Deploy Watcher's AI capabilities locally

SenseCAP Watcher is an AI watcher to help you monitor anomalies within a space and then take actions. While Watcher can utilize SenseCraft AI services, it also provides the option to deploy AI capabilities locally on your own devices, giving you greater control, privacy, and flexibility.
In this comprehensive guide, we will walk you through the process of setting up and deploying Watcher's AI services on your local devices. Whether you're using a Windows PC, a MacOS machine, or an NVIDIA® Jetson AGX Orin, we'll provide step-by-step instructions to help you harness the power of Watcher's AI capabilities in your own environment.
Throughout this guide, we'll cover the necessary software and hardware preparations, the deployment process for each supported platform, and how to effectively utilize Watcher's local AI services to unlock new possibilities and enhance your productivity. By the end of this guide, you'll have a solid understanding of how to leverage Watcher's AI capabilities on your own devices, empowering you to create intelligent and personalized solutions tailored to your needs.
Software Preparation
To utilize Watcher's local deployment capabilities, users first need to download the necessary software. The software package includes the Watcher application and the Device AI Service components, which enable users to set up and configure their local AI services.
Users can download the Watcher APP through the following download links:
- For Windows:
- For macOS:
- For Linux:
Please choose the appropriate download link based on your operating system. The Watcher APP is compatible with Windows, macOS, and major Linux distributions, ensuring a seamless experience across different platforms.
Hardware Preparation
To ensure a smooth and optimal experience when deploying Watcher's AI capabilities locally, your device must meet the minimum hardware requirements. These requirements vary depending on your operating system. Below are the hardware requirements for each supported platform:
| Windows | Mac | Linux (arm64) | |
|---|---|---|---|
| Graphics Card (Recommended Configuration) | GeForece RTX2070 | Apple M1 16 GB | GeForece RTX2070 |
| RAM (Minimum Configuration) | 8 GB | 16 GB | 8 GB |
| Storage (Minimum Configuration) | 20 GB | 20 GB | 20 GB |
It's important to note that these are the minimum requirements, and having higher specifications can significantly improve the performance and responsiveness of Watcher's AI services. If you plan to deploy multiple AI services simultaneously or process large amounts of data, we recommend using devices with more advanced hardware configurations.
Performance Considerations
The performance of Watcher's locally deployed AI services can vary based on your device's hardware specifications. Here are some general performance guidelines:
- RAM: Higher amounts of RAM allow for smoother multitasking and can handle more complex AI models and larger datasets.
- Graphics Card: A dedicated graphics card like the RTX2070 can greatly accelerate AI computations, especially for tasks involving computer vision and deep learning.
- Storage: Sufficient storage space is essential for storing AI models, datasets, and generated outputs. The recommended 20 GB of storage ensures ample space for Watcher's AI services.
When deploying Watcher's AI services locally, it's crucial to consider your specific use case and the complexity of the AI models you intend to use. If you require real-time processing or plan to handle resource-intensive tasks, it's recommended to opt for higher-end hardware configurations to ensure optimal performance.
By meeting the hardware requirements and considering the performance factors mentioned above, you can ensure a smooth and efficient deployment of Watcher's AI capabilities on your local device.
Devices Benchmark
Here's our response timeline after deploying AI services on some of our devices.
| Device | Windows 10 32GB with GeForce RTX4060 Graphics Card | Windows 10 16GB with non-Graphics Card | Mac Mini M1 (16 GB) | NVIDIA® Jetson AGX Orin 32GB |
|---|---|---|---|---|
| Task Analysis Time | 5s | 17m14s | 36s | 18s |
| Image Analysis Time | 4s | 4m10s | 8s | 7s |
When comparing NVIDIA Jetson AGX series products to consumer-grade graphics cards like the RTX 4090 for AI-related tasks, the Jetson AGX series offers several key advantages:
-
Industrial-grade reliability: Jetson AGX series products are designed for industrial and commercial applications, which means they have a longer Mean Time Between Failures (MTBF). They are built to operate continuously, 24/7, without encountering issues. In contrast, consumer-grade graphics cards like the RTX 4090 are not designed for such demanding, round-the-clock operation and may not offer the same level of reliability.
-
Compact size and low power consumption: Jetson AGX series products are designed with embedded and edge computing applications in mind. They have a smaller form factor and consume less power compared to high-end consumer graphics cards. This makes them more suitable for deployment in space-constrained environments and reduces the overall operating costs. The lower power consumption also means less heat generation, which is crucial for embedded systems and helps to minimize cooling requirements.
In addition to these advantages, the Jetson AGX series offers a comprehensive software stack optimized for AI workloads, making it easier for developers to create and deploy AI applications efficiently. The combination of industrial-grade reliability, compact size, low power consumption, and optimized software stack makes the Jetson AGX series a compelling choice for AI-related projects and applications, especially when compared to consumer-grade graphics cards like the RTX 4090.
Deployment on Windows
To deploy Watcher's AI capabilities on a Windows device, follow these simple steps.
Step 1. Locate the downloaded .exe file in your computer's downloads folder or the specified location. Double-click on the .exe file to start the installation process. The installation wizard will guide you through the setup process. You don't need to make any additional selections or configurations during the installation.
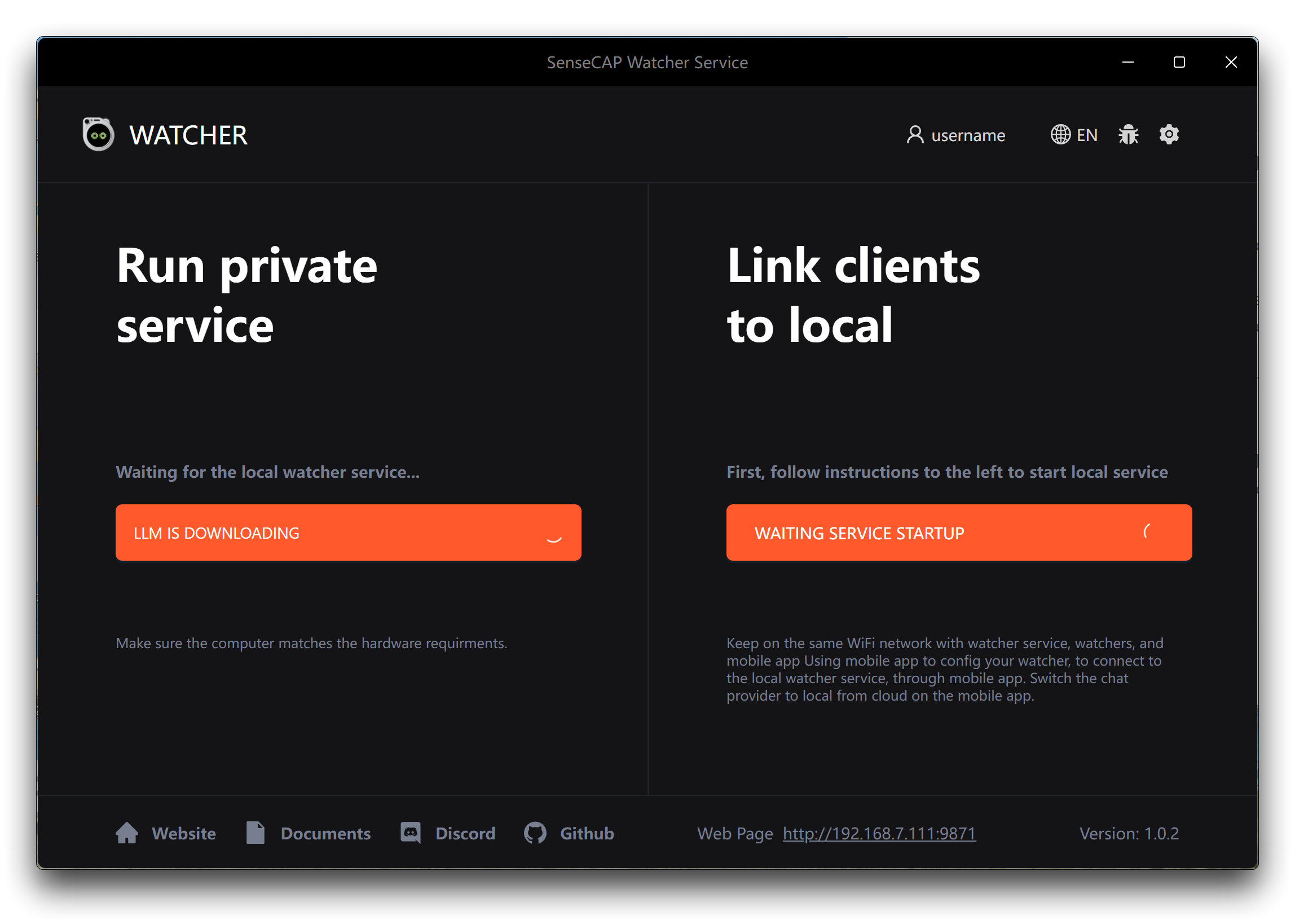
Step 2. When the installation is finished, launch the Watcher application. Upon launching the application for the first time, you will be prompted to choose the AI models you wish to use. Watcher provides two options.
-
Llama 3.1 + LLaVA: If you select this option, click the Apply button below to start downloading the required AI models and associated files. These additional downloads may take some time, as they can be around 10 GB in size. Ensure that you have a stable and fast internet connection during the model download process to avoid any interruptions or incomplete downloads.
-
OpenAI: If you prefer to use OpenAI's models, you need to prepare your OpenAI API key in advance. Make sure you have a valid API key and sufficient credits to use the OpenAI models. When prompted, enter your API key to configure Watcher to use OpenAI's services.
Choose the option that best suits your needs and resources. If you have ample storage space and a reliable internet connection, the Llama 3.1 + LLaVA option provides a self-contained solution. If you prefer the flexibility and power of OpenAI's models and have an API key ready, select the OpenAI option.
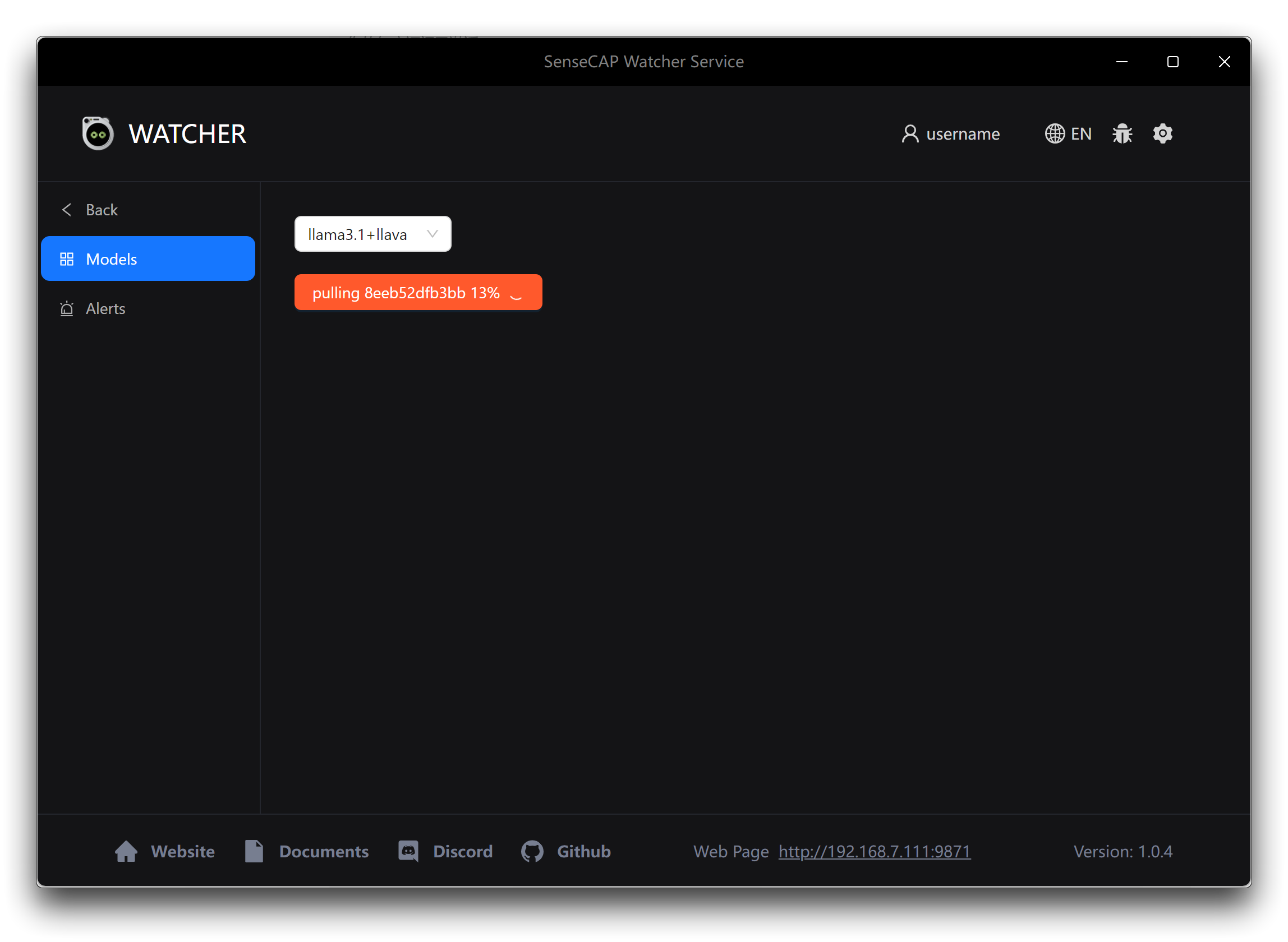
Once the model files are downloaded and installed, Watcher will be ready to use on your Windows device.
Deployment on MacOS
To deploy Watcher's AI capabilities on a macOS device, follow these steps.
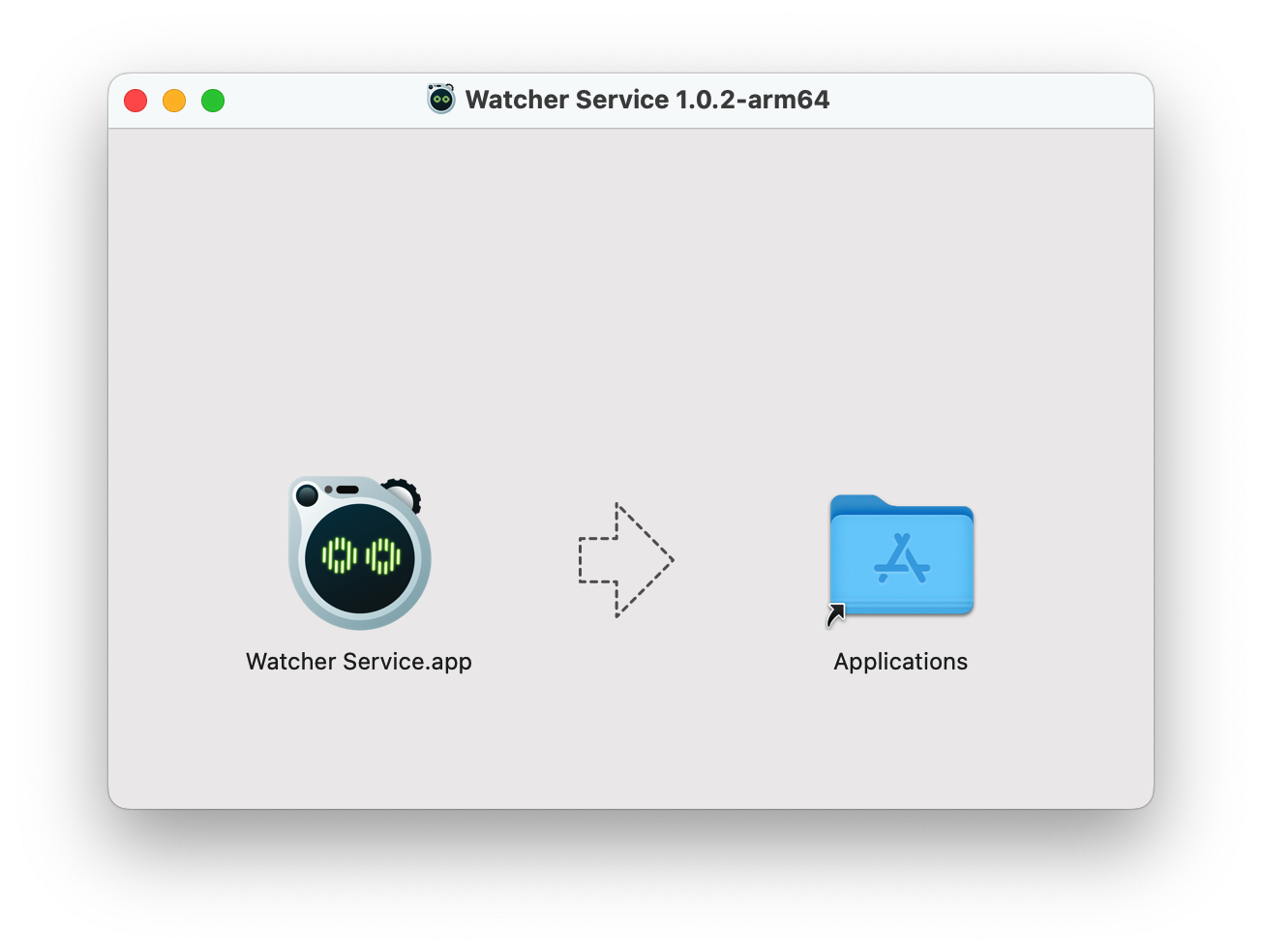
Step 1. Locate the downloaded .dmg file in your computer's downloads folder or the specified location. Double-click on the .dmg file to open it. A new window will appear, showing the contents of the installation package.
Step 2. In the new window, you will see the Watcher application icon and an alias for the Applications folder. Click and drag the Watcher application icon onto the Applications folder alias within the window. This action will copy the Watcher application to your computer's Applications folder.
Once the copying process is complete, you can close the .dmg window.
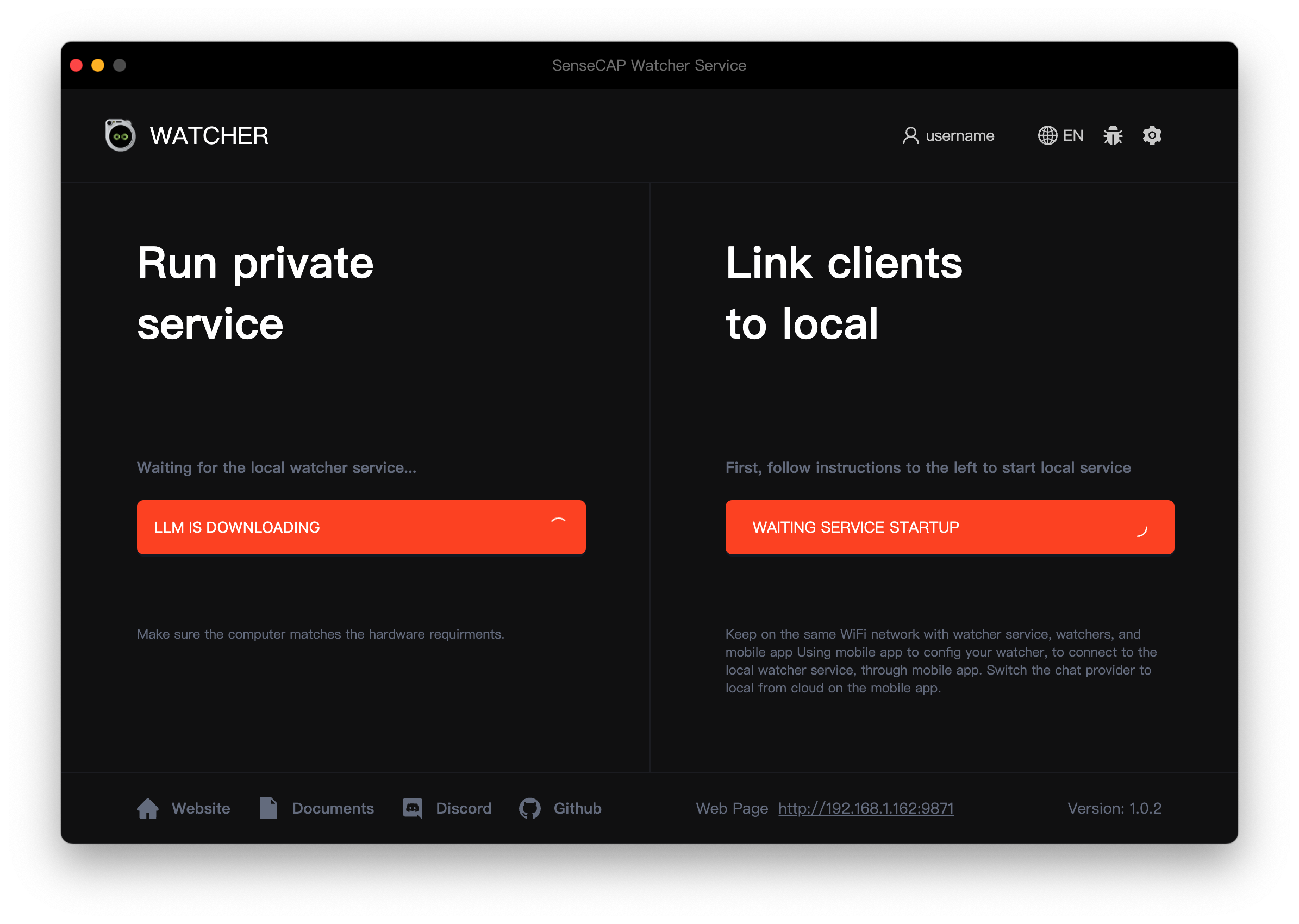
Step 3. Upon launching the application for the first time, Watcher will automatically start downloading the required AI models and associated files. These additional downloads may take some time, as they can be around 10 GB in size. Ensure that you have a stable and fast internet connection during the model download process to avoid any interruptions or incomplete downloads.
-
Llama 3.1 + LLaVA: If you select this option, click the Apply button below to start downloading the required AI models and associated files. These additional downloads may take some time, as they can be around 10 GB in size. Ensure that you have a stable and fast internet connection during the model download process to avoid any interruptions or incomplete downloads.
-
OpenAI: If you prefer to use OpenAI's models, you need to prepare your OpenAI API key in advance. Make sure you have a valid API key and sufficient credits to use the OpenAI models. When prompted, enter your API key to configure Watcher to use OpenAI's services.
Choose the option that best suits your needs and resources. If you have ample storage space and a reliable internet connection, the Llama 3.1 + LLaVA option provides a self-contained solution. If you prefer the flexibility and power of OpenAI's models and have an API key ready, select the OpenAI option.
Once the model files are downloaded and installed, Watcher will be ready to use on your macOS device.
Deployment on NVIDIA® Jetson AGX Orin / Linux
To deploy Watcher's AI capabilities on an NVIDIA® Jetson AGX Orin or a Linux device, follow these steps.
Step 1. Open a terminal window on your Jetson AGX Orin or Linux device.
Step 2. Navigate to the directory where the downloaded .deb file is located using the cd command. Run the following command to install Watcher.
sudo dpkg -i watcher_service_x.x.x_arm64.deb
Replace watcher_service_x.x.x_arm64.deb with the actual name of the downloaded .deb file. The installation process will begin. You may be prompted to enter your system password to authorize the installation. Wait for the installation to complete. The terminal will display the progress and any additional information.
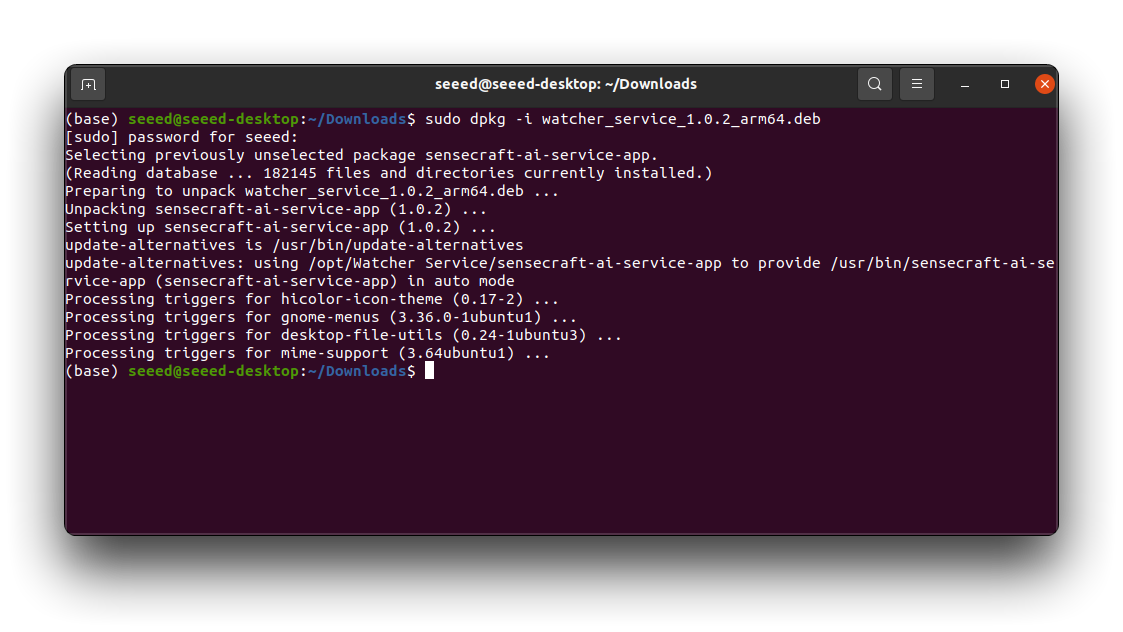
Step 3. Once the installation is finished, you can launch Watcher by typing watcher in the terminal or by finding it in your application launcher.
-
Llama 3.1 + LLaVA: If you select this option, click the Apply button below to start downloading the required AI models and associated files. These additional downloads may take some time, as they can be around 10 GB in size. Ensure that you have a stable and fast internet connection during the model download process to avoid any interruptions or incomplete downloads.
-
OpenAI: If you prefer to use OpenAI's models, you need to prepare your OpenAI API key in advance. Make sure you have a valid API key and sufficient credits to use the OpenAI models. When prompted, enter your API key to configure Watcher to use OpenAI's services.
Choose the option that best suits your needs and resources. If you have ample storage space and a reliable internet connection, the Llama 3.1 + LLaVA option provides a self-contained solution. If you prefer the flexibility and power of OpenAI's models and have an API key ready, select the OpenAI option.
Similar to the Windows and macOS installations, Watcher will automatically start downloading the required AI models and associated.
Configure the use of local AI services on the SenseCraft APP
To use the local AI services provided by Watcher in the SenseCraft APP, follow these concise steps:
Step 1. Open the Watcher APP on your device and click the Start Service button in the bottom-left section.
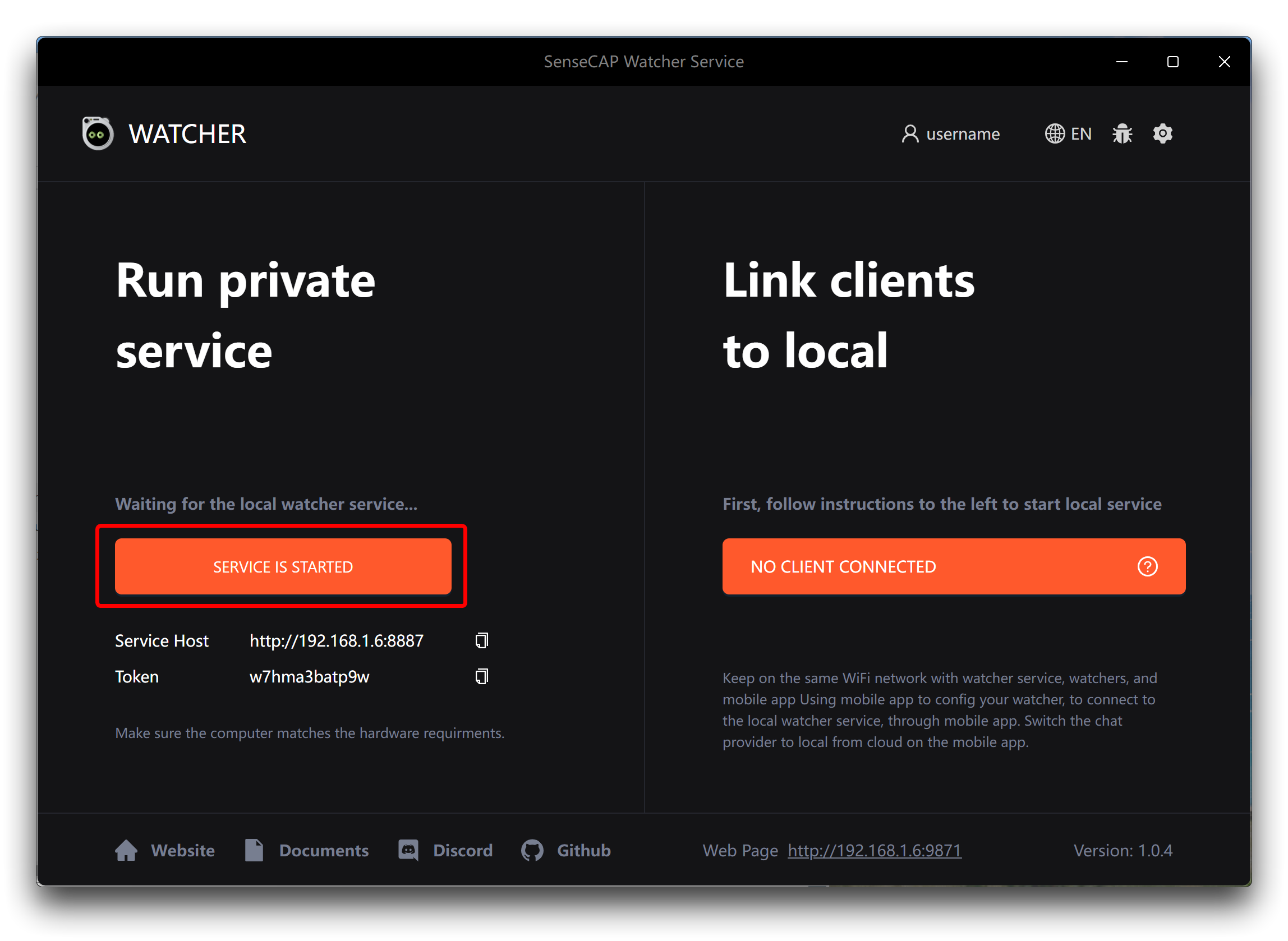
Step 2. In the SenseCraft APP, navigate to the Watcher interface and tap on the settings button in the top-right corner. Select Device AI Service from the settings menu.
Step 3. Copy the URL and Token from the Watcher APP's home screen.
Step 4. Paste the URL and Token into their respective fields in the Device AI Service settings within the SenseCraft APP.
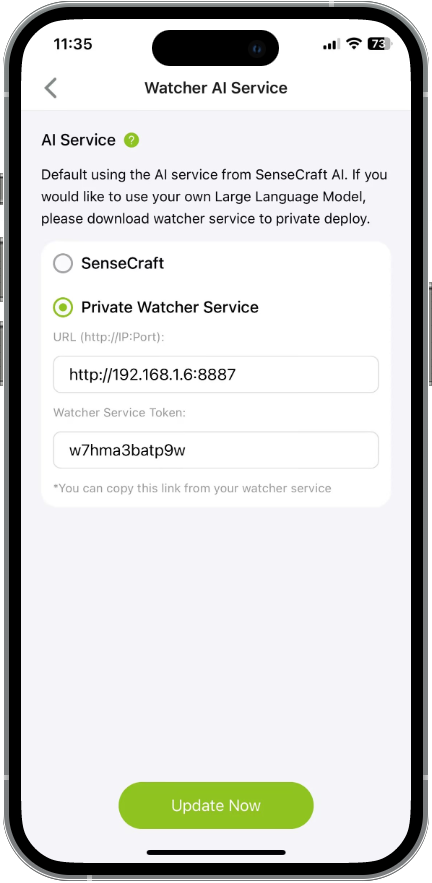
Step 5. You can now assign tasks to Watcher through the SenseCraft APP, and Watcher will process them using its locally deployed AI capabilities.
Please note that it is important to make sure that your computer meets the recommended computer configurations in Hardware Preparation. If it is below the recommended configuration, then you may not receive the recognition results and alarm messages on time, as your computer may be in full swing analysing one of your images, at which point Watcher will appear to be in a constant state of observation.
By completing these steps, you can harness the power of Watcher's AI services directly on your device, ensuring enhanced privacy and the ability to conveniently customize your own integrated system. With Watcher's AI capabilities running locally, you can perform advanced tasks, analysis, and automation securely and efficiently, all while keeping your data under your control.
We will continue to add tutorials on using HTTP Message Block for message push after localised deployment in the Application directory, so stay tuned!
FAQ
SenseCap Watcher Service don't work
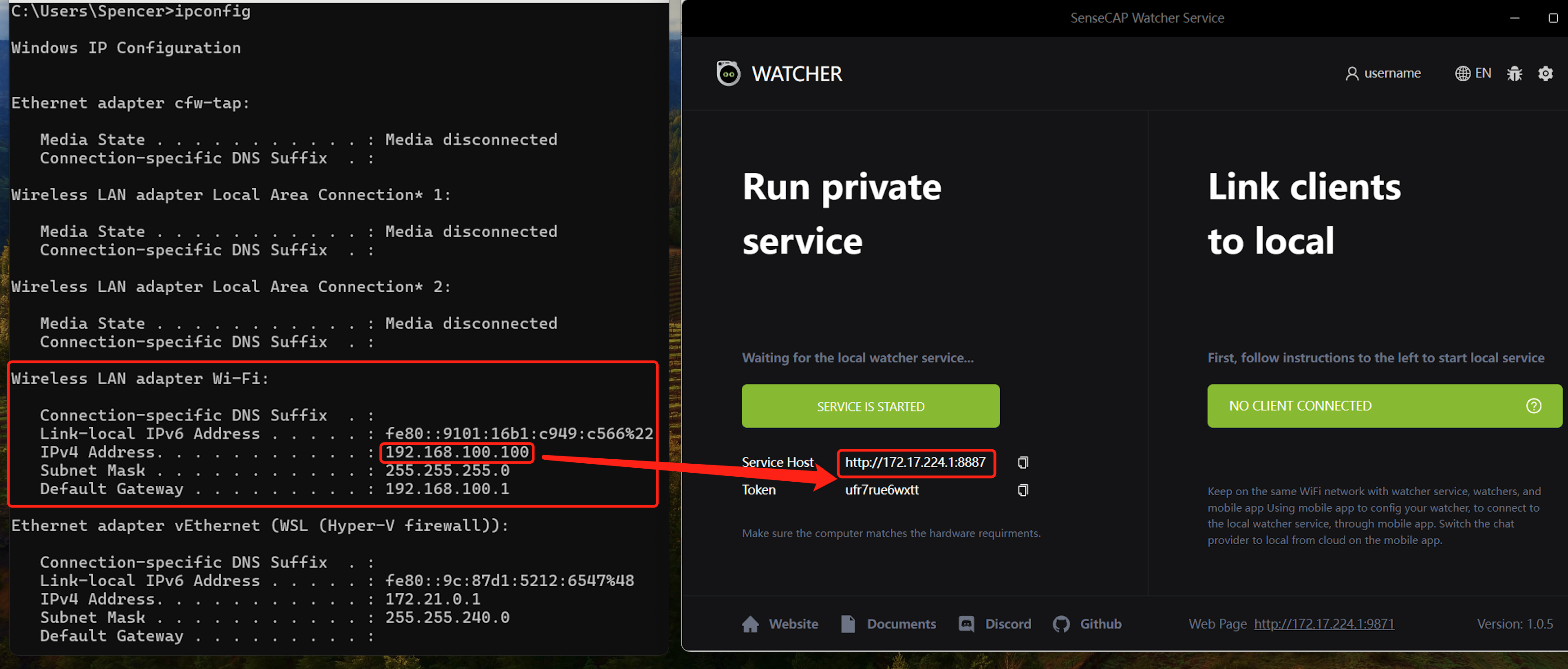
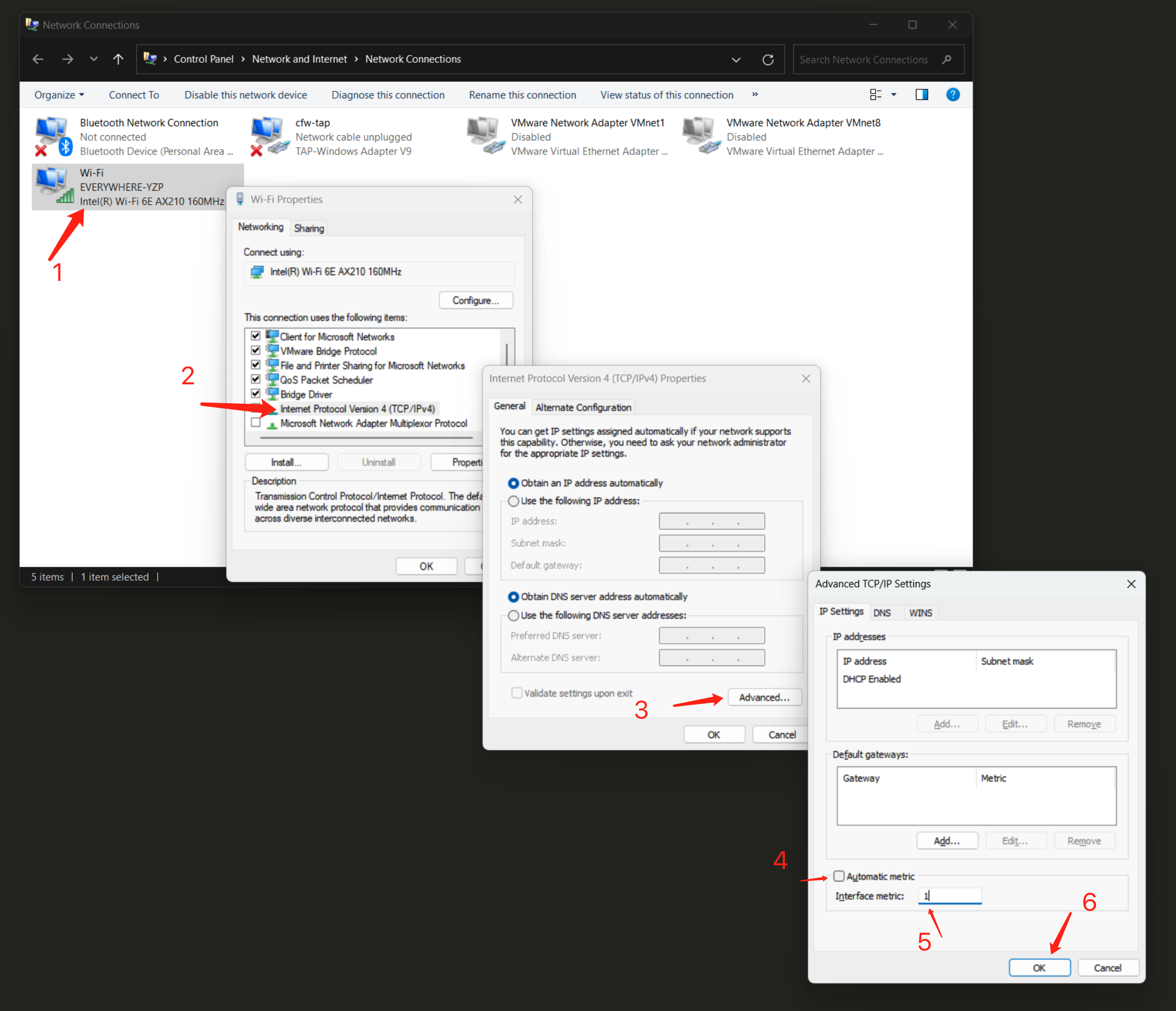
The IP of Service Host should be your computer IP address, if not, SenseCAP Watcher Service won’t work. You need to fix that by following steps.
-
Press Win + R > type "ncpa.cpl" > Enter.
-
Right-click "Wi-Fi" or Ethernet > select "Properties."
-
Double-click on IPv4 or IPv6 > Click "Advanced."
-
Uncheck Automatic Metric > Enter 1 (or your desired number) > Click OK.
Tech Support & Product Discussion
Thank you for choosing our products! We are here to provide you with different support to ensure that your experience with our products is as smooth as possible. We offer several communication channels to cater to different preferences and needs.