Train and Deploy Your Own AI Model Into Grove - Vision AI
Upgradable to Industrial Sensors
With the SenseCAP S2110 controller and S2100 data logger, you can easily turn the Grove into a LoRaWAN® sensor. Seeed not only helps you with prototyping but also offers you the possibility to expand your project with the SenseCAP series of robust industrial sensors.
The IP66 housing, Bluetooth configuration, compatibility with the global LoRaWAN® network, built-in 19 Ah battery, and powerful support from APP make the SenseCAP S210x the best choice for industrial applications. The series includes sensors for soil moisture, air temperature and humidity, light intensity, CO2, EC, and an 8-in-1 weather station. Try the latest SenseCAP S210x for your next successful industrial project.







Overview
In this wiki, we will teach you how to train your own AI model for your specific application and then deploy it easily to the Grove - Vision AI Module. Let's get started!
Hardware introduction
We will mainly use the Grove - Vision AI Module throughout this wiki. So first, let's become familiar with the hardware.
Grove - Vision AI Module
Grove Vision AI Module represents a thumb-sized AI camera, customized sensor which has been already installed ML algorithm for people detection, and other customized models. Being easily deployed and displayed within minutes, it works under ultra-low power model, and provides two ways of singal transmission and multiple onboard modules, all of which make it perfect for getting started with AI-powered camera.

Software introduction
We will be using the following software technologies in this wiki
- Roboflow - for annotating
- YOLOv5 - for training
- TensorFlow Lite - for inferencing

What is Roboflow?
Roboflow is an annotation tool based online. This tool allows you to easily annotate all your images, add further processing to these images and export the labeled dataset into different formats such as YOLOV5 PyTorch, Pascal VOC, and more! Roboflow also has public datasets readily available to users.
What is YOLOv5?
YOLO is an abbreviation for the term ‘You Only Look Once’. It is an algorithm that detects and recognizes various objects in an image in real-time. Ultralytics YOLOv5 is the version of YOLO based on the PyTorch framework.
What is TensorFlow Lite?
TensorFlow Lite is an open-source, product ready, cross-platform deep learning framework that converts a pre-trained model in TensorFlow to a special format that can be optimized for speed or storage. The special format model can be deployed on edge devices like mobiles using Android or iOS or Linux based embedded devices like Raspberry Pi or Microcontrollers to make the inference at the Edge.
Wiki structure
This wiki will be divided into three main sections
- Train your own AI model with a public dataset
- Train your own AI model with your own dataset
- Deploy the trained AI model into Grove - Vision AI Module
The first section will be the fastest way to build your own AI model with the least number of steps. The second section will take some time and effort to build your own AI model, but it will be definitely worth the knowledge. The third section about deploying the AI model can be done either after first or second section.
So there are two ways to follow this wiki:
- Follow section 1 and then section 3 - fast to follow
- Follow section 2 and then section 3 - slow to follow
However, we encourage to follow the first way at first and then move onto the second way.
1. Train your own AI model with a public dataset
The very first step of an object detection project is to obtain data for training. You can either download datasets available publicly or create your own dataset!
But what is the fastest and easiest way to get started with object detection? Well...Using public datasets can save you a lot of time that you would otherwise spend on collecting data by yourself and annotating them. These public datasets are already annotated out-of-the-box, giving you more time to focus on your AI vision applications.
Hardware preparation
- Grove - Vision AI Module
- USB Type-C cable
- Windows/ Linux/ Mac with internet access
Software preparation
- No need to prepare additional software
Use publicly available annotated dataset
You can download a number of publically available datasets such as the COCO dataset, Pascal VOC dataset and much more. Roboflow Universe is a recommended platform which provides a wide-range of datasets and it has 90,000+ datasets with 66+ million images available for building computer vision models. Also, you can simply search open-source datasets on Google and choose from a variety of datasets available.
-
Step 1. Visit this URL to access an Apple Detection dataset available publicly on Roboflow Universe
-
Step 2. Click Create Account to create a Roboflow account
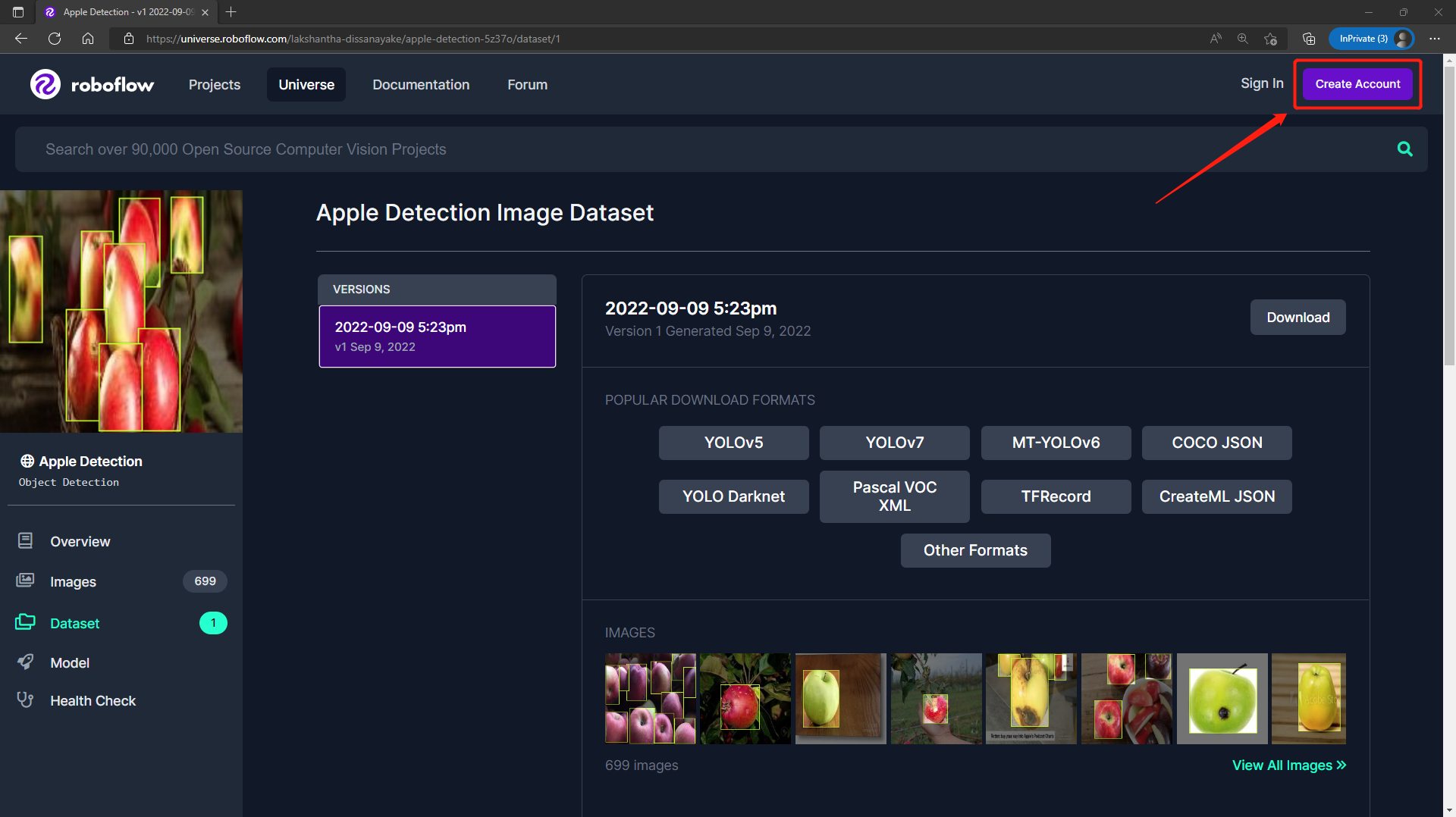
- Step 3. Click Download, select YOLO v5 PyTorch as the Format, click show download code and click Continue
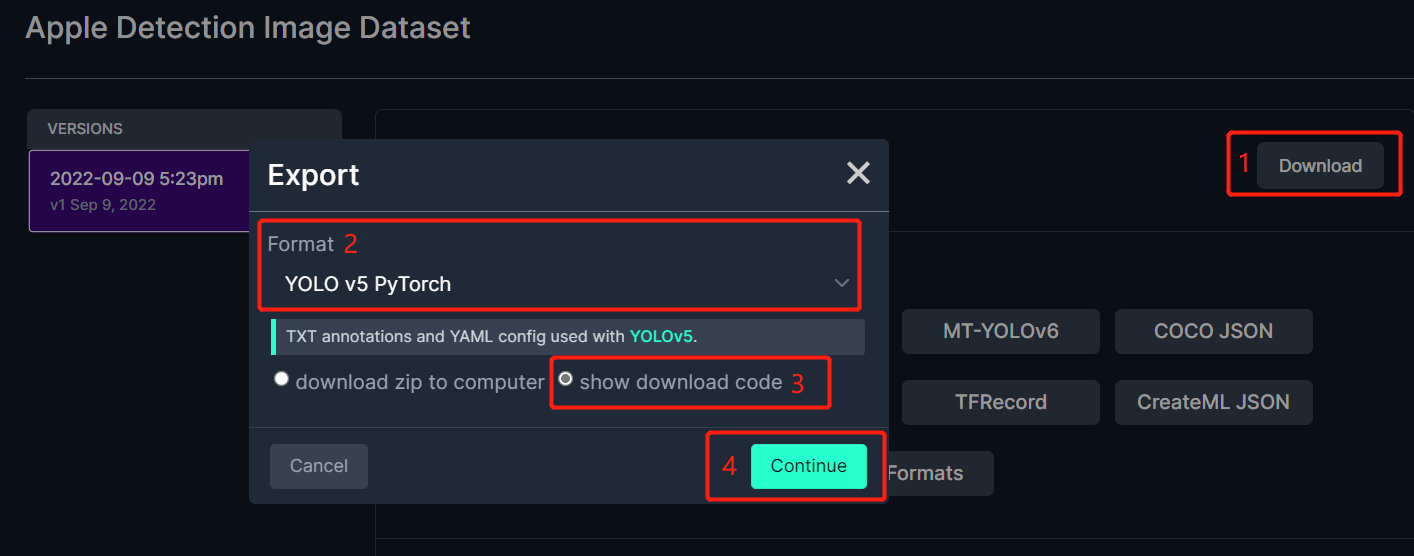
This will generate a code snippet that we will use later inside Google Colab training. So please keep this window open in the background.
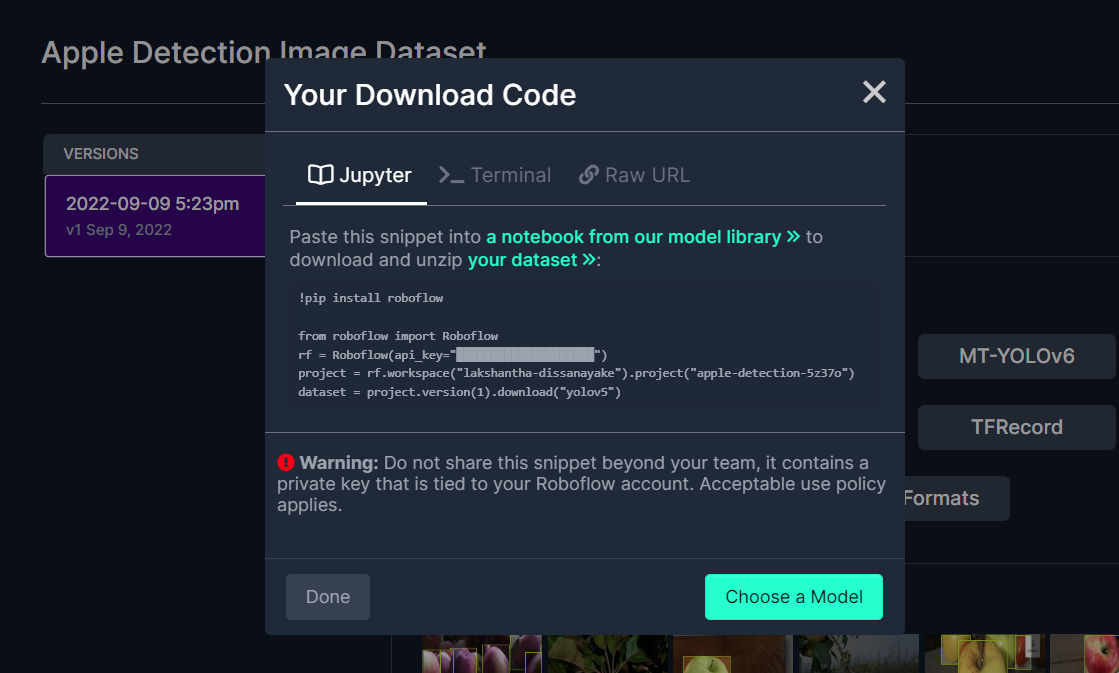
Train using YOLOv5 on Google Colab
After we have chosen a public dataset, we need to train the dataset. Here we use a Google Colaboratory environment to perform training on the cloud. Furthermore, we use Roboflow api within Colab to easily download our dataset.
Click here to open an already prepared Google Colab workspace, go through the steps mentioned in the workspace and run the code cells one by one.
Note: On Google Colab, in the code cell under Step 4, you can directly copy the code snippet from Roboflow as mentioned above
It will walkthrough the following:
- Setup an environment for training
- Download a dataset
- Perform the training
- Download the trained model
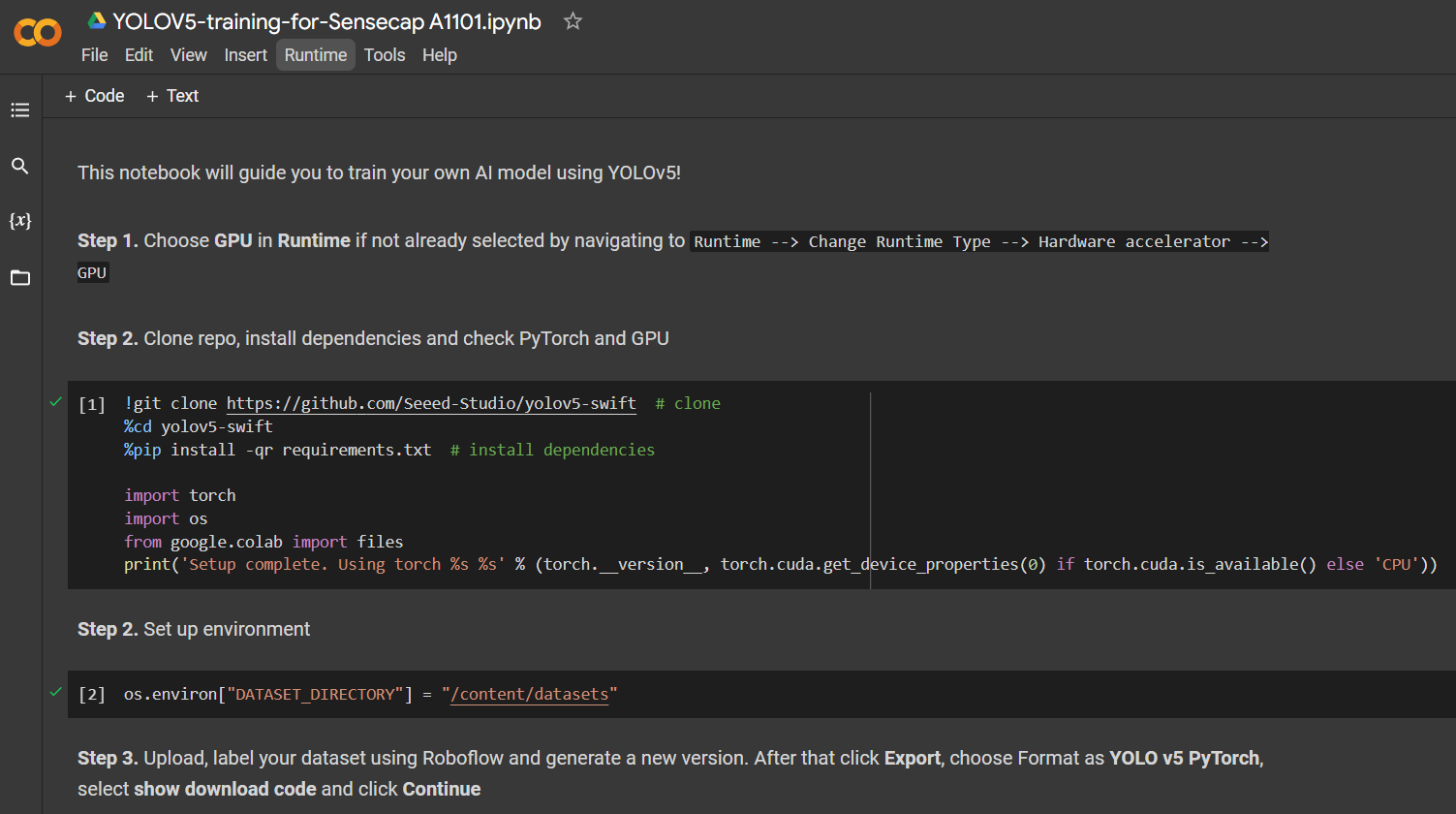
For an apple detection dataset with 699 images, it took around 7 minutes to finish the training process on Google Colab running on NVIDIA Tesla T4 GPU with 16GB GPU memory.
If you followed the above Colab project, you know that you can load 4 models to the device all at once. However, please note that only one model can be loaded at a time. This can be specified by the user and will be explained later in this wiki.
Deploy and inference
If you directly want to jump to section 3 which explains how to deploy the trained AI model into Grove - Vision AI Module and perform inference, click here.
2. Train your own AI model with your own dataset
If you want to build specific object detection projects where the public datasets do not have the objects that you want to detect, you might want to build your own dataset. When you record data for your own dataset, you have to make sure that you cover all angles (360 degrees) of the object, place the object in different environments, different lighting and different weather conditions. After recording your own dataset, you also have to annotate the images in the datset. All these steps will be convered in this section.
Eventhough there are different methods of collecting data such as using a mobile phone camera, the best way to collect data is to use the in-built camera on the Grove - Vision AI Module. This is because the colors, image quality and other details will be similar when we perform inference on Grove - Vision AI Module which makes the overall detection more accurate.
Annotate dataset using Roboflow
If you use your own dataset, you will need to annotate all the images in your dataset. Annotating means simply drawing rectangular boxes around each object that we want to detect and assign them labels. We will explain how to do this using Roboflow.
Roboflow is an annotation tool based online. Here we can directly import the video footage that we have recorded into Roboflow and it will be exported into a series of images. This tool is very convenient because it will let us help distribute the dataset into "training, validation and testing". Also this tool will allow us to add further processing to these images after labelling them. Furthermore, it can easily export the labelled dataset into YOLOV5 PyTorch format which is what we exactly need!
For this wiki, we will use a dataset with images containing apples so that we can detect apples later on and do counting as well.
-
Step 1. Click here to sign up for a Roboflow account
-
Step 2. Click Create New Project to start our project
- Step 3. Fill in Project Name, keep the License (CC BY 4.0) and Project type (Object Detection (Bounding Box)) as default. Under What will your model predict? column, fill in an annotation group name. For example, in our case we choose apples. This name should highlight all of the classes of your dataset. Finally, click Create Public Project.
- Step 4. Drag and drop the images that you have captured using Grove - Vision AI Module
- Step 5. After the images are processed, click Finish Uploading. Wait patiently until the images are uploaded.
- Step 6. After the images are uploaded, click Assign Images
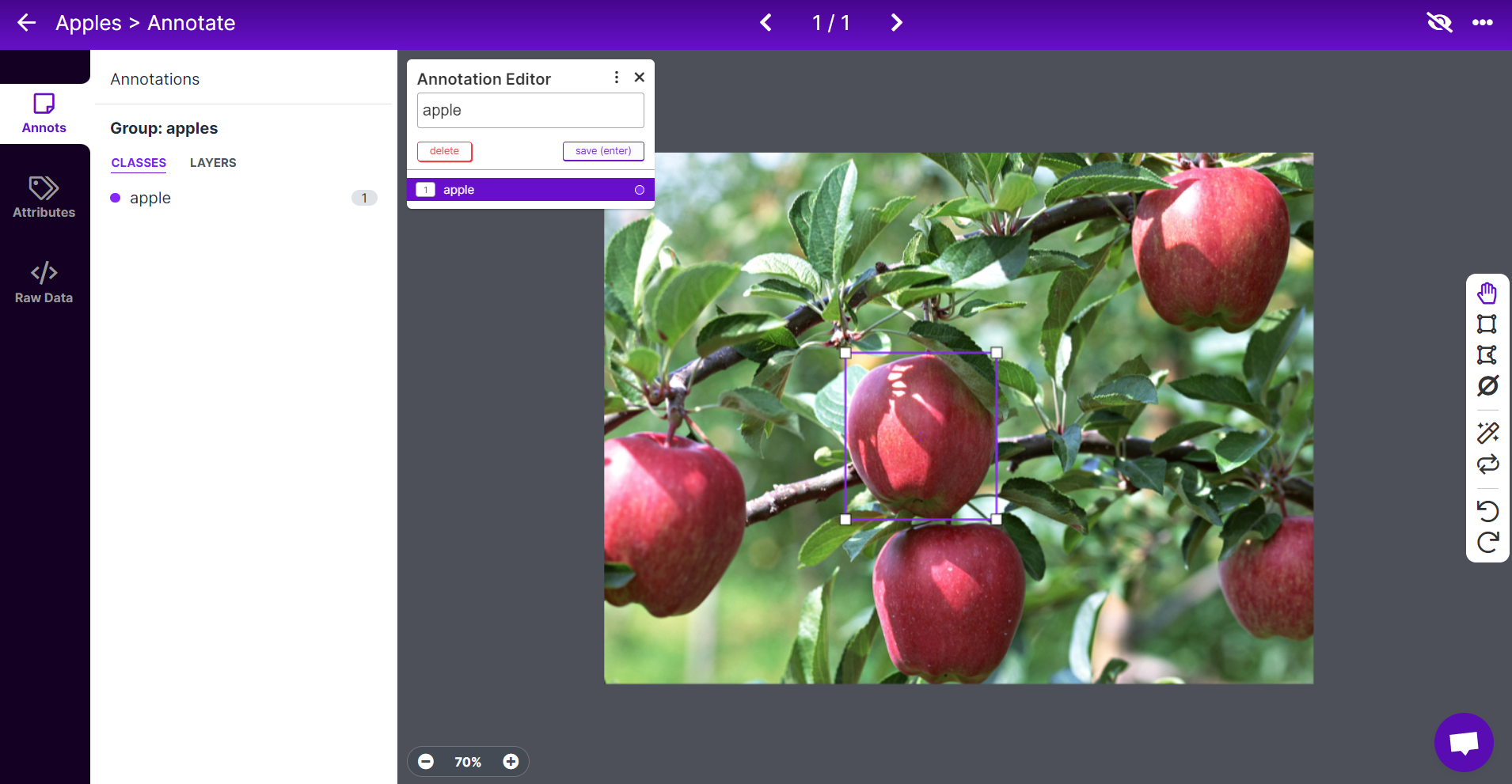
- Step 7. Select an image, draw a rectangular box around an apple, choose the label as apple and press ENTER
- Step 8. Repeat the same for the remaining apples
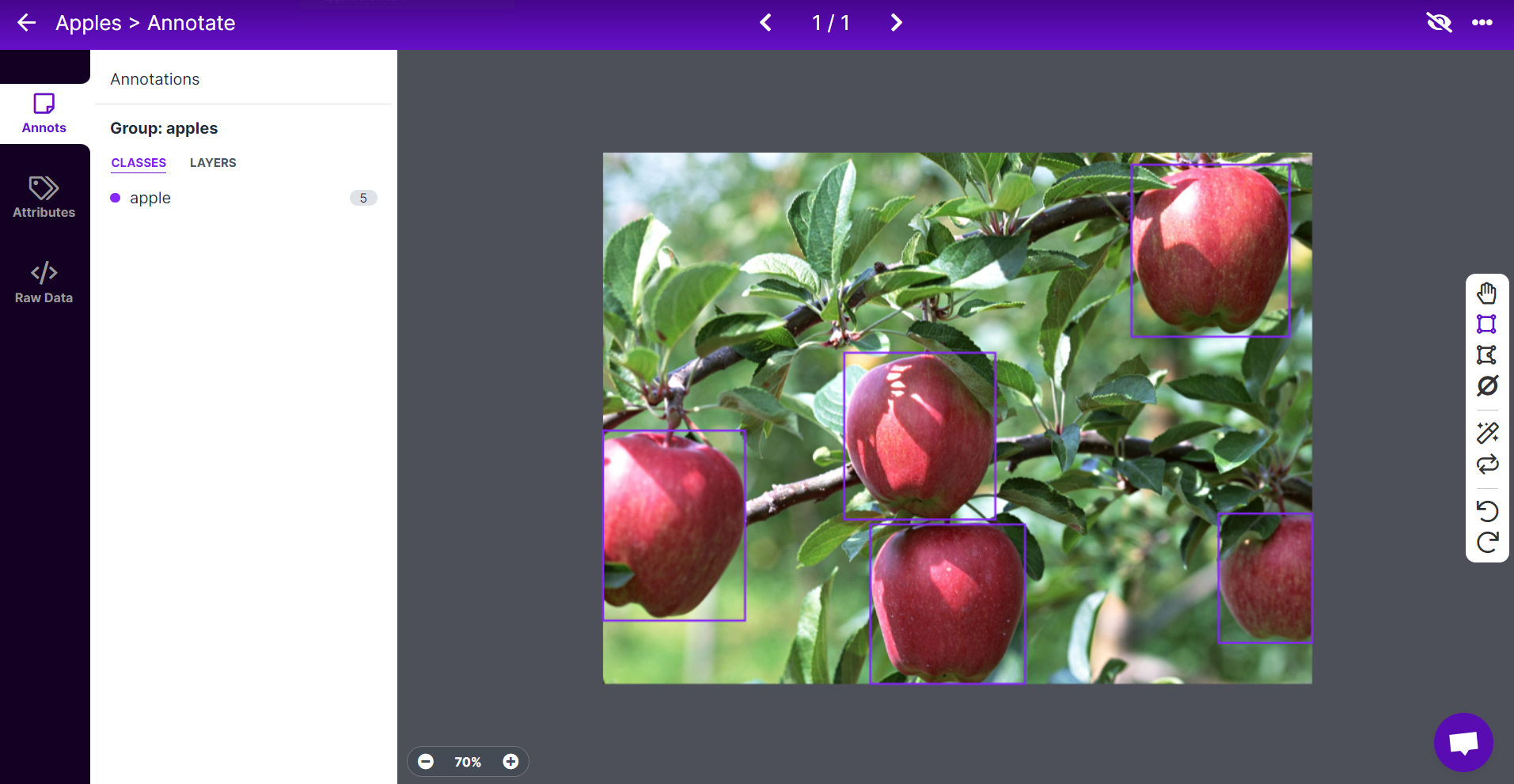
Note: Try to label all the apples that you see inside the image. If only a part of an apple is visible, try to label that too.
- Step 9. Continue to annotate all the images in the dataset
Roboflow has a feature called Label Assist where it can predict the labels beforehand so that your labelling will be much faster. However, it will not work with all object types, but rather a selected type of objects. To turn this feature on, you simply need to press the Label Assist button, select a model, select the classes and navigate through the images to see the predicted labels with bounding boxes
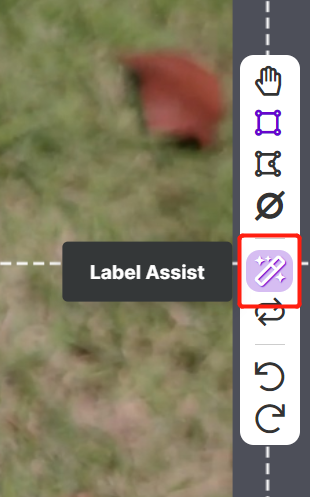
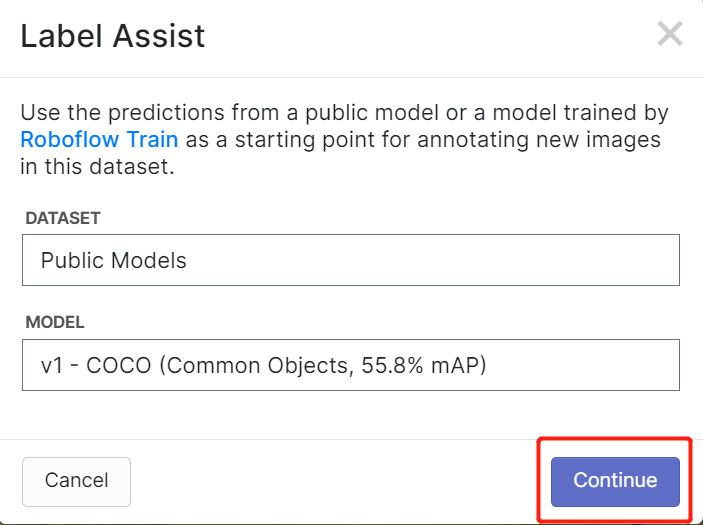
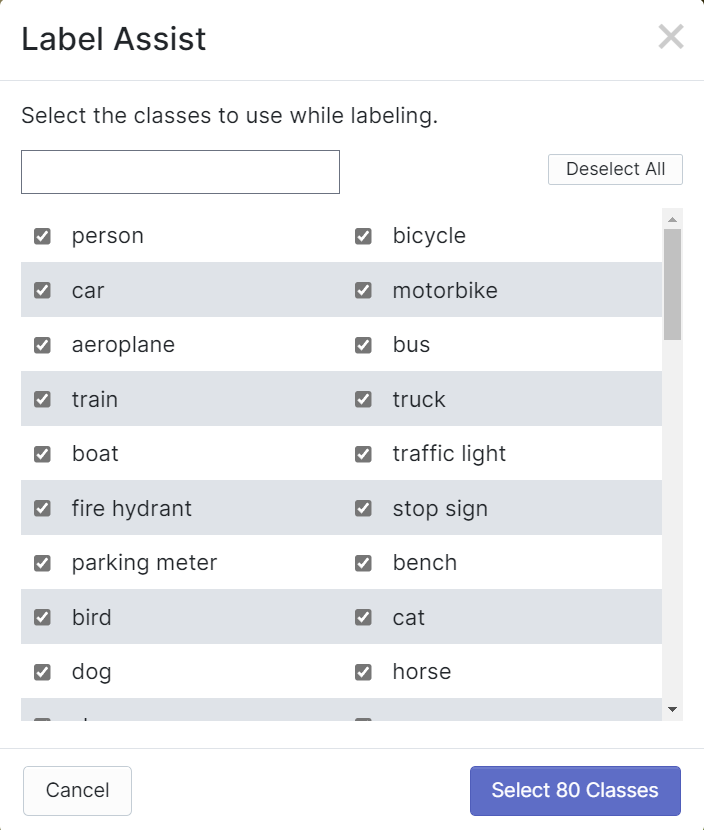
As you can see above, it can only help to predict annotations for the 80 classes mentioned. If your images do not contain the object classes from above, you cannot use the label assist feature.
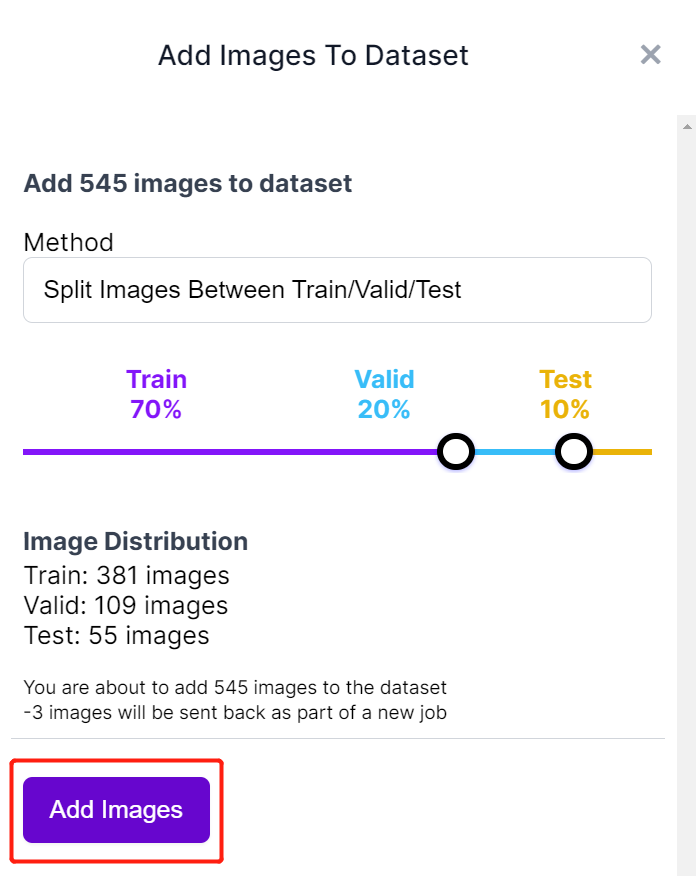
- Step 10. Once labelling is done, click Add images to Dataset

- Step 11. Next we will split the images between "Train, Valid and Test". Keep the default percentages for the distribution and click Add Images
- Step 12. Click Generate New Version

- Step 13. Now you can add Preprocessing and Augmentation if you prefer. Here we will change the Resize option to 192x192
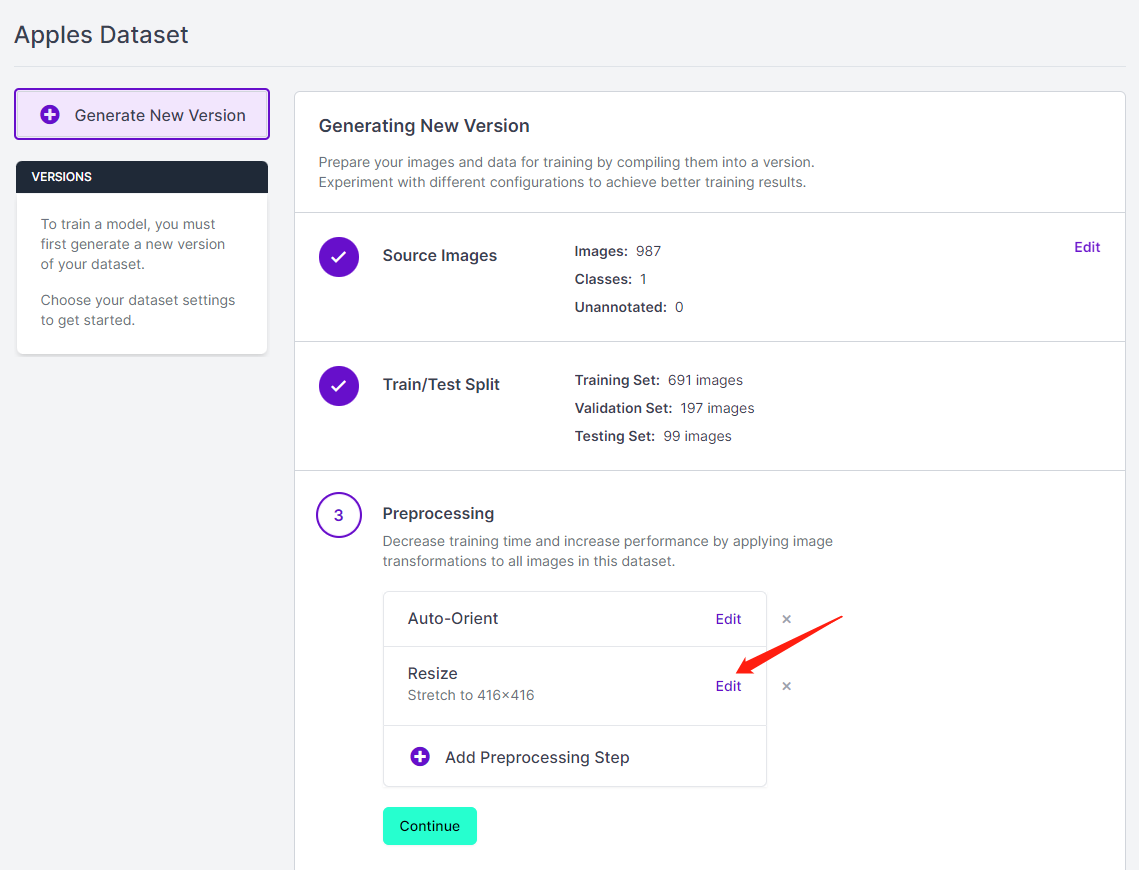
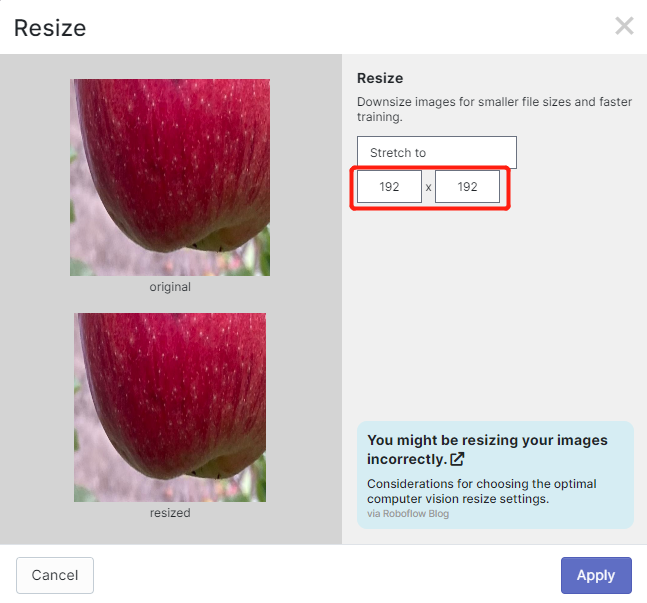
Here we change the image size to 192x192 because we will use that size for training and the training will be faster. Otherwise, it will have to convert all images to 192x192 during the training process which consumes more CPU resources and makes the training process slower.
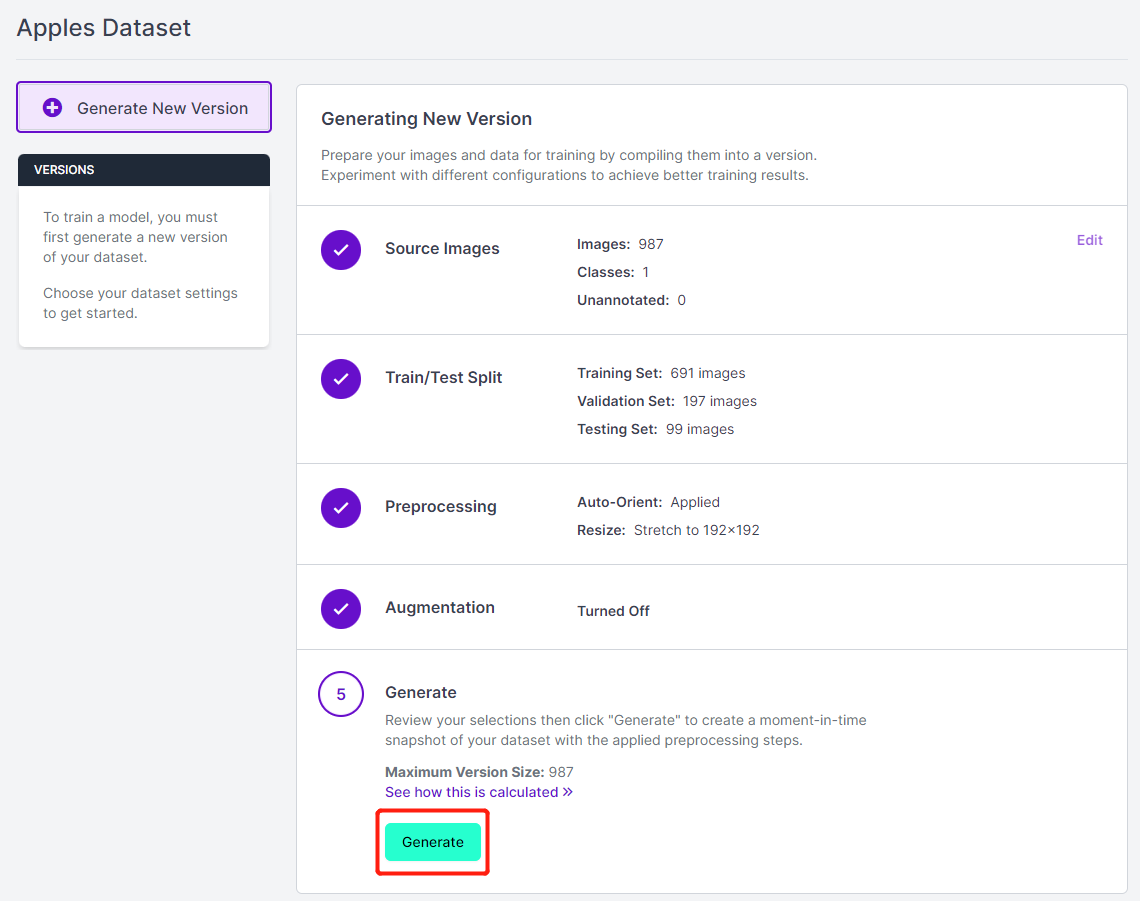
- Step 14. Next, proceed with the remaining defaults and click Generate
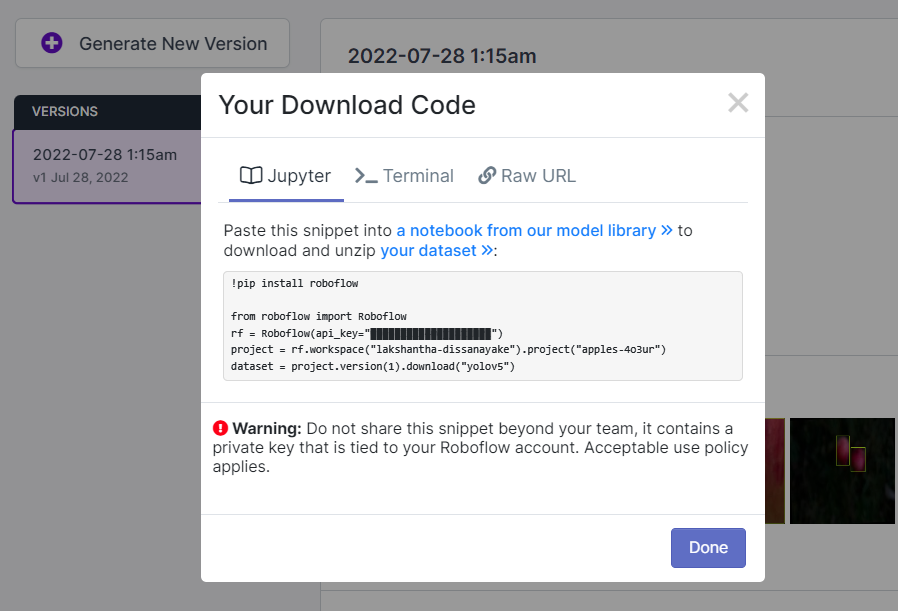
- Step 15. Click Export, select Format as YOLO v5 PyTorch, select show download code and click Continue
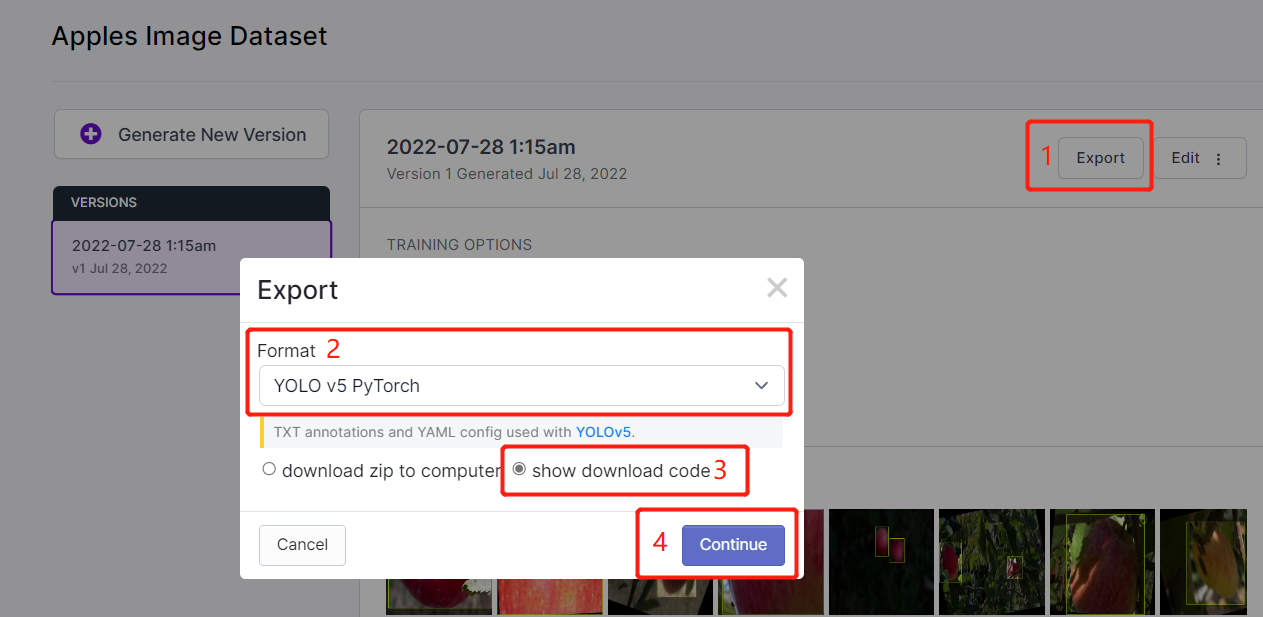
This will generate a code snippet that we will use later inside Google Colab training. So please keep this window open in the background.
Train using YOLOv5 on Google Colab
After we are done with annotating the dataset, we need to train the dataset. Jump to this part which explains how to train an AI model using YOLOv5 running on Google Colab.
3. Deploy the trained model and perform inference
Grove - Vision AI Module
Now we will move the model-1.uf2 that we obtained at the end of the training into Grove - Vision AI Module. Here we will connect the Grove - Vision AI Module with the Wio Terminal to view the inference results.
Note: If this is your first time using Arduino, we highly recommend you to refer Getting Started with Arduino. Also, please follow this wiki to setup Wio Terminal to work with Arduino IDE.
-
Step 1. Install the latest version of Google Chrome or Microsoft Edge browser and open it
-
Step 2. Connect Grove - Vision AI Module into your PC via a USB Type-C cable

- Step 3. Double-click the boot button on Grove - Vision AI Module to enter mass storage mode

After this you will see a new storage drive shown on your file explorer as GROVEAI
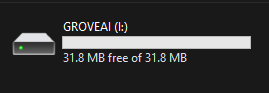
- Step 4. Drag and drop the model-1.uf2 file to GROVEAI drive
As soon as the uf2 finishes copying into the drive, the drive will disappear. This means the uf2 has been successfully uploaded to the module.
Note: If you have 4 model files ready, you can drag and drop each model one-by-one. Drop first model, wait until it finishes copying, enter boot mode again, drop second model and so on.
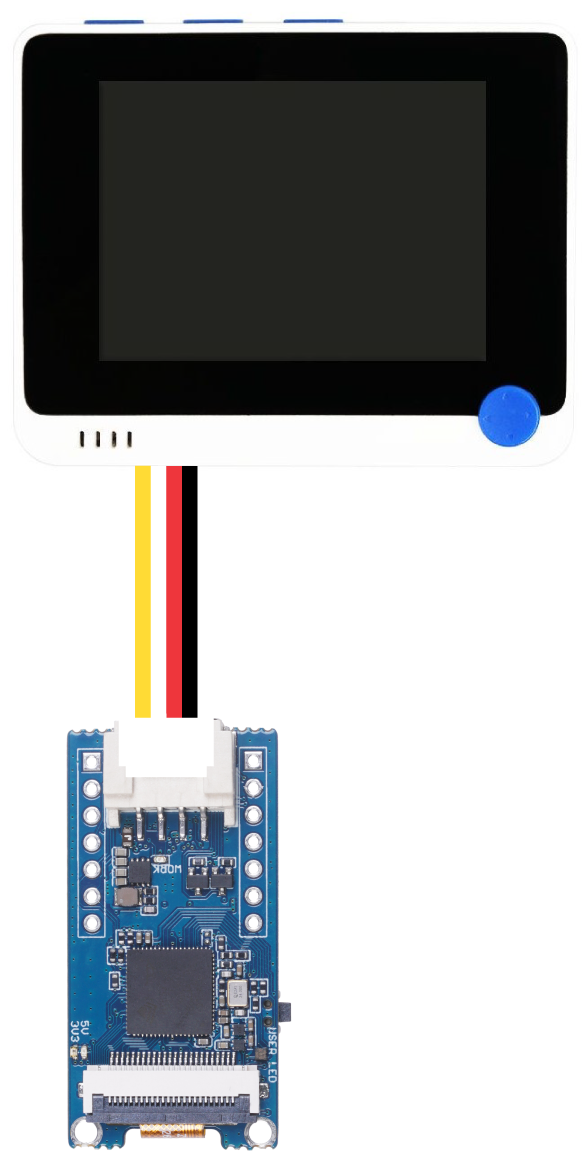
- Step 5. While the Grove - Vision AI Module is still connected with the PC using USB, connect it to the Wio Terminal via the Grove I2C port as follows
-
Step 6. Install Seeed_Arduino_GroveAI library into Arduino IDE and open object_detection.ino example
-
Step 7. If you have only loaded one model (with index 1) into Grove - Vision AI Module, it will load that model. However, if you have loaded multiple models, you can specify which model to use by changing MODEL_EXT_INDEX_[value] where value can take the digits 1,2,3 or 4
// for example:
if (ai.begin(ALGO_OBJECT_DETECTION, MODEL_EXT_INDEX_2))
The above will load the model with index 2
- Step 8. Since we are detecting apples, we will make a slight change to the code here
Serial.print("Number of apples: ");
- Step 9. Connect the Wio Terminal to PC, upload this code to the Wio Terminal and open serial monitor of Arduino IDE with 115200 as the baud rate
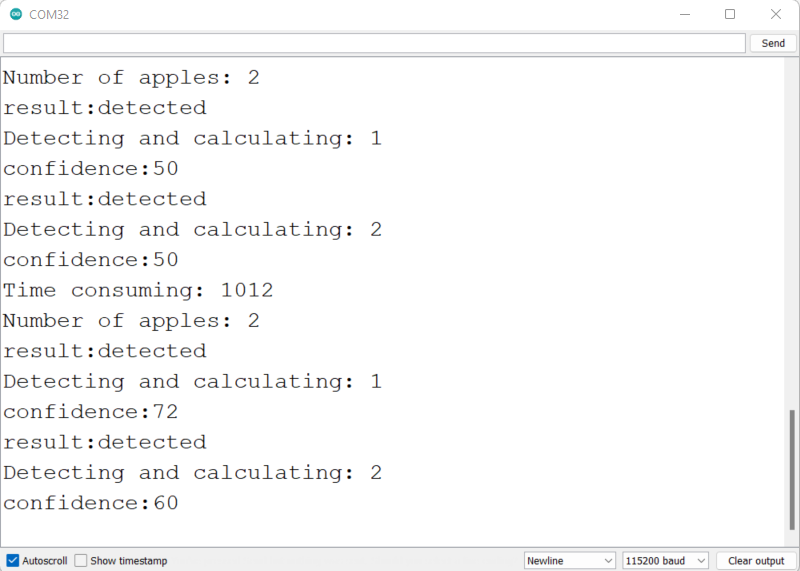
You will be able to see the detection information on the serial monitor as above.
- Step 10. Click here to open a preview window of the camera stream with the detections

- Step 11. Click Connect button. Then you will see a pop up on the browser. Select Grove AI - Paired and click Connect
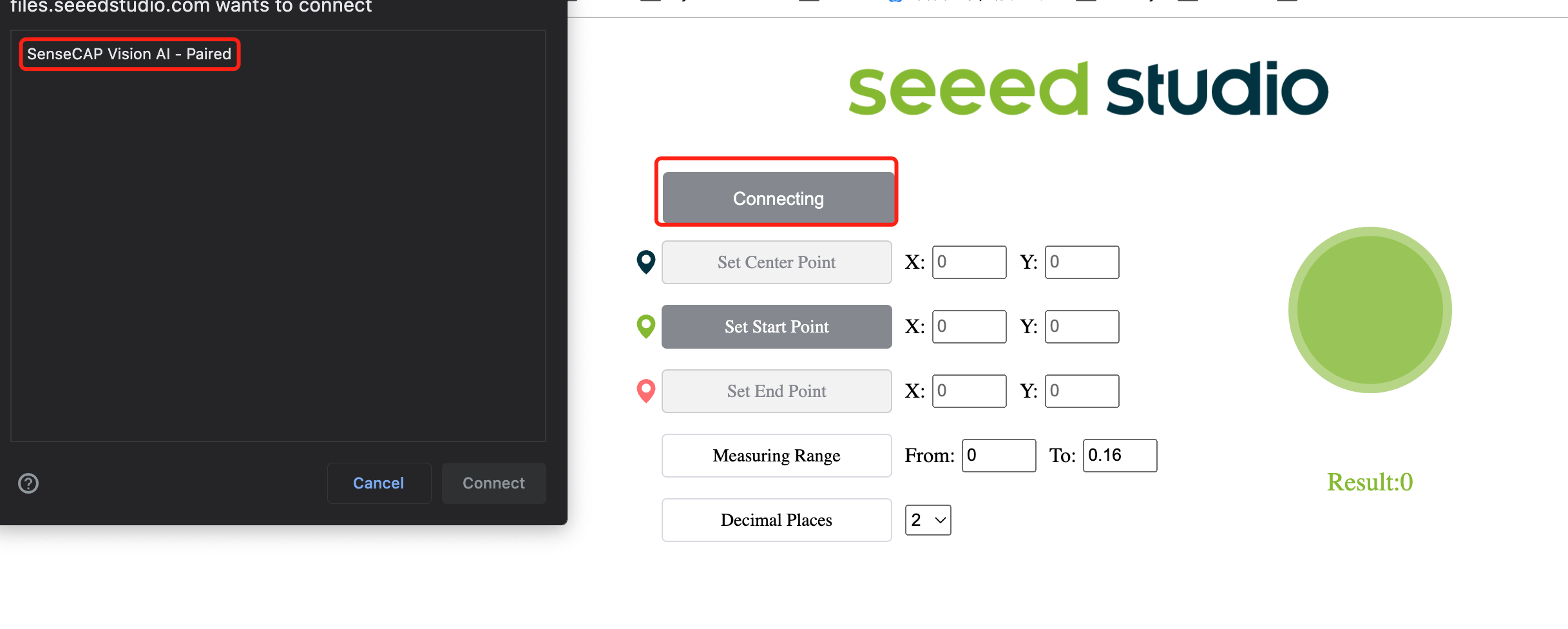
- Step 12. View real-time inference results using the preview window!

As you can see above, the apples are being detected with bounding boxes around them. Here "0" corresponds to each detection of the same class. If you have multiple classes, they will be named as 0,1,2,3,4 and so on. Also the confidence score for each detected apple (0.8 and 0.84 in above demo) is being displayed!
Bonus content
If you feel more adventurous, you can continue to follow the rest of the wiki!
Can I train an AI model on my PC?
You can also use your own PC to train an object detection model. However, the training preformance will depend on the hardware you have. You also need to have a PC with a Linux OS for training. We have used an Ubuntu 20.04 PC for this wiki.
- Step 1. Clone the yolov5-swift repo and install requirements.txt in a Python>=3.7.0 environment
git clone https://github.com/Seeed-Studio/yolov5-swift
cd yolov5-swift
pip install -r requirements.txt
- Step 2. If you followed the steps in this wiki before, you might remember that we exported the dataset after annotating in Robolflow. Also in Roboflow Universe, we downloaded the dataset. In both methods, there was a window like below where it asks what kind of format to download the dataset. So now, please select download zip to computer, under Format choose YOLO v5 PyTorch and click Continue
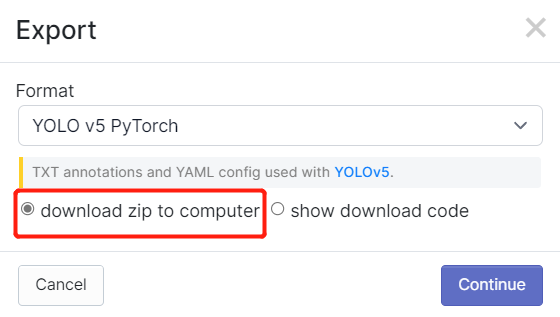
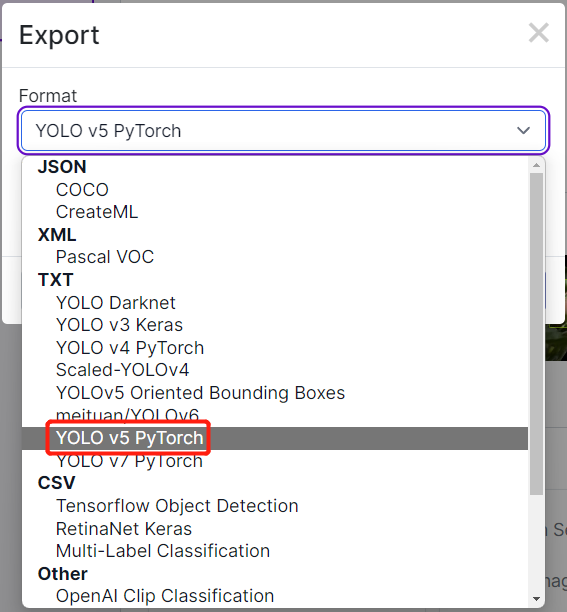
After that, a .zip file will be downloaded to your computer
- Step 3. Copy and paste the .zip file that we downloaded into yolov5-swift directory and extract it
# example
cp ~/Downloads/Apples.v1i.yolov5pytorch.zip ~/yolov5-swift
unzip Apples.v1i.yolov5pytorch.zip
- Step 4. Open data.yaml file and edit train and val directories as follows
train: train/images
val: valid/images
- Step 5. Download a pre-trained model suitable for our training
sudo apt install wget
wget https://github.com/Seeed-Studio/yolov5-swift/releases/download/v0.1.0-alpha/yolov5n6-xiao.pt
- Step 6. Execute the following to start training
Here, we are able to pass a number of arguments:
- img: define input image size
- batch: determine batch size
- epochs: define the number of training epochs
- data: set the path to our yaml file
- cfg: specify our model configuration
- weights: specify a custom path to weights
- name: result names
- nosave: only save the final checkpoint
- cache: cache images for faster training
python3 train.py --img 192 --batch 64 --epochs 100 --data data.yaml --cfg yolov5n6-xiao.yaml --weights yolov5n6-xiao.pt --name yolov5n6_results --cache
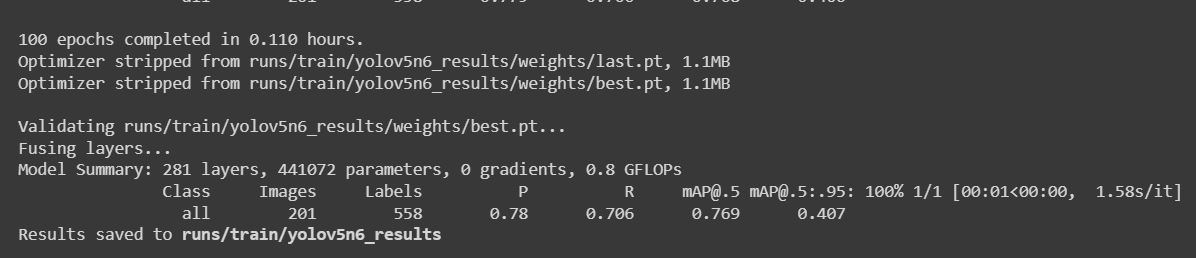
For an apple detection dataset with 987 images, it took around 30 minutes to finish the training process on a Local PC running on NVIDIA GeForce GTX 1660 Super GPU with 6GB GPU memory.

If you followed the above Colab project, you know that you can load 4 models to the device all at once. However, please not that only one model can be loaded at a time. This can be specified by the user and will be explained later in this wiki.
- Step 7. If you navigate to
runs/train/exp/weights, you will see a file called best.pt. This is the generated model from training.

- Step 8. Export the trained model to TensorFlow Lite
python3 export.py --data {dataset.location}/data.yaml --weights runs/train/yolov5n6_results/weights/best.pt --imgsz 192 --int8 --include tflite
- Step 9. Convert TensorFlow Lite to a UF2 file
UF2 is a file format, developed by Microsoft. Seeed uses this format to convert .tflite to .uf2, allowing tflite files to be stored on the AIoT devices launched by Seeed. Currently Seeed's devices support up to 4 models, each model (.tflite) is less than 1M .
You can specify the model to be placed in the corresponding index with -t.
For example:
-t 1: index 1-t 2: index 2
# Place the model to index 1
python3 uf2conv.py -f GROVEAI -t 1 -c runs//train/yolov5n6_results//weights/best-int8.tflite -o model-1.uf2
Eventhough you can load 4 models to the device all at once, please not that only one model can be loaded at a time. This can be specified by the user and will be explained later in this wiki.
- Step 10. Now a file named model-1.uf2 will be generated. This is the file that we will load into the Grove - Vision AI Module to perform the inference!
Resources
-
[Web Page] YOLOv5 Documentation
-
[Web Page] Ultralytics HUB
-
[Web Page] Roboflow Documentation
-
[Web Page] TensorFlow Lite Documentation
Tech Support & Product Discussion
Thank you for choosing our products! We are here to provide you with different support to ensure that your experience with our products is as smooth as possible. We offer several communication channels to cater to different preferences and needs.