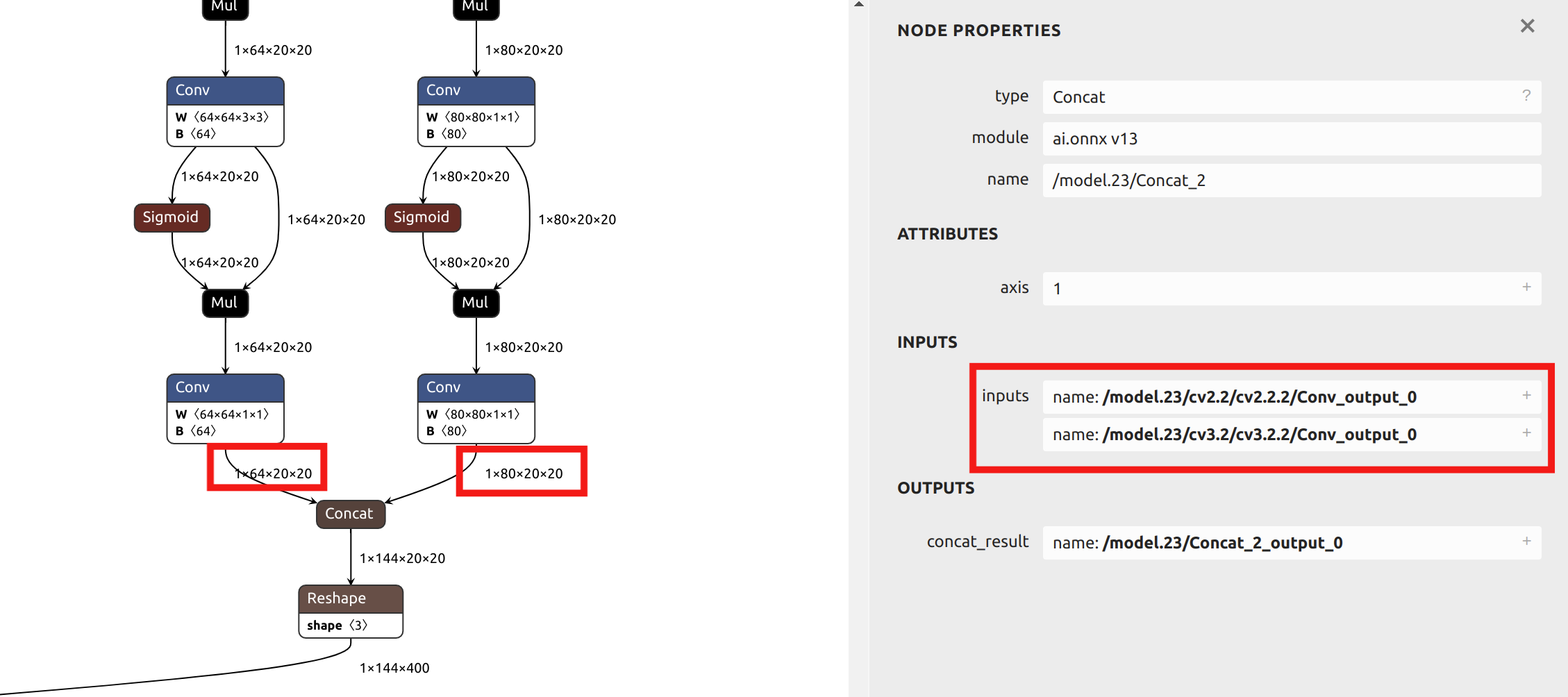
Description of Main Parameters for model_transform:
| Parameter Name | Required? | Description |
|---|---|---|
| model_name | Yes | Specify the model name. |
| model_def | Yes | Specify the model definition file, such as '.onnx', '.tflite', or '.prototxt'. |
| input_shapes | No | Specify the input shape, e.g., [[1,3,640,640]]. A two-dimensional array that can support multiple inputs. |
| input_types | No | Specify the input types, such as int32. Use commas to separate multiple inputs. Default is float32. |
| resize_dims | No | Specify the dimensions to which the original image should be resized. If not specified, it will be resized to the model's input size. |
| keep_aspect_ratio | No | Whether to keep the aspect ratio when resizing. Default is false; if true, padding with zeros will be used for missing areas. |
| mean | No | Mean value for each channel of the image. Default is 0,0,0,0. |
| scale | No | Scale value for each channel of the image. Default is 1.0,1.0,1.0. |
| pixel_format | No | Image type, which can be one of 'rgb', 'bgr', 'gray', or 'rgbd'. Default is 'bgr'. |
| channel_format | No | Channel type for image input, which can be 'nhwc' or 'nchw'. For non-image inputs, use 'none'. Default is 'nchw'. |
| output_names | No | Specify output names. If not specified, the model's default output names are used. |
| test_input | No | Specify an input file for validation, such as an image, npy, or npz file. If not specified, no accuracy validation is performed. |
| test_result | No | Specify the output file for the validation result. |
| excepts | No | Specify network layers to exclude from validation, separated by commas. |
| mlir | Yes | Specify the output MLIR file name and path. |
MLIR to F16 cvimodel
If you want to convert from mlir to F16-precision cvimodel, you can enter the following reference command in the terminal:
model_deploy \
--mlir yolo11n.mlir \
--quant_input \
--quantize F16 \
--customization_format RGB_PACKED \
--processor cv181x \
--test_input ../image/dog.jpg \
--test_reference yolo11n_top_outputs.npz \
--fuse_preprocess \
--tolerance 0.99,0.9 \
--model yolo11n_1684x_f16.cvimodel
After a successful conversion, you will obtain an FP16-precision cvimodel file that can be directly used for inference. If you need an INT8-precision or mixed-precision cvimodel file, please refer to the content in the later sections of the following article.
Description of Main Parameters for model_deploy:
| Parameter Name | Required? | Description |
|---|---|---|
| mlir | Yes | MLIR file |
| quantize | Yes | Quantization type (F32/F16/BF16/INT8) |
| processor | Yes | It depends on the platform being used. The 2024 version of reCamera selects "cv181x" as a parameter. |
| calibration_table | No | The calibration table path. Required when it is INT8 quantization |
| tolerance | No | Tolerance for the minimum similarity between MLIR quantized and MLIR fp32 inference results |
| test_input | No | The input file for validation, which can be an image, npy or npz. No validation will be carried out if it is not specified |
| test_reference | No | Reference data for validating mlir tolerance (in npz format). It is the result of each operator |
| compare_all | No | Compare all tensors, if set |
| excepts | No | Names of network layers that need to be excluded from validation. Separated by comma |
| op_divide | No | Try to split the larger op into multiple smaller op to achieve the purpose of ion memory saving, suitable for a few specific models |
| model | Yes | Name of output model file (including path) |
| skip_validation | No | Skip cvimodel correctness verification to boost deployment efficiency; cvimodel verification is on by default |
After compilation, a file named yolo11n_1684x_f16.cvimodel is generated. The quantized model may have a slight loss in accuracy, but it will be more lightweight and have faster inference speed.
MLIR to INT8 cvimodel
Calibration table generation
Before converting to the INT8 model, you need to run calibration to get the calibration table.
The number of input data is about 100 to 1000 according to the situation.
Then use the calibration table to generate a symmetric or asymmetric cvimodel. It is gen-erally not recommended to use the asymmetric one if the symmetric one already meets the requirements, because the performance of the asymmetric model will be slightly worse than the symmetric model.
Here is an example of the existing 100 images from COCO2017 to perform calibration:
run_calibration \
yolo11n.mlir \
--dataset ../COCO2017 \
--input_num 100 \
-o yolo11n_calib_table
After running the command above, a file named yolo11n_calib_table will be generated, which is used as the input file for subsequent compilation of the INT8 model.
Description of Main Parameters for run_calibration:
| Parameter | Required? | Description |
|---|---|---|
| N/A | Yes | Specify the MLIR file |
| dataset | No | Specify the input sample directory, where the path contains corresponding images, npz, or npy files |
| data_list | No | Specify the sample list; either dataset or data_list must be selected |
| input_num | No | Specify the number of calibration samples; if set to 0, all samples are used |
| tune_num | No | Specify the number of tuning samples; default is 10 |
| histogram_bin_num | No | Number of bins for the histogram; default is 2048 |
| o | Yes | Output the calibration table file |
Compile to INT8 symmetric quantized cvimodel
After obtaining the yolo11n_cali_table file, run the following command to convert it into an INT8 symmetric quantized model:
model_deploy \
--mlir yolo11n.mlir \
--quantize INT8 \
--quant_input \
--processor cv181x \
--calibration_table yolo11n_calib_table \
--test_input ../image/dog.jpg \
--test_reference yolo11n_top_outputs.npz \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--model yolo11n_1684x_int8_sym.cvimodel
After compilation, a file named yolo11n_1684x_int8_sym.cvimodel is generated. The model quantized to INT8 is more lightweight and has faster inference speed compared to models quantized to F16/BF16.
Quick Test
You can use Node-RED on reCamera for visualization to quickly verify the converted yolo11n_1684x_int8_sym.cvimodel. Simply set up a few nodes, as shown in the example video below:
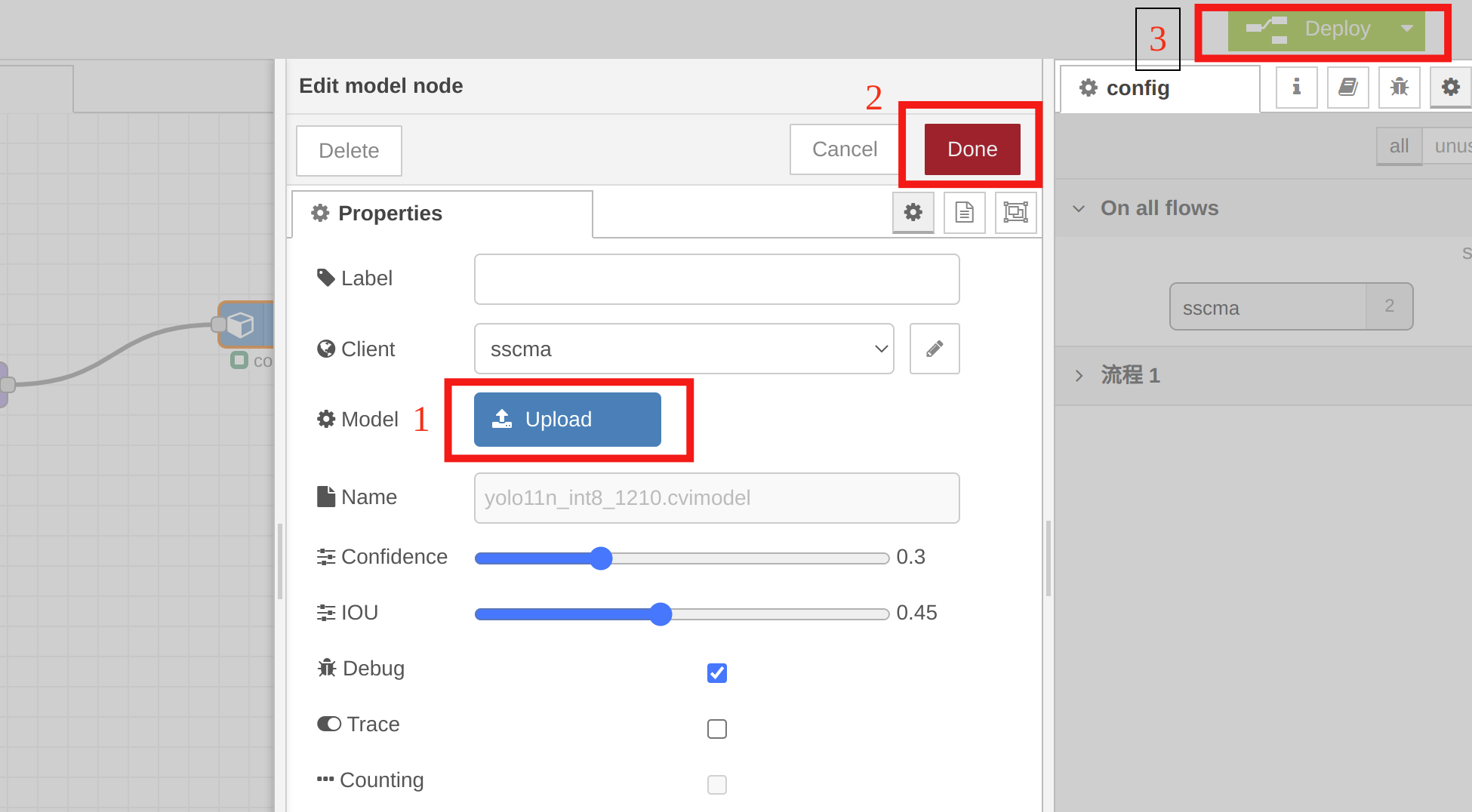
You need to select the yolo11n_1684x_int8_sym.cvimodel in the model node for quick verification. Double-click the model node, click "Upload" to import the quantized model, then click "Done", and finally click "Deploy".
We can view the inference results of the INT8 quantized model in the preview node. The cvimodel obtained through correct conversion and quantization methods is still reliable:
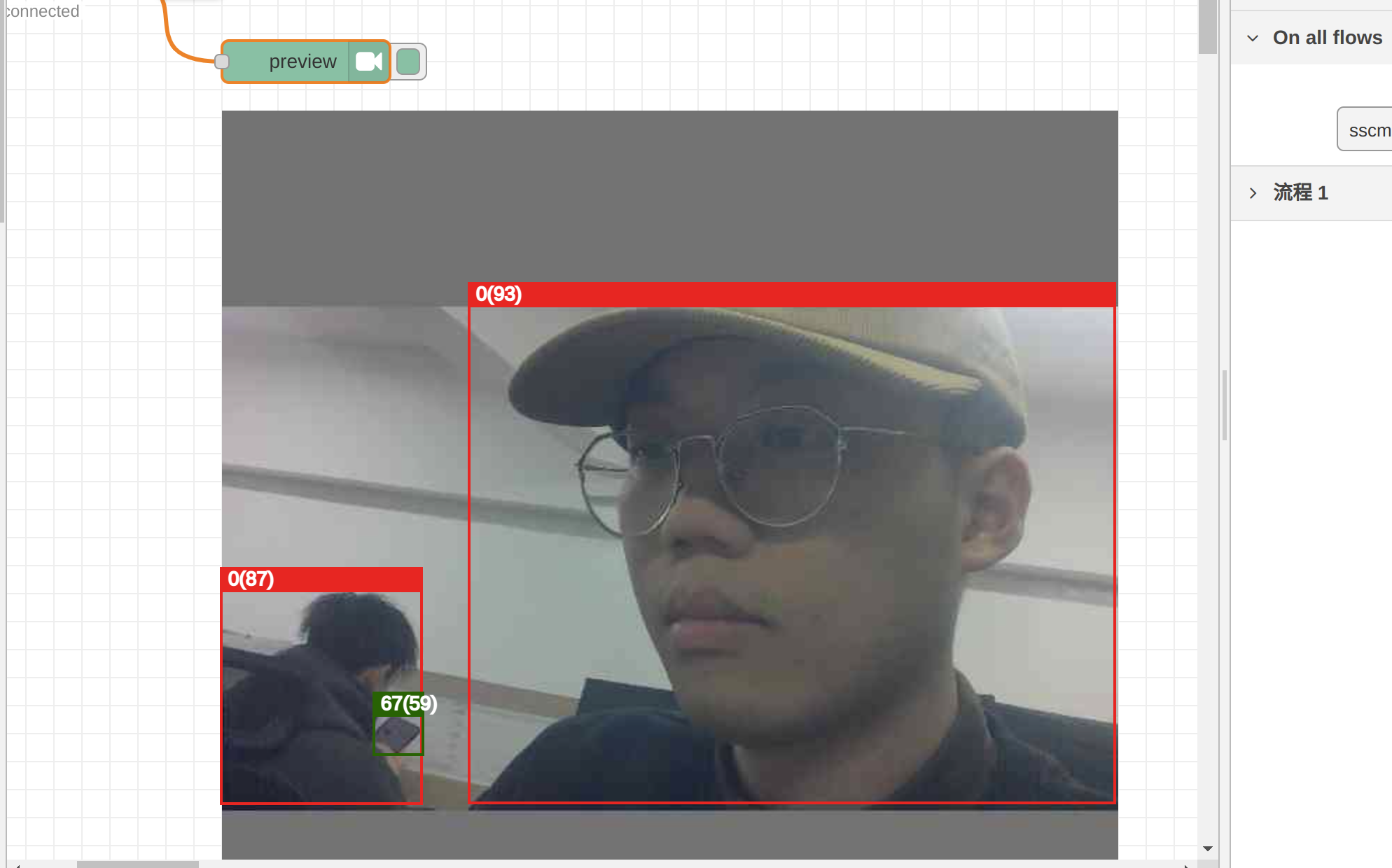
Currently, reCamera's Node-RED only supports preview testing for a limited number of models. In the future, we will adapt more models. If you import a custom model into Node-RED or do not set the specified output tensor as shown in our example, Node-RED's backend does not support preview testing, even if your cvimodel is correct.
We will release tutorials on preprocessing and postprocessing for various models, so you can write your own code to infer your custom cvimodel.
Mixed-Precision Quantization
When the precision of certain layers in a model is easily affected by quantization, but we still need faster inference speed, a single precision quantization may no longer be suitable. In such cases, mixed-precision quantization can better address the situation. For layers that are more sensitive to quantization, we can choose F16/BF16 quantization, while for layers with minimal precision loss, we can use INT8.
Next, we will use yolov5s.onnx as an example to demonstrate how to quickly convert and quantize the model into a mixed-precision cvimodel. Before reading this section, make sure you have gone through the previous sections of the article, as the operations in this section build upon the content covered earlier.
Here is the download link for yolov5s.onnx. You can click the link to download the model and copy it to your workspace for further use.
Download the model: Download yolov5s.onnx
After downloading the model, please place it into your workspace for the next steps.
mkdir model_yolov5s && cd model_yolov5s
cp -rf ${REGRESSION_PATH}/dataset/COCO2017 .
cp -rf ${REGRESSION_PATH}/image .
mkdir workspace && cd workspace
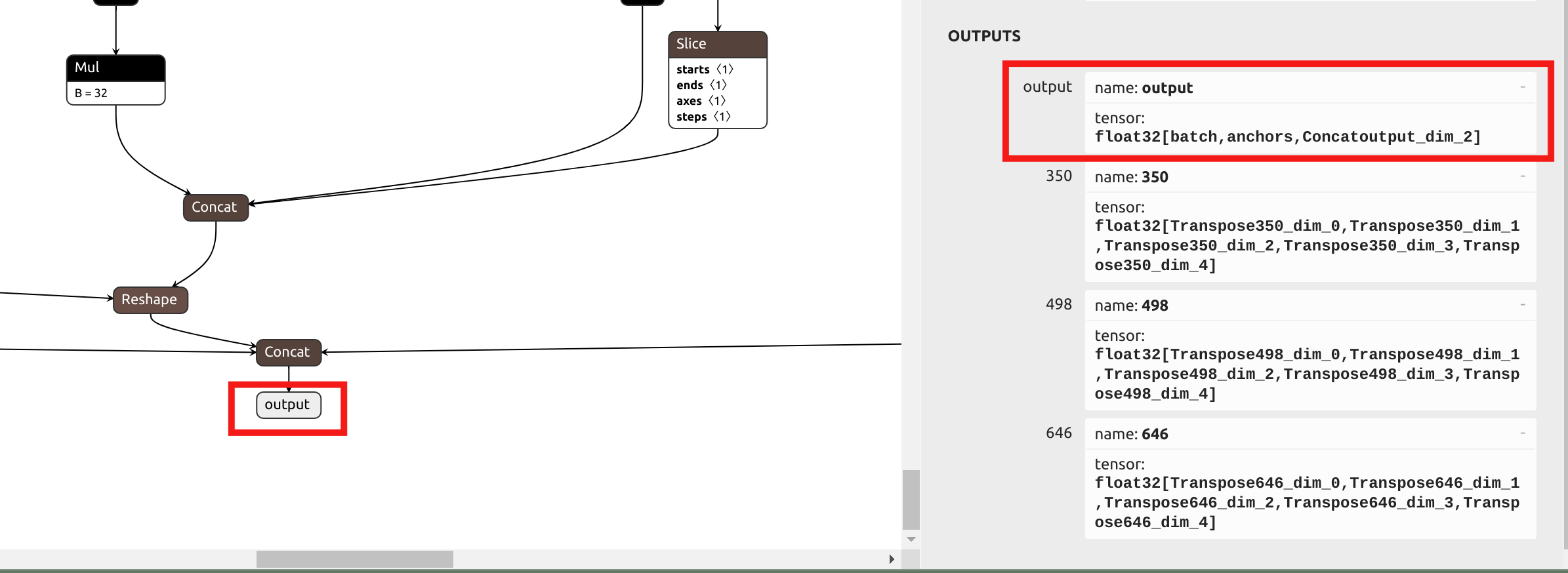
The first step is still to convert the model to the .mlir file. Because the precision loss in the YOLO's head is minimal when using mixed-precision quantization, unlike the previous approach, we will choose the final output name at the end rather than the outputs before the head in the --output_names parameter.Visualize the ONNx in Netron:
Since the normalization parameters of yolov5 are the same as those of yolo11, we can obtain the following command for model_transform:
model_transform \
--model_name yolov5s \
--model_def yolov5s.onnx \
--input_shapes [[1,3,640,640]] \
--mean 0.0,0.0,0.0 \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
--output_names output \
--test_input ../image/dog.jpg \
--test_result yolov5s_top_outputs.npz \
--mlir yolov5s.mlir
Then we also need to generate the calibration table, and this step is the same as in the previous section:
run_calibration \
yolov5s.mlir \
--dataset ../COCO2017 \
--input_num 100 \
-o yolov5s_calib_table
Unlike the section where we converted the int8 symmetric quantized yolo11 model, before executing model_deploy, we need to generate a mixed-precision quantization table.** The reference command is as follows:
run_qtable \
yolov5s.mlir \
--dataset ../COCO2017 \
--calibration_table yolov5s_calib_table \
--processor cv181x \
--min_layer_cos 0.99 \
--expected_cos 0.999 \
-o yolov5s_qtable
The parameter description for run_qtable is shown in the table below:
| Parameter | Required? | Description |
|---|---|---|
| N/A | Yes | Specify the MLIR file |
| dataset | No | Specify the input sample directory, which contains images, npz, or npy files |
| data_list | No | Specify the sample list; either dataset or data_list must be selected |
| calibration_table | Yes | Input calibration table |
| processor | Yes | It depends on the platform being used. The 2024 version of reCamera selects "cv181x" as a parameter. |
| fp_type | No | Specify the floating-point precision type for mixed precision, supports auto, F16, F32, BF16; default is auto |
| input_num | No | Specify the number of input samples; default is 10 |
| expected_cos | No | Specify the minimum expected cosine similarity for the final network output layer; default is 0.99 |
| min_layer_cos | No | Specify the minimum cosine similarity for each layer's output; values below this threshold will use floating-point computation; default is 0.99 |
| debug_cmd | No | Specify debugging command string for development use; default is empty |
| global_compare_layers | No | Specify the layers to replace for final output comparison, e.g., 'layer1,layer2' or 'layer1:0.3,layer2:0.7' |
| loss_table | No | Specify the file name to save the loss values of all layers quantized to floating-point types; default is full_loss_table.txt |
After each layer's predecessor layer is converted to the corresponding floating-point mode based on its cos, the cos value calculated for that layer is checked. If the cos is still smaller than the min_layer_cos parameter, the current layer and its direct successor layers will be set to use floating-point operations.
run_qtable recalculates the cos of the entire network's output after setting each pair of adjacent layers to use floating-point computation. If the cos exceeds the specified expected_cos parameter, the search terminates. Therefore, setting a larger expected_cos will result in more layers being attempted for floating-point operations.
Finally, run model_deploy to obtain the mixed-precision cvimodel:
model_deploy \
--mlir yolov5s.mlir \
--quantize INT8 \
--quantize_table yolov5s_qtable \
--calibration_table yolov5s_calib_table \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--processor cv181x \
--model yolov5s_mix-precision.cvimodel
After obtaining yolov5s_mix-precision.cvimodel, we can use model_tool to view detailed information about the model:
model_tool --info yolov5s_mix-precision.cvimodel
Key information such as TensorMap and WeightMap will be printed to the terminal:
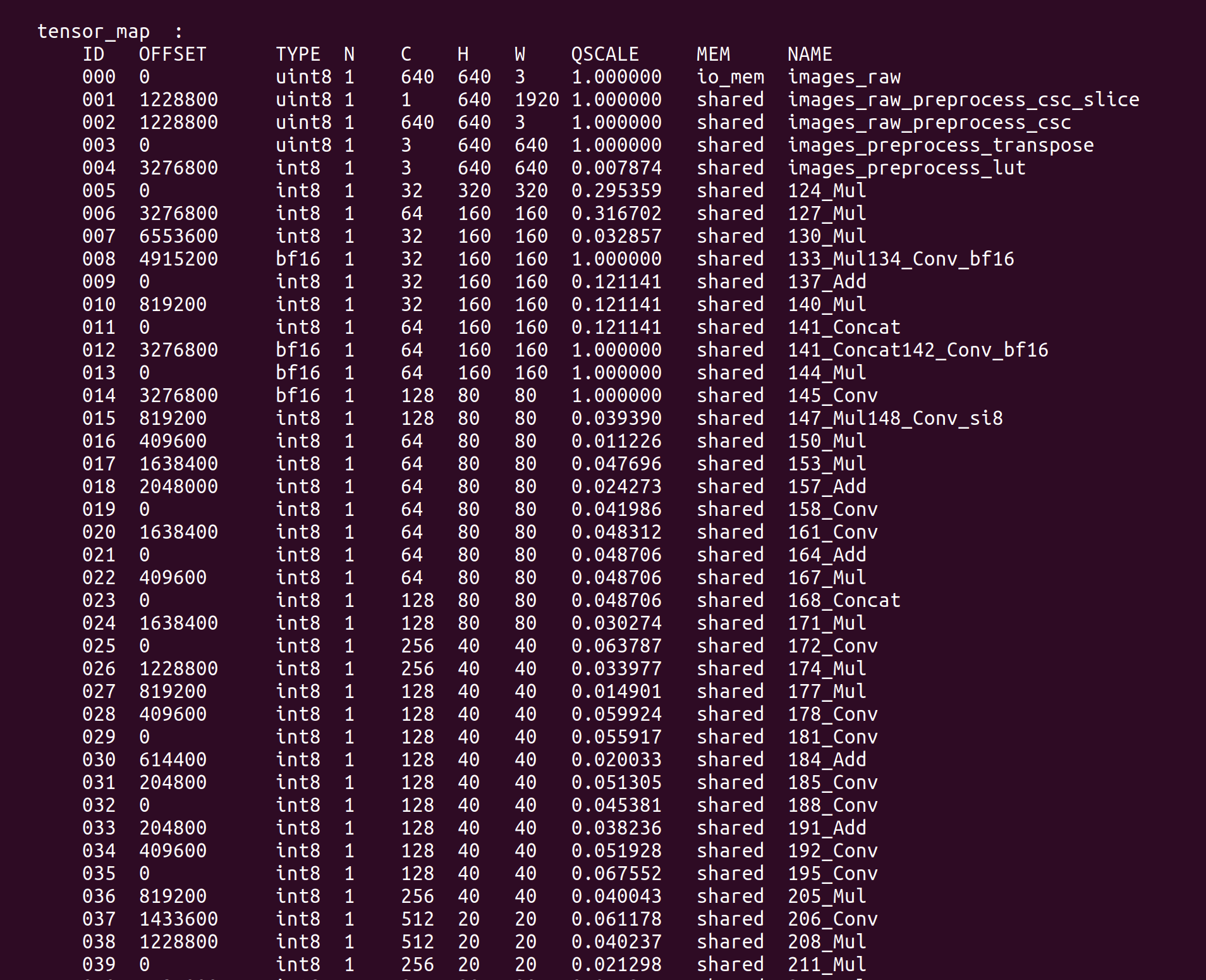
We can run an example in reCamera to verify the mixed-precision quantized YOLOv5 model. Pull the compiled test example:
git clone https://github.com/jjjadand/yolov5_Test_reCamera.git
Copy the compiled examples and yolov5s_mix-precision.cvimodelusing software like FileZilla to reCamera. (You can review Getting Started with reCamera)
After the copy is complete, run the command in the recamera terminal:
cp /path/to/yolov5s_mix-precision.cvimodel /path/to/yolov5_Test_reCamera/solutions/sscma-model/build/
cd yolov5_Test_reCamera/solutions/sscma-model/build/
sudo ./sscma-model yolov5s_mix-precision.cvimodel Dog.jpg Out.jpg
Preview Out.jog, the mixed-precision quantized yolov5 model inference results are as follows:

Resources
Tech Support & Product Discussion
Thank you for choosing our products! We are here to provide you with different support to ensure that your experience with our products is as smooth as possible. We offer several communication channels to cater to different preferences and needs.