Overview

ReSpeaker 2-Mics Pi HAT is a dual-microphone expansion board for Raspberry Pi designed for AI and voice applications. This means that you can build a more powerful and flexible voice product that integrates Amazon Alexa Voice Service, Google Assistant, and so on.
The board is developed based on WM8960, a low power stereo codec. There are 2 microphones on both sides of the board for collecting sounds and it also provides 3 APA102 RGB LEDs, 1 User Button and 2 on-board Grove interfaces for expanding your applications. What is more, 3.5mm Audio Jack or JST 2.0 Speaker Out are both available for audio output.
Features
- Raspberry Pi compatible(Support Raspberry Pi Zero and Zero W, Raspberry Pi B+, Raspberry Pi 2 B, Raspberry Pi 3 B, Raspberry Pi 3 B+, Raspberry Pi 3 A+ and Raspberry Pi 4)
- 2 Microphones
- 2 Grove Interfaces
- 1 User Button
- 3.5mm Audio Jack
- JST2.0 Speaker Out
- Max Sample Rate: 48Khz
Application Ideas
- Voice Interaction Application
- AI Assistant
Hardware Overview
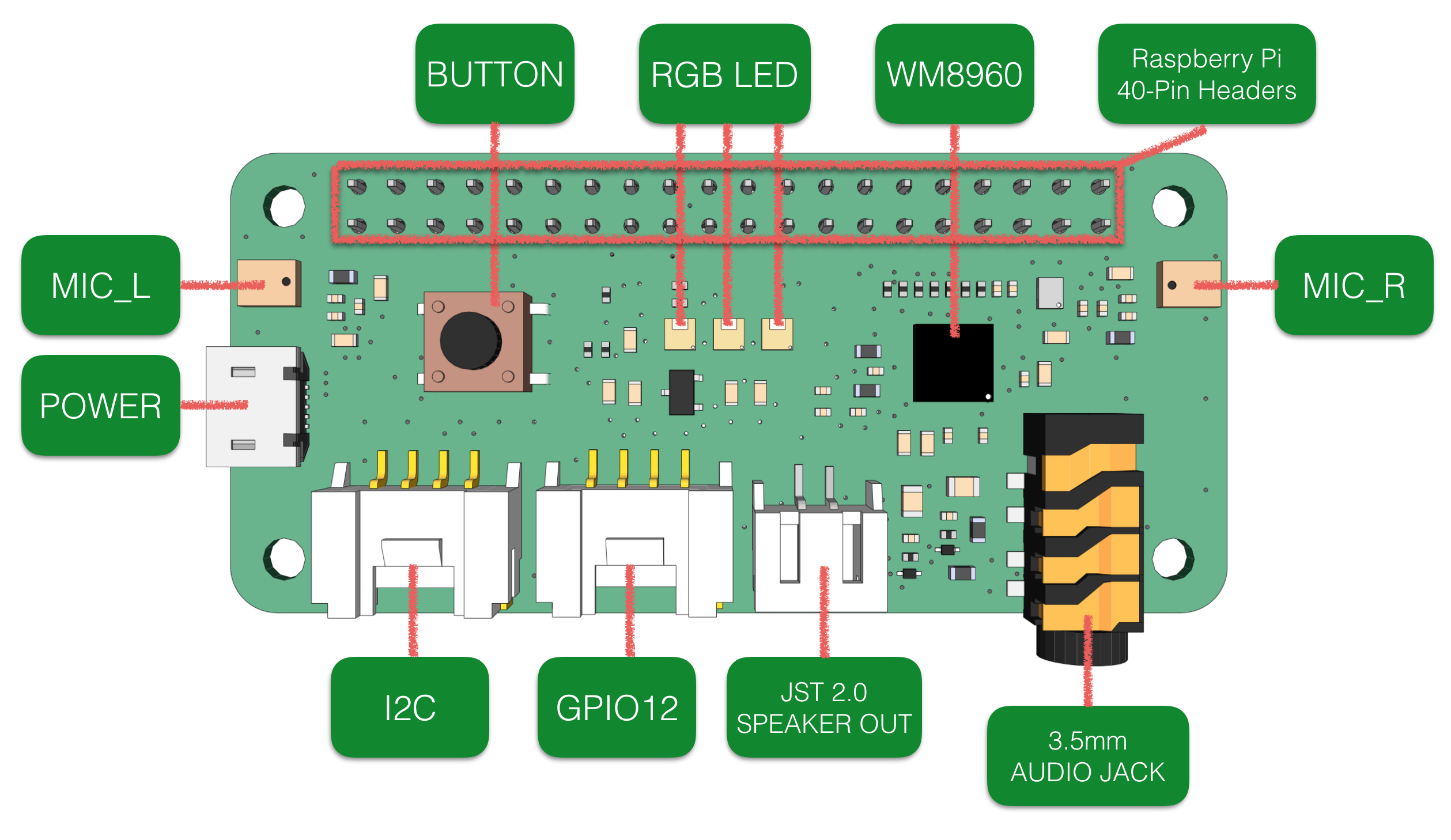
- BUTTON: a User Button, connected to GPIO17
- MIC_Land MIC_R: 2 Microphones on both sides of the board
- RGB LED: 3 APA102 RGB LEDs, connected to SPI interface
- WM8960: a low power stereo codec
- Raspberry Pi 40-Pin Headers: support Raspberry Pi Zero, Raspberry Pi 1 B+, Raspberry Pi 2 B , Raspberry Pi 3 B and Raspberry Pi 3 B+
- POWER: Micro USB port for powering the ReSpeaker 2-Mics Pi HAT, please power the board for providing enough current when using the speaker.
- I2C: Grove I2C port, connected to I2C-1
- GPIO12: Grove digital port, connected to GPIO12 & GPIO13
- JST 2.0 SPEAKER OUT: for connecting speaker with JST 2.0 connector
- 3.5mm AUDIO JACK: for connecting headphone or speaker with 3.5mm Audio Plug
Supported Platforms



Enabling Voice Recognition at the Edge with Picovoice

Picovoice enables enterprises to innovate and differentiate rapidly with private voice AI. Build a unified AI strategy around your brand and products with our speech recognition and Natural-language understanding (NLU) technologies.
Seeed has partnered with Picovoice to bring Speech Recognition solution at the edge using ReSpeaker 2-Mic Pi HAT for developers.
Picovoice is an end-to-end platform for building voice products on your terms. It enables creating voice experiences similar to Alexa and Google. But it entirely runs 100% on-device. There are advantages of Picovoice:
- Private: Everything is processed offline. Intrinsically HIPAA and GDPR compliant.
- Reliable: Runs without needing constant connectivity.
- Zero Latency: Edge-first architecture eliminates unpredictable network delay.
- Accurate: Resilient to noise and reverberation. It outperforms cloud-based alternatives by wide margins.
- Cross-Platform: Design once, deploy anywhere. Build using familiar languages and frameworks.
Open-source Keyword detection with Mycroft Precise
In addition to Picovoice, we provide limited support for Mycroft Precise - an open-source real-time keyword detection package. Mycroft Precise is fully open source and can be trained to recognize anything from a name to a cough. Precise is designed to run on Linux. It is known to work on a variety of Linux distributions including Debian, Ubuntu and Raspbian. According to official README file, "it probably operates on other *nx distributions."
Mycroft Precise is Apache-2.0 License project, which means you can modify and distribute it, including for commercial purposes - the only requirement being that you preserve the original license.
You can find examples for both Picovoice products and Mycroft Precise in Getting Started documentation for corresponding platform.
Schematic Online Viewer
Resources
-
[Eagle] Respeaker_2_Mics_Pi_HAT_SCH
-
[Eagle] Respeaker_2_Mics_Pi_HAT_PCB
-
[Driver] Seeed-Voice Driver
-
[Algorithms] Algorithms includes DOA, VAD, NS
-
[Voice Engine] Voice Engine project, provides building blocks to create voice enabled objects
-
[Algorithms] AEC
-
[Eagle] Respeaker_2_Mics_Pi_HAT_SCH_v2
Projects
Build Your Own Amazon Echo Using a RPI and ReSpeaker HAT: How to build your own Amazon Echo using a Raspberry Pi and ReSpeaker 2-Mics HAT.
Your personal home barista comes to life with this voice-enabled coffee machine: An open-source, private-by-design coffee machine that keeps your favorite coffee and caffeination schedule private.
Tech Support & Product Discussion
Thank you for choosing our products! We are here to provide you with different support to ensure that your experience with our products is as smooth as possible. We offer several communication channels to cater to different preferences and needs.