Knife Detection: An Object Detection Model deployed on Triton Inference Sever based on reComputer
Security check is a safety alarm for the consideration of passengers and the transportation sectors, keeping danger away, usually applying in the airports, railway stations, subway stations, etc. In the existing security inspection field, security inspection machines are deployed on the inbound passages of public transportation. In general, it requires multiple devices to work at the same time.
Nevertheless, the detection performance of prohibited items in X-ray images is still not ideal due to the overlapping of detected objects during the security inspection. For this matter, based on the de-occlusion module in the Triton Interface Sever, deploying a prohibited item detection algorithm in the Xray images can perform a better way.
Hence, credit to Yanlu Wei, Renshuai Tao et al., we provide this fundamental project that we are going to deploy a Deep Learning model on reComputer J1010 that could detect prohibited items (knives) with the Raspberry Pi and the reComputer J1010 where we use one reComputer J1010 as our inference server and two Raspberry Pi to simulate security inspection machines as sending images. The reComputer 1020, reComputer J2011, reComputer J2012 and Nvidia Jetson AGX Xavier are all supported.
Getting Started
Triton Inference Server provides a cloud and edge inferencing solution, optimized for both CPUs and GPUs. Triton supports an HTTP/REST and GRPC protocol that allows remote clients to request inferencing for any model being managed by the server. Here we are going to use Triton (Triton Inference Server) as our local server which will be deployed detection model.
Hardware
Hardware Required
In this project the required devices are shown as below:
- Raspberry Pi 4B*2
- reComputer J1010
- HDMI-display screen, mouse and keyboard
- PC
Hardware Setup
Two Raspberry Pi and reComputer should be powered on and all of them should be under the same internet. In this project, we use two Raspberry pi to simulate security machine's work since the security inspection machines are used by multiple devices in most instances. Hence, both
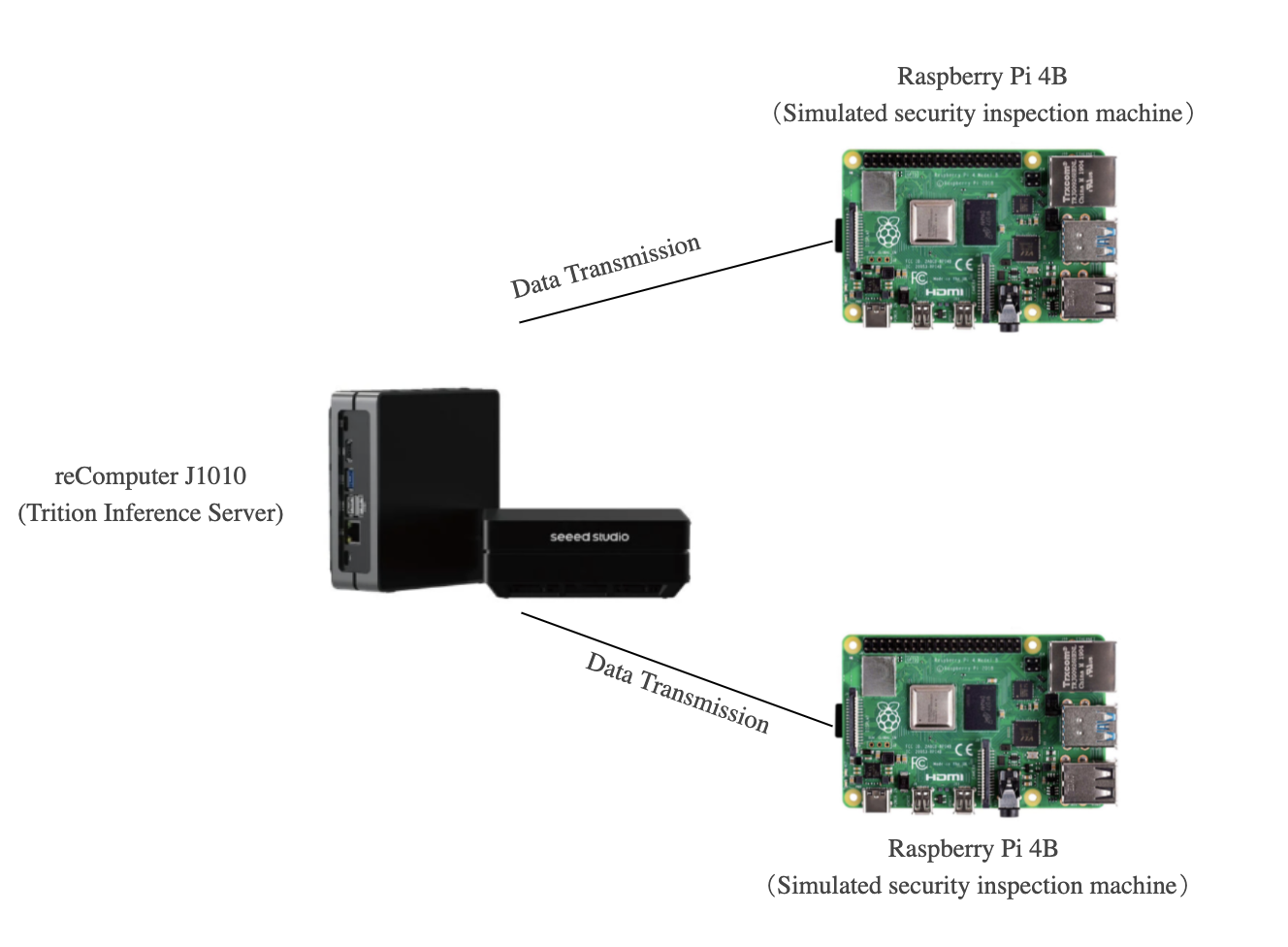
Just one Raspberry Pi could be also applied to this project. However, simultaneous knife detection on two devices demonstration could offer better dynamic batching capabilities of the Triton Inference Server. In the next instruction, we will introduce you how to set up the software on Raspberry Pi and reComputer J1010.
Software
We here use Xray images dataset as our input data which will be placed on the Raspberry Pi. After that, reComputer will output the processed inference results to the Raspberry Pi. In the end, the Raspberry Pi will complete the final work and display on the screen, i.e., the last layer of inference model will be deployed on the Raspberry Pi.
Set up Raspberry Pi
We here will show you how to set up required softwares on Raspberry Pi, including
Step 1. Install the Raspbian Buster system and basic configuration from the official website. In this project, we use RASPBERRY PI OS(64 bit) as our operated system.
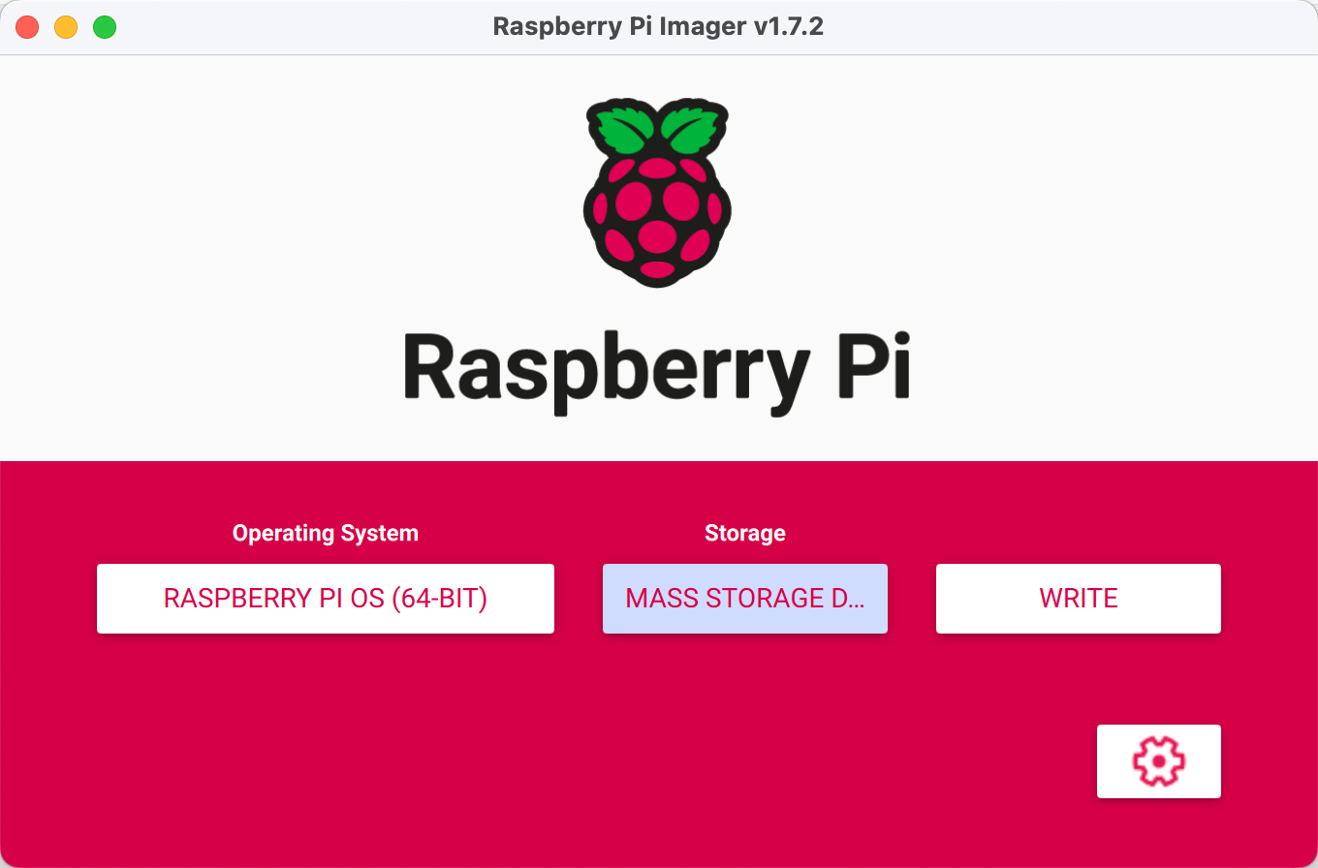
Step 2. Configure the Raspberry Pi SSH port (optional).
Before deploying the environment, we can open the Raspberry Pi SSH port and call it remotely using the SSH interface on the PC.
Notice: make sure the PC and Raspberry Pi are under the same LAN.
Step 3. Configure the Python environment.
We need to deploy the required environments for the inference model as Python, PyTorch, Tritonclient, and TorchVision. and image display as OpenCV on the Raspberry Pi. We provide the instructions below:
Python
We can execute python –V and ensure the Python version is 3.9.2. We need to install PyTorch, Torchclient and TorchVision that the versions we need are corresponding to the Python version 3.9.2. You can refer to here to download and install.
PyTorch
If the Python version is correct. We can now install Pytorch.
Notice: Before we install Pytorch, we have to check out Raspbian version.
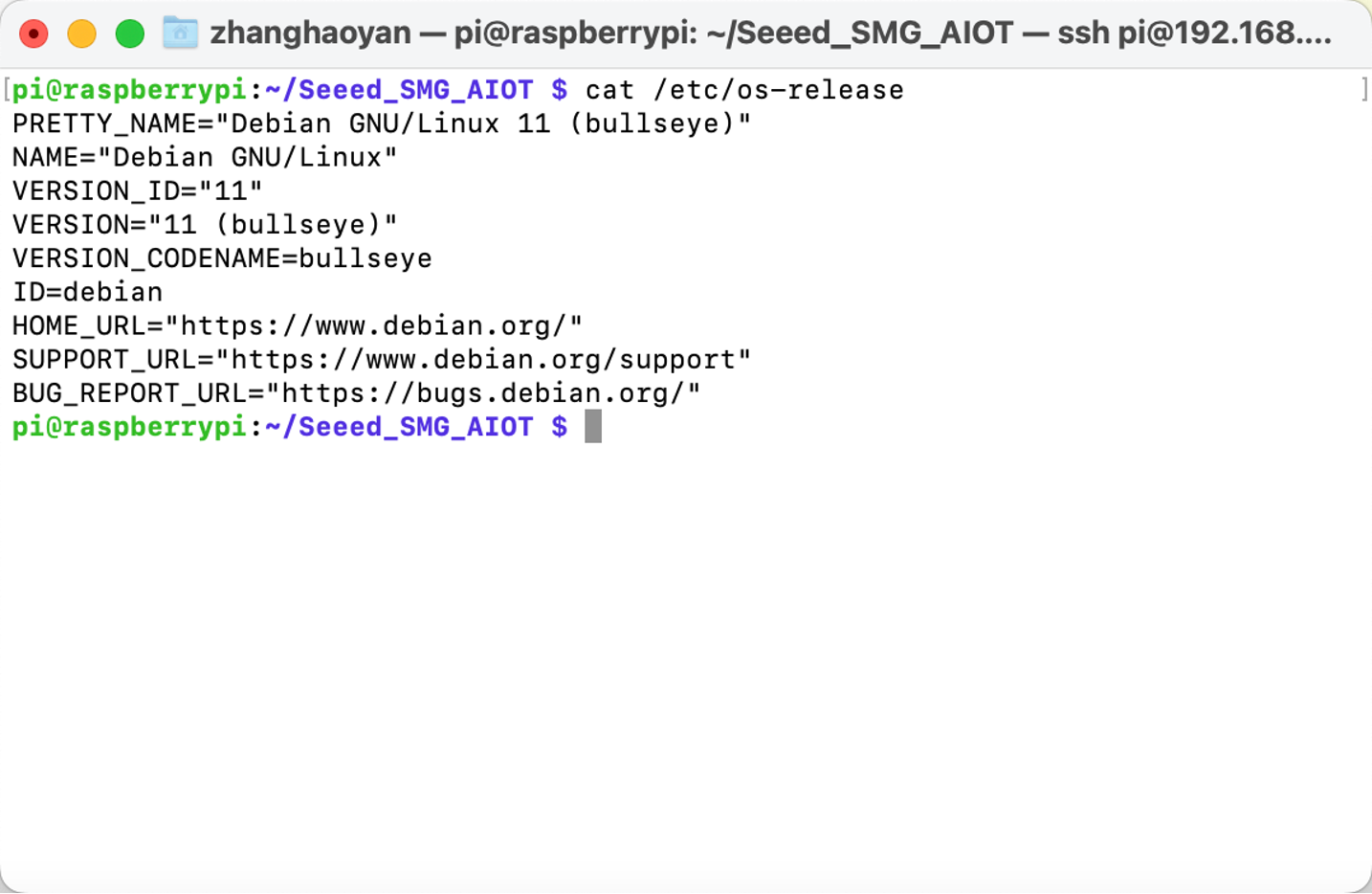
Execute the command below to install Pytorch:
# get a fresh start
sudo apt-get update
sudo apt-get upgrade
# install the dependencies
sudo apt-get install python3-pip libjpeg-dev libopenblas-dev libopenmpi-dev libomp-dev
# above 58.3.0 you get version issues
sudo -H pip3 install setuptools==58.3.0
sudo -H pip3 install Cython
# install gdown to download from Google drive
sudo -H pip3 install gdown
# Buster OS
# download the wheel
gdown https://drive.google.com/uc?id=1gAxP9q94pMeHQ1XOvLHqjEcmgyxjlY_R
# install PyTorch 1.11.0
sudo -H pip3 install torch-1.11.0a0+gitbc2c6ed-cp39-cp39-linux_aarch64.whl
# clean up
rm torch-1.11.0a0+gitbc2c6ed-cp39-cp39m-linux_aarch64.whl
After a successful installation, we can check PyTorch with the following commands after initiating python:
import torch as tr
print(tr.__version__)
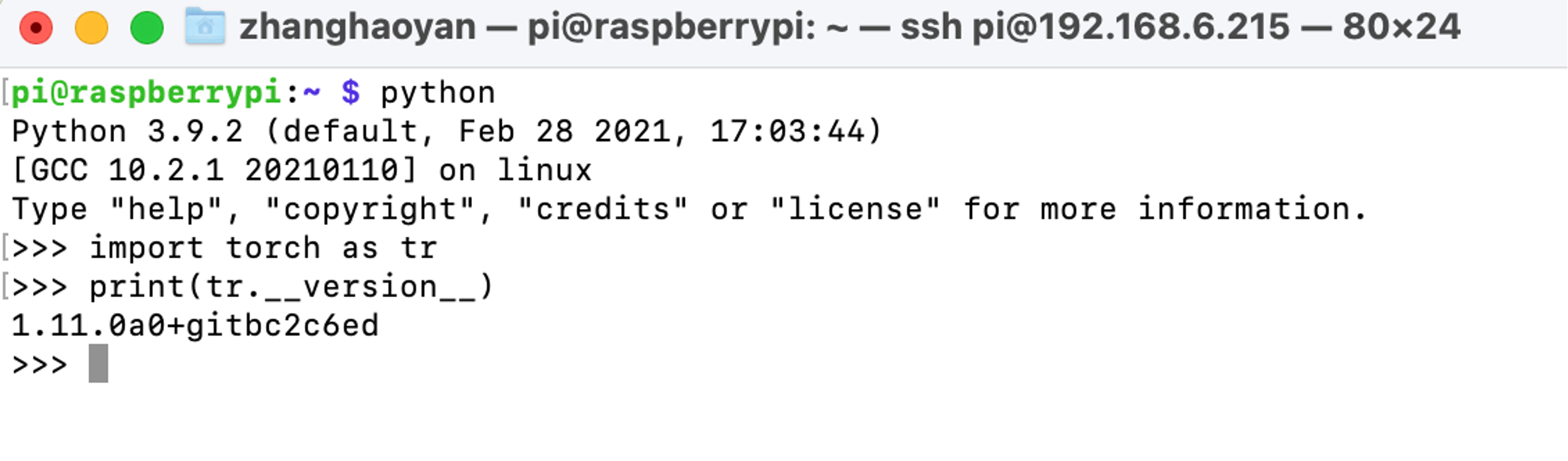
Notice: PyTorch wheels for Raspberry Pi 4 can be find in https://github.com/Qengineering/PyTorch-Raspberry-Pi-64-OS
Tritonclient
We can execute pip3 install tritonclient[all] to download Tritonclient.
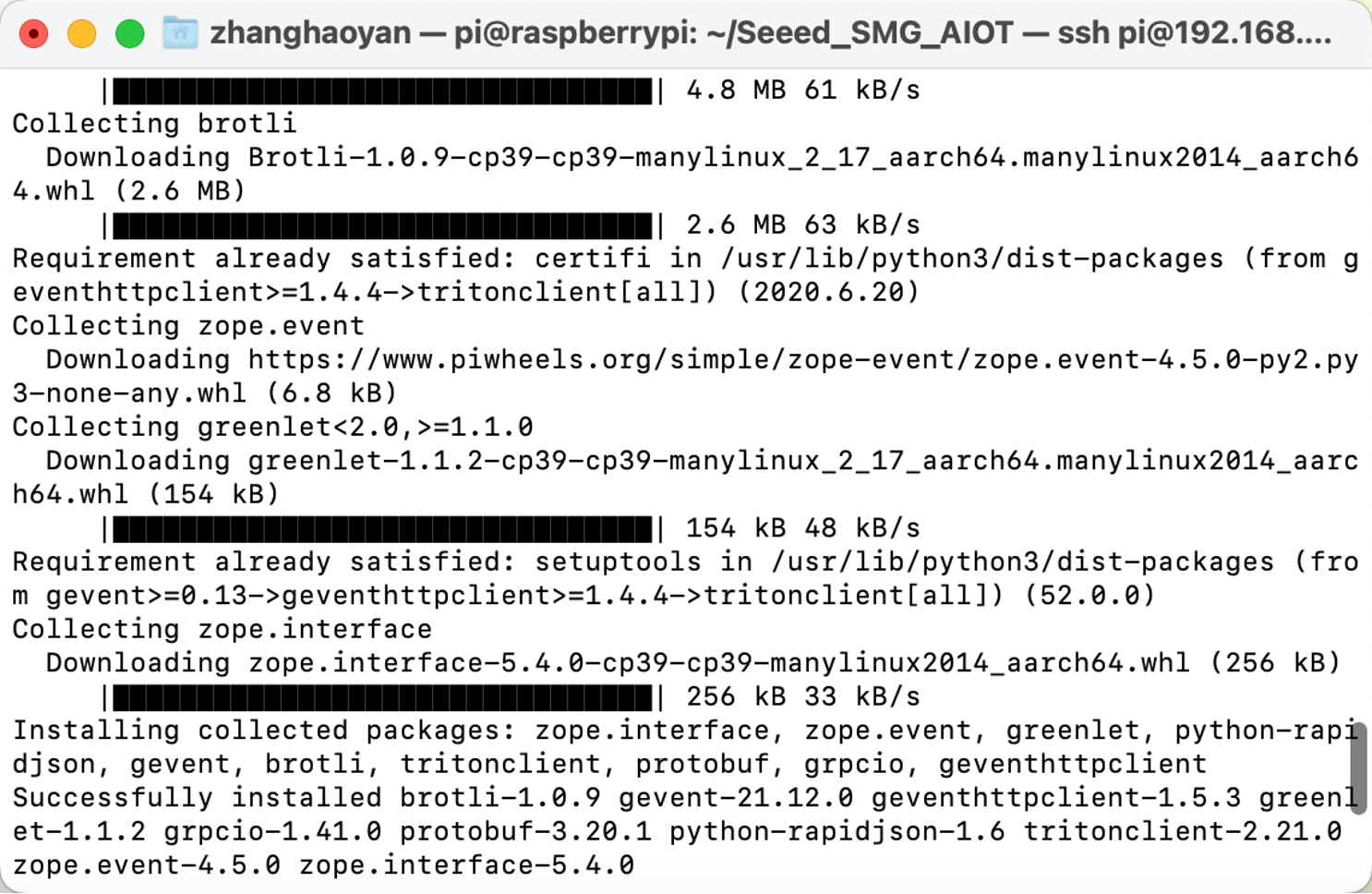
TorchVision
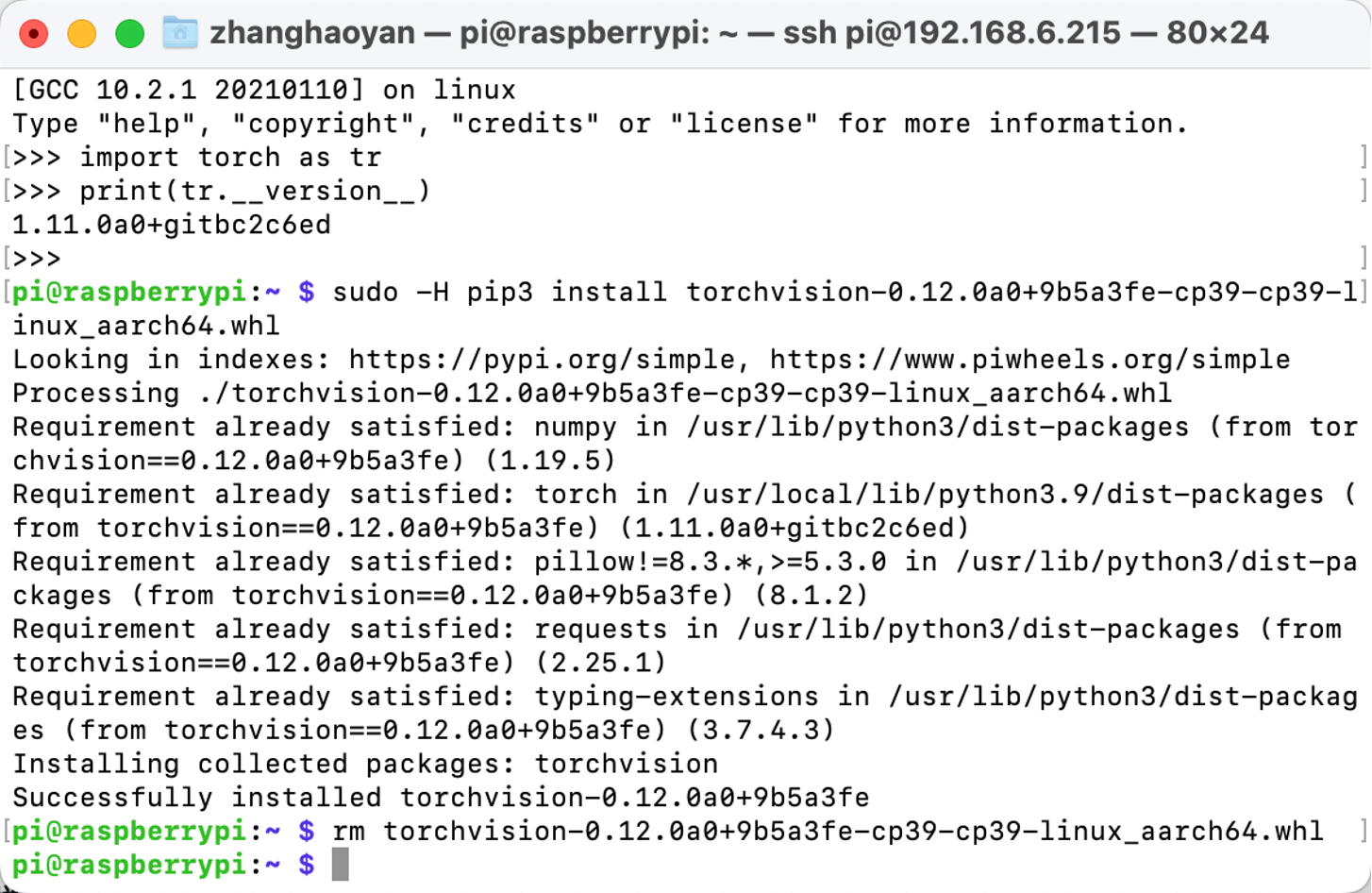
After Pytorch was installed, we can move to the Torchvision installation. Here are the commands:
# download the wheel
gdown https://drive.google.com/uc?id=1oDsJEHoVNEXe53S9f1zEzx9UZCFWbExh
# install torchvision 0.12.0
sudo -H pip3 install torchvision-0.12.0a0+9b5a3fe-cp39-cp39-linux_aarch64.whl
# clean up
rm torchvision-0.12.0a0+9b5a3fe-cp39-cp39-linux_aarch64.whl
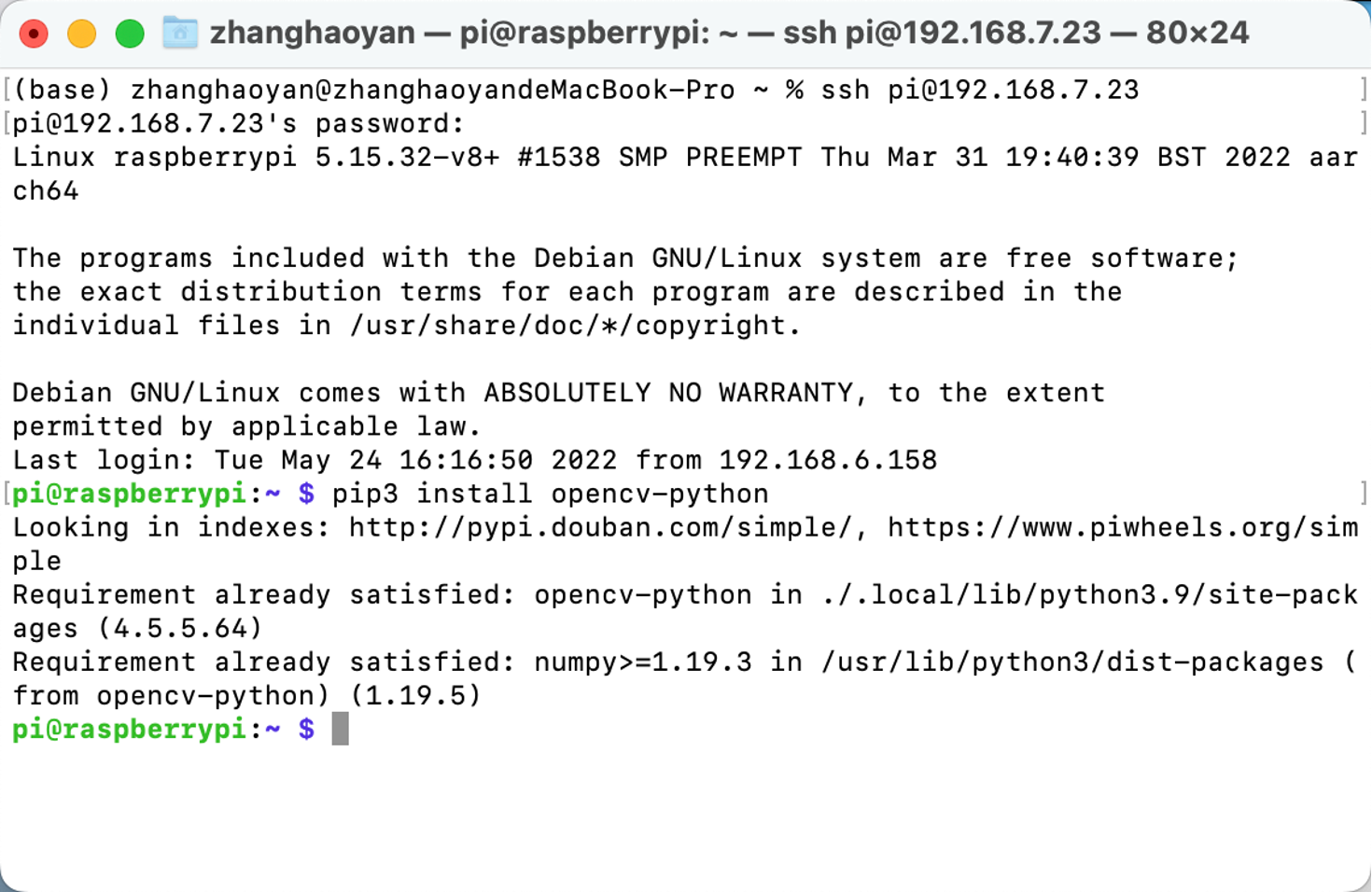
OpenCV
We can directly execute pip3 install opencv-python to install OpenCV:
Set up reComputer J1010
In this project, we will deploy Triton Inference Server to the reComputer J1010. In order to enhance the interactivity and deployment convenience of the trained model, we will convert the model into ONXX format.
Step 1. Install Jetpack 4.6.1 into reComputer J1010.
Step 2. Create a new folder “opi/1” in “home/server/docs/examples/model_repository ”. and then download trained and converted model.onnx and put it into the “1” folder.
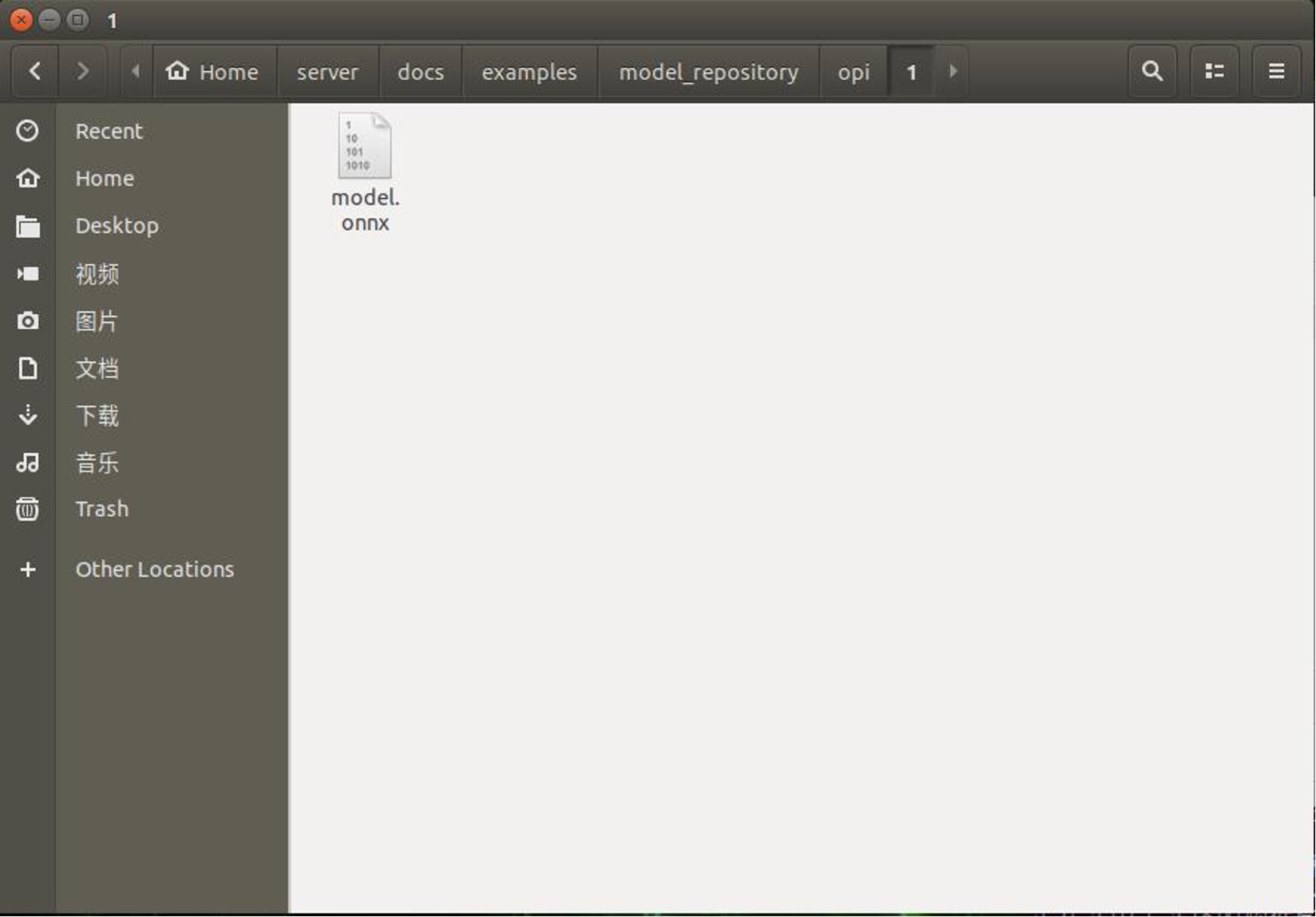
If you need another general server, you can execute the following steps.
Open a new Terminal and execute
git clone https://github.com/triton-inference-server/server
cd ~/server/docs/examples
sh fetch_models.sh
Step 3. Install the release of Triton for JetPack 4.6.1 and is provided in the attached tar file: tritonserver2.21.0-jetpack5.0.tgz.
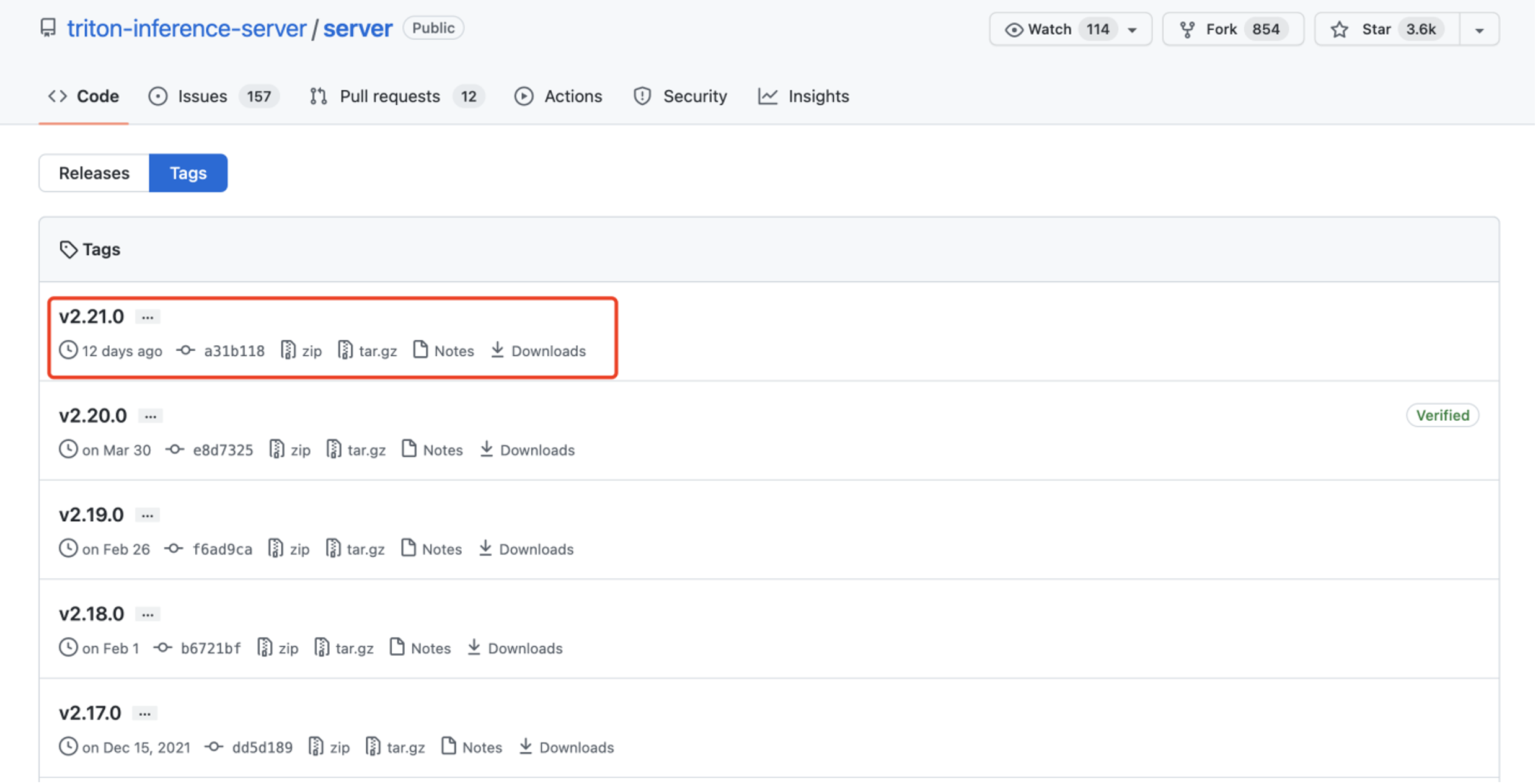
The tar file here contains the Triton server executable and shared libraries including the C++ and Python client libraries and examples. For more information about how to install and use Triton on JetPack you can refer to here.
Step 4. Execute the following command:
mkdir ~/TritonServer && tar -xzvf tritonserver2.19.0-jetpack4.6.1.tgz -C ~/TritonServer
cd ~/TritonServer/bin
./tritonserver --model-repository=/home/seeed/server/docs/examples/model_repository --backend-directory=/home/seeed/TritonServer/backends --strict-model-config=false --min-supported-compute-capability=5.3
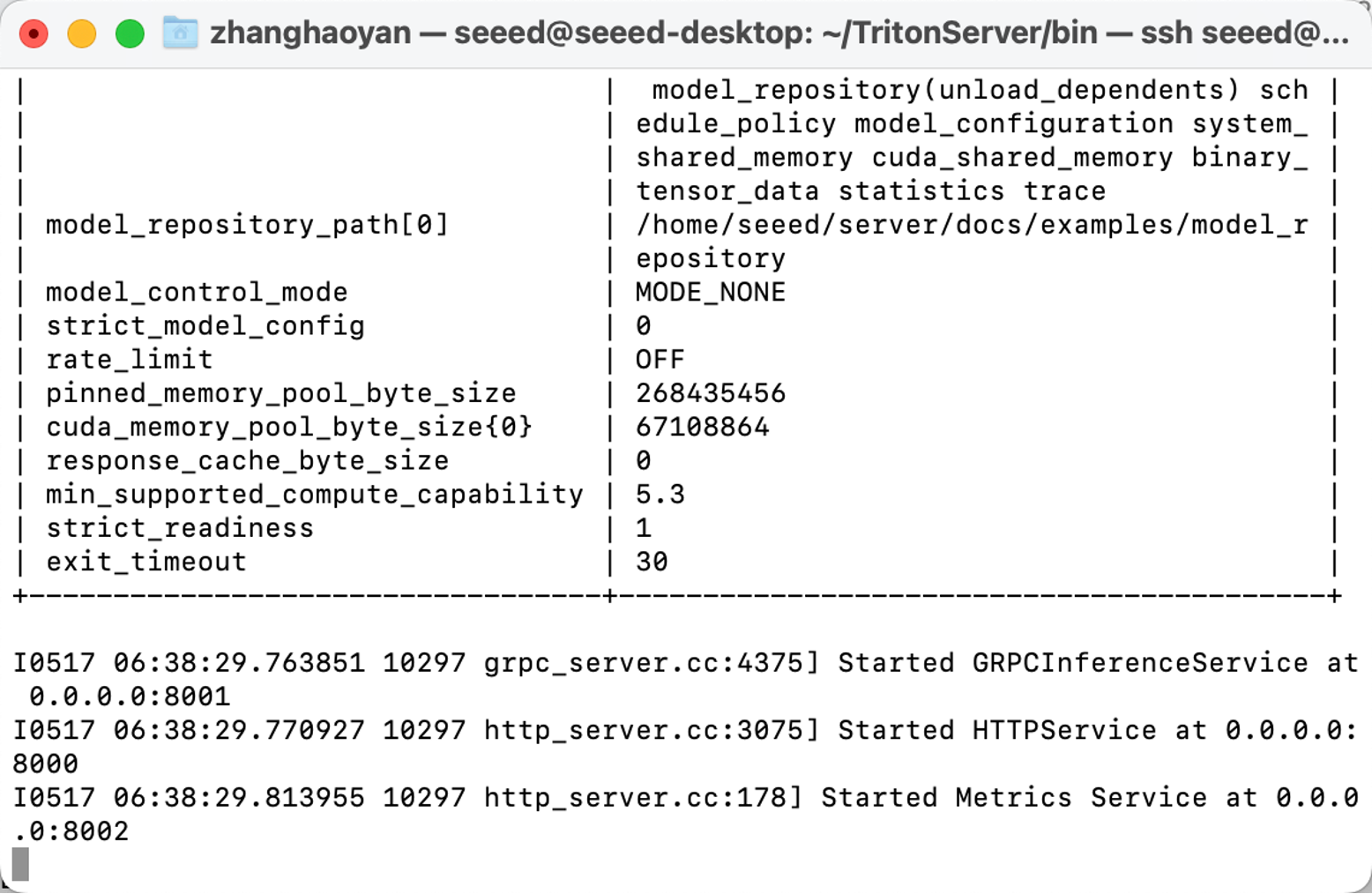
Now, we have set up all the preparations.
Operating the Program
Since all the required environments are deployed, we can run our project according to following steps.
Step 1. Download model and related files.
- Clone module from GitHub.
Open a new Terminal and execute:.
git clone https://github.com/LemonCANDY42/Seeed_SMG_AIOT.git
cd Seeed_SMG_AIOT/
git clone https://github.com/LemonCANDY42/OPIXray.git
- Create a new folder “weights” to store the trained weight of this algorithm “DOAM.pth”. Download the weight file and execute:
cd OPIXray/DOAMmkdir weights
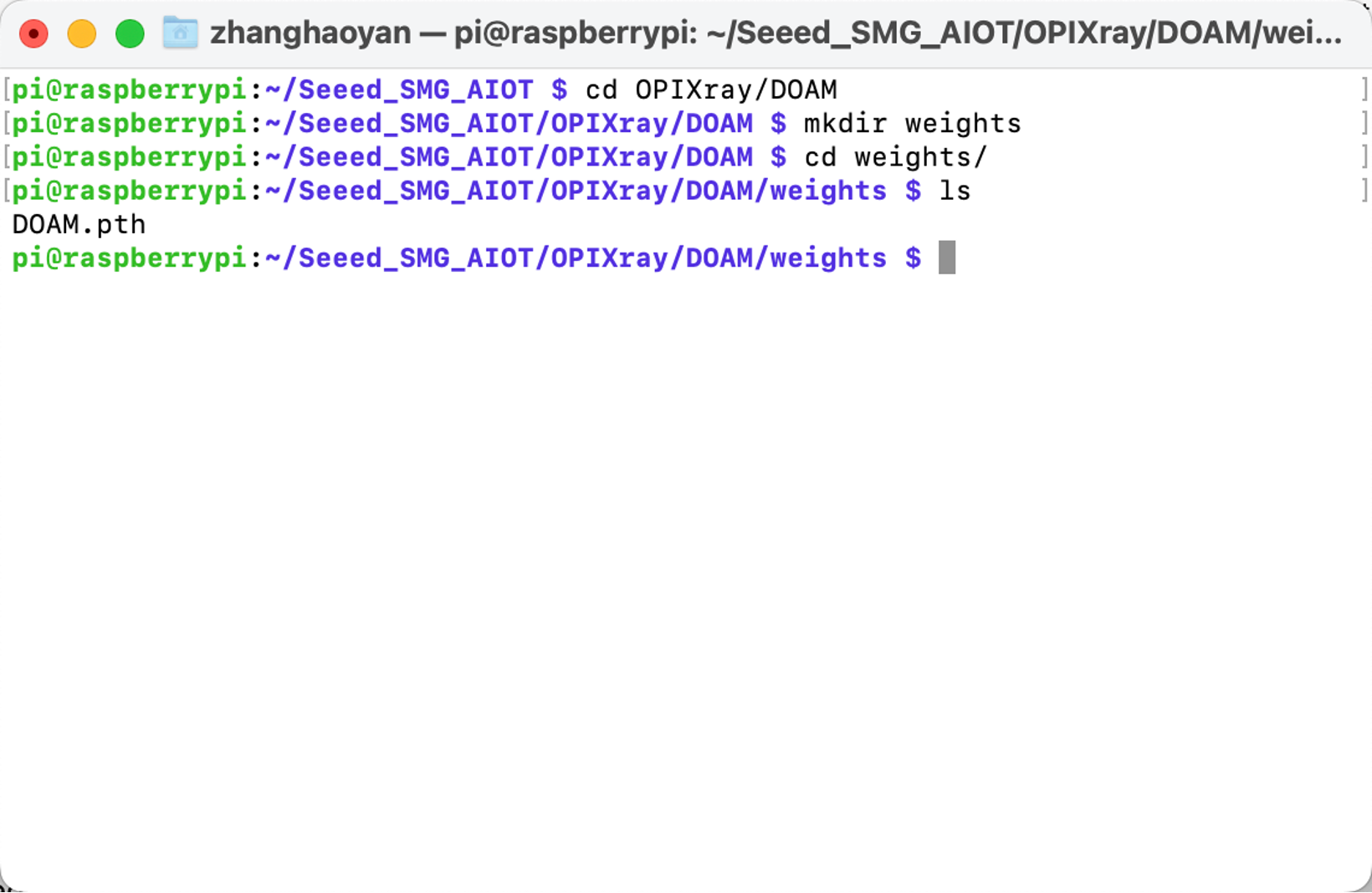
- Create a new “Dataset” folder to store the Xray images dataset.
Step 2. Running inference model.
Execute python OPIXray_grpc_image_client.py -u 192.168.8.230:8001 -m opi Dataset
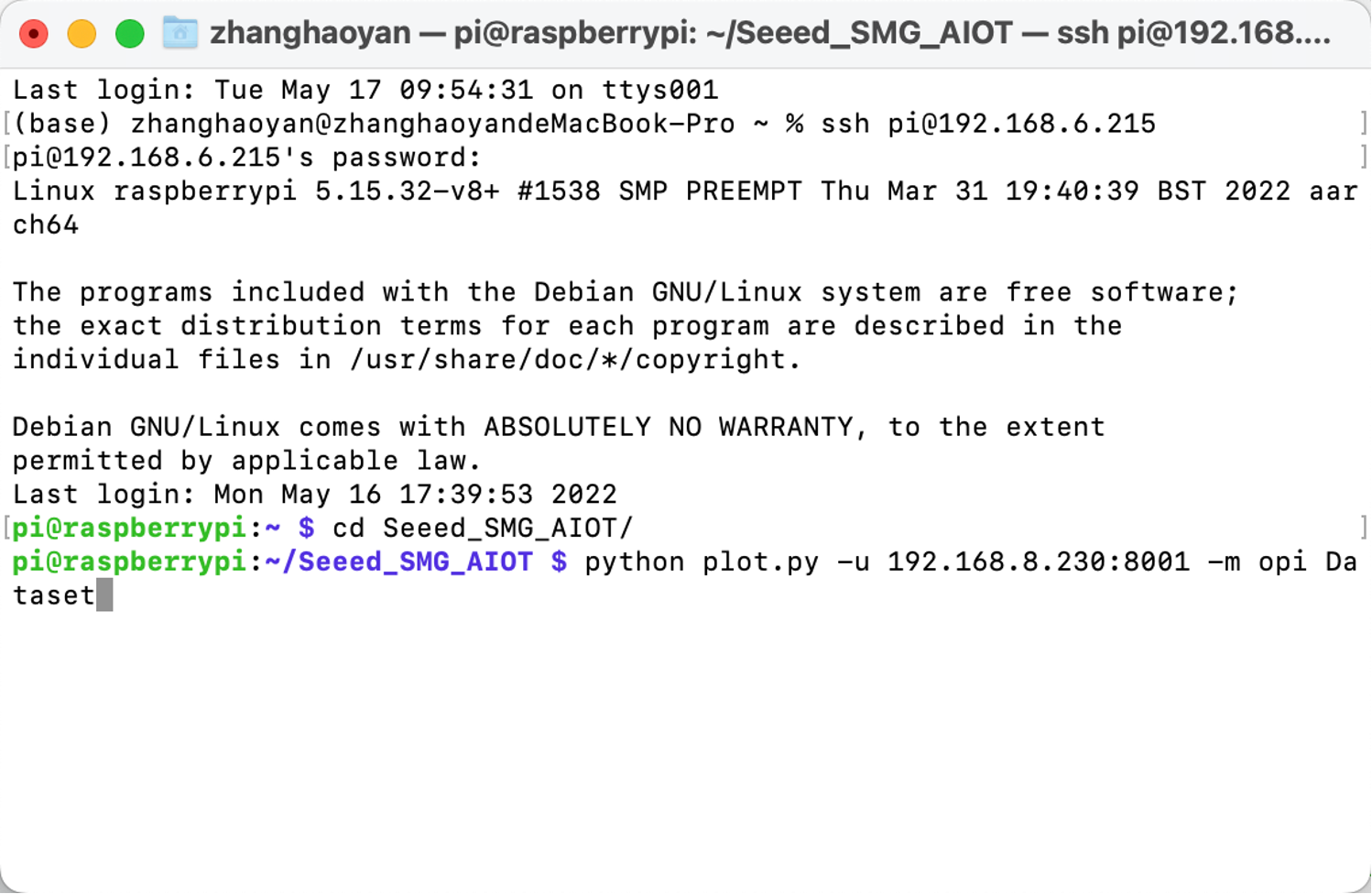
The result will be shown as the figure below:

Troubleshooting
When you luanch Triton server, you may meet following errors:
- if error with libb64.so.0d, execute:
sudo apt-get install libb64-0d
- if error with error with libre2.so.2, execute:
sudo apt-get install libre2-dev
- if error: creating server: Internal - failed to load all models, execute:
--exit-on-error=false
Tech Support & Product Discussion
Thank you for choosing our products! We are here to provide you with different support to ensure that your experience with our products is as smooth as possible. We offer several communication channels to cater to different preferences and needs.